









一.简介
微信在2016年发布了一个RPC框架phxrpc,github地址是:phxrpc。号称微信后台很多地方都使用到了,看了下,代码总体来说比较简单,但是其中有一些很有意思的地方,后面慢慢讲。
二.编译运行
可以见微信文档[可能是phcrpc仅有的文档:)]:编译。
此处自己来总结一下:
PhxRPC必须依赖的第三方库只有Protobuf。在编译前,在third_party目录放置好protobuf目录,或者通过软链的形式。这个third_party目录是没有的,需要自己创建,并且将protobuf代码放进去,protobuf链接。
1.编译protobuf
- 进入third_party/protobuf目录。
- ./autogen.sh
- ./configure CXXFLAGS=-fPIC –prefix=[当前目录绝对路径], 这一步CXXFLAGS和–prefix都必须设置对。
- make && make install
- 编译完成后检查是否在当前目录成功生成bin,include,lib三个子目录。
2.编译phxrpc
- 进入PhxRPC根目录。
- make
- 编译完成后检查是否生成lib子目录,并检查lib目录下是否生成静态库libphxrpc.a.
- 上面三步其实不仅生成了libphxrpc.a,还生成了sample中的代码,sample中的代码默认生成使用的是:
../codegen/phxrpc_pb2server -I ../ -I ../third_party/protobuf/include -f search.proto -d .所以如果想要生成的worker是使用协程方式执行,需要在sample下重新生成,或者你直接修改sample中的Makefile文件就OK:
../codegen/phxrpc_pb2server -I ../ -I ../third_party/protobuf/include -f search.proto -d . -u3.运行
进入sample,执行server:
./search_main -c search_server.conf后面的-c是server的配置文件。
执行client:
./search_tool_main -f PHXEcho -s "hello"这个search_tool_main是封装了client的可执行文件,上面的-f代表需要调用server中的哪个函数,-s代表这个函数需要什么参数。
如果需要使用方法,直接执行:
./search_tool_main会有usage的提示。
三.整体思路
下面着重讲一下phxrpc的整体的实现思路。
1).phxrpc的网络框架使用的epoll来进行调度的,你会看到各种各样的epoll,还有很多让我自己都觉得自己“无知”的写法:)。
2).phx并没有使用常规的“异步+回调”的方式,转而使用“协程”来处理线程中的阻塞问题。这个还是蛮有意思的,后面慢慢讲。
其他的就没什么特别的trick了。
1.一些重要对象
phxrpc中主要的对象有以下几种:
- HshaServer:server对象
- HshaServer Unit:逻辑上的工作单元,可以理解成是一个工厂,存在多个,一个unit可以包含多个worker。server接收到的client会分配给这些unit进行实际的处理。
