






神经网络与深度学习
2025年深度学习课程笔记
目录
四、LeNet-5网络
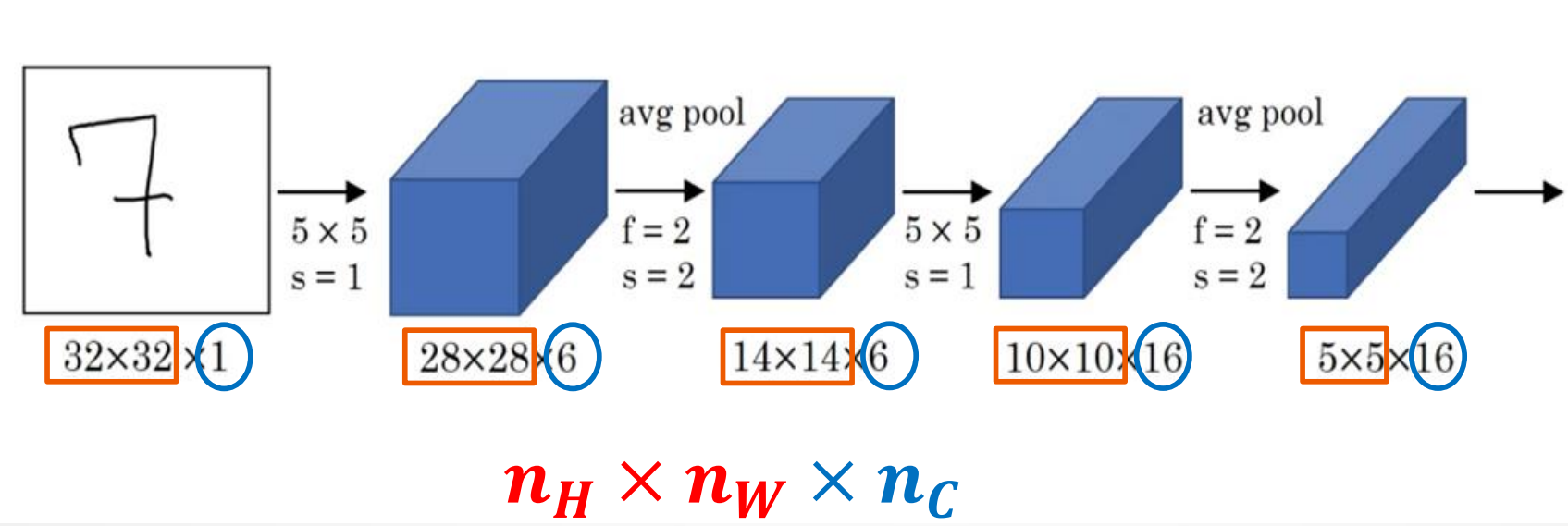
1. 网络结构
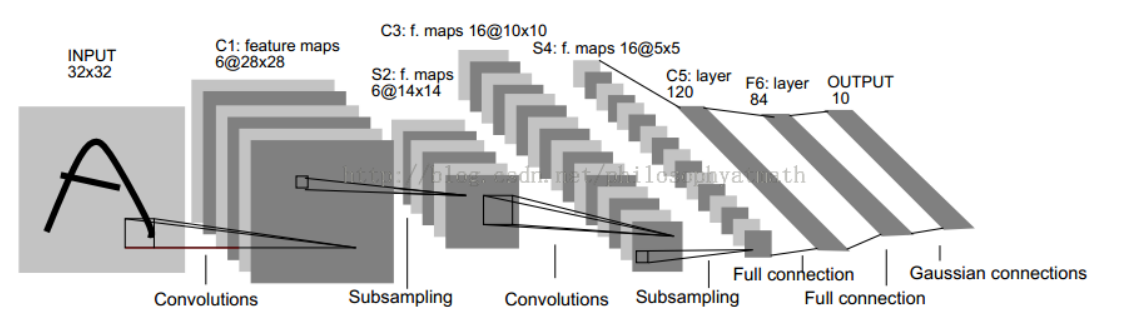
结构详解
C1层
- 6个Feature map构成
- 每个神经元对输入进行5*5卷积
- 每个神经元对应5*5+1个参数,共6个feature map,28*28个神经元,因此共有(5*5+1)*6*(28*28)=122,304连接
S2层
- 池化(Pooling)层
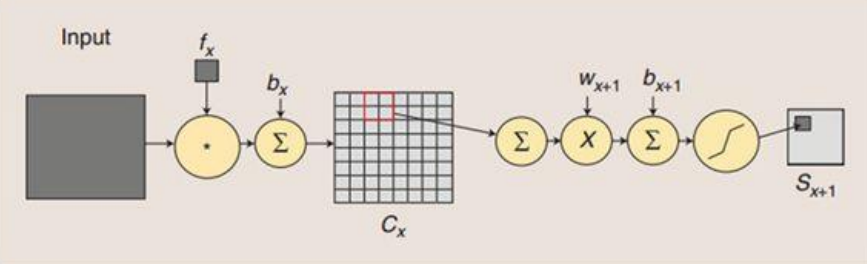
C3层
- 卷积层
S4层——与S2层工作相同
C5层
- 120个神经元
- 每个神经元同样对输入进行5*5卷积,与S4全连接
- 总连接数(5*5*16+1)*120=48120
F6层
- 84个神经元
- 与C5全连接
- 总连接数(120+1)*84=10164
输出层
- 由欧式径向基函数单元构成
- 每类一个单元
- 输出RBF单元计算输入向量和参数向量之间的欧式距离
网络说明
与现在网络的区别
- 卷积时不进行填充(padding)
- 池化层选用平均池化而非最大池化
- 选用Sigmoid或tanh而非ReLU作为非线性环节激活函数
- 层数较浅,参数数量小(约为6万)
普遍规律
- 随网络深入,宽、高衰减,通道数增加
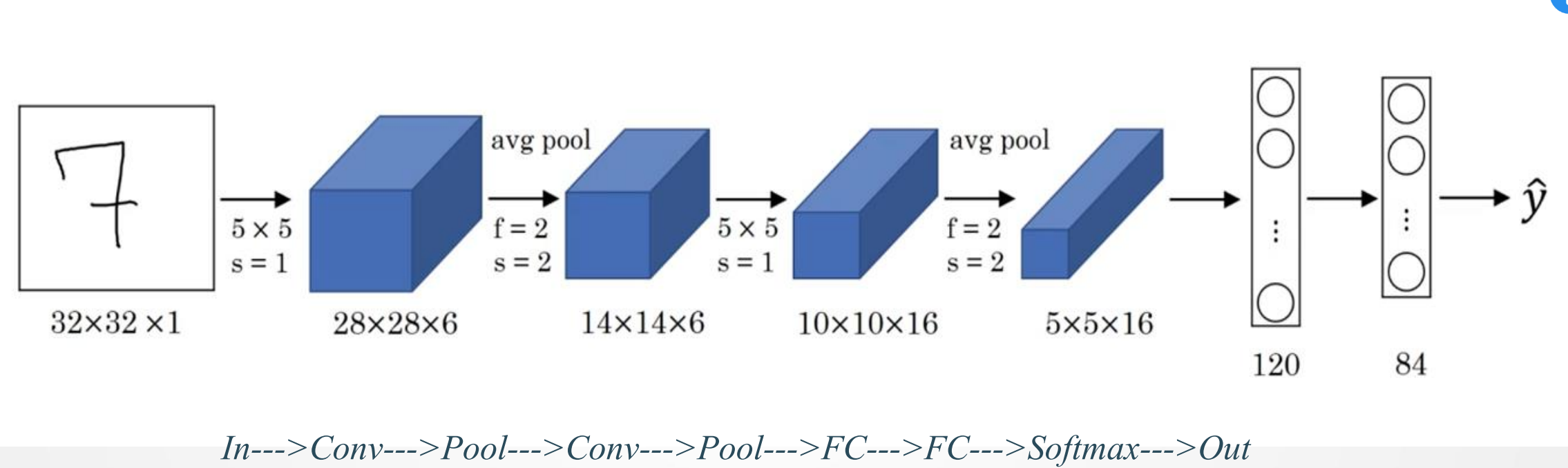
2.代码实现
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = torch.nn.Sequential(
