







一、生产过程:
1、获取路由消息,本地缓存不存在,重新获取(获取Topic发布信息:tryToFindTopicPublishInfo)
传入topic、消息字符串,根据传入的topic查询是否在本地缓存中,不在从NameSerer中获取topic并存入本地缓存:GET_ALL_TOPIC_LIST_FROM_NAMESERVER;
(当topic不存在时,之前的版本可以默认自动创建topic,4.3.0版本不会自动创建topic,需要单独去创建topic)
2、判断通讯模式,SYNC同步模式默认失败重试2次,异步和oneway模式只发送一次
3、选择一个消息队列:selectOneMessageQueue
第一次从队列列表messageQueueList中随机选择一个,后面从此基础上+1,达到轮询的效果,读写队列列表是在创建topic时指定的,读、写队列readQueueNums=5, writeQueueNums=5
也可以使用hash方式,使同一个订单的数据一直发送到同一个MessageQueue上,以达到顺序效果。
4、发送消息(底层通讯采用netty)
5、存储消息(根据配置,可同步或异步存储消息)
6、返回消息结果
二、存储过程:
1、获取MappedFile最后一个文件,若没有或已写满则创建一个新的MapedFile文件
2、调用MapedFile.appendMessage方法将消息写入消息缓存中,有后台服务线程定时的将缓存中的消息刷盘到物理文件中;
3、若最后一个文件剩余空间不足写入此次消息,重新获取新的MapedFile文件
若Broker是同步刷盘:
a、单broker,等待master的刷盘结果,构建commit请求对象GroupCommitRequest,放入写请求队列中,唤醒线程开始读
B、主从同步,等待slaves的同步结果
若Broker是异步刷盘:也是唤醒后台线程服务,根据commitLog时间间隔刷盘
三、消费过程
1、读方法有两个参数,一个偏移量(上次读取到的位置),一个读取的大小(固定值)
总结:rocketmq写都是通过同一个commitLog进行,同一个文件夹commitlog下,所有生产者写同一个文件,默认大小1G,写满后重新创建一个文件,每个文件的命名就是为上一个文件的位置结束偏移量
比如第一个文件名00000000000000000000,第二个文件名00000000000010485760;写是后台线程从缓存区写入文件中,读也是后台线程读入对应的topic文件中,放在comsumerqueue文件夹下。
消息顺序、消息重复、消息丢失问题解决方案?
消息顺序:是同一个订单的数据hash到同一个MessageQueue上,第一个成功之后再发送第二个,或者业务系统自己做业务顺序,做完一件事再做另一件事;
消息重复:由业务系统完成,保持业务处理的幂等性
消息丢失:1、保证发送成功,ack确认;2、保证同步到slave节点上了(消息队列一般都是先写到缓冲区,再落盘,所以无法用持久化,而是用多个副本来保证高可用);3、保证消费成功,消费ack确认。
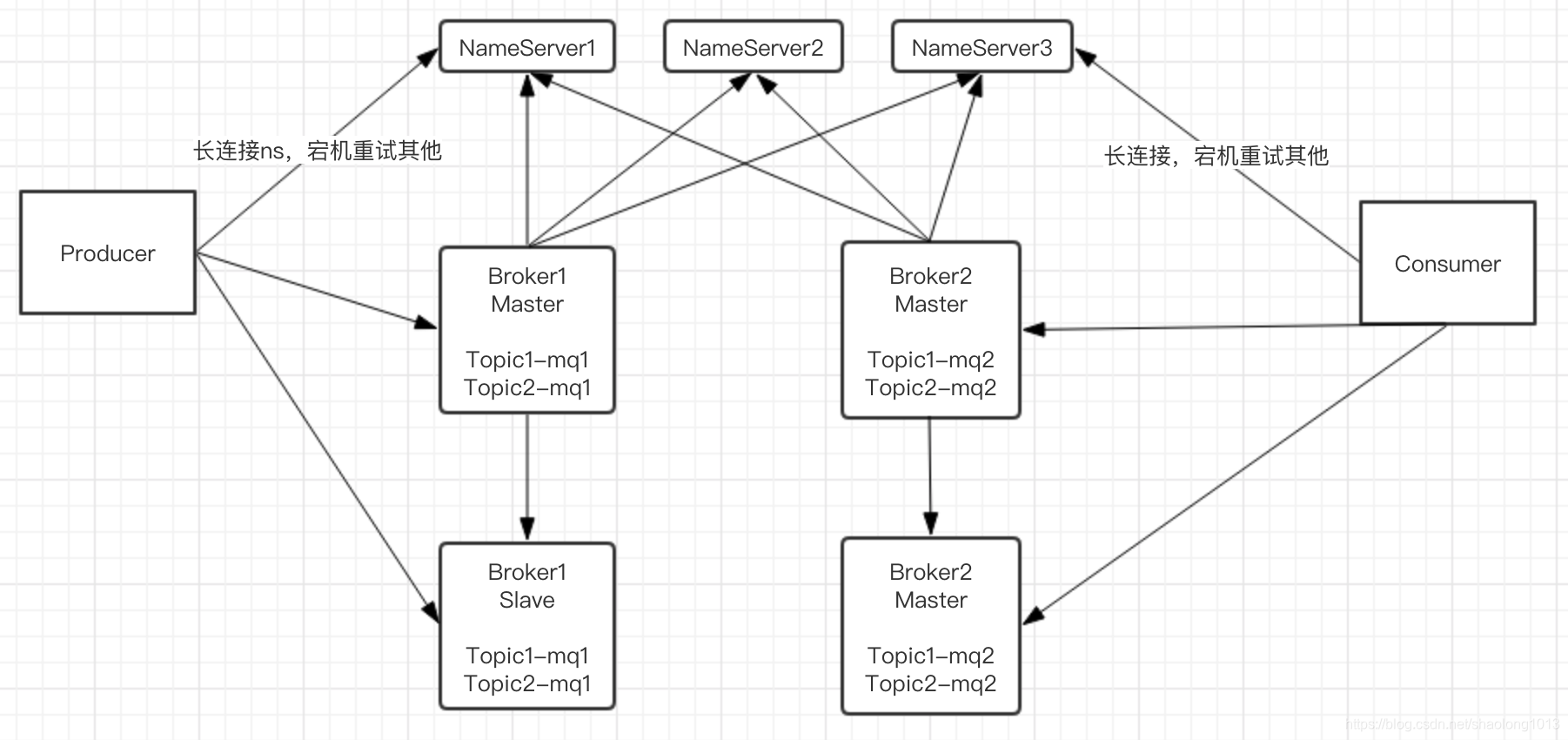
一、主要组件producer、nameserver、broker、consumer;
