







文章目录
1、高并发场景秒杀抢购超卖Bug实战重现
2、阿里巴巴内部高并发秒杀下单方案首次揭秘
3、基于Redis与MQ实现秒杀下单架构
4、十万订单每秒热点数据架构优化实践
5、秒杀下单MQ如何保证不丢消息
6、解决MQ下单消息重复消费幂等机制详解
7、线上MQ百万秒杀订单积压优化实战
8、Redis集群崩溃时如何保证秒杀系统高可用
9、Redis主从切换导致库存同步异常以及超卖问题
10、MQ集群崩溃时如何保证秒杀系统高可用
11、秒杀链路中Redis与MQ如何保证事务一致性
三高——高并发、高可用、高可扩展
秒杀系统一般单独部署,省的影响其他服务,
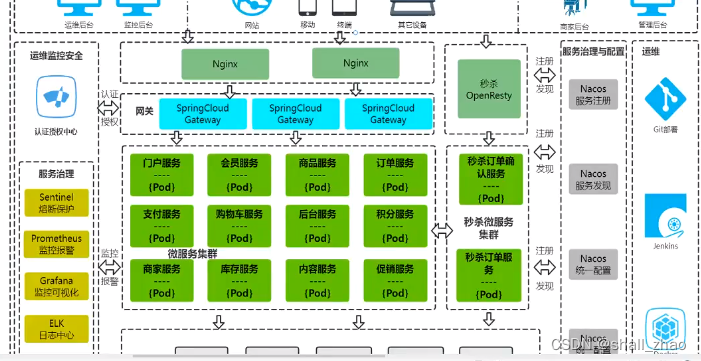
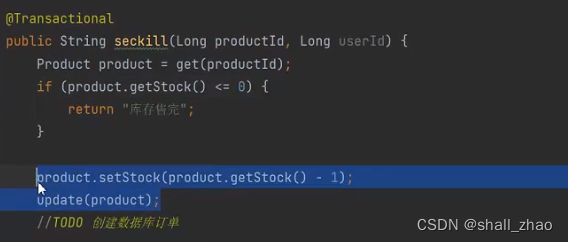
这样的秒杀,在高并发情况下会产生超卖的情况,怎么办?
用数据库乐观锁解决超卖
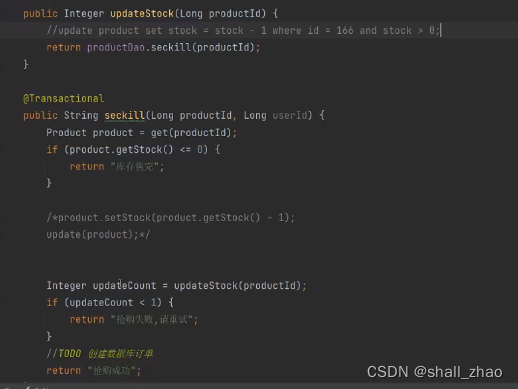
数据库上千的并发已经是极限了,虽然没加分布式锁(分布式锁性能更差劲),那希望性能继续提升怎么办?
阿里巴巴:为了提升数据库性能,对数据库的源码级别做了改造——在DB内部实现内存队列,一次性接收很多的请求,一次性更新。
一般公司是没能力改这个的。
京东:redis,mq,也有用缓存的
先看一个用redis简单实现的
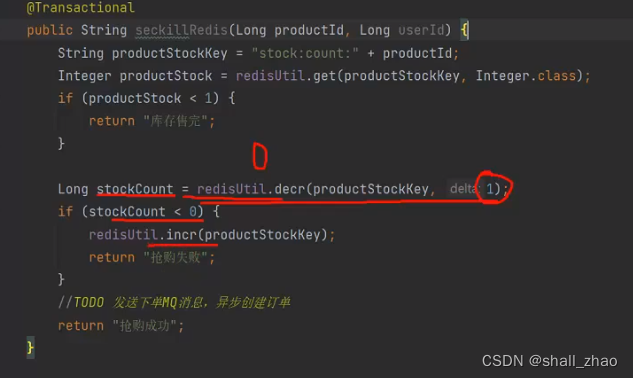
异步下单,下单的时候没有操作数据库,性能就提高了,先给用户返回抢购成功,前面加一个转圈圈的过程,后面的交给MQ,前段可以定时的往后端发送是否下单成功,直到查询到下单成功在跳转到支付页面。