- Data flow:所有的数据(包括request和response)都会进入data flow,谁需要就从data flow中拉取。
- Worker Pool:管理所有的workers
- Worker:实际的工作线程(每个都是独立的线程)。如果是协程模式,那么每个worker中存在多个协程工作实例,通过epoll进行管理这些协程。
- Epoll:IO调度使用的是epoll。具体怎么做下面再说。
- Runtime:我想说这是一个很诡异的名字,Orz…。这个其实就要用于调度所有的协程的控制结构,所有的协程都会注册到这个结构中。
这些对象的生成过程(流程)如下图,结合下图慢慢讲:
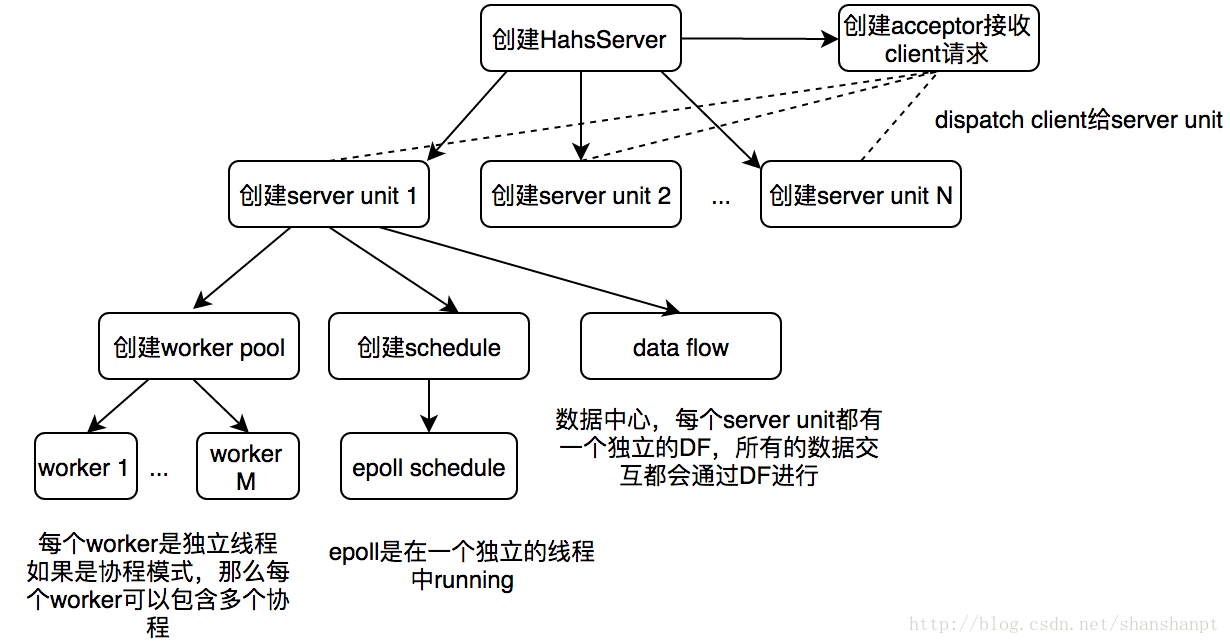
1.首先创建一个HshaServer对象
2.HshaServer会创建多个Server Unit:
auto hsha_server_unit = new HshaServerUnit(this, i, (int)worker_thread_count_per_io,config.GetWorkerUThreadCount(), worker_utherad_stack_size, dispatch,args);3.每个Server unit会创建worker 和 epoll scheduler
// 每个Unit的构造如下:
HshaServerUnit :: HshaServerUnit(
HshaServer * hsha_server,
int idx,
int worker_thread_count,
int worker_uthread_count_per_thread,
int worker_utherad_stack_size,
Dispatch_t dispatch,
void * args) :
hsha_server_(hsha_server),
#ifndef __APPLE__
scheduler_(8 * 1024, 1000000, false),
#else
// 创建epoll调度器,用于管理client的fds
scheduler_(32 * 1024, 1000000, false),
#endif
// 创建worker pool
// 本质相当于一个线程池
// 每个worker是一个线程,在new Worker的时候创建的~
worker_pool_(&scheduler_, worker_thread_count, worker_uthread_count_per_thread,
worker_utherad_stack_size, &data_flow_, &hsha_server_->hsha_server_stat_, dispatch, args),
// server io
hsha_server_io_(idx, &scheduler_, hsha_server_->config_, &data_flow_,&hsha_server_->hsha_server_stat_, &hsha_server_->hsha_server_qos_, &worker_pool_),
// 需要注意:当前的这个线程是 epoll 的IO线程!!!