Reshape(),
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))nn. Sequential():该函数可以将不同的模块组合成一个新的模块,将各模块按顺序输入即可
nn.AvgPool2d(kernel_size, stride):平均池化,输入参数分别为池化窗口大小和步长。二参数同时可以为整数,否则为元组
MaxPool2d:最大池化,输入参数分别为池化窗口大小和步长。二参数同时可以为整数,否则为元组
nn. Sigmoid():该函数为上一层的输出添加sigmoid激活函数类似的还有nn.ReLU(),nn.Tanh()等
nn. Conv2d(in_channels,out_channels,kernel_size):卷积层,其三个参数按顺序代表输入通道数、输出通道数、卷积核大小。若卷积核形状为正方形,则卷积核大小可以为int,否则,卷积核大小必须为元组(tuple),如:nn.Conv2d(1, 6, (5, 4)),即代表卷积核大小为5×4除此之外,还有:
stride参数:可以规定卷积的步长,与卷积核大小类似,若各方向步长相同则可以为整数,否则应为元组
padding参数:在图像的周围补充0的个数,常常用于控制卷积前后图像的尺寸大小
五、基本卷积神经网络
1.AlexNet
网络结构
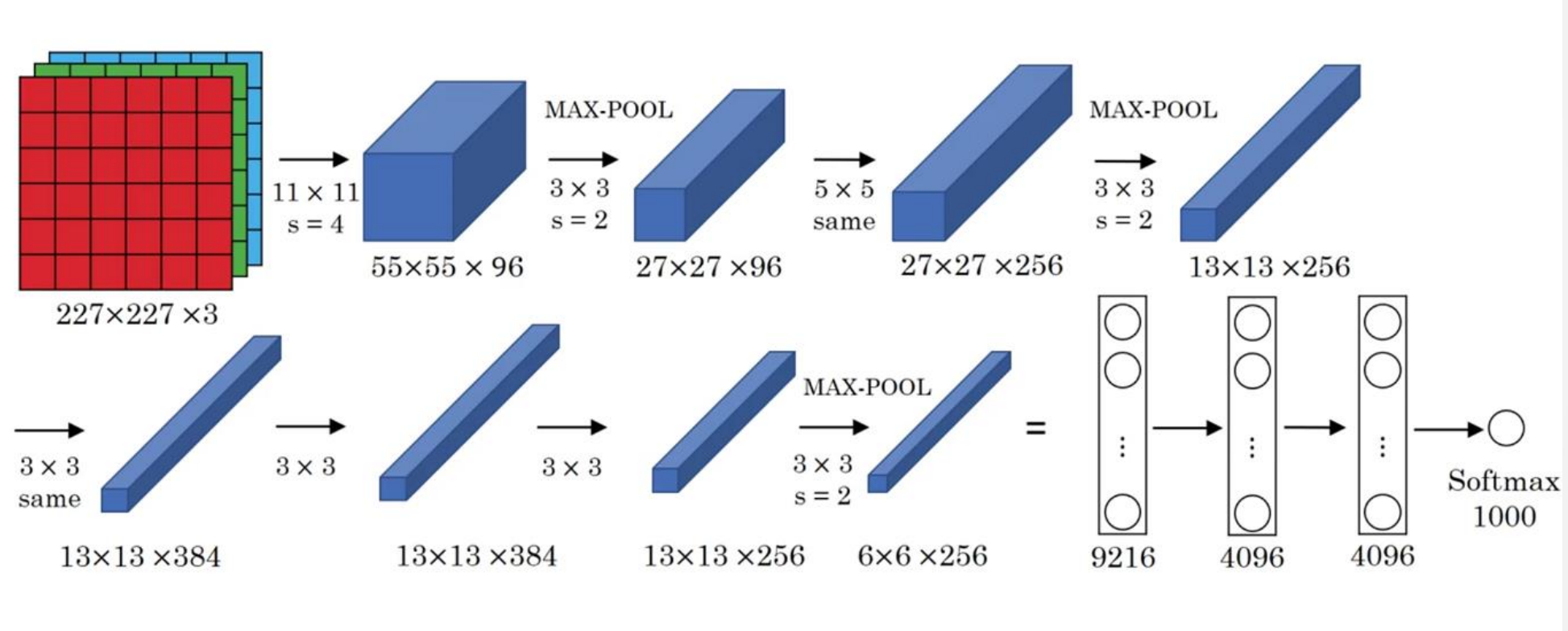
网络说明
网络一共有8层可学习层——5层卷积层和3层全连接层
改进
- 池化层均采用最大池化
- 选用ReLU作为非线性环节激活函数
- 网络规模扩大,参数数量接近6000万
- 出现“多个卷积层+一个池化层”的结构