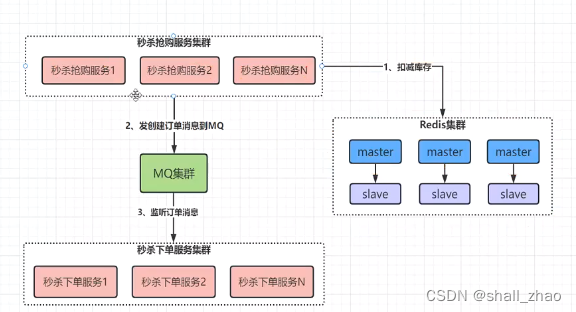
但现在的方案,每秒能支撑十万的并发吗?——显然不行。
redis理论上每秒十万的请求(一般只有查询,等等等条件下)。
redis集群架构部署
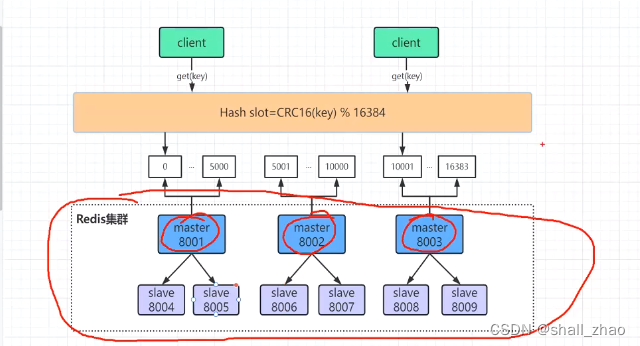
redis集群,数据是分片存储的——有哈希分片算法
一个redis读写混合并发,撑死也就两三万。
那我们把秒杀商品均匀的分配到不同的redis节点上,理论上,只要节点足够多,可以抗住十万的并发,但是实际上,万一分片的全都到一个节点上了,就不行了
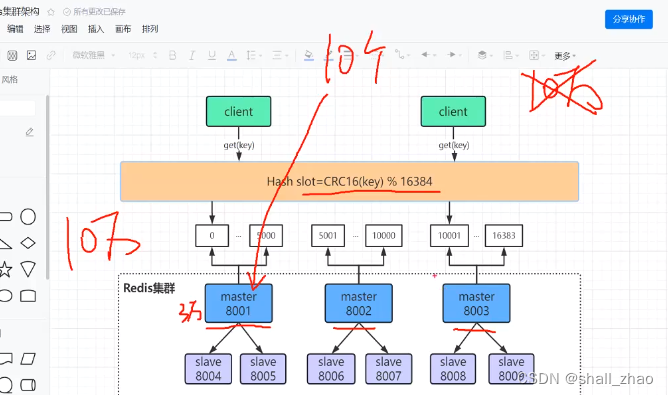
redis集群架构的数据倾斜怎么解决?
- 预热商品缓存的时候我们是清楚的,万一在预热的时候发生数据倾斜了,就通过一些命令把一部分数据迁移到其他节点上去,尽可能均匀分配。
- HashTag,在key前面加上HashTag,这样也可以解决数据倾斜
但是还有问题——热点商品也会导致某一个节点并发过量
热点商品问题——怎么解决并发?
做缓存预热的时候就应该把这个商品拆分开
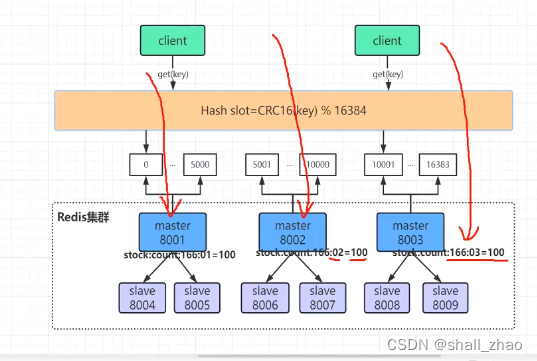
可以做数据的分片,是对一个商品的库存做分片。
再看看这样的秒杀系统,还有什么问题?
MQ丢消息怎么解决?
肯定有丢消息的可能,不同的MQ有不同的方案
简单点的方案,在发MQ消息之前,存一份到消息发送表,等处理完成后在回去修改消息发送表。
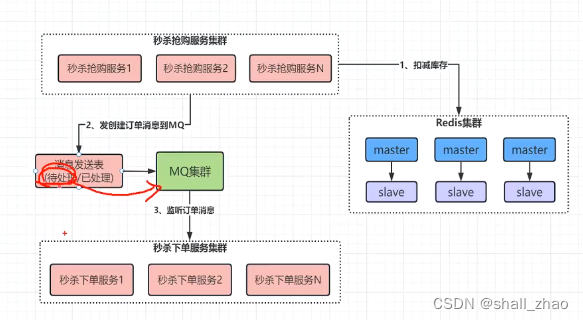
虽然不至于丢,但是毕竟操作数据库了,并发肯定不高。
针对不同的MQ做对应的MQ消息丢失的方案
MQ消息积压怎么解决?
