









最近发觉etcd是一个不错的学习存储的对象,功能比较完备,同时相对比较简单,最重要的是golang实现。所以花了些时间看了etcd的源码,看一下相关功能的具体实现。本篇主要集中在storage模块的梳理。
etcd是一个基于raft构建的分布式kv存储,raft是一个基于日志复制状态机的共识算法。这里就涉及到两部分存储:
- raft本身需要的日志存储;
- etcd(状态机部分)需要的kv存储;
除了上述的两部分存储外,持久化存储常见的优化是通过预写日志来持久化变更记录,而将变更缓存在缓冲区中,达到条件进行批量刷盘,etcd中同样采用了该优化。
预写日志
etcd storage模块中定义了Storage接口以及具体的实现,其具备保存预写日志、快照以及相关的功能。在具体实现中因为快照和日志的差异,这两部分是拆分到不同的子模块中实现的。预写日志是etcd持久化的真正保障。
type Storage interface {
// Save function saves ents and state to the underlying stable storage.
// Save MUST block until st and ents are on stable storage.
Save(st raftpb.HardState, ents []raftpb.Entry) error
// SaveSnap function saves snapshot to the underlying stable storage.
SaveSnap(snap raftpb.Snapshot) error
// Close closes the Storage and performs finalization.
Close() error
// Release releases the locked wal files older than the provided snapshot.
Release(snap raftpb.Snapshot) error
// Sync WAL
Sync() error
// MinimalEtcdVersion returns minimal etcd storage able to interpret WAL log.
MinimalEtcdVersion() *semver.Version
}
type storage struct {
lg *zap.Logger
s *snap.Snapshotter
// Mutex protected variables
mux sync.RWMutex
w *wal.WAL
}
storage持有Snapshotter和WAL两个对象,分别实现快照及日志相关的功能。
其中Snapshotter功能的实现比较简单,在对应的目录下,每个快照对应一个文件。文件命名格式为term-index.snap,该格式将term\index放置在文件名中,有助于快速检索,也是常见的优化方式。在此基础中提供了一系列的增删查的功能。
wal的实现也比较简单,其采用了rotate file的形式实现。每个文件的大小为64MB,文件命名格式为seq-index.wal,其中seq表示wal文件的序号。当文件的大小超过64MB时,会使用新的文件。wal中采用的是预创建文件的形式,由filePipeline实现。这种方式的好处是避免写入过程中创建新文件可能引起的性能波动。
func (fp *filePipeline) Open() (f *fileutil.LockedFile, err error) {
select {
case f = <-fp.filec:
case err = <-fp.errc:
}
return f, err
}
func (fp *filePipeline) run() {
defer close(fp.errc)
for {
f, err := fp.alloc()
if err != nil {
fp.errc <- err
return
}
select {
case fp.filec <- f:
case <-fp.donec:
os.Remove(f.Name())
f.Close()
return
}
}
}
wal的写入是通过encoder对象实现,encoder中封装了预写日志的编码,并在fd上封装了pageWriter。wal的编码格式采用了常见LV格式(length+value),前8个字节表示value的长度,value则是一条record的序列化数据。record有3个字段type、crc、data,分别表示raft消息类型、data的哈希签名、raft entry的内容。
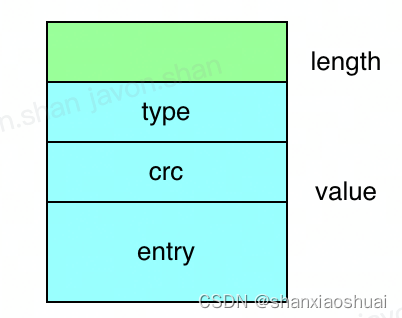
上面提到了wal的写入是通过pageWriter来实现,而pageWriter带有缓冲,是异步写入。我们知道,wal是etcd持久化的真正保障,其必须保证同步写入。这里的判断是在wal中实现的,如果写入的日志条目数不为0,或者写入的raft状态同wal现存的状态不一致,那么wal会显式调用encoder的sync方法,保证同步写入。
// MustSync returns true if the hard state and count of Raft entries indicate
// that a synchronous write to persistent storage is required.
