










文章目录
0x00 文章内容
- Text格式概念
- 编码实现
- 校验结果
- 可能出现的问题解决
Hadoop支持的四种常用的文件格式:Text(csv)、Parquet、Avro以及SequenceFile,非常关键!
0x01 Text格式概念
1. Text是啥
普通的文档格式,txt格式。
0x02 编码实现
1. 写文件完整代码
package com.shaonaiyi.hadoop.filetype.text;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.task.JobContextImpl;
import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl;
import java.io.IOException;
/**
* @Author shaonaiyi@163.com
* @Date 2019/12/17 11:20
* @Description Hadoop支持的文件格式之写Text
*/
public class MRTextFileWriter {
public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException, ClassNotFoundException, InterruptedException {
//1 构建一个job实例
Configuration hadoopConf = new Configuration();
Job job = Job.getInstance(hadoopConf);
//2 设置job的相关属性
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3 设置输出路径
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9999/user/hadoop-sny/mr/filetype/text"));
//FileOutputFormat.setCompressOutput(job, true);
//FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//4 构建JobContext
JobID jobID = new JobID("jobId", 123);
JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID);
//5 构建taskContext
TaskAttemptID attemptId = new TaskAttemptID("jobTrackerId", 123, TaskType.REDUCE, 0, 0);
TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId);
//6 构建OutputFormat实例
OutputFormat format = job.getOutputFormatClass().newInstance();
//7 设置OutputCommitter
OutputCommitter committer = format.getOutputCommitter(hadoopAttemptContext);
committer.setupJob(jobContext);
committer.setupTask(hadoopAttemptContext);
//8 获取writer写数据,写完关闭writer
RecordWriter<NullWritable, Text> writer = format.getRecordWriter(hadoopAttemptContext);
writer.write(null, new Text("shao"));
writer.write(null, new Text("nai"));
writer.write(null, new Text("yi"));
writer.write(null, new Text("bigdata-man"));
writer.close(hadoopAttemptContext);
//9 committer提交job和task
committer.commitTask(hadoopAttemptContext);
committer.commitJob(jobContext);
}
}
2. 读文件完整代码
package com.shaonaiyi.hadoop.filetype.text;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.task.JobContextImpl;
import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl;
import java.io.IOException;
import java.util.List;
import java.util.function.Consumer;
/**
* @Author shaonaiyi@163.com
* @Date 2019/12/17 11:38
* @Description Hadoop支持的文件格式之读Text
*/
public class MRTextFileReader {
public static void main(String[] args) throws IOException, IllegalAccessException, InstantiationException {
//1 构建一个job实例
Configuration hadoopConf = new Configuration();
Job job = Job.getInstance(hadoopConf);
//2 设置需要读取的文件全路径
FileInputFormat.setInputPaths(job, "hdfs://master:9999/user/hadoop-sny/mr/filetype/text");
//3 获取读取文件的格式
TextInputFormat inputFormat = TextInputFormat.class.newInstance();
//4 获取需要读取文件的数据块的分区信息
//4.1 获取文件被分成多少数据块了
JobID jobID = new JobID("jobId", 123);
JobContext jobContext = new JobContextImpl(job.getConfiguration(), jobID);
List<InputSplit> inputSplits = inputFormat.getSplits(jobContext);
//读取每一个数据块的数据
inputSplits.forEach(new Consumer<InputSplit>() {
@Override
public void accept(InputSplit inputSplit) {
TaskAttemptID attemptId = new TaskAttemptID("jobTrackerId", 123, TaskType.MAP, 0, 0);
TaskAttemptContext hadoopAttemptContext = new TaskAttemptContextImpl(job.getConfiguration(), attemptId);
RecordReader reader = inputFormat.createRecordReader(inputSplit, hadoopAttemptContext);
try {
reader.initialize(inputSplit, hadoopAttemptContext);
System.out.println("<key,value>");
System.out.println("-----------");
while (reader.nextKeyValue()) {
System.out.println("<"+reader.getCurrentKey() + "," + reader.getCurrentValue()+ ">" );
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
0x03 校验结果
1. 启动集群
a. 启动HDFS集群,
start-dfs.sh
PS:如不启动会处于一个卡死状态
Exception in thread "main" java.net.ConnectException: Call From shaonaiyi/192.168.98.205 to master:9999 failed on connection exception: java.net.ConnectException: Connection refused: no further information; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
2. 执行写Text文件格式代码
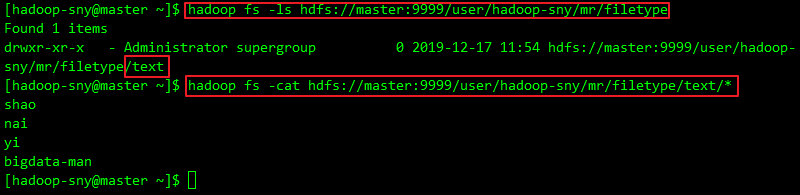
a. 直接在Win上执行,如无报错,去集群查看结果:
hadoop fs -ls hdfs://master:9999/user/hadoop-sny/mr/filetype
hadoop fs -cat hdfs://master:9999/user/hadoop-sny/mr/filetype/text/*
PS:如果报权限错误:
Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="/user/hadoop-sny":hadoop-sny:supergroup:drwxr-xr-x
解决方案:需要去集群里修改权限
hadoop fs -mkdir -p hdfs://master:9999/user/hadoop-sny/mr/filetype
hadoop fs -chmod 757 hdfs://master:9999/user/hadoop-sny/mr/filetype
3. 执行读Text文件格式代码
a. 可得如下结果
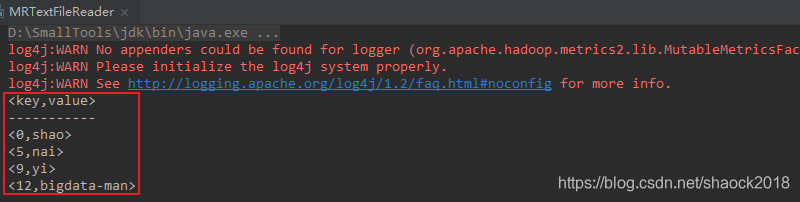
System.out.println("<"+reader.getCurrentKey() + "," + reader.getCurrentValue()+ ">" );
reader.getCurrentKey()为偏移量,每一行的起始值
reader.getCurrentValue()为具体的值
与MapReduce单词计数例子时一样。
0x04 可能出现的问题解决
1. 类无法导入

请参考文章:“Usage of API documented as @since 1.8+”报错的解决办法
0xFF 总结
- Hadoop支持的文件格式系列:
Hadoop支持的文件格式之Text
Hadoop支持的文件格式之Avro
Hadoop支持的文件格式之Parquet
Hadoop支持的文件格式之SequenceFile - 项目实战中,文章:网站用户行为分析项目之会话切割(二)中使用的存储格式是Parquet。
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一 原创不易,如转载请标明出处。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}