消息积压会导致前端一直转圈圈(哈哈哈),但是等十来分钟你会等吗?
插DB慢,我们可以插redis,那查的话怎么查询?如果查DB找不到,就找Redis
如果收到message的发送时间和当前的处理时间太长了,快速的插入到redis。这是临时的处理方案,最终后台还是要同步到DB的。
如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
你看这问法,其实本质针对的场景,都是说,可能你的消费端出了问题,不消费了;或者消费的速度极其慢。接着就坑爹了,可能你的消息队列集群的磁盘都快写满了,都没人消费,这个时候怎么办?或者是这整个就积压了几个小时,你这个时候怎么办?或者是你积压的时间太长了,导致比如 RabbitMQ 设置了消息过期时间后就没了怎么办?
所以就这事儿,其实线上挺常见的,一般不出,一出就是大 case。一般常见于,举个例子,消费端每次消费之后要写 mysql,结果 mysql 挂了,消费端 hang 那儿了,不动了;或者是消费端出了个什么岔子,导致消费速度极其慢。
问题剖析
关于这个事儿,我们一个一个来梳理吧,先假设一个场景,我们现在消费端出故障了,然后大量消息在 mq 里积压,现在出事故了,慌了。
大量消息在 mq 里积压了几个小时了还没解决
几千万条数据在 MQ 里积压了七八个小时,从下午 4 点多,积压到了晚上 11 点多。这个是我们真实遇到过的一个场景,确实是线上故障了,这个时候要不然就是修复 consumer 的问题,让它恢复消费速度,然后傻傻的等待几个小时消费完毕。这个肯定不能在面试的时候说吧。
一个消费者一秒是 1000 条,一秒 3 个消费者是 3000 条,一分钟就是 18 万条。所以如果你积压了几百万到上千万的数据,即使消费者恢复了,也需要大概 1 小时的时间才能恢复过来。
一般这个时候,只能临时紧急扩容了,具体操作步骤和思路如下:
- 先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
mq 中的消息过期失效了
假设你用的是 RabbitMQ,RabbtiMQ 是可以设置过期时间的,也就是 TTL。如果消息在 queue 中积压超过一定的时间就会被 RabbitMQ 给清理掉,这个数据就没了。那这就是第二个坑了。这就不是说数据会大量积压在 mq 里,而是大量的数据会直接搞丢。
这个情况下,就不是说要增加 consumer 消费积压的消息,因为实际上没啥积压,而是丢了大量的消息。我们可以采取一个方案,就是批量重导,这个我们之前线上也有类似的场景干过。就是大量积压的时候,我们当时就直接丢弃数据了,然后等过了高峰期以后,比如大家一起喝咖啡熬夜到晚上 12 点以后,用户都睡觉了。这个时候我们就开始写程序,将丢失的那批数据,写个临时程序,一点一点的查出来,然后重新灌入 mq 里面去,把白天丢的数据给他补回来。也只能是这样了。
假设 1 万个订单积压在 mq 里面,没有处理,其中 1000 个订单都丢了,你只能手动写程序把那 1000 个订单给查出来,手动发到 mq 里去再补一次。
mq 都快写满了
如果消息积压在 mq 里,你很长时间都没有处理掉,此时导致 mq 都快写满了,咋办?这个还有别的办法吗?没有,谁让你第一个方案执行的太慢了,你临时写程序,接入数据来消费,消费一个丢弃一个,都不要了,快速消费掉所有的消息。然后走第二个方案,到了晚上再补数据吧。
对于 RocketMQ,官方针对消息积压问题,提供了解决方案。
1. 提高消费并行度
大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。所以,应用必须要设置合理的并行度。如下有几种修改消费并行度的方法:
同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。提高单个 Consumer 的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax 实现。
2. 批量方式消费
某些业务流程如果支持批量方式消费,则可以很大程度上提高消费吞吐量,例如订单扣款类应用,一次处理一个订单耗时 1 s,一次处理 10 个订单可能也只耗时 2 s,这样即可大幅度提高消费的吞吐量,通过设置 consumer 的 consumeMessageBatchMaxSize 返个参数,默认是 1,即一次只消费一条消息,例如设置为 N,那么每次消费的消息数小于等于 N。
3. 跳过非重要消息
发生消息堆积时,如果消费速度一直追不上发送速度,如果业务对数据要求不高的话,可以选择丢弃不重要的消息。例如,当某个队列的消息数堆积到 100000 条以上,则尝试丢弃部分或全部消息,这样就可以快速追上发送消息的速度。示例代码如下:
public ConsumeConcurrentlyStatus consumeMessage(
List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