func MustSync(st, prevst pb.HardState, entsnum int) bool {
// Persistent state on all servers:
// (Updated on stable storage before responding to RPCs)
// currentTerm
// votedFor
// log entries[]
return entsnum != 0 || st.Vote != prevst.Vote || st.Term != prevst.Term
}
raft日志存储
etcd中的raft模块是基于raft/v3实现的。该库实现了leader选举、日志复制等功能,存储、网络等则是定义了相关接口,可以由用户自己开发。raft Storage接口定义如下,该库同时提供了MemoryStorage的实现,etcd就采用了该实现。MemoryStorage基于内存数组实现,满足raft的功能需要,持久化则完全依靠etcd的wal保证。
type Storage interface {
// TODO(tbg): split this into two interfaces, LogStorage and StateStorage.
// InitialState returns the saved HardState and ConfState information.
InitialState() (pb.HardState, pb.ConfState, error)
// Entries returns a slice of log entries in the range [lo,hi).
// MaxSize limits the total size of the log entries returned, but
// Entries returns at least one entry if any.
Entries(lo, hi, maxSize uint64) ([]pb.Entry, error)
// Term returns the term of entry i, which must be in the range
// [FirstIndex()-1, LastIndex()]. The term of the entry before
// FirstIndex is retained for matching purposes even though the
// rest of that entry may not be available.
Term(i uint64) (uint64, error)
// LastIndex returns the index of the last entry in the log.
LastIndex() (uint64, error)
// FirstIndex returns the index of the first log entry that is
// possibly available via Entries (older entries have been incorporated
// into the latest Snapshot; if storage only contains the dummy entry the
// first log entry is not available).
FirstIndex() (uint64, error)
// Snapshot returns the most recent snapshot.
// If snapshot is temporarily unavailable, it should return ErrSnapshotTemporarilyUnavailable,
// so raft state machine could know that Storage needs some time to prepare
// snapshot and call Snapshot later.
Snapshot() (pb.Snapshot, error)
}
// MemoryStorage implements the Storage interface backed by an
// in-memory array.
type MemoryStorage struct {
// Protects access to all fields. Most methods of MemoryStorage are
// run on the raft goroutine, but Append() is run on an application
// goroutine.
sync.Mutex
hardState pb.HardState
snapshot pb.Snapshot
// ents[i] has raft log position i+snapshot.Metadata.Index
ents []pb.Entry
callStats inMemStorageCallStats
}
MemoryStorage的实现比较简单,就是日志的追加、匹配、查询、压缩等,做这些操作时通常都需要基于term+index的匹配,更多的细节会在raft部分介绍。
backend
backend是etcd的kv存储。当然实际上只是kv存储的一部分,backend加内存化的treeIndex才构成完整的支持mvcc的kv存储。这部分内容会在mvcc部分详细介绍。这里我们仅介绍backend,etcd的持久化的kv存储。
etcd中定义了Backend的接口以及相应的实现,接口及实现如下。
type Backend interface {
// ReadTx returns a read transaction. It is replaced by ConcurrentReadTx in the main data path, see #10523.
ReadTx() ReadTx
BatchTx() BatchTx
// ConcurrentReadTx returns a non-blocking read transaction.
ConcurrentReadTx() ReadTx
Snapshot() Snapshot
Hash(ignores func(bucketName, keyName []byte) bool) (uint32, error)
// Size returns the current size of the backend physically allocated.
// The backend can hold DB space that is not utilized at the moment,
// since it can conduct pre-allocation or spare unused space for recycling.
// Use SizeInUse() instead for the actual DB size.
Size() int64
// SizeInUse returns the current size of the backend logically in use.
// Since the backend can manage free space in a non-byte unit such as
// number of pages, the returned value can be not exactly accurate in bytes.
SizeInUse() int64
// OpenReadTxN returns the number of currently open read transactions in the backend.
OpenReadTxN() int64
Defrag() error
ForceCommit()
Close() error
// SetTxPostLockInsideApplyHook sets a txPostLockInsideApplyHook.