// 看RunFunc里面的代码就知道了
// 后面调用了:scheduler_->RunForever();
thread_(&HshaServerUnit::RunFunc, this) {
}上面的代码显示Unit创建了:
worker pool:每个worker都是一个独立的线程(在Worker的构造函数中可知)。
epoll schedule + 独立io线程:用于调度所有的client socket fd。
4.worker pool 创建多个worker
WorkerPool :: WorkerPool(
UThreadEpollScheduler * scheduler,
int thread_count,
int uthread_count_per_thread,
int utherad_stack_size,
DataFlow * data_flow,
HshaServerStat * hsha_server_stat,
Dispatch_t dispatch,
void * args)
: scheduler_(scheduler), data_flow_(data_flow),
hsha_server_stat_(hsha_server_stat), dispatch_(dispatch),
args_(args), last_notify_idx_(0) {
// 创建多个worker
for (int i = 0; i < thread_count; i++) {
// 创建一个最底层的实际做事的worker
auto worker = new Worker(this, uthread_count_per_thread, utherad_stack_size);
assert(worker != nullptr);
worker_list_.push_back(worker);
}
}再看worker的代码:
Worker :: Worker(WorkerPool * pool, const int uthread_count, int utherad_stack_size)
: pool_(pool), uthread_count_(uthread_count), utherad_stack_size_(utherad_stack_size), shut_down_(false),
worker_scheduler_(nullptr), thread_(&Worker::Func, this) {
}上面代码可知每个worker是一个独立的线程。
5.data flow
用于存储所有的resp和req数据。
至此:每个对象基本的功能都基本清楚了。
2.基本流程
本小节讲一下基本的流程。
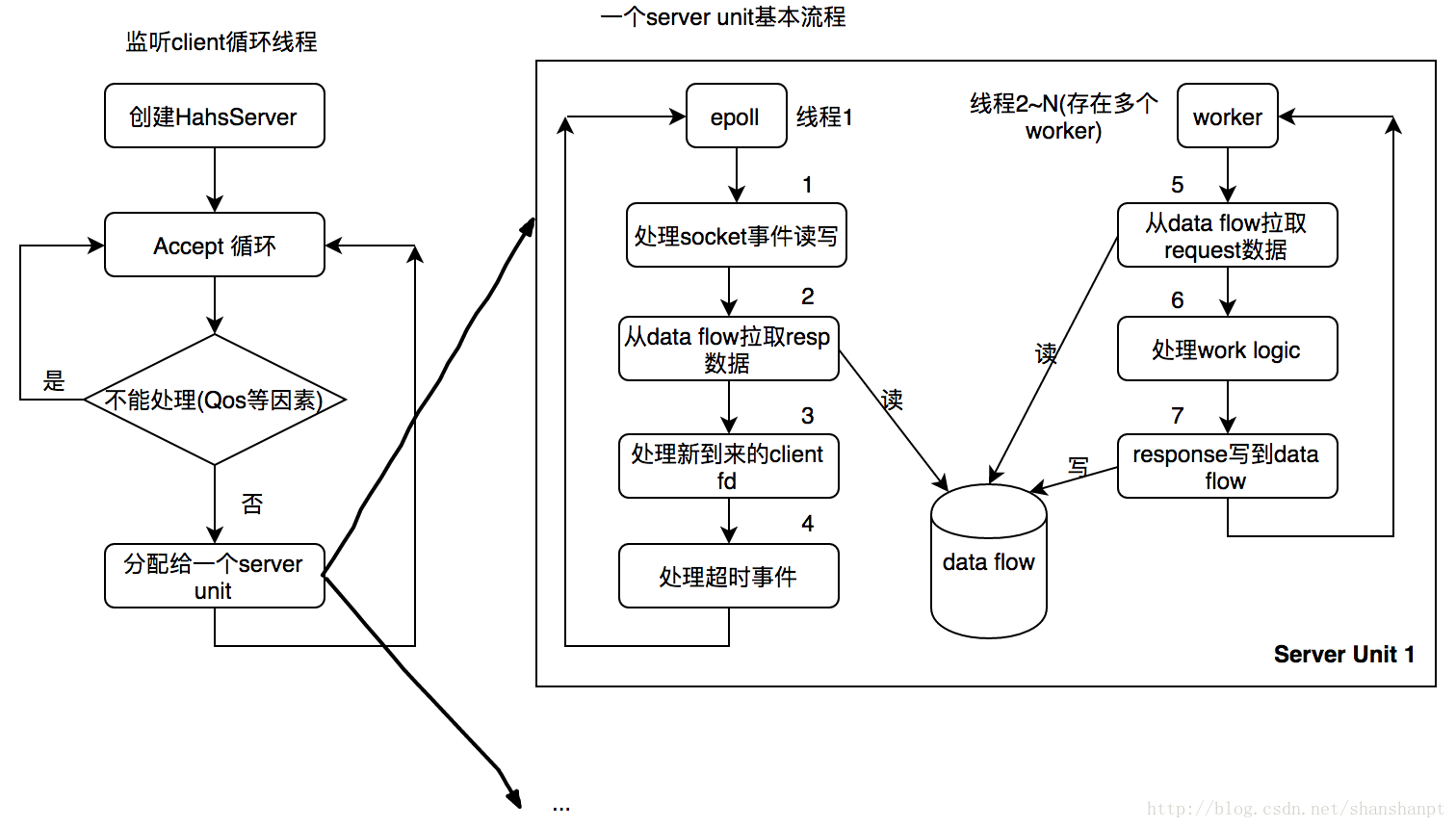
左侧主线程负责监听client请求:
[详见代码:hsha_server.cpp,HshaServerAcceptor :: LoopAccept函数]
这段逻辑是最常规的Linux网络编程中的步骤:
1).创建监听socket,注意需要下面设置:
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, (char*) &flags, sizeof(flags)) 需要设置SO_REUSEADDR标志。
作用:假设server在某种情况下进程被杀死,但是这个时候server的端口是没有被释放的,一般会内核保存一段时间,这个时候重启server的时候没法使用之前的地址,这样显然是不行的,如果换了地址,client就找不到了,所以这个时候设置SO_REUSEADDR表示重启后可以直接使用,无需等待2MSL时间。
2). accept:
int accepted_fd = accept(listen_fd, (struct sockaddr*) &addr, &socklen);接收client的请求。
3).将新的client分配给一个server unit。然后返回继续监听。
右边图示解释:
右侧其实是多个server unit,图中只画出了一个server unit。对于每个server unit,包括三个模块分别是:epoll scheduler,data flow,workers。
1). epoll scheduler
[代码:uthread_epoll.cpp, UThreadEpollScheduler::Run()函数]
这里的epoll代码特别奇怪,不仅处理了socket事件,还把轮询放在一起执行了,看下面的代码你体会下:
// 此处超时时间写死hardcode:4ms
// 意思是:如果在4ms内有事件被触发,那么执行下面的代码
// 如果超时了,那么会强制执行一次,此时是没有socket事件的,但是
// 可以处理下面轮询的工作啊,Orz...
// 尼玛...
int nfds = epoll_wait(epoll_fd_, events, max_task_, 4);
...
// 处理socket事件读写
for (int i = 0; i < nfds; i++) {...}
...
// 下面都是属于轮询(最迟4ms一次轮询)的工作
// 1. 读取data flow,看看有么有response可以读取,如果有
// 那么通知相应的socket进行写给client
if (active_socket_func_ != nullptr) {
while ((socket = active_socket_func_()) != nullptr)
...
}
...
// 处理新接收的client
if (handler_accepted_fd_func_ != nullptr) {
handler_accepted_fd_func_();
}
...
// 处理超时事件
// 这些超时时间其实是一个heap(小根堆)进行管理的
// 以后详细讲讲
DealwithTimeout(next_timeout);上面的代码简直了,事件触发和轮询融合的“天衣无缝”…叼叼叼…
2).data flow
这个结构其实超级简单,就是两个队列:
// 缓存request队列
ThdQueue<std::pair<QueueExtData, HttpRequest *> > in_queue_;
// 缓存response队列
ThdQueue<std::pair<QueueExtData, HttpResponse *> > out_queue_;这个结构本身不会有任何动作,所有的动作都是由想要写或者想要读的组件触发。
例如:
<1>. hsha_server.cpp的IOFunc()函数中,接收到client的请求后,将request写入data flow:
data_flow_->PushRequest((void *)socket, request);<2>. 之前说过,在epoll的轮询中会去主动拉取data flow的response:
active_socket_func_
// 对应hsha_server.cpp中的ActiveSocketFunc函数
//scheduler_->SetActiveSocketFunc(std::bind(&HshaServerIO::ActiveSocketFunc, this));
// 这个函数中执行:从data flow中拉取response
int queue_wait_time_ms = data_flow_->PluckResponse(args, response);<3>.前面的1)和2)代表的是放入client的request和获取最终的response结果,但是中间的处理是谁呢???OK,这时候应该想到是worker,看看worker是不是自取data的。(此处以worker的ThreadMode为例子)
在hsha_server.cpp的Worker :: ThreadMode()函数中:
// 主动从data flow拉取数据
// 也就是说,client的request数据最终是被worker消费的
int queue_wait_time_ms = pool_->data_flow_->PluckRequest(args, request);
...
