










新的开发语言如雨后春笋般涌现,比如 Mozilla 的 Rust、Apple 的 Swift 以及 Jetbrains 的 Kotlin 等等,当然很多好的语言也在不断迭代,比如 Java。这些语言为开发人员在开发速度、安全性、便利性、可移植性和功能上提供了多种选择。
这几年编程语言的发展速度为什么这么快?我觉得其中一个重要原因,就是我们具备了构建语言尤其是 编译器的新工具,其中首屈一指的就是 LLVM(Low-Level Virtual Machine)。LLVM 是一个开源项目,最初是由 Swift 语言创始人 Chris Lattner 以伊利诺伊大学的一个研究项目为基础发展而来。
LLVM 不仅简化了新语言的创建工作,而且提升了现有语言的发展。它提供了一种工具,自动化了创建语言任务中许多最吃力的部分,包括创建编译器、将输出代码移植到多个平台和架构上,以及编写代码实现异常处理这样的常见语言隐喻(metaphor)。LLVM 是自由许可的,这意味着它可作为软件组件自由重用,也可以作为服务自由部署。
如果列出一份使用了 LLVM 的语言清单,我们能从中看到许多耳熟能详的名字。例如,Apple 的 Swift 语言使用 LLVM 作为编译器框架,Rust 使用 LLVM 作为工具链的核心组件。此外,很多编译器也提供了 LLVM 版本。例如,Clang 这个 C/C++ 编译器本身就是一个以 LLVM 为准绳的项目。还有 Kotlin,它名义上是一种 JVM 语言,使用称为 Kotlin Native 的语言开发,该语言也使用了 LLVM 编译机器原生代码。
LLVM 简介
LLVM 本质上是一个使用编程方式创建机器原生代码的软件库。开发人员调用其 API,生成一种使用“中间表示”(IR,Intermediate Representation)格式的指令。进而,LLVM 将 IR 编译为独立软件库,或者使用另一种语言的上下文(例如,使用该语言的编译器)对代码执行 JIT(即时,just-in-time)编译。
LLVM API 提供了一些原语,用于表示开发编程语言中常见结构和模式。例如,几乎所有的语言都具有函数和全局变量的概念。LLVM 也将函数和全局变量作为 IR 的标准元素。这样,开发人员可以直接使用 LLVM 的实现,并聚焦于自身语言中的独到之处,不再需要花费时间和精力去重造这些特定的轮子。
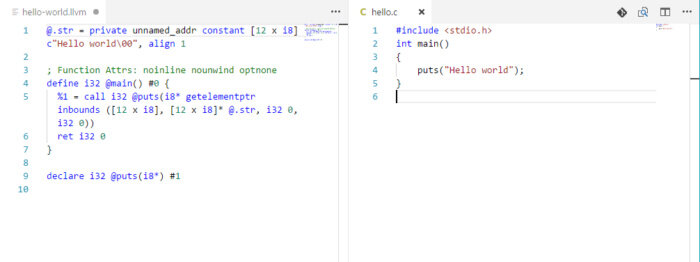
图 1 一个 LLVM IR 的例子。图右侧显示了一个使用 C 编写的简单程序,左侧显示了使用 Clang 编译器转换得到的 LLVM IR 代码
LLVM:为可移植性而设计
我们通常对 C 语言的认识,可套用到对 LLVM 的认识上。我们时常将 C 语言看成是一种可移植的高层汇编语言,因为 C 中提供了一些直接映射到系统硬件的结构,并已移植到近乎所有现有的系统架构上。但是作为一种可移植的汇编语言并非 C 语言的设计目标,这只是由该语言的工作机制所提供的一个副产品。
与此不同,LLVM IR 的设计从一开始,就是要成为一种可移植的汇编语言。IR 实现可移植性的方式之一,就是提供了独立于任何特定机器架构的原语。例如,整数类型可使用任何所需的位数,甚至大到 128 位整数,不会受限于机器的最大位宽度。开发人员也无需为匹配某种特定处理器的指令集,考虑如何对输出做精雕细琢。LLVM 解决了所有这一切。
如果读者想实地查看 LLVM IR 的运行情况,推荐访问 ELLCC 项目网站,并可动手在浏览器中尝试一个将 C 代码转换为 LLVM IR 的现场演示(文末有链接)。
在编程语言中使用 LLVM
LLVM 通常作为语言的 AOT(预先编译,ahead-of-time)编译器使用。此外,LLVM 还支持其它一些功能。
使用 LLVM 的 JIT 编译器
在一些情况下,需要代码在运行时直接生成,而不是做预先编译。例如,Julia 语言就对代码做 JIT 编译,因为它看重的是运行速度,并可通过 REPL(读取 - 求值 - 输出循环,read-eval-print loop)或交互式提示符与用户交互。.NET 的开源实现 Mono 也提供了选项,支持通过 LLVM 后端方式编译生成原生代码。
Python 的高性能科学计算库 Numba 将设定的 Python 函数 JIT 编译为机器代码,也可以对使用了 Numba 的代码做 AOT 编译。但是作为一种解释性语言,Python 与 Julia 一样也提供了快速开发。使用 JIT 编译代码,是对 Python 交互工作流的一种很好的补充,要优于使用 AOT 编译。