SetTxPostLockInsideApplyHook(func())
}
type backend struct {
// size and commits are used with atomic operations so they must be
// 64-bit aligned, otherwise 32-bit tests will crash
// size is the number of bytes allocated in the backend
size int64
// sizeInUse is the number of bytes actually used in the backend
sizeInUse int64
// commits counts number of commits since start
commits int64
// openReadTxN is the number of currently open read transactions in the backend
openReadTxN int64
// mlock prevents backend database file to be swapped
mlock bool
mu sync.RWMutex
bopts *bolt.Options
db *bolt.DB
batchInterval time.Duration
batchLimit int
batchTx *batchTxBuffered
readTx *readTx
// txReadBufferCache mirrors "txReadBuffer" within "readTx" -- readTx.baseReadTx.buf.
// When creating "concurrentReadTx":
// - if the cache is up-to-date, "readTx.baseReadTx.buf" copy can be skipped
// - if the cache is empty or outdated, "readTx.baseReadTx.buf" copy is required
txReadBufferCache txReadBufferCache
stopc chan struct{}
donec chan struct{}
hooks Hooks
// txPostLockInsideApplyHook is called each time right after locking the tx.
txPostLockInsideApplyHook func()
lg *zap.Logger
}
backend是一个基于boltdb实现的kv存储。
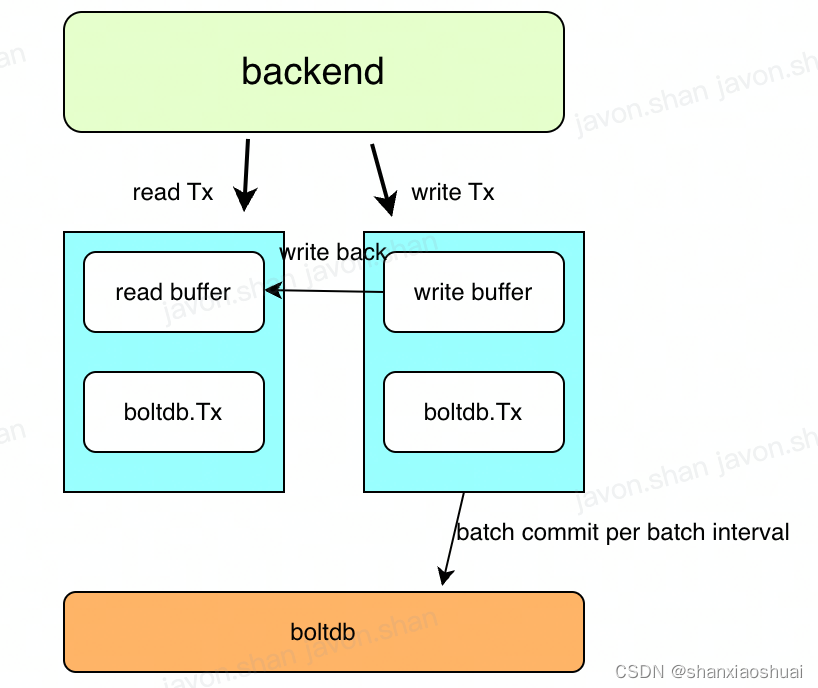
blotdb的具体内容后面同样会专门介绍,这里只需要知道boltdb是一个golang实现的支持事务的kv存储。backend在boltdb基础上封装了带有缓冲区的事务。当backend的事务提交时,实际上boltdb并没有真正的提交,此时的修改是由backend维护在内存中,持久化同样是依靠wal来保证。当事务积累到一定程度时,才会进行批量提交,这提高了etcd整体的写入性能。
func (b *backend) run() {
defer close(b.donec)
t := time.NewTimer(b.batchInterval)
defer t.Stop()
for {
select {
case <-t.C:
case <-b.stopc:
b.batchTx.CommitAndStop()
return
}
if b.batchTx.safePending() != 0 {
b.batchTx.Commit()
}
t.Reset(b.batchInterval)
}
}
ReadTx
etcd中定义了ReadTx(读事务)的接口,其主要有范围读和遍历两个方法。同时有readTx和concurrentReadTx两个具体的实现,都是在baseReadTx上的封装。
type ReadTx interface {
Lock()
Unlock()
RLock()
RUnlock()
UnsafeRange(bucket Bucket, key, endKey []byte, limit int64) (keys [][]byte, vals [][]byte)
UnsafeForEach(bucket Bucket, visitor func(k, v []byte) error) error
}
type readTx struct {
baseReadTx
}
type concurrentReadTx struct {
baseReadTx
}
我们看下baseReadTx的实现,其持有boltdb的事务,以及读缓冲区。对读缓冲区及只读事务分别有读写锁进行并发访问保护。
// Base type for readTx and concurrentReadTx to eliminate duplicate functions between these
type baseReadTx struct {
// mu protects accesses to the txReadBuffer
mu sync.RWMutex
buf txReadBuffer
// TODO: group and encapsulate {txMu, tx, buckets, txWg}, as they share the same lifecycle.
