










推荐:
《亿级流量网站架构核心技术》张开涛
《重新定义Spring Cloud实战》
《Spring Cloud与Docker》周立
程序员DD博客 是《Spring Cloud微服务实战》作者
测试实战项目
spring-cloud-code/blob/master/README.md
微服务基础
性能:集群LB、分治、并行、异步、最终一致、缓存
保护:限流、隔离、池化、降级、熔断、幂等消费
性能:
集群:实现系统/服务吞吐量TPS和消费能力的动态伸缩,提高整个系统的并行计算能力。例如同一个服务注册多个进程节点,形成一个服务集群,RPC框架通过软负载均衡调用服务节点,提高单个服务的整体消费能力。Nginx也可以在更顶层做同样的工作。
分治:无论是集群/服务拆分,都是把大流量分散到不同节点消费,相当于分流治理。
并行异步:通过异步/定时任务并行处理业务/响应请求,IO/Tomcat线程只负责接收/投递请求任务而不执行业务代码,所以不会被业务代码阻塞。这样可以提高单位时间接收请求的数量,避免请求/链接过多而阻塞,从而增加整个系统的吞吐量TPS。比如DDD中推荐的CQRS架构思想;CAP/BASE中提到的柔性状态,保证异步最终一致性;异步响应式模型。其实很多框架底层都是异步处理/响应思想,如:Netty、Dubbo、WebFlux、Nacos等等。说简单点就是我先把所有请求都接收进来放入队列,然后再多线程消费。队列是实现异步线程/进程切换的常用手段之一,JDK的线程池底层是阻塞队列,多进程间可以用MQ实现。
最终一致性:配合异步思想,异步/定时任务处理消费请求落库,保证数据最终的一致性。
缓存:浏览器静态资源、CDN、Nginx+Lua、Redis、JVM级、ES等等可以做多级缓存设计,空间换时间减少查询DB/IO/重复计算的开销。如果使用分布式缓存(Redis)可以让各个服务进程达到无状态化,使服务器增加、上下线更加灵活。
保护:
限流:对后端服务的整体保护的同时提高吞吐量,可以将无用/恶意/超负荷流量拒之门外,保护后端系统。可以在前端js、nginx、网关等位置执行限流。限流针对不同粒度不同配置。例如:1、总体限流保护整个系统;2、IP级限流防止恶意流量;3、秒杀场景针对每种商品放行极少量请求到后端;4、布隆过滤无效参数拒绝等等操作。
降级熔断:服务出错后有更加灵活的降级处理手段,同时为内部服务消费能力的动态调节提供友好支持。例如在服务器硬件资源有限时,部分冷门服务可以下线或减少做降级处理,增加核心业务服务,短时间内增加核心业务的消费能力。再如同一台服务器中可以配置大小服务组合。当大服务的业务量突增时,可以下线小服务,减少小服务对CPU、内存、IO的开销。
隔离、池化:防止某一个服务/API访问量大但是处理速度慢。将整个系统资源全部占用,导致其他服务/API无法正常工作。对服务/API做QPS/信号量/线程隔离。对系统资源做池化管理,如连接池、线程池等。复用资源,避免资源滥用。
幂等消费:避免重复消费,在任何系统中都是必须的。CAS、redis.setnx、乐观锁、悲观锁、分布式锁、主键冲突.....等。
场景:1、RPC调用超时报错/重试,但是服务提供方已执行完。2、MQ消费者成功消费,但是生产者/补偿者重发消息。
拆分原则
业务解耦、并发量、可否降级、数据耦合度、人员配置、开发进度/难易度等....进行拆分。拆分会随着业务的不断拓展而改变。
适合拆分:Mvc三层架构中的@Service层、公共服务、业务独立服务、需动态调节集群吞吐量的服务、可以降级服务、修改频繁服务
不适合拆分:不满足上边条件。如某个功能的子功能,与父功能耦合度过于复杂,且与其他业务服务没有交集的服务功能可以不拆分。
垂直拆分:以业务为标准。
水平拆分:以功能为标准。
微服务间数据跨库关联查询
https://blog.csdn.net/shanchahua123456/article/details/105976164
分布式服务不一致问题
服务A调用服务B,服务B成功执行后服务A失败回滚,此时一致性无法保证。
0 服务A异常处理,主动回调B
1 分布式事务
2 定时补偿机制
3 最终一致性。服务A不直接调用服务B,服务A成功后再通过MQ执行服务B的业务。
幂等性
服务B要保证幂等调用,避免服务A重复执行调用后,服务B多次消费。
幂等设计:防止重复消费。悲观锁检查、乐观锁检查、主键冲突等。推荐以组合方案的形式保证绝对幂等。
主键冲突:捕获异常。
悲观锁检查:分段锁Lock、Redis SetNx记录消息ID(原子性)。只为保证唯一线程执行,不阻塞线程。
乐观锁检查:update+where+状态/版本 判断影响行=0,或redis+lua完成cas操作。一定保证检查和执行是原子性的,避免并发问题。其还有一个重要作用是防止过期消息覆盖。例如:当前数据库中订单状态=2,而此消息的订单状态=1。说明消息已过期,此时就不应该再消费此消息了。
第三方调用
第三方系统调用更加复杂,因为可能无法控制第三方幂等消费,只能控制我方调用幂等执行。
例如:某第三方支付平台,支付结果通过异步回调方式通知的我方服务,且支持同一订单多次支付。假如我方支付信息已经推送到第三方支付系统支付成功,但是延迟返回回调通知给我方服务。用户暂时看到订单仍然是未支付状态,,但是实际上钱已经通过第三方支付平台转账,避免用户在回调通知返回前重复点击支付是有必要的。
方案1:增加中间状态"支付中",且使用双重检查分段锁保护,且回调时才释放锁。保证得到回调结果之前只能发送一次。状态修改/检查要在发起支付请求前完成,保证并发场景只有一次支付请求,也避免请求请求发送成功但是状态修改失败。存在问题:如果setnx成功但是支付请求可能没发出去,造成永久支付中状态。
支付API:
先通过第三方API查询Order支付情况。
if redis.setnx(orderid,v){ //非阻塞悲观锁。可以用数据库代替: update set state=1 where state=0 and id=@id 判断影响行。
try{
二次通过第三方API查询Order支付情况。
保证只有一个线程可以发起支付请求(orderid)。
}catch{
请求发起失败,删除悲观锁redis.del(orderid),再次开放支付。
}
}else{
return "支付中,稍后再试!"