// 下面处理逻辑
WorkerLogic(args, request, queue_wait_time_ms);<4>. 在上面worker处理逻辑函数中WorkerLogic:
...
// 向data flow中发送response数据
pool_->data_flow_->PushResponse(args, response);
...3).worker流程
worker的流程比较简单,每个worker都是run在独立的线程中的,如果是协程模式,那么每个线程中有多个协程,使用epoll进行调度。
基本就是下面简单的循环完事:
void Worker :: ThreadMode() {
// 下面进入死循环
while (!shut_down_) {
// 空闲的worker++
pool_->hsha_server_stat_->worker_idles_++;
void * args = nullptr;
HttpRequest * request = nullptr;
// 空闲的worker会在此处进程拉取client的请求,如果没有拉到请求,那么worker继续等待
int queue_wait_time_ms = pool_->data_flow_->PluckRequest(args, request);
if (request == nullptr) {
//break out
continue;
}
// 拉到请求了,那么空闲的worker--
pool_->hsha_server_stat_->worker_idles_--;
// 下面worker开始执行逻辑
WorkerLogic(args, request, queue_wait_time_ms);
}
}3.一些子模块解析
上图中的1~7个子模块,简单细讲一下:
1).处理socket事件读写
这个比较简单,epoll对于管理的套接字进行,没什么好说的。
2).从data flow拉取response数据
基本函数就三个:
UThreadSocket_t * HshaServerIO :: ActiveSocketFunc() {
while (data_flow_->CanPluckResponse()) {
...
int queue_wait_time_ms = data_flow_->PluckResponse(args, response);
...
return socket;
}
return nullptr;
}int DataFlow :: PluckResponse(void *& args, HttpResponse *& response) {
...
bool succ = out_queue_.pluck(rp);
...
} bool pluck(T & value) {
std::unique_lock<std::mutex> lock(mutex_);
if (break_out_) {
return false;
}
// 如果队列空,等待数据
while (queue_.empty()) {
cv_.wait(lock);
if (break_out_) {
return false;
}
}
// 队列中取数据
size_--;
value = queue_.front();
queue_.pop();