long offset = msgs.get(0).getQueueOffset();
String maxOffset =
msgs.get(0).getProperty(Message.PROPERTY_MAX_OFFSET);
long diff = Long.parseLong(maxOffset) - offset;
if (diff > 100000) {
// TODO 消息堆积情况的特殊处理
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
// TODO 正常消费过程
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
4. 优化每条消息消费过程
举例如下,某条消息的消费过程如下:
•根据消息从 DB 查询【数据 1】•根据消息从 DB 查询【数据 2】•复杂的业务计算•向 DB 插入【数据 3】•向 DB 插入【数据 4】
这条消息的消费过程中有 4 次与 DB 的 交互,如果按照每次 5ms 计算,那么总共耗时 20ms,假设业务计算耗时 5ms,那么总过耗时 25ms,所以如果能把 4 次 DB 交互优化为 2 次,那么总耗时就可以优化到 15ms,即总体性能提高了 40%。所以应用如果对时延敏感的话,可以把 DB 部署在 SSD 硬盘,相比于 SCSI 磁盘,前者的 RT 会小很多。
解决MQ下单消息重复消费幂等机制
发消息重复了,重试一次,但实际上成功了,又发了一次,
重复消费会带来的问题呢?如果消费者的业务逻辑是执行一个查询的逻辑,那么无论消费几次,这对于业务来说是没有太大的影响的,但如果消费者的业务逻辑是向数据库中插入一条数据,那么重复消费将会导致至少插入两条相同的数据,自然导致了数据的异常。
那么幂等是什么意思呢?幂等(idempotent、idempotence)实际上是一个数学与计算机学概念,在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同,通俗点说就是:同样的参数或者数据去调用同一个接口,无论重复调用多少次,总能保证数据的正确性,不能出错,这就是接口的幂等性。这里“数据的正确性”和具体的业务相关,不同的业务,对于幂等性的定义是不一样的。
基于幂等性的要求,我们需要改造业务处理逻辑,使得在重复消息的情况下也不会影响最终的结果。怎么改造呢?这得结合具体的业务来考虑:
- 如果一个业务是只读业务,或者是更新的业务,那么多次读取或者多次更新相同的数据基本上都没什么问题。
- 如果业务需要插入数据,但是插入的数据中有唯一key能够区分(比如订单id,或者生产者生成的token),那么业务逻辑就可以变成在插入前先查询这个唯一key是否在数据库中,如果消费方的业务表不需要存储这个key,那么消费方也可以单独建立一张唯一key表,插入唯一key表和插入业务表的sql逻辑一定要都在一个事务中,在插入前判断这个唯一key是否在数据库的唯一key表中,如果存在说明此前已经成功消费了这条消息,不再消费,否则就是没有成功消费,继续消费。
- 如果业务需要插入数据,但是插入的数据中没有唯一key能够区分,这种是无法完全避免因为多条重复的消息或者一条消息多次重复消费带来的问题。因此最好是让发送消息的同事向消息内容中添加一个唯一的字段,即使消费者方的业务不需要也没关系,因为这样就能的防止重复的消息和重复消费了。
- 上面通过数据库的方式来防止重复消费的都属于“强校验”类型,会一定程度上影响数据库性能,通常涉及到金钱的都需要强校验,如果不需要强校验,那么使用Redis来代替也行,比如生产者将id或者token作为key存入Redis,消费者消费时先判断是否存在id或者token,如果存在则消费,消费完毕之后消除key。很多的业务都不需要强校验,比如获取登陆短信验证码的时候,多发送两条,或者发送失败都没关系,我们都遇到过。
上面的都是通用的办法,但处理重复消费的问题,始终要根据具体业务来考虑自己的解决办法,比如我们公司有很多监听一张表的binlog日志然后将操作同步到另一张表上的场景,这种情况下,某些消费者直接将原始表的id作为同步表的id,这样插入的时候,如果id重复肯定是插入不了的,天然的就保证了消息的幂等性。但有时候,同步的表是使用的自己的自增id,此时就需要在插入之前通过其他唯一的业务字段判断此数据是否已被消费过,如果被消费过,则不执行插入。
Redis集群崩溃时如何保证秒杀系统高可用
第一步:设计高可用的Redis集群
在构建高可用的秒杀系统之前,我们需要首先确保Redis集群本身是高可用的。这可以通过以下几种方式来实现:
1. Redis主从复制
使用Redis的主从复制机制,将主节点的数据复制到多个从节点上。当主节点发生故障时,可以立即切换到一个从节点,确保数据的持久性和可用性。
# Redis主从配置示例
# 主节点配置
bind 127.0.0.1
port 6379
# 从节点配置
replicaof 127.0.0.1 6379