普遍规律
- 随网络深入,宽、高衰减,通道数增加

上图中左侧为连接数,右侧为参数
2.VGG-16
网络结构
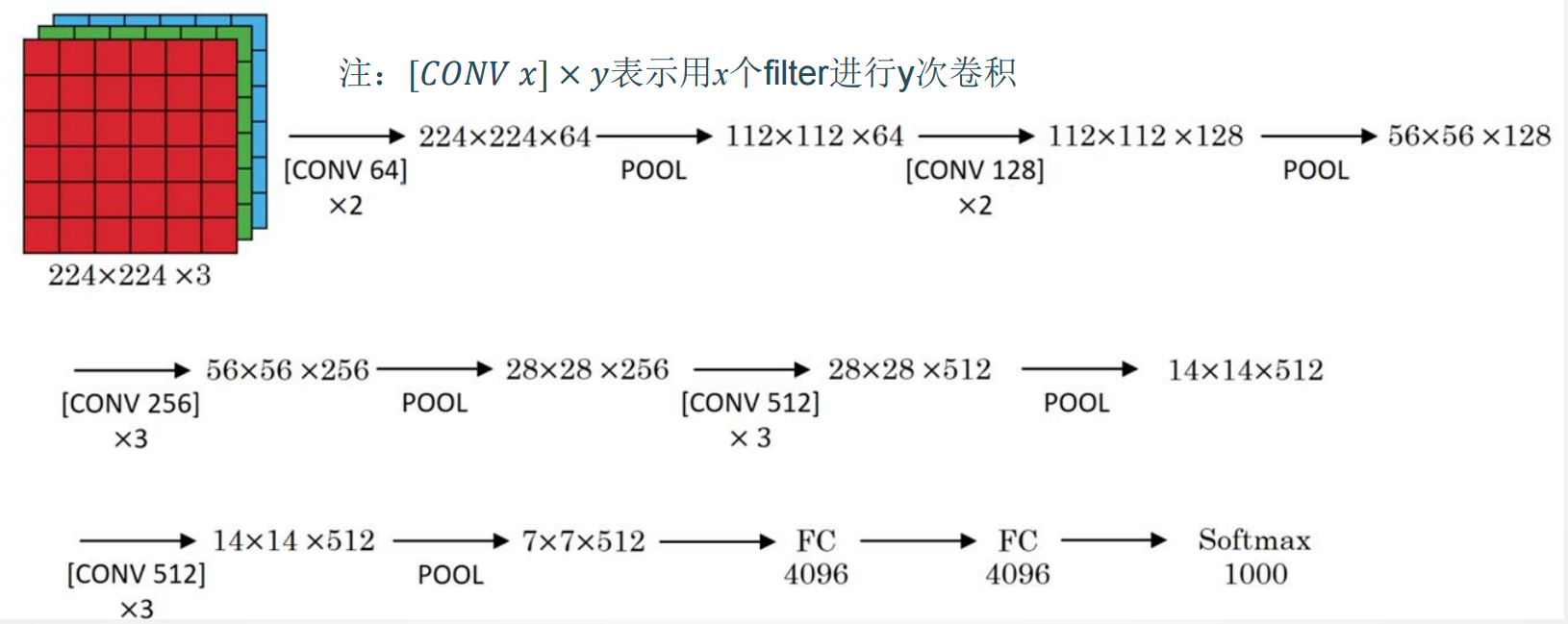
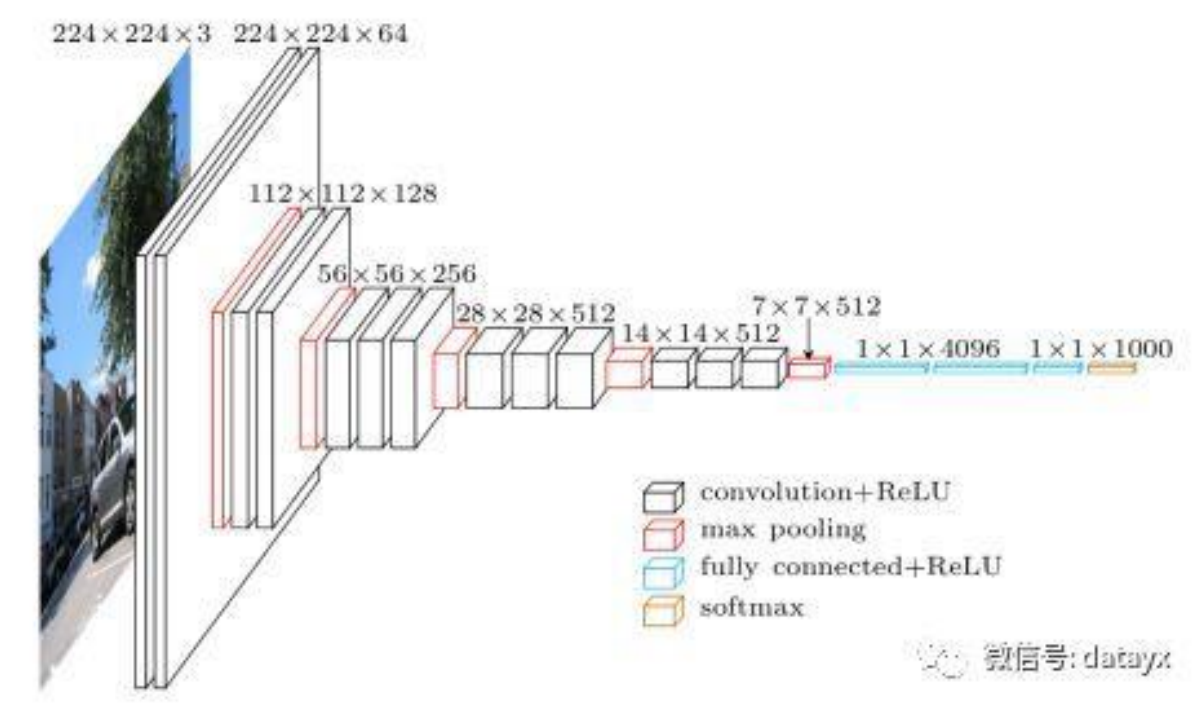
网络说明
改进
- 网络规模进一步增大,参数数量约为1.38亿
- 由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。
普遍规律
- 随网络深入,高和宽衰减,通道数增多。
3.残差网络
非残差网络的缺陷——梯度消失问题



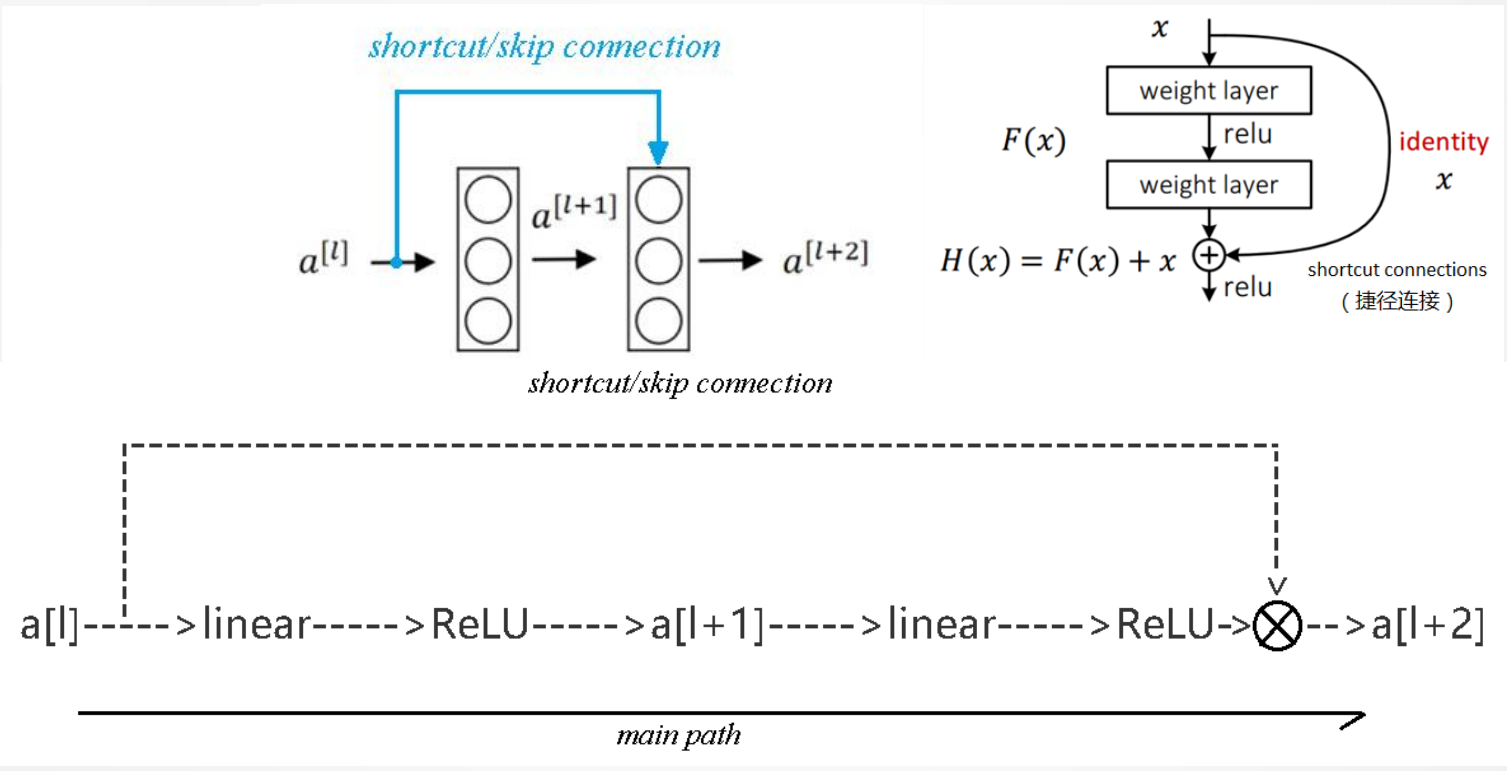
构建残差网络
残差块
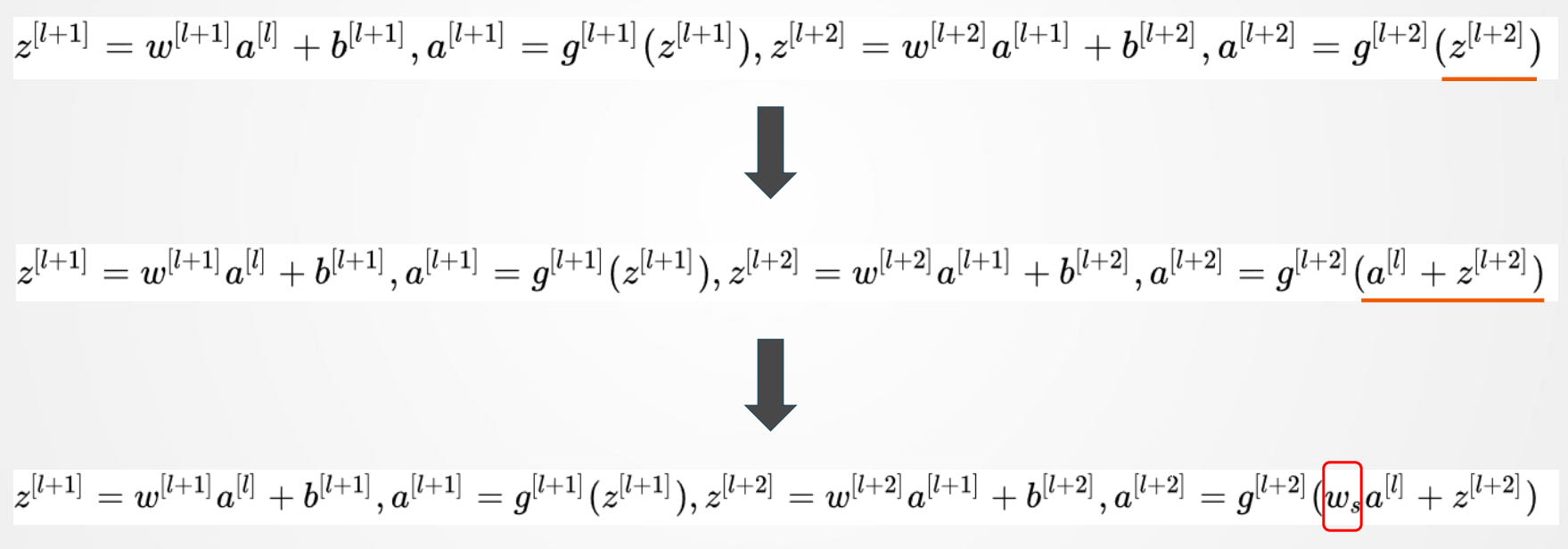
残差网络
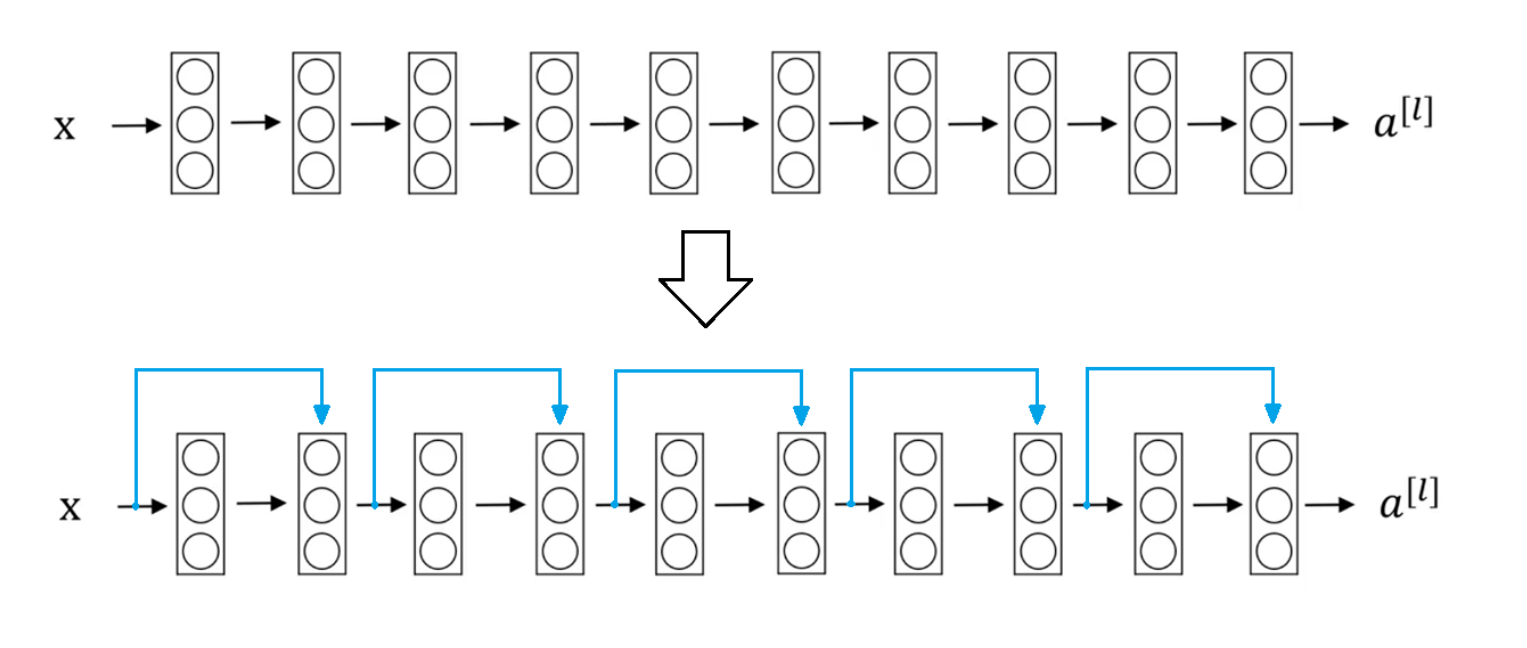
残差网络结构
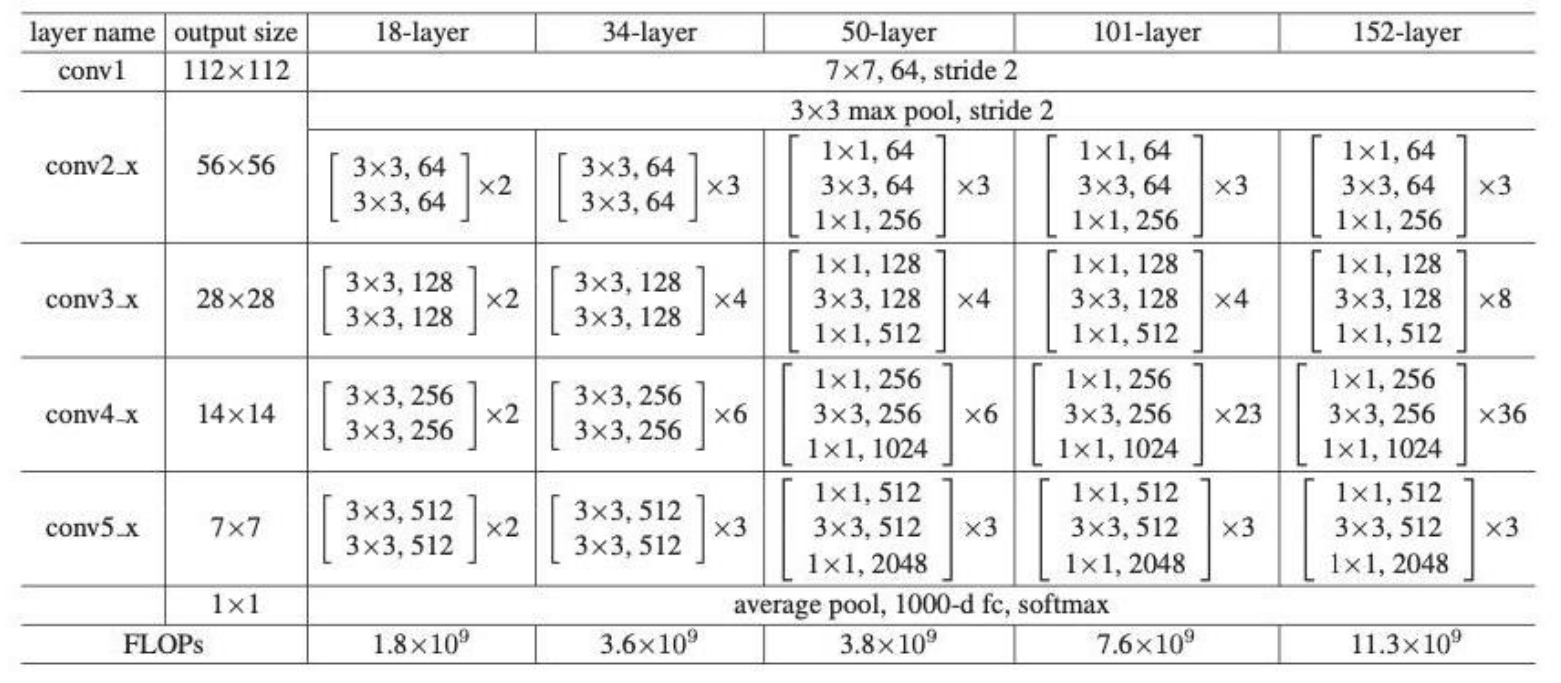
- 普通网络的基准模型受VGG网络的启发
- 卷积层主要有3×3的过滤器,并遵循两个简单的设计规则:①对输出特征图的尺寸相同的各层,都有相同数量的过滤器; ②如果特征图的大小减半,那么过滤器的数量就增加一倍,以保证每一层的时间复杂度相同。
- ResNet模型比VGG网络更少的过滤器和更低的复杂性。ResNet具有34层的权重层,有36亿FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
六、深度学习视觉应用
1.常用数据集
