






数据清理与再处理(Cleaning and Munging)
真实世界的数据是脏的,在你使用数据之前,你不得不对数据做一些工作。例如,在”获取数据”章节中,在我们使用它们的时候,我们需要把字符串转换成floats或者ints:
closing_price = float(row[2])解析数据可能减少错误,通过创建一个包裹csv.reader的函数来做这个。我们会给出一个解析器的清单,每个解析器说明怎样解析列中的一个,我们会使用None表示”对这个列不做任何操作”:
def parse_row(input_row, parsers):
"""given a list of parsers (some of which may be None)
apply the appropriate one to each element of the input_row"""
return [parser(value) if parser is not None else value
for value, parser in zip(input_row, parsers)]
def parse_rows_with(reader, parsers):
"""wrap a reader to apply the parsers to each of its rows"""
for row in reader:
yield parse_row(row, parsers)要是坏的数据怎么办?一个”float”值不是真的代表一个数字?我们通常会得到None而不是摧毁我们的程序,我们能利用helper函数来做这个:
def try_or_none(f):
"""wraps f to return None if f raises an exception
assumes f takes only one input"""
def f_or_none(x):
try: return f(x)
except: return None
return f_or_none然后我们能利用try_or_none函数重写parse_row函数:
def parse_row(input_row, parsers):
return [try_or_none(parser)(value) if parser is not None else value
for value, parser in zip(input_row, parsers)]例如,如果我们有一个逗号分隔的股票数据,且其中有坏的数据:
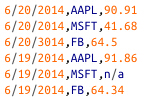
现在我们读数据并解析:
import dateutil.parser
data = []
with open("comma_delimited_stock_prices.csv", "rb") as f:
reader = csv.reader(f)
for line in parse_rows_with(reader, [dateutil.parser.parse, None, float]):
data.append(line)做完上面之后,我们需要检查具有None的行:
for row in data:
if any(x is None for x in row):
print row然后对于这些None行,决定我们想要对他们做什么。(一般来讲,有3个选项:(1)消除他们;(2)返回到数据源中,试着修改坏/丢失的数据;(3)什么也不做,期求后面的操作能通过)
我们能为csv.DictReader创建类似的helpers,这种情况,你可能想要提供具有字段名的key作为字典,字典的value为解析器。例如:
def try_parse_field(field_name, value, parser_dict):
"""try to parse value using the appropriate function from parser_dict"""
parser = parser_dict.get(field_name) # None if no such entry
if parser is not None:
return try_or_none(parser)(value)
else:
return value
def parse_dict(input_dict, parser_dict):
return { field_name : try_parse_field(field_name, value, parser_dict)
for field_name, value in input_dict.iteritems() }下一步就是检测离群值(outliers),例如,你注意到在股票数据中”3014年”了么,那个没有给我们任何错误,但是很明显是错误的,如果你不获取它,你会得到错误的结论。真实的世界中数据集有很多丢失小数、很多0、排版错误以及无数其他问题需要我们处理。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