// txMu protects accesses to buckets and tx on Range requests.
txMu *sync.RWMutex
tx *bolt.Tx
buckets map[BucketID]*bolt.Bucket
// txWg protects tx from being rolled back at the end of a batch interval until all reads using this tx are done.
txWg *sync.WaitGroup
}
读缓冲区是由每个桶的缓存构成。桶在boltdb中相当于mysql中的表的概念,每个桶的缓存是由kv的数组组成。
当用户发起读事务时,会先查询读缓冲区,读缓冲区中查到的key,则不会再查询boltdb;读缓冲区没有查到的key,则会去boltdb中查询。
// txReadBuffer accesses buffered updates.
type txReadBuffer struct {
txBuffer
// bufVersion is used to check if the buffer is modified recently
bufVersion uint64
}
// txBuffer handles functionality shared between txWriteBuffer and txReadBuffer.
type txBuffer struct {
buckets map[BucketID]*bucketBuffer
}
// bucketBuffer buffers key-value pairs that are pending commit.
type bucketBuffer struct {
buf []kv
// used tracks number of elements in use so buf can be reused without reallocation.
used int
}
type kv struct {
key []byte
val []byte
}
BatchTx
batchTx是读写事务,BatchTx接口定义了增删改查的方法,并提供了batchTx和batchTxBuffered的实现。
type BatchTx interface {
ReadTx
UnsafeCreateBucket(bucket Bucket)
UnsafeDeleteBucket(bucket Bucket)
UnsafePut(bucket Bucket, key []byte, value []byte)
UnsafeSeqPut(bucket Bucket, key []byte, value []byte)
UnsafeDelete(bucket Bucket, key []byte)
// Commit commits a previous tx and begins a new writable one.
Commit()
// CommitAndStop commits the previous tx and does not create a new one.
CommitAndStop()
LockInsideApply()
LockOutsideApply()
}
batchTx就是在blotdb的事务基础上做了简单的封装,具体备增删改查的能力。batchTxBuffered在batchTx基础上增加了写缓冲区,会将写入变更记录到写缓冲区中,并在解锁时把变更同步到读缓冲区中。
至于为什么batchTxBuffered只提供了put和seq put的方法,这是因为在etcd中由于mvcc的特性,实际删除也只是增加一个版本的kv,只不过value为空。
type batchTx struct {
sync.Mutex
tx *bolt.Tx
backend *backend
pending int
}
type batchTxBuffered struct {
batchTx
buf txWriteBuffer
}
type txWriteBuffer struct {
txBuffer
// Map from bucket ID into information whether this bucket is edited
// sequentially (i.e. keys are growing monotonically).
bucket2seq map[BucketID]bool
}
concurrentReadTx
concurrentReadTx是为了解决readTx慢查询(expensive read)带来的阻塞问题。
我们先看下readTx的问题。
readTx持有读写锁,该锁是保证其txReadBuffer并发访问的安全。当使用readTx进行读操作时,需要加读锁,此时可以支持并发读;写锁在两种情况下会被申请:
- 当一次batchTx操作完成时,会将txWriteBuffer中的内容同步到txReadBuffer中,需要申请写锁;
func (t *batchTxBuffered) Unlock() {
if t.pending != 0 {
t.backend.readTx.Lock() // blocks txReadBuffer for writing.