还有一些非正统的方法,也尝试使用 LLVM 作为 JIT。例如,有方法尝试编译 PostgreSQL 查询,并实现了性能翻五番。
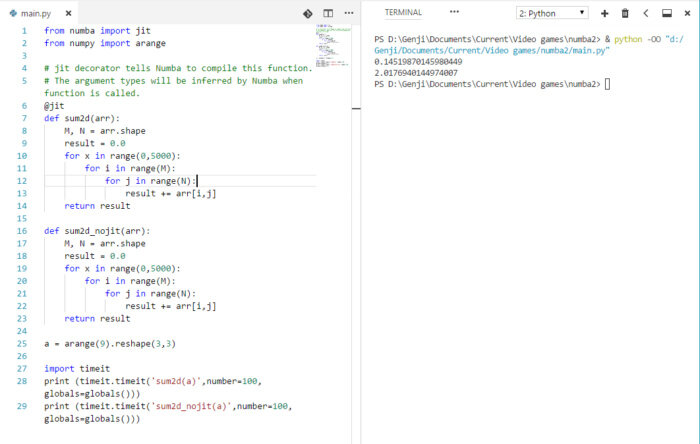
图 2 Numba 使用 LLVM 对科学计算代码做 JIT 编译,加速了代码的执行。例如,经 JIT 加速的 sum2d 函数, 要比常规 Python 代码的执行速度快 139 倍
使用 LLVM 做自动代码优化
LLVM 不仅将 IR 编译为原生机器代码,开发人员也可以通过编程方式,指导 LLVM 使用链接过程对代码做高度精细的优化。这种优化卓有成效,其中涉及内联函数、去除死代码(包括未使用的类型定义和函数参数)和循环展开(loop unrolling)等。
同样,LLVM 的强大之处在于无需开发人员自己去实现所有这些功能。LLVM 包揽了所有一切,而且开发人员可在需要时关闭这些功能。例如,如果我们考虑牺牲一些性能去给出更小的二进制文件,可以让编译器前端告知 LLVM 禁止循环展开。
使用 LLVM 的领域特定语言(DSL)
通常,LLVM 用于生成通用语言编译器。但是,LLVM 也可用于生成一些高度垂直或排他性 DSL。我们甚至可以说,这正是 LLVM 大显身手之处。因为在使用 LLVM 创建一种 DSL 时,无需亲历亲为创建语言中的大量苦差事,并可给出良好的表现。
例如,Emscripten 项目使用 LLVM IR,并将 IR 代码转化为 JavaScript。这将在理论上支持所有具有 LLVM 后端的语言导出可运行在浏览器中的代码。尽管 Emscripten 的长期计划是使用基于 LLVM 的后端生成 WebAssembly,但是该项目很好地展示了 LLVM 的灵活性。
另一种使用 LLVM 的方式,是将领域特定的扩展添加到现有的语言中。例如,Nvidia 使用 LLVM 创建了 Nvidia CUDA 编译器,实现在语言中添加对 CUDA 的原生支持,并作为所生成的原生代码的一部分做编译,而不是通过随之一起交付的软件库做调用。
在各种语言中使用 LLVM
LLVM 的通常使用方式,是编码在开发人员顺手的开发语言中。当然,该语言应支持 LLVM 软件库。
其中,广为采用的 C 和 C++。不少 LLVM 开发人员二者必取其一,理由是:
- LLVM 本事就是使用 C++ 编写的。
- LLVM 的 API 以 C/C++ 化身(incarnation)提供。
- 很多语言开发倾向于以 C/C++ 为基础。
当然,选择并不局限于这两种语言。不少语言支持原生地调用 C 软件库。因此在理论上讲,可以使用任何一种此类语言做 LLVM 开发。当然,如果语言本身就提供包装了 LLVM API 的软件库,这样最好。幸运的是,很多语言和运行时都具有这样的软件库,其中包括 C#/.NET/Mono、Rust、Haskell、OCAML、Node.js、Go 和 Python。
需要给出警告的是,部分语言对 LLVM 的绑定尚不完备。以 Python 为例。尽管 Python 提供了多种选择,但每种选择的完备性和实用性各有千秋:
- LLVM 项目本身就维护了一组到 LLVM C API 的绑定,但是目前为止已停止进一步的维护。
- llvmpy 在 2015 年后就停止维护了。这对于任何一个软件项目都不是一个好消息。考虑到每次 LLVM 修订版本中的更改数量,对于 LLVM 而言尤为如此。
- llvmlite 是 Numba 开发团队开发的。当前已成为在 Python 中使用 LLVM 的一个有力竞争者。但是 llvmlite 局限于针对 Numba 的需要,因此提供的功能只是 LLVM 用户所需功能的一个子集。
- llvmcpy 意在为 C 软件库提供最新的、可自动更新的 Python 绑定,支持使用 Python 的原生风格访问。llvmcpy 依然处于开发的早期阶段,但是已经可以使用 LLVM API 完成一些基本工作。
如果有兴趣了解如何使用 LLVM 软件库构建一种语言,可以阅读由 LLVM 创始人撰写的教程。该教程使用 C++ 和 OCAML,一步步引导读者去创建一个名为“Kaleidoscope”的简单语言。进而移植到其它语言中:
- Haskell:参考原始教程可直接移植。