}
异步回调API:
收到支付平台推送通知,根据orderid支付结果修改订单状态。
成功:更新订单状态。
失败:删除悲观锁redis.del(orderid),再次开放支付。
SpringCloud
Spring Cloud主要组件分工
消费者:
Rbbion:负载均衡,超时,重试
Hystrix:降级、熔断、依赖隔离、异步任务、请求合并
Feign:拟RPC接口调用,整合rbbion+hystrix
注册中心:
Eruka:AP分布式注册中心
网关:
路由、负载均衡、限流、降级熔断、缓存、反爬、安全认证、黑白名单、日志、降级
Zuul:基于Servlet实现的网关,整合rbbion+hystrix
Gateway:Netty异步IO网关整合rbbion+hystrix
配置中心:
Config:通过消息总线将配置文件的信息发放到各个服务。
调优
周立的《Spring Cloud与Docker》第2版 中单独一章总结了各个组件的调优、超时、重试配置。推荐参考调试。
优化springboot容器
在优化Cloud组件前,首先要保证springboot自身的吞吐量不是瓶颈,以Tomcat为例。
server.tomcat.max-connections=10000
server.tomcat.accept-count=10000
server.tomcat.max-threads=500
server.tomcat.min-spare-threads=100
server.tomcat.uri-encoding=UTF-8
Hystrix执行流程
Hystrix通过rxjava的window操作符实现的时间窗口计数
核心类:抽象类 HystrixCommand
HystrixCommand extends AbstractCommand
HystrixCommand需要子类重写其抽象方法【run()】或【getFallback()】。
抽象方法run()中实现核心业务逻辑。
getFallback()反射降级方法。
实现形式:
Fegin集成\@HystrixCommand 都是HystrixCommand的子类实现。
@HystrixCommand通过AOP动态代理获得JoinPoint。获得method、arg[]、@注解配置信息等,实例化HystrixCommand子类对象。
重要属性:
HystrixCommandKey ;
HystrixThreadPoolKey ;
HystrixThreadPool; 依赖隔离线程池。首次初始化后缓存到HystrixThreadPool.静态Map中,key=ThreadPoolKey。
HystrixCommandProperties 属性配置;
HystrixCircuitBreaker 断路器;
HystrixCommandMetrics metrics 统计; 内部HealthCounts通过rxjava.window实现滑动窗口计数
每次执行都实例化HystrixCommand子类对象。
实际执行时:
HystrixCommand.execute()->super.queue().get() ;
queue()中代码提交到线程池,返回Future.get()阻塞当前线程。
queue():Future 中最核心的代码:
final Future<R> delegate = toObservable().toBlocking().toFuture();
底层使用rxjava实现,被观察者Observable执行核心逻辑会回调观察者Observe对象的相应方法。
rxjava主要关注被观察者注册绑定观察者代码,再倒推执行方法
toObservable():Observable 创建rxjava被观察者
Observable.defer(Callable):Observable
->call():Observable
->applyHystrixSemantics():Observable 注册被观察者
->circuitBreaker.allowRequest():boolean 判断【断路器】熔断状态
->executionSemaphore.tryAcquire():boolean 信号量模式判断
->executeCommandAndObserve():Observable
->executeCommandWithSpecifiedIsolation(hystrixCommand.this):Observable 依赖隔离执行方法
.lift(new HystrixObservableTimeoutOperator<R>(_cmd)); 如果有配置Hystrix超时,为Observable添加超时处理者
if 隔离策略=THREAD {
Observable.defer( Callable->call()
->统计计数工作
metrics.markCommandStart(commandKey, threadPoolKey,..) HealthCounts通过rxjava.window实现时间窗口计数
HystrixCounters.incrementGlobalConcurrentThreads();
threadPool.markThreadExecution();
->HystrixCommandExecutionHook.onThreadStart(this)+onRunStart(this)+onExecutionStart(this)
->getUserExecutionObservable(this):Observable
->getExecutionObservable():Observable
... ->run() HystrixCommand子类对象重写的业务逻辑。
).doOnSubscribe(threadPool.getScheduler) 【线程隔离】被观察者切换线程执行,rxjava通过threadPool执行上面的defer任务,并绑定超时处理者。
:Observable 此处返回的Observable向上出栈,return到applyHystrixSemantics()
}else{
信号量
}
toFuture()->BlockingOperatorToFuture.toFuture->返回Future
为被观察者Observable注册一个观察者Observe对象,监听Observable回调onNext()\onCompleted()\onError()方法。
实例化一个Future,重写了Future.get->CountDownLatch.await实现线程阻塞。
被观察者Observable执行完成后回调观察者Observe.onCompleted()时,执行CountDownLatch.countDown唤醒被阻塞线程。
Hystrix-dashboard Turbine 多个同名线程池,在dashboard会合成一个显示,Pool Size是所有池总和
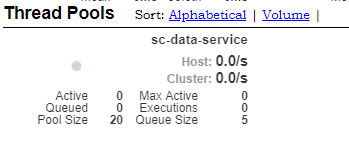