// gofail: var beforeWritebackBuf struct{}
t.buf.writeback(&t.backend.readTx.buf)
// gofail: var afterWritebackBuf struct{}
t.backend.readTx.Unlock()
if t.pending >= t.backend.batchLimit {
t.commit(false)
}
}
t.batchTx.Unlock()
}
- batchInterval到期后,batchTx批量提交,此时会对boltdb的事务进行真正提交刷盘,同时重置读写事务,需要申请写锁防止新的读请求;
func (t *batchTxBuffered) commit(stop bool) {
// all read txs must be closed to acquire boltdb commit rwlock
t.backend.readTx.Lock()
t.unsafeCommit(stop)
t.backend.readTx.Unlock()
}
func (t *batchTxBuffered) unsafeCommit(stop bool) {
if t.backend.hooks != nil {
// gofail: var commitBeforePreCommitHook struct{}
t.backend.hooks.OnPreCommitUnsafe(t)
// gofail: var commitAfterPreCommitHook struct{}
}
if t.backend.readTx.tx != nil {
// wait all store read transactions using the current boltdb tx to finish,
// then close the boltdb tx
go func(tx *bolt.Tx, wg *sync.WaitGroup) {
wg.Wait()
if err := tx.Rollback(); err != nil {
t.backend.lg.Fatal("failed to rollback tx", zap.Error(err))
}
}(t.backend.readTx.tx, t.backend.readTx.txWg)
t.backend.readTx.reset()
}
t.batchTx.commit(stop)
if !stop {
t.backend.readTx.tx = t.backend.begin(false)
}
}
以上两种情况出现的频率是很频繁的。如果申请写锁时存在一个慢查询(expensive read),那么就会阻塞写锁,同时因为写锁的申请,也会阻塞其他的读请求。此时backend只有一个慢查询在执行,相当于一个etcd节点被慢查询完全阻塞。
concurrentReadTx就是为了解决该问题,其采用了拷贝而非共享的思路,使得由读写锁控制的N read 1 write变成了读写之间真正的并发。
如下所示,创建concurrentReadTx时将读缓冲区进行了拷贝,因此只有创建时需要持有读锁,真正读请求时不需要持有读锁,使得读写是真正的并发。同时增加了txWg来记录当前boltdb的只读事务上还有多少读请求,这用来判断什么时候可以关闭该只读事务,该操作为异步执行。
更消息的内容可参见Fully Concurrent Reads Design Proposal。
func (b *backend) ConcurrentReadTx() ReadTx {
b.readTx.RLock()
defer b.readTx.RUnlock()
b.readTx.txWg.Add(1)
b.txReadBufferCache.mu.Lock()
curCache := b.txReadBufferCache.buf
curCacheVer := b.txReadBufferCache.bufVersion
curBufVer := b.readTx.buf.bufVersion
isEmptyCache := curCache == nil
isStaleCache := curCacheVer != curBufVer
var buf *txReadBuffer
switch {
case isEmptyCache:
curBuf := b.readTx.buf.unsafeCopy()
buf = &curBuf
case isStaleCache:
b.txReadBufferCache.mu.Unlock()
curBuf := b.readTx.buf.unsafeCopy()
b.txReadBufferCache.mu.Lock()
buf = &curBuf
default:
buf = curCache
}
if isEmptyCache || curCacheVer == b.txReadBufferCache.bufVersion {
b.txReadBufferCache.buf = buf
b.txReadBufferCache.bufVersion = curBufVer
}
b.txReadBufferCache.mu.Unlock()
return &concurrentReadTx{
baseReadTx: baseReadTx{
buf: *buf,
txMu: b.readTx.txMu,
tx: b.readTx.tx,
buckets: b.readTx.buckets,
txWg: b.readTx.txWg,
},
}
}
以上就是etcd storage模块的内容,mvcc的部分会单独写一篇来介绍。后续包括boltdb、raft实现等也都会慢慢介绍。
如果觉得本文对您有帮助,可以请博主喝杯咖啡~

















 465
465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