MNIST:MNIST 数据集主要由一些手写数字的图片和相应的标签组成,图片一共有 10 类,分别对应从 0~9。MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
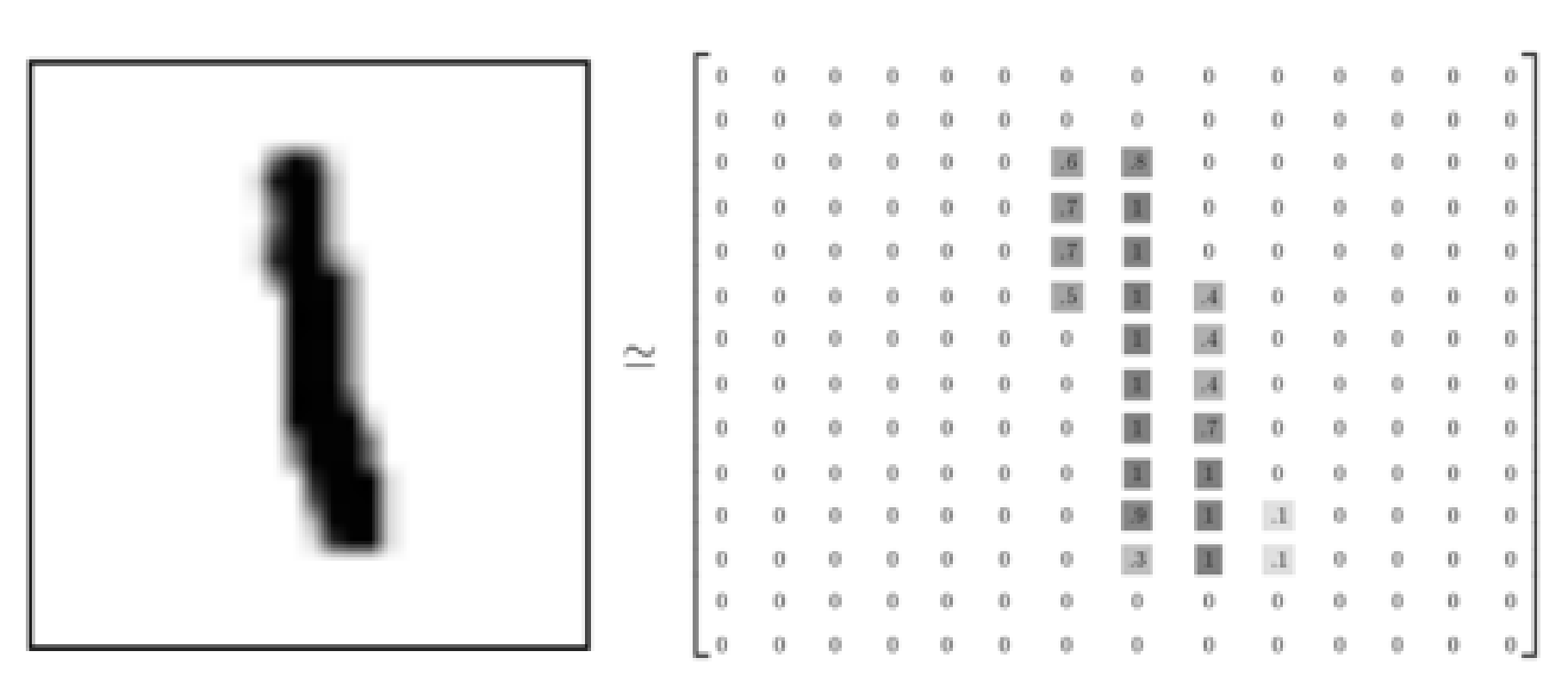
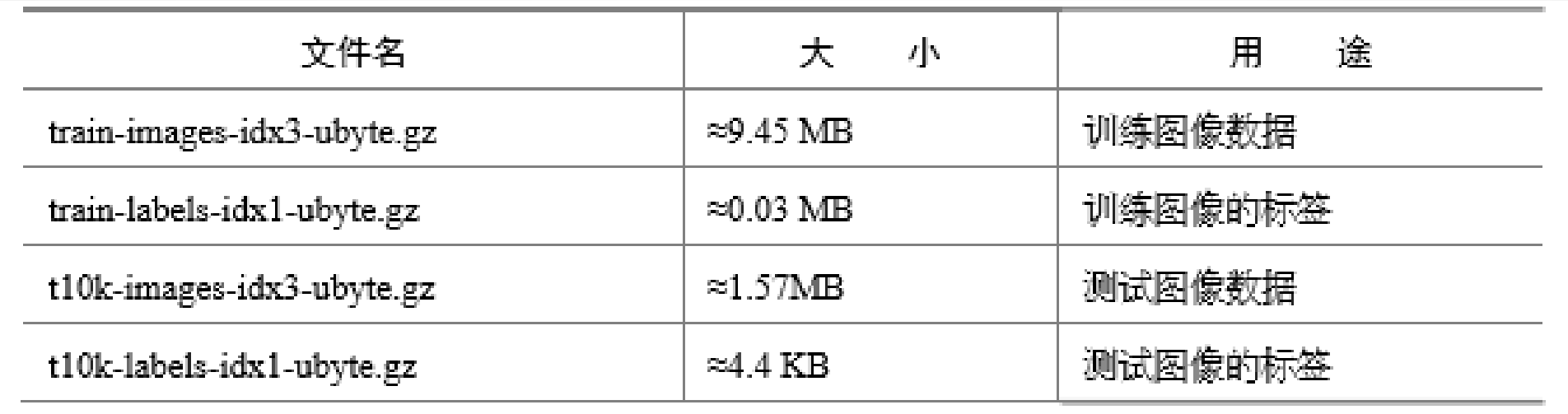
原始的 MNIST 数据库一共包含下面 4 个文件
Fashion-MNIST数据集
- FashionMNIST 是一个替代 MNIST 手写数字集 的图像数据集。它是由 Zalando旗下的研究部门提供,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
- FashionMNIST 的大小、格式和训练集/测试集划分与原始的MNIST 完全一致。60000/10000 的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
以下是数据集中的类,以及来自每个类的10个随机图像:

CIFAR-10数据集
- CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像
- 数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像
以下是数据集中的类,以及来自每个类的10个随机图像:

PASCAL VOC数据集
- PASCAL的全称是Pattern Analysis, Statistical Modelling and Computational Learning
- VOC的全称是Visual Object Classes