return true;
}所以说到底,就是读取队列数据,注意多线程之间的互斥读取。此处的互斥使用的就是简单的加锁操作。
3).处理新到来的client fd
这个过程是比较重要的过程,从server主线程接收到client到最后,差不多分成三大步如下:
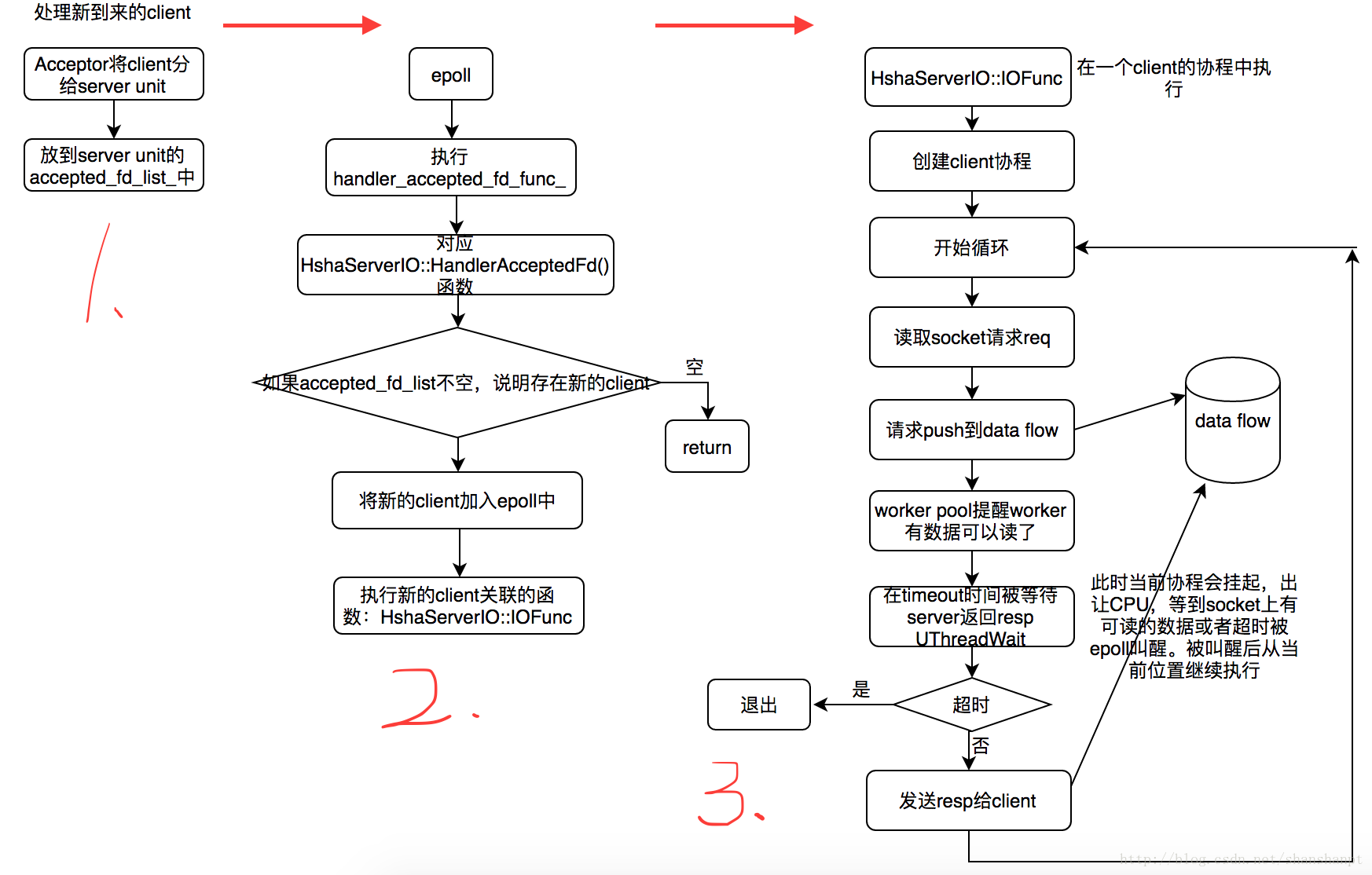
<1>.最左边1部分,是在主线程中执行的,Acceptor将新的client分配给一个server unit,本质是将其放进accepted_fd_list_结构中。epoll在轮询的时候会判断这个结构是否有数据存在。
<2>. epoll在轮询的时候会判断server unit的这个结构中是否存在数据,如果有说明有新的client,那么需要处理。
对应epoll轮询中的handler_accepted_fd_func_函数,这个函数在epoll初始化之前被赋值为:
scheduler_->SetHandlerAcceptedFdFunc(std::bind(&HshaServerIO::HandlerAcceptedFd, this));所以请看hsha_server.cpp中的HandlerAcceptedFd函数:
// 在epoll scheduler中增加一些Task
void HshaServerIO :: HandlerAcceptedFd() {
std::lock_guard<std::mutex> lock(queue_mutex_);
while (!accepted_fd_list_.empty()) {
int accepted_fd = accepted_fd_list_.front();
accepted_fd_list_.pop();
// 调度器增加一个task。
// 以后每次使用epoll相应这些client的fd
// 执行函数是IOFunc
scheduler_->AddTask(std::bind(&HshaServerIO::IOFunc, this, accepted_fd), nullptr);
}
}这些task关联的函数是IOFunc。
需要注意,在epoll的run函数后面有一个ConsumeTodoList();函数,用于将所有的task加入协程scheduler中:
void UThreadEpollScheduler::ConsumeTodoList() {
while (!todo_list_.empty()) {
auto & it = todo_list_.front();
// 对于当前的task,创建一个协程
int id = runtime_.Create(it.first, it.second);
// swap到创建的协程执行
runtime_.Resume(id);
todo_list_.pop();
}
}看runtime_.Resume(id)这一行,就是执行当前的协程,这个协程在创建的时候被定位到执行关联的函数处,这个具体实现在uthread_context_system.cpp中,暂时不多讲,后面再说。
所以当runtime_.Resume(id)时候其实就是执行HshaServerIO::IOFunc函数。
<3>.关于HshaServerIO::IOFunc函数
看注释,写的特别清楚!