如图当前启动两个调用微服务,都有@FeignClient(name = "sc-data-service"),设置每个线程池默认大小是10,在dashboard只显示一个sc-data-service,但是Pool Size为两个服务中线程池总和。经测试实际使用中是JVM级别,各用各的互不干扰。Pool Size初始为0,会随着使用增长,但是不会超过服务设置的max值总和,因为线程池是jvm级别。
依赖隔离ThreadPool命名规则:
Feign:以他的name(serviceid)属性命名pool,一个FeignClient对应一个pool
Zuul:以serviceid命名pool,一个serviceid对应一个pool
Hystrix:可以配置ThreadPoolkey,其默认为ThreadPoolkey=GroupKey=类名。一个ThreadPoolkey对应一个pool。可以为类/方法单独制定ThreadPoolkey
图中是Hystrix_DashBoard界面,上面是CommandKey和熔断状态,下面是ThreadPoolkey和线程使用状态。
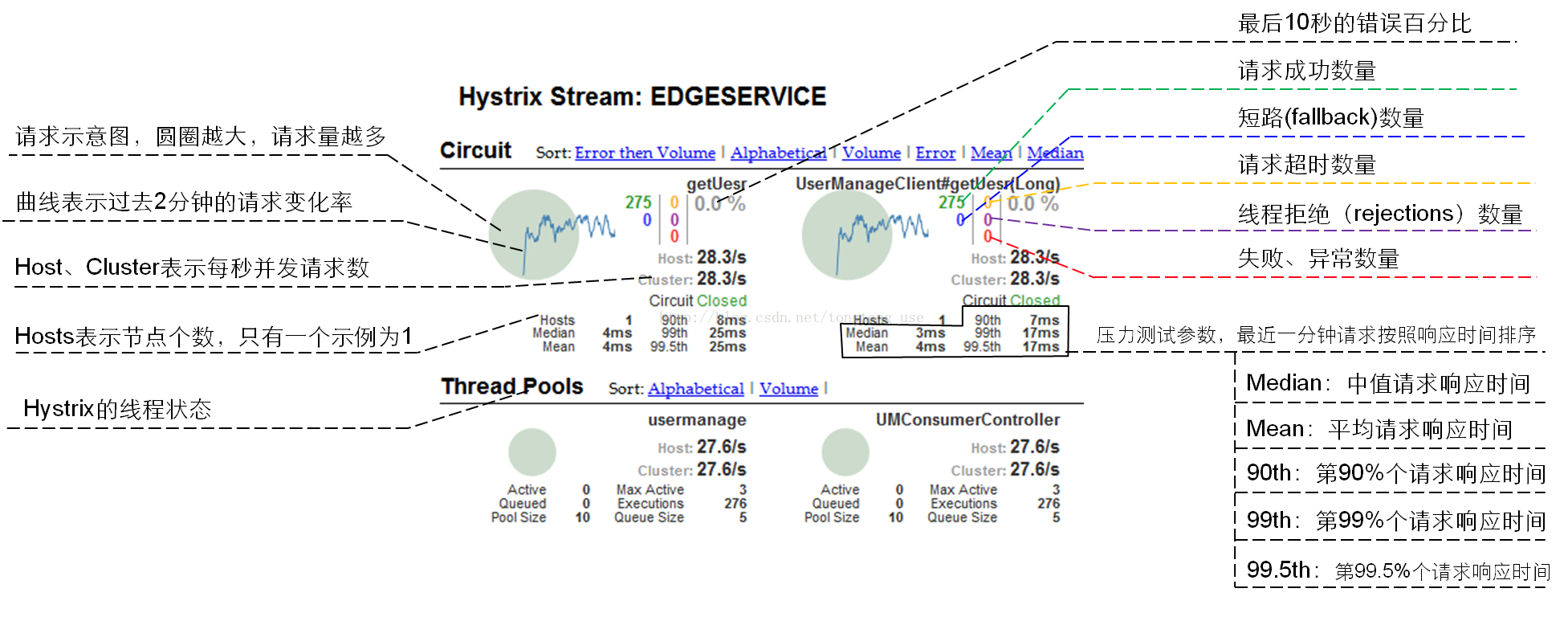
Feign、Zuul、Gateway集成了Ribbon和Hystrix
Feign:ServiceID = FeignClientName = RibbonClientName = ThreadPoolKey;
FeignClientName#methodName = CommandKey;
Zuul: ServiceID = RibbonClientName = ThreadPoolKey = CommandKey;
Gateway:ServiceID = RibbonClientName = ThreadPoolKey ;
CommandKey 可配置HystrixFilter args.name;
Feign、Zuul、Gateway都支持在springboot配置文件中(yml)直接对Ribbon、Hystrix的属性进行配置,从而改变重试、负载均衡、依赖隔离等相关配置。RibbonClientName、ThreadPoolKey、CommandKey是局部配置的关键(hystrix-dashboard上会显示各种hystrix-key的命名)。局部配置优先级高于全局配置。
Hystrix中每一个ThreadPoolKey代表一个线程池。线程池之间相互不影响,一个服务/方法流量大只会阻塞自己的线程池,不会影响其他服务。形成线程级别的依赖隔离。(还要注意外部容器Tomcat的线程、链接)
Hystrix配置项以command开头时用CommandKey,以threadpool开头时用ThreadPoolKey
Hystrix异常
1 HystrixRuntimeException ... could not be queued for execution Hystrix线程池已满
2 HystrixRuntimeException ... timed-out and no fallback available. 超时
Feign性能优化
并发:
并发控制:转发连接池的链接数、ribbon链接数、hystrix隔离限流;
思路:链接数调到足够大不要成为瓶颈,依赖隔离/限流交给hystrix配置。
配置项与下面zuul性能优化类似。
压缩:
#请求和响应GZIP压缩支持
feign.compression.request.enabled=true
feign.compression.response.enabled=true
#支持压缩的mime types
feign.compression.request.enabled=true
feign.compression.request.mime-types=text/xml,application/xml,application/json
feign.compression.request.min-request-size=2048
Feign要配置http连接池
默认是HTTPURLConnection,每次调用都创建新的连接,并发量大时会将服务提供端主机连接占满。
feign.httpclient.enabled=true 或 feign.okhttp.enabled=true。增加相应的Maven依赖。
推荐okhttp:FeignRibbonClientAutoConfiguration ---> OkHttpFeignLoadBalancedConfiguration配置类中用到以下参数创建连接池和客户端。
feign.okhttp.enabled=true
feign.httpclient.max-connections=200 # 默认值。okhttp链接池最大链接数。
feign.httpclient.max-connections-per-route=50 # 默认值 。 okhttp链接池每个url的最大同时链接数。
Feign源码
默认配置:
FeignAutoConfiguration:配置Feign上下文(FeignContext)、配置Targeter、配置Client(仅仅组件)
FeignClientsConfiguration:Decoder、Encoder、Retryer(Fegin重试)、Contract(SpringMvcContract)、FeignBuilder
FeignRibbonClientAutoConfiguration:Request Options(超时配置)、配置Client(带负载均衡)
Feign的调用过程 :
DefaultTargeter生成代理:
FeignInvocationHandler#invoke 动态代理获得method\args[]...
->SynchronousMethodHandler#invoke(args);
【Retryer决定Feign是否重试】
->buildTemplateFromArgs.create(args):RequestTemplate 通过args[]创建RequestTemplate
->遍历RequestInterceptor#apply(template) 执行请求拦截器,处理RequestTemplate
->生成request
->LoadBalancerFeignClient#execute(request) ribbon负载均衡
->lbClient(clientName):FeignLoadBalancer 选出负载均衡Client
->FeignLoadBalancer#executeWithLoadBalancer(request)
->buildLoadBalancerCommand(request..) 创建请求命令
->LoadBalancerCommand#submit(operation)
->retryHandler#getMaxRetrysSame()、getMaxRetrysNext()