- 目标分类(识别)、检测、分割最常用的数据集之一
- 第一届PASCAL VOC举办于2005年,2012年终止。常用的是PASCAL 2012
一共分成20类:
- person
- bird, cat, cow, dog, horse, sheep
- aeroplane, bicycle, boat, bus, car, motorbike, train
- bottle, chair, dining table, potted plant, sofa, tv/monitor
文件格式:
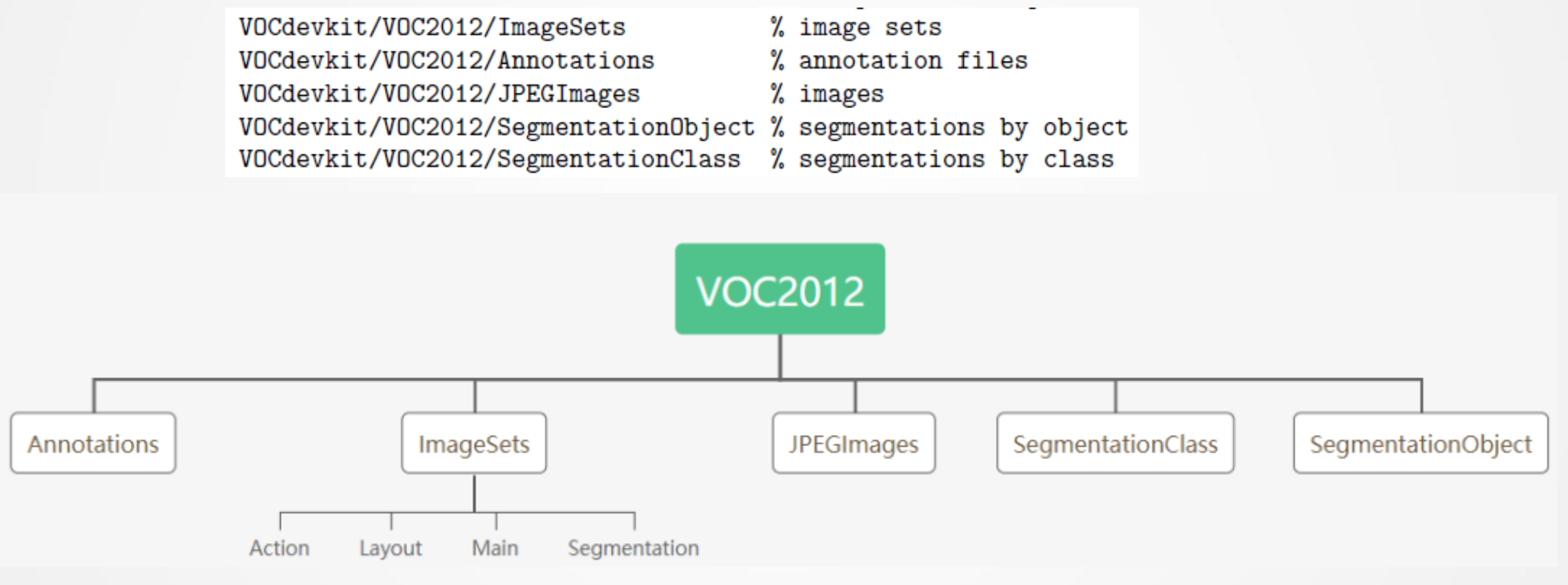
20类图像实例:

MS COCO数据集
- MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集
- 数据集以scene understanding为目标,主要从复杂的日常场景中截取
- 包含目标分类(识别)、检测、分割、语义标注等数据集
- ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆
- 官网:http://cocodataset.org
提供的标注类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
- 人:1类
- 交通工具:8类,自行车,汽车等
- 公路常见:5类,信号灯,停车标志等
- 动物:10类,猫狗等
- 携带物品:5类,背包,雨伞等
- 运动器材:10类,飞盘,滑雪板,网球拍等。
- 厨房餐具:7类,瓶子,勺子等
- 水果及食品:10类
- 家庭用品:7类,椅子、床,电视等
- 家庭常见物品:17类,笔记本,鼠标,遥控器等