void HshaServerIO :: IOFunc(int accepted_fd) {
// 创建UThreadSocket_t,对原始的socket fd增加一些属性
UThreadSocket_t * socket = scheduler_->CreateSocket(accepted_fd);
UThreadTcpStream stream;
// 新建一个缓冲区绑定到socket上
// 这里很牛逼的把socket和缓冲区绑定在一起,下面的处理很方便
// 这一块也很有意思,后面会细讲
stream.Attach(socket);
// 设置socket超时时间
UThreadSetSocketTimeout(*socket, config_->GetSocketTimeoutMS());
HshaServerStat::TimeCost time_cost;
// 大循环
while (true) {
hsha_server_stat_->io_read_requests_++;
HttpRequest * request = new HttpRequest;
// 接收请求
int socket_ret = HttpProto::RecvReq(stream, request);
if (socket_ret != 0) {
delete request;
hsha_server_stat_->io_read_fails_++;
hsha_server_stat_->rpc_time_costs_count_++;
//phxrpc::log(LOG_ERR, "%s read request fail, fd %d", __func__, accepted_fd);
break;
}
hsha_server_stat_->io_read_bytes_ += request->GetContent().size();
// 判断data flow是否可以push请求到data flow队列中
if (!data_flow_->CanPushRequest(config_->GetMaxQueueLength())) {
delete request;
hsha_server_stat_->queue_full_rejected_after_accepted_fds_++;
break;
}
// Qos保证
if (!hsha_server_qos_->CanEnqueue()) {
//fast reject don't cal rpc_time_cost;
delete request;
hsha_server_stat_->enqueue_fast_rejects_++;
//phxrpc::log(LOG_ERR, "%s fast reject, can't enqueue, fd %d", __func__, accepted_fd);
break;
}
//if have enqueue, request will be deleted after pop.
bool is_keep_alive = request->IsKeepAlive();
std::string version = string(request->GetVersion() != nullptr ? request->GetVersion() : "");
hsha_server_stat_->inqueue_push_requests_++;
// 将获得request push到data flow队列中去
data_flow_->PushRequest((void *)socket, request);
// 这一块需要注意:
// 如果worker是uthread协程模式,
// 那么需要下面worker_pool_->Notify()是有效的,
// 如果是线程模式无效,这个可以具体看worker中的UThreadMode()
// 函数和ThreadMode()函数。对于ThreadMode,如果线程没有数据
// 可读,那么会阻塞,如果是UThreadMode是epoll进行调度,
// 所以当有数据的时候,需要通知有数据了,
// 这个时候work pool会告诉某个woker(轮询告诉) ,
// worker会发一个Notify给自己的epoll scheduler,
// 提醒有数据可以读取了,然后worker的协程就可以读取了。
// (注意上面的epoll scheduler是worker自己私有的,和前面不一样)
//
// 简单来说,这一步就是通知worker可以做事了,
// worker做完后将resp放到data flow中,
// epoll中的 HshaServerIO::ActiveSocketFunc() 函数
// 会取出response放到socker的args中
//
worker_pool_->Notify();
// 设置socket参数null
UThreadSetArgs(*socket, nullptr);
// 这一步特别有意思,UThreadWait本质上是当前的client协程让出
// CPU,挂起,等待数据
// 如果超时那么socket中数据是空,需要退出
// 这一步什么时候能得到数据呢?