->selectServer():Server 负载均衡选择Server
->operation#call(server)
->reconstructURIWithServer(...) 替换Url中IP
->FeignLoadBalancer.execute(request)
读取RibbonProperties超时配置,发送请求,返回Response
HystrixTargeter生成带熔断功能代理:
HystrixInvocationHandler#invoke(method,args); 动态代理获得method\args[]...
->new HystrixCommand(){
->重写run()
->dispatch#get(method):MethodHandler
->SynchronousMethodHandler#invoke(args);
剩余步骤与上面相同。
->重写getFallback()
}匿名子类
Feign集成Hystrix后,对单个方法做依赖隔离
https://www.jianshu.com/p/e346874542f6
https://www.cnblogs.com/trust-freedom/p/9956427.html
Hystrix 各种key,这些key用于配置属性:
CommandKey :默认是方法名。
GroupKey:默认是类名。
ThreadPoolKey:线程池key,默认是GroupKey(类名)。@FeignClient默认是name属性。
针对 CommandKey = EchoService#echo1(String) 做个性化依赖隔离。
@FeignClient(name = "demo-provider")
public interface EchoService {
@GetMapping(value = "/echo/{str}")
String echo(@PathVariable("str") String str);
@GetMapping(value = "/echo/{str}")
String echo1(@PathVariable("str") String str);
}# hystrix默认是关闭状态
feign.hystrix.enabled=true
# 每个threadPoolKey的默认配置
hystrix.threadpool.default.coreSize=20
hystrix.threadpool.default.maxQueueSize=20
# @FeignClient(name = "demo-provider")
# threadPoolKey=demo-provider 配置
hystrix.threadpool.demo-provider.coreSize=50
hystrix.threadpool.demo-provider.maxQueueSize=50
# 针对EchoService#echo1(String)方法配置自己的threadPoolKey线程池
hystrix.command.EchoService#echo1(String).threadPoolKeyOverride=ApithreadPool
# 为threadPoolKey=ApithreadPool的线程池配置规则
hystrix.threadpool.ApithreadPool.coreSize=1
hystrix.threadpool.ApithreadPool.maxQueueSize=1
-
threadPoolKey的默认值是groupKey,而groupKey默认值是@HystrixCommand标注的方法所在类名
-
可以通过在类上加@DefaultProperties( threadPoolKey="xxx" )设置默认的threadPoolKey
-
可以通过@HystrixCommand( threadPoolKey="xxx" ) 指定当前HystrixCommand实例的threadPoolKey
-
threadPoolKey用于从线程池缓存中获取线程池 和 初始化创建线程池,由于默认以groupKey即类名为threadPoolKey,那么默认所有在一个类中的HystrixCommand共用一个线程池
-
动态配置线程池 -- 可以通过
hystrix.command.HystrixCommandKey.threadPoolKeyOverride=线程池key动态设置threadPoolKey,对应的HystrixCommand所使用的线程池也会重新创建,还可以继续通过hystrix.threadpool.HystrixThreadPoolKey.coreSize=n和hystrix.threadpool.HystrixThreadPoolKey.maximumSize=n动态设置线程池大小
注意: 通过threadPoolKeyOverride动态修改threadPoolKey之后,hystrixCommand会使用新的threadPool,但是老的线程池还会一直存在,并没有触发shutdown的机制
禁止单个FeignClient使用hystrix
// Configuration1表示feign的自定义配置类
@FeignClient(name = "microservice-provider-user", configuration = Configuration1.class)//@Configuration 不能使用@Configuration,否则会变成全局配置
public class Configuration1 {
//禁用当前配置的hystrix,局部禁用
@Bean
@Scope("prototype")
public Feign.Builder feignBuilder() {
//默认是HystrixFeign.builder()
return Feign.builder();
}
}Feign 和 Ribbon 重试冲突 (个别版本)
默认Feign是关闭重试的,FeignClientsConfiguration配置了Retryer.NEVER_RETRY的bean。
Feign 和 Ribbon重试,其实二者的重试机制相互独立。如果一个http请求,如果feign和ribbon都配置了重试机制,请求总次数 n (计算公式)为Feign 和 Ribbon 配置参数的笛卡尔积。Feign最外层用自己的Retryer循环,调用ribbon的loadbalancer。
计算公式:n(请求总次数)=Feign(默认5次) * ((ribbon.MaxAutoRetries+1) +(ribbon.MaxAutoRetriesNextServer+1))
注意:+1是代表ribbon本身默认的请求
建议关闭Feign自身的重试机制,只使用Ribbon。Ribbon的重试机制默认配置为0,也就是默认是关闭重试机制的。
ribbon.OkToRetryOnAllOperations 默认是false,表示只重试get请求。
spring:
cloud:
loadbalancer:
retry:
enabled: true
#全局配置
ribbon:
ReadTimeout: 1000
ConnectTimeout: 1000
MaxAutoRetries: 0
MaxAutoRetriesNextServer: 0 #如果服务注册列表小于 nextServer count 那么会循环请求 A > B > A
OkToRetryOnAllOperations: false
#局部配置
feign-client1:
ribbon:
ReadTimeout: 1000
ConnectTimeout: 1000feign全局取消重试 (默认)
@Bean
Retryer feignRetryer() {
return Retryer.NEVER_RETRY;
}NEVER_RETRY的源码核心是将异常抛出,这样feign就不会进行while循环掉用了。
Hystrix熔断时间应该不小于ribbon的首次+重试次数时间之和。
Ribbon关键组件
ServerList:可以响应客户端的特定服务的服务器列表。
ServerListFilter:可以动态获得的具有所需特征的候选服务器列表的过滤器。
ServerListUpdater:用于执行动态服务器列表更新。
Rule:负载均衡策略,用于确定从服务器列表返回哪个服务器。
Ping:客户端用于快速检查服务器当时是否处于活动状态。
LoadBalancer:负载均衡器,负责负载均衡调度的管理。 消费端每个service对应一个LoadBalancer,保存着serviceid、ip等信息。
服务下线后依然被调用
- Ribbon 有个刷新时间,默认是 30s。会调用
ServerList#getUpdatedListOfServers方法获取实例,可以通过ribbon.ServerListRefreshInterval=ms配置刷新时间 - 服务下线前调用 /actuator/service-registry?status=DOWN 先下线实例,然后等待下一次服务实例的刷新确保不会拿到下线的实例
Ribbon执行流程
图片来源自网络:https://zhuanlan.zhihu.com/p/31744266
RestTemplate发起请求:
LoadBalancerInterceptor拦截请求:
请求URL.host->ServiceId->LoadBalancer.execute负载均衡器->IRule.choose(key)
->ServerList(定时从注册中心同步)->返回Server->用Server.ip替换请求中的ServiceId
Feign传递List/Map 要在参数上加@RequestBody且用post请求
直接传递会反序列化失败。 jackson(默认)自动序列化为json格式。
@RequestParam是url中参数。@RequestBody是请求体中json反序列化所得。
下面是服务提供方样例
//服务端样例
@PostMapping(value = "/sendmap}")
@ResponseBody
public Map sendMap(@RequestBody Map map){
//feign默认将map放在body中,要使用@RequestBody取map
//把收到的map以json返回Feign调用方
return map;
}
@PostMapping(value = "/sendlist")
@ResponseBody
public List sendList(@RequestBody List<String> list){
//把收到的list以json返回Feign调用方
return list;
}
@PostMapping(value = "/sendlistparam")
@ResponseBody
public List sendListParam( @RequestParam("id") String id, @RequestBody List<String> list){
list.add(id);
return list;
}
Feign传递多个自定义/容器类型对象
@RequestParam是url中参数。@RequestBody是请求体中json反序列化所得。
经测试 多@RequestParam+多对象 会抛出异常。且@RequestBody对应request.body只能有一个。
方案一:把所有对象都封装到一个类对象中用@RequestBody传递过来。但是每一种传递都要涉及一个单独类型作为传递对象
方案二: 将所有内容保存到Map<String,Object>中,被调用方需要从map中按key取出value。
但是value的泛型时Object, jackson会把value解析为Map而非原始类型。所以需要对value做类型转换。
下面是将value-Map先转化为jsonString,再把jsonString转为目标类型对象。
此方案比较灵活,但是因为增加了类型转化,性能有损失。
下面是方案二的被调用方样例
//服务端样例
/**
* feign将map放在request.body中,要使用@RequestBody取得map
* 因为只能有一个@RequestBody,所以feign传递多个/种复杂对象参数时可用Map<String,Object>或是封装到一个自定义类里。
* 传过来的value类型会解析为LinkHashMap
* 可以通过ObjectMapper转换为所需类型,但是这样就多了N次转换开销影响性能。
* @param map 测试map中包含: 自定义类型UserInfo + List<Integer> + String 等多种不同类型的对象
* @return
* @throws IOException
*/
@PostMapping(value = "/sendmap}")
@ResponseBody
public Map sendMap(@RequestBody Map map) throws IOException {
//feign将map放在request.body中,要使用@RequestBody取得map
Object user = map.get("user");
//传过来的UserInfo user其类型变为LinkHashMap (user.getClass())
//jackson转换类型
ObjectMapper objectMapper = new ObjectMapper();
//jackson转换UserInfo,其必有无参构造器
UserInfo userInfo = objectMapper.readValue(objectMapper.writeValueAsString(user), UserInfo.class);
//readValue不支持泛型类型。可以通过引用变量增加泛型,其会延迟到使用时才检查类型