MS COCO数据集示例

ImageNet数据集
- 始于2009年,李飞飞与Google的合作:“ImageNet: A Large-Scale Hierarchical Image Database”
- 总图像数据:14,197,122
- 总类别数:21841
- 带有标记框的图像数:1,034,908
谷歌JFT-300M
- JFT-300M 是用于训练图像分类模型的内部 Google 数据集
- 3 亿张图像产生超过 10 亿个标签(单个图像可以有多个标签)
- 在十亿个图像标签中,大约有 3.75 亿个是通过算法选择的,该算法旨在最大限度地提高所选图像的标签精度该算法旨在最大限度地
2.评价指标
精确率与召回率
- TP: 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
- FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
- FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
- TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
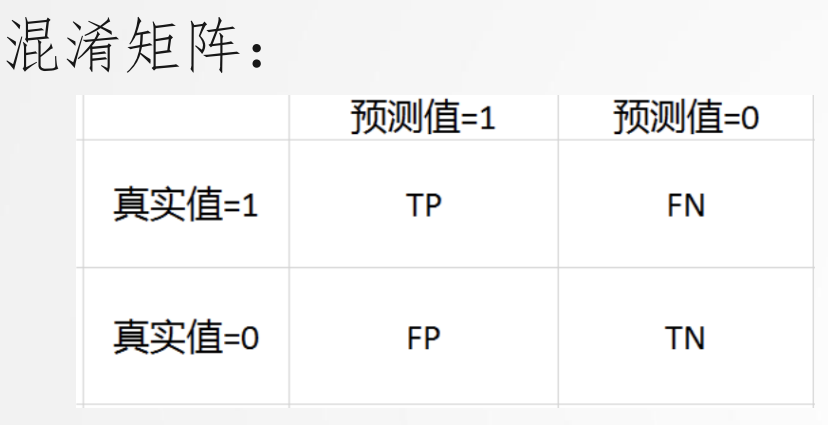
P(精确率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑃),标识“挑剔”的程度
R(召回率): 𝑇𝑃/(𝑇𝑃 + 𝐹𝑁)。召回率越高,准确度越低标识“通过”的程度