- Python: 一种方式是严格遵守教程,另一种方式做了大量重写,并提供了交互式命令行。两种方式都使用 llvmlite 作为到 LLVM 的绑定。
- Rust 和 Swift:看上去,我们不可避免地要实现将教程语言移植到这两种由 LLVM 本身创建的语言上。
该教程还有其它一些国家语言的翻译版本,例如使用原始 C++ 和 Python 的中文教程。
LLVM 尚未实现的
我们上面介绍了 LLVM 提供的很多功能,下面简述一下它目前尚未实现的。
例如,LLVM 并不对语法做解析。因为有大量工具可用于完成这个工作,例如 lex/yacc、flex/bison 和 ANTLR。解析必定会从编译中脱离出来,因此毫不奇怪 LLVM 并未试图去实现该功能。
LLVM 也不直接解决大部分针对特定语言的软件文化。例如,如何安装编译器的二进制文件,如何在安装中管理软件包,如何升级工具链等,这都需要开发人员自己去做。
最后也是最重要的一点是,LLVM 仍然尚未对部分通用语言成分给出原语。许多语言都具有某种垃圾回收的内存管理方式,或者是作为管理内存的主要方式,或者是作为对 RAII(C ++ 和 Rust 使用)等策略的附属方式。LLVM 并没有提供垃圾收集机制,而是提供了一些实现垃圾回收的工具,支持将代码标记为一些可简化垃圾收集器编写的元数据。
但是,并不排除 LLVM 可能最终会添加实现垃圾回收的本地机制。LLVM 正在以每六个月发布一个主要版本的速度快速发展。鉴于当前许多语言的开发过程是以 LLVM 为中心的,所以 LLVM 的开发速度只可能会进一步提升。
基本介绍
在本专栏中我们将使用rust编写C语言的编译系统,包括编译器,链接器,汇编器,文章跟之前的风格一样,将项目分为独立的子模块,每篇文章对每个模块或者子功能进行讲述,编写代码之前会讲述所需要的理论知识
建立项目
Rust安装请看这里
建立一个项目需要用到Cargo,Cargo在安装Rust时就会安装
通过Cargo提供的命令很容易创建一个Rust项目
admin@admin:~: cargo new compiler--bin
Created binary (application) `compiler` package上面的命令意思是使用Cargo创建一个新的项目,名字为compiler --bin参数表示要创建一个二进制文件
现在目录结构为
Cargo.toml包含crate所需的配置(比如项目信息,依赖关系等等),src/main.rs文件中包含main函数(程序主入口),你可以使用cargo build来编译compiler并且会在compiler下放生成target文件夹,该文件夹包含着编译的输出结果,编译成的二进制文件包在target/debug目录下
因为我们编译的产物是在操作系统上运行的,因此我们并不需要对项目做特殊设置
顺便提一下,使用Cargo创建项目的时候会顺便初始化成Git本地仓库,所以可以使用git status查看仓库的情况
amdins@amdins:~/compiler $ git status
位于分支 master
尚无提交
未跟踪的文件:
(使用 "git add <文件>..." 以包含要提交的内容)
.gitignore
.idea/
Cargo.toml
src/
提交为空,但是存在尚未跟踪的文件(使用 "git add" 建立跟踪)如果你使用的IDEA或Clion,可以使用.gitignore忽略跟踪.idea目录,因此我们在.gitignore文件中添加以下内容。
# 忽略idea
.idea/*如果有依赖关系的话,cargo会创建一个Cargo.lock文件来自动跟踪每个依赖关系,该文件不属于我们的代码所以加入到.gitignore文件中,至于target文件
最终我们的.gitignore文件内容就是这样的
/target
**/*.rs.bk
# 忽略idea
.idea/*
*.lock然后我们需要将其他文件添加到git进行跟踪
admin@admin:~/droll_os: git add .gitignore Cargo.toml src/
再次查看
位于分支 master
尚无提交
要提交的变更:
(使用 "git rm --cached <文件>..." 以取消暂存)
新文件: .gitignore
新文件: Cargo.toml
新文件: src/main.rs最后我们使用下面的命令完成提交
git commit -m "init project"这样我们的项目就初始化完成了。