2. Redis Sentinel
Redis Sentinel是Redis官方提供的高可用解决方案,它可以监控Redis集群中的主从节点,并在主节点故障时自动选举新的主节点。
# Redis Sentinel配置示例
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
3. Redis Cluster
Redis Cluster是Redis的分布式解决方案,它将数据分片存储在多个节点上,并提供了自动数据迁移和故障转移功能。
# Redis Cluster配置示例
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-slave-validity-factor 10
选择适合您需求的高可用方案,并确保Redis集群的稳定性和可用性。
第二步:秒杀系统的高可用设计
一旦Redis集群高可用性得到保证,接下来我们将关注秒杀系统本身的高可用性设计。
1. 分布式架构
将秒杀系统设计成分布式架构,将请求分散到多个节点上。这可以通过负载均衡器(如Nginx或HAProxy)来实现,确保请求不会集中在单一节点上。
# Nginx负载均衡配置示例
http {
upstream backend {
server app1.example.com;
server app2.example.com;
server app3.example.com;
}
server {
listen 80;
location / {
proxy_pass http://backend;
}
}
}
2. 限流和排队
在秒杀活动开始时,可能会涌入大量请求。为了避免系统过载,可以实施请求限流和排队机制。使用Redis的有序集合(Sorted Set)来维护请求的排队顺序,并使用计数器来限制每秒的请求数量。
import redis
# 连接到Redis集群
redis_client = redis.StrictRedis(host='redis-cluster-ip', port=6379, db=0)
def handle_seckill_request(user_id):
# 检查请求是否超过限流阈值
if redis_client.incr('seckill_request_count') <= MAX_REQUEST_PER_SECOND:
# 将用户加入秒杀队列
redis_client.zadd('seckill_queue', {user_id: time.time()})
else:
# 返回请求失败信息
return "秒杀请求过多,请稍后重试"
3. 异步处理
将秒杀请求的处理过程异步化,将请求加入消息队列(如RabbitMQ或Kafka)中,然后由后台任务处理器来执行秒杀操作。这可以降低系统负载,提高响应速度。
# 将秒杀请求加入消息队列
def enqueue_seckill_request(user_id):
message_queue.push({'user_id': user_id})
# 后台任务处理器
def process_seckill_request():
while True:
request = message_queue.pop()
if request:
handle_seckill_request(request['user_id'])
第三步:应对Redis集群崩溃
即使我们已经采取了多种措施来确保Redis集群的高可用性,但仍然有可能发生Redis集群的崩溃。在这种情况下,我们需要采取措施来保证秒杀系统的高可用性。
1. 降级处理
当Redis集群崩溃时,可以采取降级处理策略,将秒杀系统切换到一个临时的、基于数据库的模式。这可以通过配置文件来实现,将数据库作为备用数据源。
比如:rocksDB可以记录操作的流水日志
# 配置文件中的Redis切换策略
if redis_cluster_available:
cache = RedisCache()
else:
cache = DatabaseCache()
2. 数据同步
在Redis集群恢复之后,需要将数据库中的数据同步回Redis集群,以确保数据的一致性。可以使用数据同步工具或自定义脚本来实现这一过程。
# 数据同步脚本示例
def sync_data_to_redis():
database_data = fetch_data_from_database()
for key, value in database_data.items():
redis_client.set(key, value)
Redis主从切换导致库存同步异常以及超卖问题
Redis的主从是异步同步的,redis的主从异步同步,假设某商品,主节点是100,从节点也是100,这是主节点减一成99,还没来得及同步,但这时候99的主节点挂了,另一个是100的节点成主节点了。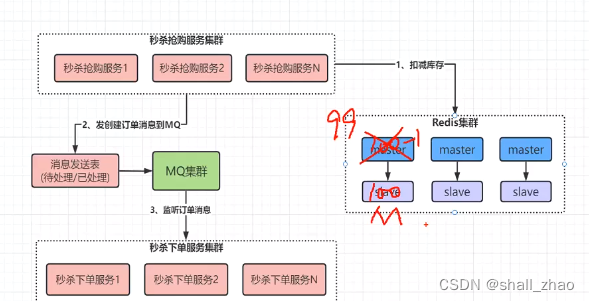
一般互联网公司不解决,但面试官非要问你,要解决怎么办?