精度(Accuracy): (𝑇𝑃 + 𝑇𝑁)/(𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁)
P-R曲线:P-R的关系曲线图,表示了召回率和准确率之间的关系,精度(准确率)越高,召回率越低
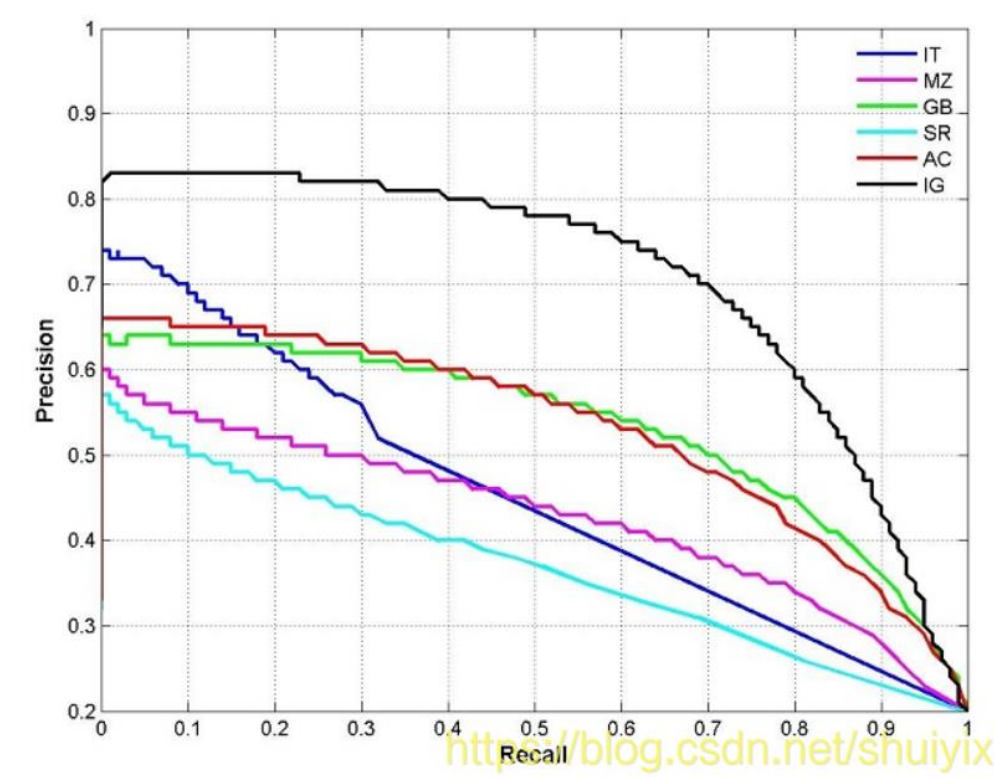
平均精度
AP:平均准确率
其中𝑁代表测试集中所有图片的个数,𝑃(𝑘)表示在能识别出𝑘个图片的时候Precision的值,而 Δ𝑟(𝑘)则表示识别图片个数从𝑘 − 1变化到𝑘时(通过调整阈值)Recall值的变化情况。
3.目标检测与YOLO
目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
目标检测问题发展
R-CNN——SPP NET——Fast R-CNN——Faster R-CNN——最终实现YOLO
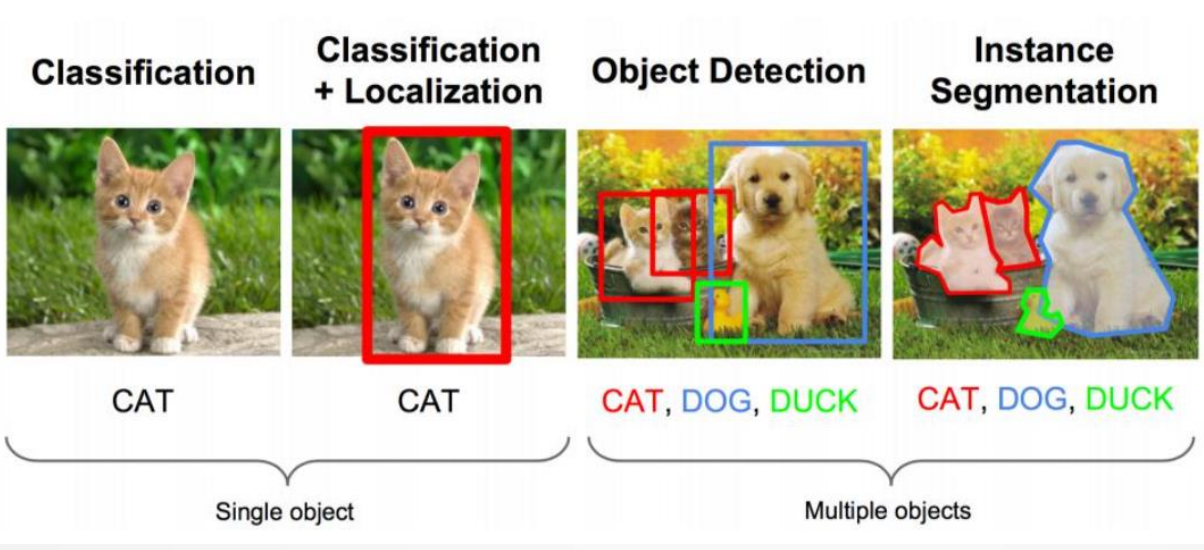
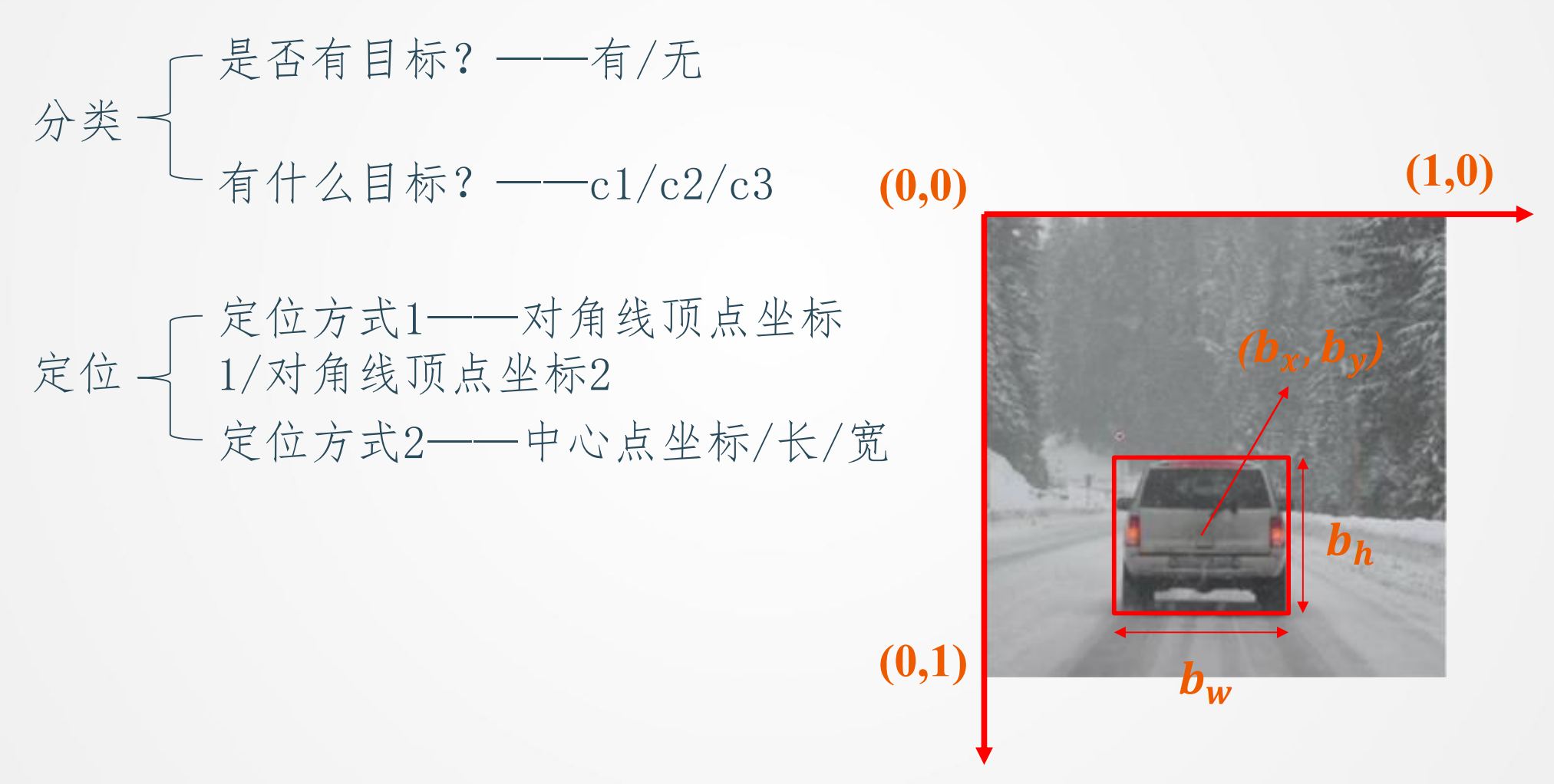
分类问题与目标检测

数据集输出表达

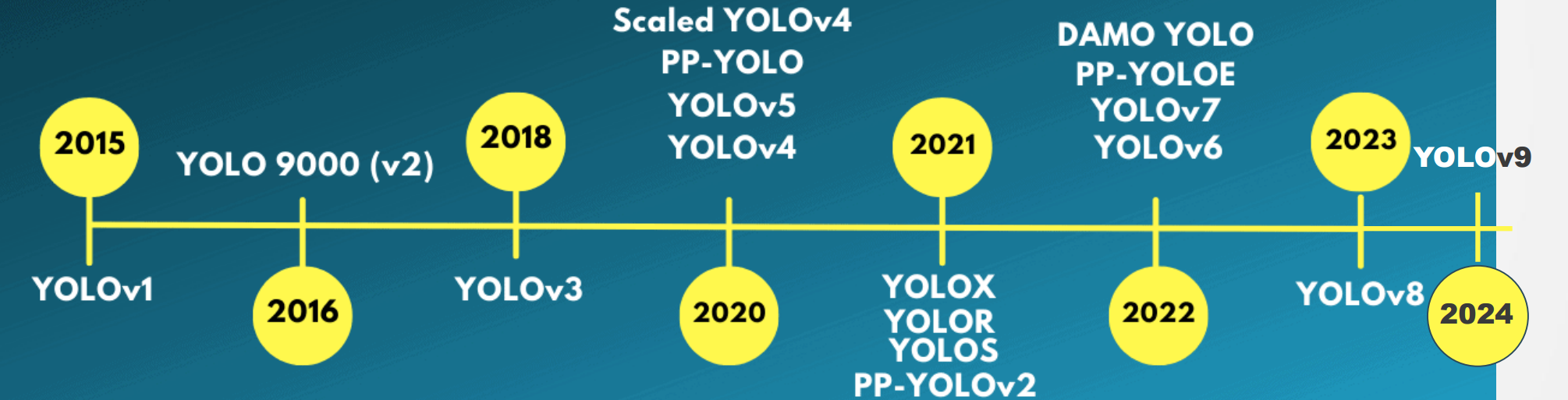
YOLO家族发展
一步法(two-stage):无需候选框,直接出最终结果。
 目标检测基本思想
目标检测基本思想
滑动窗口
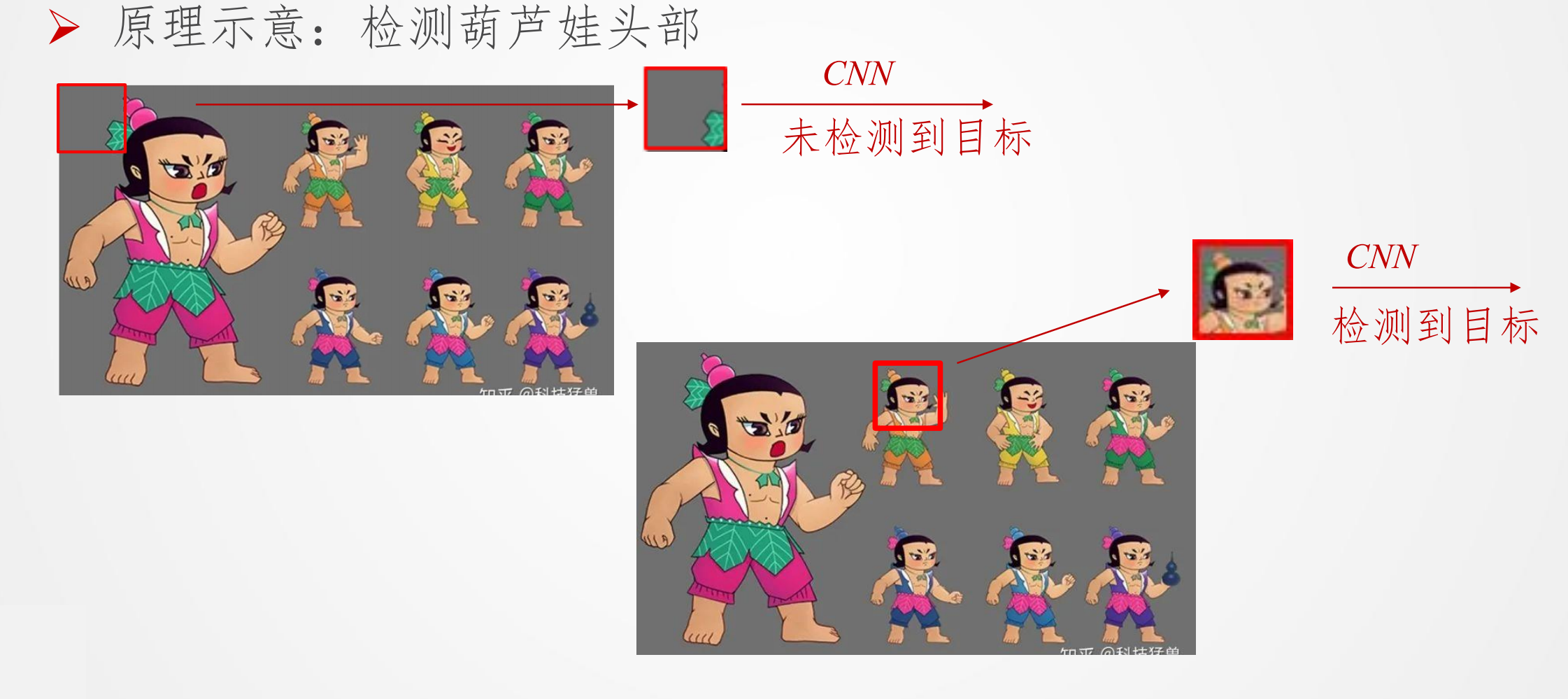
滑动窗口的问题:
1.滑动次数太多,计算太慢
假设图片为𝑤宽,ℎ高,识别一幅图片需要𝑇时间,则需要:𝑤 ∗ ℎ ∗ 𝑇的总时间。
例如:图片大小448 × 448,识别一个目标需要0.05s,则:总时间= 448 ∗ 448 ∗ 0.05 ≈ 10000𝑠,约3小时!