编译系统的过程
我们所做的编译系统将会涉及以下内容
编译器:
- 词法分析: 词法分析器通过对源代码的扫描获得高级语言定义的终结符,例如标识符,关键字,常量,运算符,逗号,分号等等
- 语法分析:经过词法分析之后我们需要通过语法分析器生成抽象语法树
- 语义分析:语义分解对生成的抽象语法树进行检查,保证源代码语义上没有问题
- 代码生成:根据据识别的语法模块翻译出目标机器指令(语法制导)
- 编译优化:我们根据前端生成的中间代码进行优化,包括冗余消除,消除死代码等等
汇编器:
- 汇编词法语法分析:对汇编代码进行词法语法的分析并生成抽象语法树
- 生成表信息:汇编器需要记录段相关的信息以及重定位符号信息
- 指令生成:根据分析的指令信息生成可执行文件,动态链接库文件 例如 .dll,.exe(windiows),elf文件,.so文件(Linux)
链接器:
- 地址空间分配:设置目标文件运行时的代码段和数据段基址
- 符号解析:为段内的符号指令地址
- 重定位:由于目标文件在链接之前不能获取自己所使用的符号虚拟地址,因此需要重新定位这些符号地址(地址修正)
C以及Rust编译的过程
主流的编译器
GCC
GCC编译器是由GNU开发的编译器,原名为GUN编译器,原本只能处理C语言随着发展,后续支持了C++,Java,Go等语言,所以改名为GNU编译器套件,GCC主要分为以下接口
- 前端接口: 将源码经过词法分析,语法分析生成与语言无关的低级中间语言表示层,然后经过优化后转化为RTL中间表示层
- 中间接口: 中间接口主要在RTL中间表示上进行各种优化,如循环优化,公共子表达式删除,指令重排等等
- 后端接口:GCC对每条RTL通过模板匹配方法调用对应的汇编模板生成汇编代码,生成的代码因处理器的不同而不同
LLVM
LLVM由C++编写,用于优化任意语言编写的程序,LLVM的命名最早源于Low Level Virtual Machine的缩写,LLVM代码有3种表示形式,IR,bitcode,汇编码,llvm提供了不同的优化Pass,对每个Pass的源码编译,得到一个Object文件,之后这些文件链接得到一个库,Pass之间由LLVM Pass管理器来统一管理
LLVM有很多其项目其中包括 LLVM Core libraries,Clang,LLD,LLDB,libc++ & libc++ ABI等等
C语言编译过程
一般的编译过程流程图大概是这样的

但是不同的编译器有着不同的编译方式,下面我们使用LLVM对C语言编译的过程进行实践
LLVM编译过程

我们开始准备LLVM的一些环境
首先我们创建一个test.c文件然后输入以下内容
int mult() {
int a = 5;
int b = 3;
int c = a * b;
return c;
}
将C源码转为LLVM IR
输入一下命令
clang -emit-llvm -S test.c -o test.ll
其中我们使用了clang作为前端进行编译,-emit-llvm用于LLVM IR写到.ll文件,-S表示仅运行预处理和编译步骤,-o参数用于将生成的内容输出到test.ll文件中
执行完毕后会在test.c同级目录下生成一个test.ll文件,将C语言代码分解为Token流(每个Token可表示标识符,字面量,运算符等等),Token流会传递给语法分析器,语法分析器使用CFG(上下文无关文法)组织成AST(抽象语法树),紧接着进行语义分析,然后生成IR
将IR转化为BitCode
我们使用一个较为简单的IR文件,内容如下
// test.ll
define i32 @mult(i32 %a, i32 %b) #0 {
%1 = mul nsw i32 %a, %b
ret i32 %1
}
使用命令如下
llvm-as test.ll -o test.bc
我们使用llvm-as(LLVM汇编器)将LLVM IR转为BitCode,-o参数用于将生成的BitCode输出到test.bc文件中
将BitCode转为目标平台汇编码
我们使用LLVM的静态编译器LLC把BitCode转为汇编码,命令如下
llc test.bc -o test.s
或者我们可以使用Clang从BitCode文件生成汇编码,命令如下
clang -S test.bc -o test.s -fomit-frame-pointer
我们使用了fomit-frame-pointer参数消除帧指针,因为Clang默认不消除帧指针,但是llc却默认消除帧指针