List<Integer> list = objectMapper.readValue(objectMapper.writeValueAsString(map.get("list")), ArrayList.class);
//二次解析后的value
System.out.println(userInfo);
System.out.println(list);
map.put("username",userInfo.getName());
return map;
}
Feign的fallback要有对应类型的bean
Spring Cloud Feign/RestTemplate组件发http请求,无请求头head内容,需要拦截器填充
服务调用方可以添加Feign或RestTemplate发送拦截器,分别实现RequestInterceptor或ClientHttpRequestInterceptor。拦截器在调用方发出http请求时拦截,此时可以为Feign/RestTemplate调用的http请求添加head信息,再发送到下游服务提供方。
RestTemplate响应内容支持泛型解析
请求返回值解析为Response<MemberList>
String request="{ \"cursor\": "+cursor+",\"size\": "+size+"}";
ParameterizedTypeReference<Response<MemberList>> typeRef = new ParameterizedTypeReference<Response<MemberList>>() {};
ResponseEntity<Response<MemberList>> responseEntity = restTemplate.exchange(url, HttpMethod.POST, new HttpEntity<>(request), typeRef);
Response<MemberList> memberList= responseEntity.getBody();
出现unknowHostException异常
需要在被调用的服务方添加一个配置信息:eureka.instance.prefer-ip-address=true
hystrix启动线程隔离后,ThreadLocal会受影响。
在涉及到hystrix线程尽量避免使用ThreadLocal或将ThreadLocal作为请求传参传递。
使用信号量模式,或是ConcurrencyStrategy解决
@HystrixCommand标注的方法在指定时间内没有执行完就会降级
计算Hystrix线程池数量和响应超时
公式:线程数= 消费者每秒一共发送多少请求数 / 单个线程每秒处理请求数 +缓冲线程数
缓冲线程 为处理不确定因素,比如:网络消耗、某个请求用时过长
响应超时:要依据平均请求处理时间,且Hystrix的超时不小于rbbion的 超时*重试次数总用时。否则不会触发重试,直接服务降级。
多维度限流
实际项目中,除以上实现的限流方式,还可能会:
一、在上文的基础上,增加配置项,控制每个路由的限流指标,并实现动态刷新,从而实现更加灵活的管理。
二、实现不同维度的限流,例如:
- 对请求的目标 URL 进行限流(例如:某个 URL 每分钟只允许调用多少次)
- 对客户端的访问 IP 进行限流(例如:某个 IP 每分钟只允许请求多少次)
- 对某些特定用户或者用户组进行限流(例如:非 VIP 用户限制每分钟只允许调用 100 次某个 API 等)
- 多维度混合的限流。此时,就需要实现一些限流规则的编排机制(与、或、非等关系)
网关认证鉴权思路
方案一:
网关全局过滤器拦截请求request。调用后端用户/权限微服务,通过URI查询此请求所需权限(A)。通过head/cookies/session取得用户信息/token,token验证需有效性等。通过用户信息(id/name)查询其拥有的权限(B),A与B比较是否匹配。若请求量较大推荐uri/user权限信息转移到cache中查询。
网关/fegin转发请求时可以把用户权限信息放入转发请求head,下游服务可以直接通过请求head查看用户权限/角色信息。
spring-session共享案例:
https://segmentfault.com/a/1190000014204992
https://www.cnblogs.com/nukill/p/11853591.html
https://www.cnblogs.com/carrychan/p/9548013.html
方案二:JWT
简单案例:https://www.jianshu.com/p/cf9ad8c3621d
思路:用户认证登录后发放jwt给前端,前端请求要携带jwt。后端服务只返回错误码(认证失败、鉴权失败...),由前端根据错误码执行路由跳转。JWT是通过加/解密来取得token信息,所以服务端可以不存储token信息。
auth-service服务负责登录认证、JWT的发放(可注册多个auth-service微服务分担压力、避免单点故障),JWT中可以携带用户信息、角色、权限。用户发送的http请求header中携带JWT。
网关解析JWT失败,直接返回认证失败错误码。前端识别错误码后,前端控制跳转到/login,由auth-service处理登录认证并发放JWT。前端缓存JWT信息。
网关解析JWT成功则将关键信息(用户信息、角色、权限)放到http-head中转发给下游对应服务。此操作增加的传输消耗,但是减少各个微服务多次解密token的消耗。下游服务通过拦截器、AOP完成检查用户拥有的角色和权限,完成鉴权。没有所需权限则返回鉴权失败错误码。
重复解决跨域问题
例子:https://blog.csdn.net/zhenghongcs/article/details/103856096
若在网关做了允许跨域配置后,应删除下游服务的跨域配置。只保留一个跨域配置。
网关部署


Zuul过滤器生命周期

Zuul性能优化
推荐文章:
SpringCloud从入门到进阶(九)——单点部署Zuul的压力测试与调优
并发控制:容器(tomcat)链接/线程数、转发连接池(zuul.host)、ribbon链接数控制、hystrix隔离限流;
思路:链接数调到足够大不要成为瓶颈,依赖隔离/限流交给hystrix配置。
ribbon.MaxConnectionsPerHost #单个后端微服务实例IP:PORT(一个jvm)能发起的最大请求并发数(单体限制)
ribbon.MaxTotalConnections #允许最大连接数,即所有后端微服务实例请求并发数之和的最大值。(整体限制)建议:
1、可以切换成Undertow。比tomcat的吞吐量更高。
2、禁用FormBodyWrapperFilter,因为此过滤器底层用同步锁。不过禁用后会导致application/x-www-form-urlencoded的请求无法正确识别。
zuul.FormBodyWrapperFilter.pre.disable = true3、以下是优化配置:
zuul.host.connect-timeout-millis: 65000
zuul.host.socket-timeout-millis: 65000
#zuul.host.maxTotalConnections与zuul.host.maxPerRouteConnections这两个参数在使用Service ID配置Zuul的路由规则时无效,只适用于指定微服务的url配置路由的情景。
zuul.host.max-per-route-connections: 1000 #zuul每个路由的最大请求转发并发数(单体限制)
zuul.host.max-total-connections: 1000 #zuul所有路由的最大请求转发并发数 (整体限制)
#ribbon.MaxConnectionsPerHost、ribbon.MaxTotalConnections 适用于使用Service ID配置Zuul的路由规则
ribbon.MaxConnectionsPerHost: 1000 #ribbon单个后端微服务实例IP:PORT(一个jvm)能发起的最大请求并发数(单体限制)
ribbon.MaxTotalConnections: 1000 #ribbon允许最大连接数,即所有后端微服务实例请求并发数之和的最大值。(整体限制)4、配置为线程池隔离,默认以ServiceId做ThreadPoolKey。
Zuul RequestContext 主要作用
1 向下游过滤器传递参数
2 为转发http添加请求头/体
3 终止转发http到服务端
3 填充返回http
Spring Cloud Zuul转发http默认转发部分head,RequestContext可将有用信息加入请求头(如用户真实IP)
a.zuul转发时注意敏感头设置
zuul转发时注意敏感头设置,application.properties文件中添加 zuul.sensitive-headers= 。 sensitiveHeaders的默认值初始值是"Cookie", "Set-Cookie", "Authorization"这三项,可以看到Cookie被列为了敏感信息,所以不会放到新http-head中转发
b.zuul网关添加过滤器,把真实IP放入请求头head中转发:
import javax.servlet.http.HttpServletRequest;
import org.springframework.stereotype.Component;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
@Component
public class XForwardedForFilter extends ZuulFilter {
private static final String HTTP_X_FORWARDED_FOR = "HTTP_X_FORWARDED_FOR";
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
String remoteAddr = request.getRemoteAddr();
//两种方法都可以 为转发的http请求添加head信息
ctx.getZuulRequestHeaders().put(HTTP_X_FORWARDED_FOR, remoteAddr);
ctx.addZuulRequestHeader("USER_HEADER", "USER_HEADER");
return null;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
}
收到转发的微服务获取ip:
String ip = request.getHeader("HTTP_X_FORWARDED_FOR");Zuul过滤器之间传递信息
见上边代码,zuul过滤器之间不能通过参数传递信息,但是提供了 RequestContext类通过ThreadLocal来传递信息。
requestContext.set("startTime", System.currentTimeMillis());zuul个从 接收用户请求+过滤+转发到微服务+接收微服务响应信息+返回给用户,这整个过程中每个请求对应同一个的线程完成。所以ThreadLocal可以完整的串联整个接收转发响应的全部生命周期。
Zuul终止过滤转发
//禁止http向其他服务转发,但是依然会向下执行过滤器
requestContext .setSendZuulResponse(false);
requestContext .setResponeseBody("{\"status\":500,\"messgae\":\"需登录!\"}");
//向下游Filter传递信息
//下游Filter在shouldFilter()通过login值判断是否需要过滤
requestContext .set("login",false);
Zuul统一异常处理
https://www.cnblogs.com/duanxz/p/7543040.html
Zuul+SpringSecurty 验证用户登录简单案例
将认证用户的相关信息放入header中, 后端服务可以直接读取使用
@Component
public class UserInfoHeaderFilter extends ZuulFilter {
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
return FORM_BODY_WRAPPER_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
RequestContext ctx = RequestContext.getCurrentContext();
//判断上游Filter传递信息
return (boolean ) ctx.get("login");
}
@Override
public Object run() {
//取出Authentication
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
RequestContext ctx = RequestContext.getCurrentContext();
//验证不为空 且 不是匿名authentication
if (authentication != null && !(authentication instanceof AnonymousAuthenticationToken)) {
Object principal = authentication.getPrincipal();
String userInfo;
if (principal instanceof SysUser) {
SysUser user = (SysUser) principal;
userInfo = user.getUsername();