1、nameserver类似于zk,区别是每个ns上都存储了所有broker对应topic的全量元数据,ns之间不进行通讯;ns集群宕机不影响现有服务,只有一个ns存活可加入新服务;broker和所有的ns保持长连接,broker有变化自动同步到ns,ns同步到P和C;组件之间都是通过长连接通讯;
2、broker是提供读写服务和存储消息的载体,所有producer都往同一个mapedFile文件里写,利用IO的完全顺序写提供高效的写服务,读不是完全顺序的;
二、写入过程:
1、将写请求放入CommitService线程List<GroupCommitRequest> requestsWrite = new ArrayList<GroupCommitRequest>();的list中,并将这个请求的用CountDownLatch等待,同时countDown()唤醒次线程,此线程没有被唤醒情况下每10ms定时执行,执行完后修改请求GroupCommitRequest的状态,并将请求countDown释放,期间利用java.nio.channels.FileChannel写入文件中;
2、topic存储在多个broker上,一个topic包含多个messagequeue,mq均衡分布在不同的broker上,达到负载均衡的目的;
3、写都写在commitlog目录下,并将每条消息的起始位置,偏移量,大小等信息写入对应consumerqueue下的对应的topic文件中,消费端通过读取consumerqueue中的对应topic中的消息其实位置和偏移量等信息,再去commitlog下的文件中读取消息实体内容;
4、consumerqueue其实就是个索引文件,消息写入commitlog后再异步写入consumerqueue中
三、消费:
读取topic文件夹下对应的messagequeue文件,读取索引,再从commitlog中读取真实数据;
- push
- 优点,就是及时性。
- 缺点,就是受限于消费者的消费能力,可能造成消息的堆积,Broker 会不断给消费者发送不能处理的消息。
- pull
- 优点,就是主动权掌握在消费方,可以根据自己的消息速度进行消息拉取。
- 缺点,就是消费方不知道什么时候可以获取的最新的消息,会有消息延迟和忙等。
目前的消息队列,基于 push + pull 模式结合的方式,Broker 仅仅告诉 Consumer 有新的消息,具体的消息拉取,还是 Consumer 自己主动拉取。
四、HA:
1、Slave向Master报告已同步的位置,M根据之前同步的位置,从后继续同步数据给S
2、S与S之间不进行通讯,都只与M通讯
3、M宕机,S可继续提供消费服务,不能提供写服务,M宕机nameserver中收到消息,同步给producer,producer从轮询列表中剔除掉对应的broker即可;
五、负载均衡:
生产者:默认所有producer轮询写所有broker,每个broker所有的messageQueue都往同一个commitlog文件中写,以达到每个broker都是顺序写;
消费者:消费组有多少个消费组,平均分配多个消息队列;
















 1805
1805











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