llc命令把LLVM的BitCode编译为指定架构的汇编语言,如果命令中没有指定任何架构默认生成的本机汇编码
执行BitCode
我们把test.c的内容换为以下内容
#include<stdio.h>
int main(){
int num = 5;
printf("number is %d\n", num);
return 0;
}
然后我们按照之前的步骤将test.c转为BitCode
$ clang -emit-llvm -S test.c -o test.ll
$ llvm-as test.ll -o test.bc
注: 在Windows执行第2步是会出现以下错误
llvm-as: test.ll:31:62: error: expected ‘global’ or ‘constant’
@"??_C@_0O@BAPFBKAP@number?5is?5? C F d ? 6 ? CFd?6? CFd?6?AA@" = linkonce_odr dso_local unnamed_addr constant [14 x i8] c"number is %d\0A\00", comdat, align 1
错误原因等待解决
最后我们使用LLI命令来运行BitCode
$ lli test.bc
LLI使用LLVM bitcode格式 作为输入并且使用即时编译器(JIT)执行,如果当前的架构不 存在JIT编译器,会用解释器执行
Rust编译过程
Rust使用的是rustc进行编译,编译的过程如下

详细过程如下
- 解析输入:将
.rs文件作为输入并进行解析生成AST(抽象语法树) - 名称解析,宏扩展和属性配置:解析完毕后处理
AST,处理#[cfg]节点解析路径,扩展宏 - 转为HIR:名称解析完毕后将AST转换为
HIR(高级中间表示),HIR比AST处理的更多,但是他不负责解析Rust的语法,例如((1+2)+3)和1+2+3在AST中会保留括号,虽然两者的含义相同但是会被解析成不同的树,但是在HIR中括号节点将会被删除,这两个表达式会以相同的方式表达 - 类型检查以及后续分析:处理HIR的重要步骤就是类型检查,例如使用
x.f时如果我们不知道x的类型就无法判断访问的哪个f字段,类型检查会创建TypeckTables其中包括表达式的类型,方法的解析方式 - 转为MIR以及后置处理:完成类型检查后,将HIR转为MIR(中级中间表示)进行借用检查以及优化
- 转为LLVM IR和优化:LLVM进行优化,从而生成许多
.o文件 - 链接: 最后将那些
.o文件链接在一起
我们开始实践这一过程
首先我们创建一个Cargo项目
~$ cargo new complier_test
main.rs文件中的内容如下
fn main(){
println!("Hello");
}
将源代码转为HIR
我们可以使用cargo的 -Zunpretty参数来生成hir,rustc命令没有找到。。
~/complier_test$ cargo rustc -- -Zunpretty=hir-tree -o main.hir
然后在src目录下会生成main.hir文件
将源代码转为MIR
转为mir的过程我们可以使用rustc来完成
~/complier_test/src$ rustc --emit mir -o main.mir main.rs
我们使用emit来生成emit用来生成mir,除此之外还可以使用emit来生成LLVM IR
~/complier_test/src$ rustc --emit llvm-ir -o main.ll main.rs
转换为BitCode
然后我们可以使用llvm-as将IR转为BitCode
~/complier_test/src$ llvm-as main.ll -o main.bc
或者我们可以使用rustc的emit参数生成
~/complier_test/src$ rustc --emit llvm-bc -o main.bc
最后我们可以使用LLI来运行BitCode
~/complier_test/src$ lli main.bc本文为翻译文章,原文链接:
www.infoworld.com/article/324…
相关链接:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