} else {
//jwt的token只有name
userInfo = authentication.getName();
}
//将认证用户的相关信息放入header中, 后端服务可以直接读取使用
ctx.addZuulRequestHeader(SecurityConstants.USER_HEADER, userInfo);
ctx.addZuulRequestHeader(SecurityConstants.ROLE_HEADER, CollectionUtil.join(authentication.getAuthorities(), ","));
}
else{
//禁止路由转发
ctx.setSendZuulResponse(false);
ctx.setResponeseBody("{\"status\":500,\"messgae\":\"需登录!\"}");
//向下游Filter传递信息
ctx.set("login",false);
}
return null;
}
}Gateway
1 在启用通过注册中心serviceId转发请求到微服务时,请求uri:gateway-ip/service-id/xxx/xx。
设置spring.cloud.gateway.discovery.locator.lowerCaseServiceId=true。
否则url中的serviceId必须是大写。
2
Gateway的全局异常处理
Spring Cloud Gateway中的全局异常处理不能直接用@ControllerAdvice来处理。Finchley版本的Gateway,使用WebFlux形式作为底层框架,而不是Servlet容器,所以常规的异常处理无法使用。通过继承DefaultErrorWebExceptionHandler实现统一异常处理。
网关都是给接口做代理转发的,后端对应的都是REST API,返回数据格式都是JSON。如果不做处理,当发生异常时,Gateway默认给出的错误信息是html页面,不方便前端进行异常处理。
https://blog.csdn.net/u010889990/article/details/82963682
Gateway过滤器
https://windmt.com/2018/05/08/spring-cloud-14-spring-cloud-gateway-filter/
1 GatewayFilter 普通过滤器,需要为URL配置此过滤器。
2 全局过滤器,默认为所有URL过滤
Gateway内置redis限流
https://windmt.com/2018/05/09/spring-cloud-15-spring-cloud-gateway-ratelimiter/
1内置redis限流RequestRateLimiter
2 基于Actuator 实现cpu负载限流
Gateway动态路由
1 基于配置中心修改配置
2 基于DB\REDIS
https://windmt.com/2019/01/20/spring-cloud-20-gateway-dynamic-routing/
3 基于restapi
http://springcloud.cn/view/407
4 Spring Boot Admin 或 Gateway提供的Actuator接口
https://www.jianshu.com/p/8f007bcf36ea
服务优雅下线 /actuator/service-registry
management:
endpoints:
web:
exposure:
include: service-registry 发送POST请求到/actuator/service-registry 端点。该应用在Eureka Server上的状被标记为DOWN ,但是应用本身其实依然是可以正常对外服务的。
Spring Cloud Config 服务端修改端口
默认端口8888,若想修改端口必须放在bootstrap.yml中,否则无效。bootstrap是boot就先加载的配置文件
Eureka 特点
优点:AP原则,开箱即用
缺点:基于内存存储,客户端上报完整信息内存浪费,
单一调度更新,大量客户端轮询更新服务端,服务端压力较大
eureka集群间广播复制,服务端压力较大

获得服务列表
在SpringCloud框架下通过DiscoveryClient可以获得服务列表信息(服务ID、主机IP等)
import org.springframework.cloud.client.discovery.DiscoveryClient;
@Autowired
private DiscoveryClient discoveryClient;
public void getServiceInstance(){
List<String> services = discoveryClient.getServices();
List<ServiceInstance> serviceInstance = discoveryClient.getInstances("serviceid");
}Spring Cloud Sidecar整合异构服务
案例:https://www.jianshu.com/p/2788b7220407
Sidecar边车模式,可以将非spring cloud或非jvm的restful项目直接集成到spring cloud项目中。Cloud Sidecar服务为异构服务做代理功能,由Sidecar服务为被整合的异构服务提供服务注册、负载均衡、限流熔断功能,而被代理的异构restful服务几乎不用修改,只需要为Sidecar服务提供几个固定API即可接入到spring cloud项目中来。
边车模式也是servicemesh的核心思想之一,即业务服务项目只关心业务逻辑,与服务治理相关功能完全解耦。而服务注册发现、调用、监控、流控等服务治理的相关功能都由Sidecar代理服务项目实现。
Nginx错误日志502
//nginx/error.log
upstream sent invalid chunked response while reading upstream, client: xx.xx.xx.xxx, server:
nginx使用了http1.0协议从后端返回响应体的, 但是http1.0不支持keeplive, 因此需要配置。
proxy_http_version 1.1;
proxy_set_header Connection "";
幂等消费
超时调用后重试保证幂等。首要前提消息要有唯一标示。
a.根据ID判断是否重复消费(可以用Redis+lua保证原子性的判断更新)
b.多次重复执行,结果一致
c.利用数据库主键/唯一键冲突
d.update+where 条件乐观锁执行
e.Lock双重检查锁














 2577
2577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