// epoll中会主动去拉取data flow的response
// 然后在相关的函数中会将response写入socket关联的缓冲区
// 这样如果在超时时间内写入,那么下面的
// UThreadGetArgs(*socket) != nullptr
// 那么就完成了一次交互过程,尼玛,这耦合性太强了。
UThreadWait(*socket, config_->GetSocketTimeoutMS());
// 如果超时了还没有回复那么退出
if (UThreadGetArgs(*socket) == nullptr) {
//timeout
hsha_server_stat_->worker_timeouts_++;
hsha_server_stat_->rpc_time_costs_count_++;
//because have enqueue, so socket will be closed after pop.
socket = stream.DetachSocket();
UThreadLazyDestory(*socket);
//phxrpc::log(LOG_ERR, "%s timeout, fd %d sockettimeoutms %d",
//__func__, accepted_fd, config_->GetSocketTimeoutMS());
break;
}
hsha_server_stat_->io_write_responses_++;
// 获取response
HttpResponse * response = (HttpResponse *)UThreadGetArgs(*socket);
HttpProto::FixRespHeaders(is_keep_alive, version.c_str(), response);
// 发送response给client
socket_ret = HttpProto::SendResp(stream, *response);
hsha_server_stat_->io_write_bytes_ += response->GetContent().size();
delete response;
hsha_server_stat_->rpc_time_costs_count_++;
if (socket_ret != 0) {
hsha_server_stat_->io_write_fails_++;
}
// 如果不是keep live,那么break
if(!is_keep_alive || (socket_ret != 0)) {
break;
} else {
// 返回while(true)继续等待数据
hsha_server_stat_->rpc_time_costs_ += time_cost.Cost();
}
}
hsha_server_stat_->rpc_time_costs_ += time_cost.Cost();
hsha_server_stat_->hold_fds_--;
}看上面的注释基本就清楚了新的client和server的交互流程。但是总体看来,代码的耦合性太强了,差点绕晕。。。
4).处理超时事件
此处所有的超时事件都是被管理在一个heap(小根堆)中,每次epoll轮询的时候都会判断哪些事件已经超时了,如果已经超时,那么执行相应的协程代码。
5).从data flow拉取request数据
这个过程和上面拉取response数据是类似的。
6).处理Work logic
这个是worker实际的工作函数,如下:
void Worker :: WorkerLogic(void * args, HttpRequest * request, int queue_wait_time_ms) {
// 统计信息
pool_->hsha_server_stat_->inqueue_pop_requests_++;
pool_->hsha_server_stat_->inqueue_wait_time_costs_ += queue_wait_time_ms;
pool_->hsha_server_stat_->inqueue_wait_time_costs_count_++;
HttpResponse * response = new HttpResponse;
// 如果从数据队列中拉取请求数据超时,那么drop这个请求
if (queue_wait_time_ms < MAX_QUEUE_WAIT_TIME_COST) {
HshaServerStat::TimeCost time_cost;
DispatcherArgs_t dispatcher_args(pool_->hsha_server_stat_->hsha_server_monitor_,
worker_scheduler_, pool_->args_);
// 下面执行路由函数
// 这个dispatch_其实是真的处理逻辑函数,是由最外层的
// server_main.cpp中定义的,一般是void HttpDispatch(...)
// 这个函数内部会根据调用的函数做一些分发,从而调用真实的处理函数
pool_->dispatch_(*request, response, &dispatcher_args);
pool_->hsha_server_stat_->worker_time_costs_ += time_cost.Cost();
} else {
pool_->hsha_server_stat_->worker_drop_requests_++;
}
// 将response数据fill给到data_flow_
pool_->data_flow_->PushResponse(args, response);
pool_->hsha_server_stat_->outqueue_push_responses_++;
// 通知epoll有response数据可读了
pool_->scheduler_->NotifyEpoll();
delete request;
}7).response写到data flow中
写队列,简单,不讲了。
OK,至此phxrpc的整体流程和部分复杂流程讲完了,哎,代码看下来,感觉耦合性挺强的,所以有点晕。。。后面几篇会写一些关键点的实现。















 1219
1219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