——红锁
直接修改redis源码,让主从同步,不仅难度太大,而且性能下降
那么怎么办,我们不搞从节点,全部搞成主节点。
MQ集群崩溃时如何保证秒杀系统高可用
秒杀链路中Redis与MQ如何保证事务一致性
在当今互联网时代,秒杀活动成为了各大电商平台吸引用户的重要手段。然而,秒杀活动的高并发场景对系统的性能和稳定性提出了巨大的挑战。为了保证秒杀链路中的事务一致性,我们需要借助Redis和MQ这两个强大的工具。本文将详细介绍Redis与MQ如何保证事务一致性,并给出相应的代码demo。
一、秒杀链路中的事务一致性问题
在秒杀活动中,用户在短时间内涌入系统,同时抢购同一商品,这就会导致高并发的读写请求。而在传统的数据库事务中,由于数据库的读写锁机制,会导致性能瓶颈,无法满足秒杀活动的高并发需求。因此,我们需要寻找一种更高效的解决方案。
二、Redis的应用
Redis是一种高性能的NoSQL数据库,其特点是快速、可持久化、支持多种数据结构等。在秒杀链路中,我们可以利用Redis的原子操作和高速读写特性来保证事务的一致性。
商品库存的管理
在秒杀活动中,商品的库存是一个重要的指标。我们可以将每个商品的库存数量存储在Redis中,并利用Redis的原子操作实现库存的减少和增加。
示例代码:
# 初始化商品库存
redis.set('product:stock', 100)
# 减少库存
def decrease_stock():
stock = redis.get('product:stock')
if stock > 0:
redis.decr('product:stock')
return True
else:
return False
# 增加库存
def increase_stock():
redis.incr('product:stock')
1.用户购买记录的管理
为了防止用户重复购买同一商品,我们需要记录用户的购买信息。同样地,我们可以利用Redis的原子操作和高速读写特性来管理用户的购买记录。
示例代码:
# 记录用户购买记录
def record_purchase(user_id, product_id):
redis.sadd('user:%s:purchases' % user_id, product_id)
# 检查用户是否已购买过该商品
def check_purchase(user_id, product_id):
return redis.sismember('user:%s:purchases' % user_id, product_id)
三、MQ的应用
MQ(消息队列)是一种高效的异步通信机制,可以实现不同服务之间的解耦和削峰填谷。在秒杀链路中,我们可以利用MQ来异步处理订单的生成和支付等操作,从而保证事务的一致性。
订单生成
当用户成功秒杀到商品后,我们可以将生成订单的操作放入MQ中异步处理。这样可以减轻系统的压力,提高响应速度。
示例代码:
# 订单生成
def generate_order(user_id, product_id):
# 生成订单逻辑
...
# 将订单信息放入MQ中
mq.push('order', order_info)
2.订单支付
在用户生成订单后,我们可以将订单支付的操作放入MQ中异步处理。这样可以保证订单的支付和库存的减少是原子操作,从而保证事务的一致性。
示例代码:
# 订单支付
def pay_order(order_id):
# 订单支付逻辑
...
# 将支付结果放入MQ中
mq.push('pay', pay_result)
四、保证事务一致性的实现
通过Redis和MQ的应用,我们可以实现秒杀链路中的事务一致性。具体的实现步骤如下:
用户请求秒杀商品时,先检查用户是否已购买过该商品,如果已购买,则返回秒杀失败;
如果用户未购买过该商品,则先检查商品的库存是否大于0,如果大于0,则继续执行下一步;
从Redis中减少商品的库存,并记录用户的购买记录;
将生成订单的操作放入MQ中异步处理;
在订单生成的消费者中,处理订单的生成和支付操作,保证订单的支付和库存的减少是原子操作;
在订单支付的消费者中,处理订单的支付结果。
通过以上步骤,我们可以保证秒杀链路中的事务一致性,有效应对高并发场景下的性能和稳定性问题。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