2.目标大小不同,每一个滑动位置需要用很多框
图片宽度和高度都不相同,比例也不相同,因此需要取很多框。
例如:标准框100*50大小,
• 取50*50,50*25,200*50,200*100等不同大小,在面积和宽高比变化
• 假设面积变化3类(0.5,1,2), 宽高比3类(0.5,1,2),则共有9种。
总时间是原来的9倍:
总时间= 10000 × 9 = 90000𝑠,约1天3小时!
滑动窗口的改进:
- 一般图片中,大多数位置都不存在目标。
- 可以确定那些更有可能出现目标的位置,再有针对性的用CNN进行检测——两步法(Region Proposal)
- 两步法依然很费时!
- 进一步减少出现目标的位置,而且将目标分类检测和定位问题合在一个网络里——一步法(YOLO)
YOLO网络结构
YOLO网络结构概略图
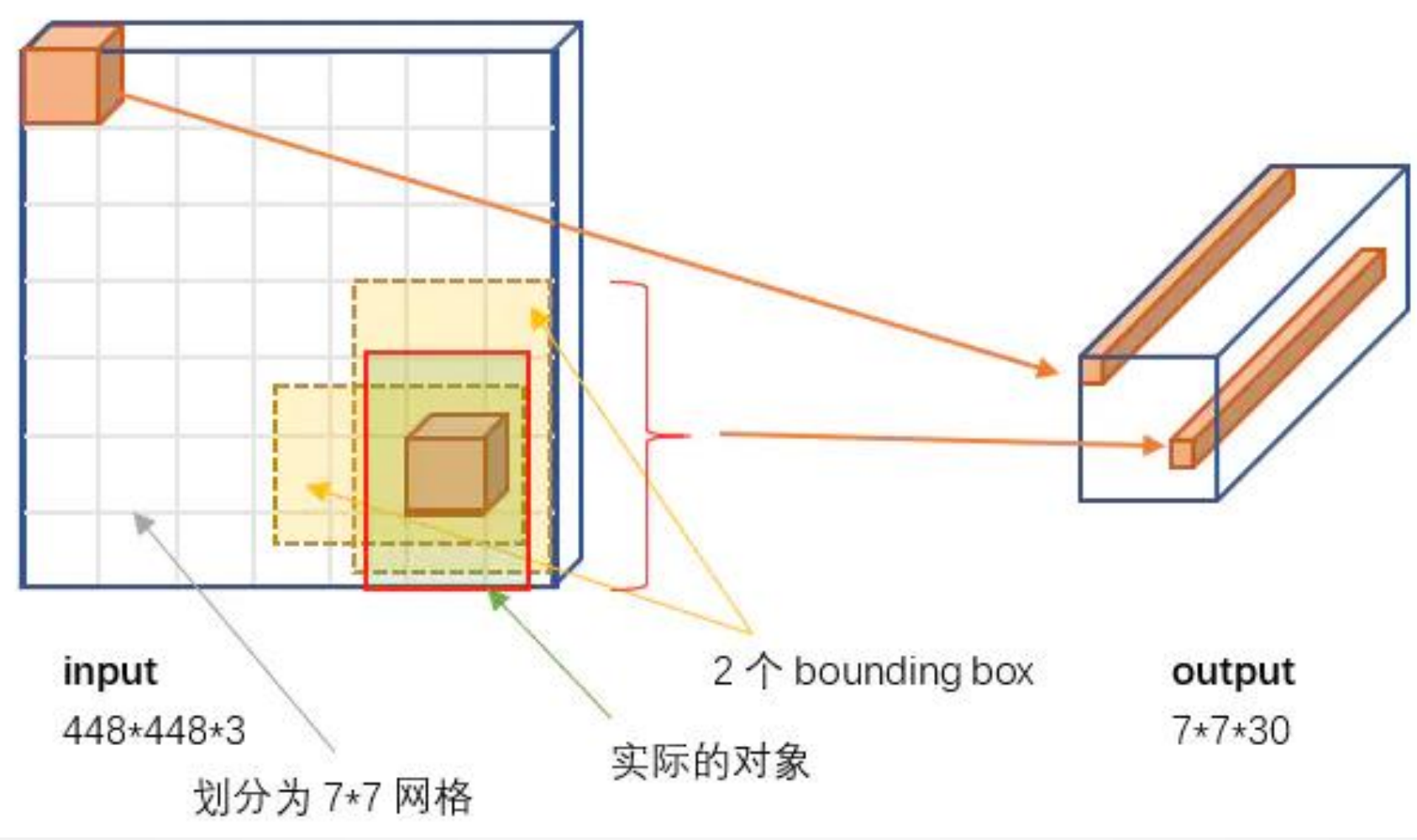
YOLO官方的模型结构图
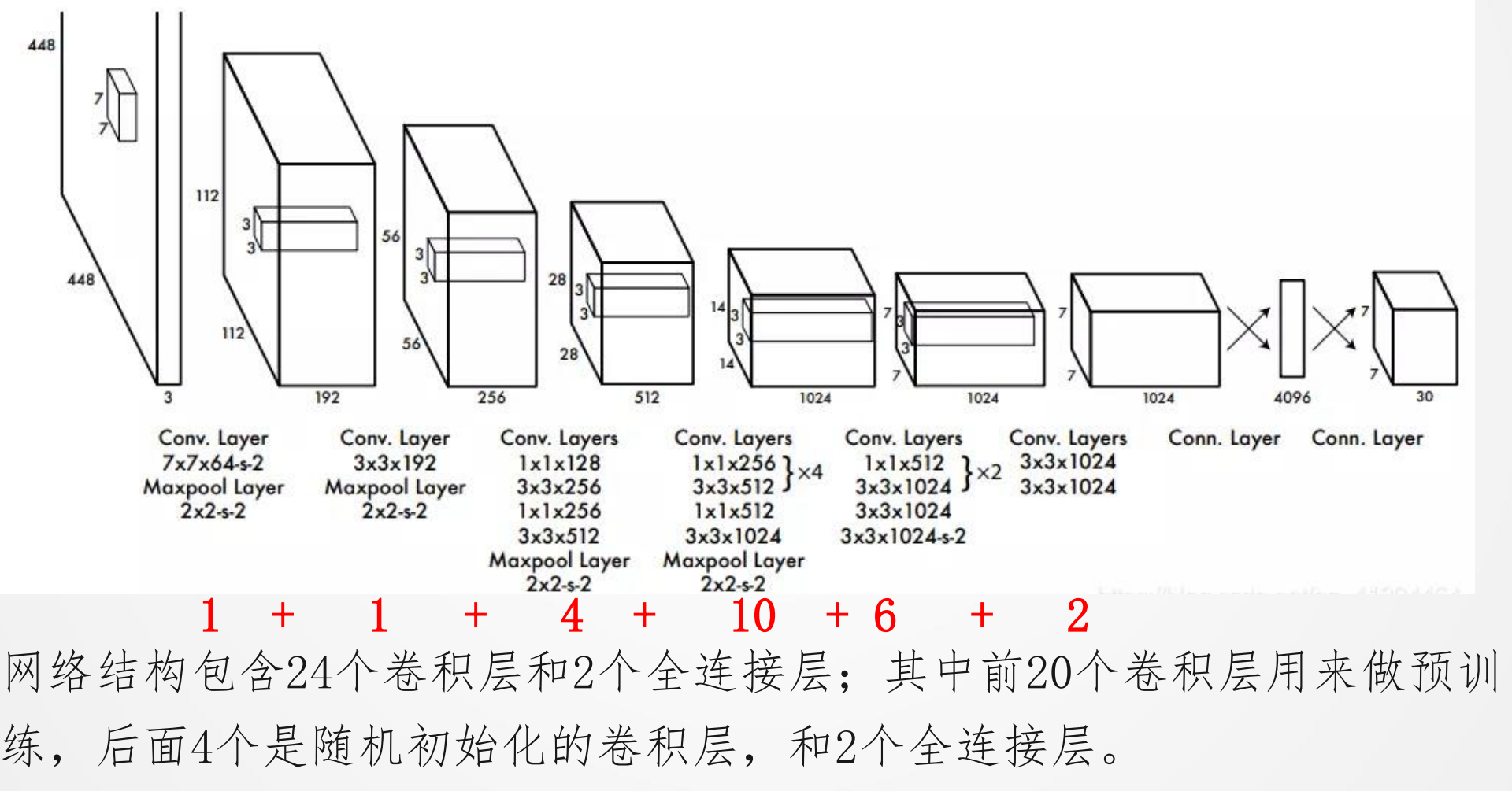
YOLO详细结构
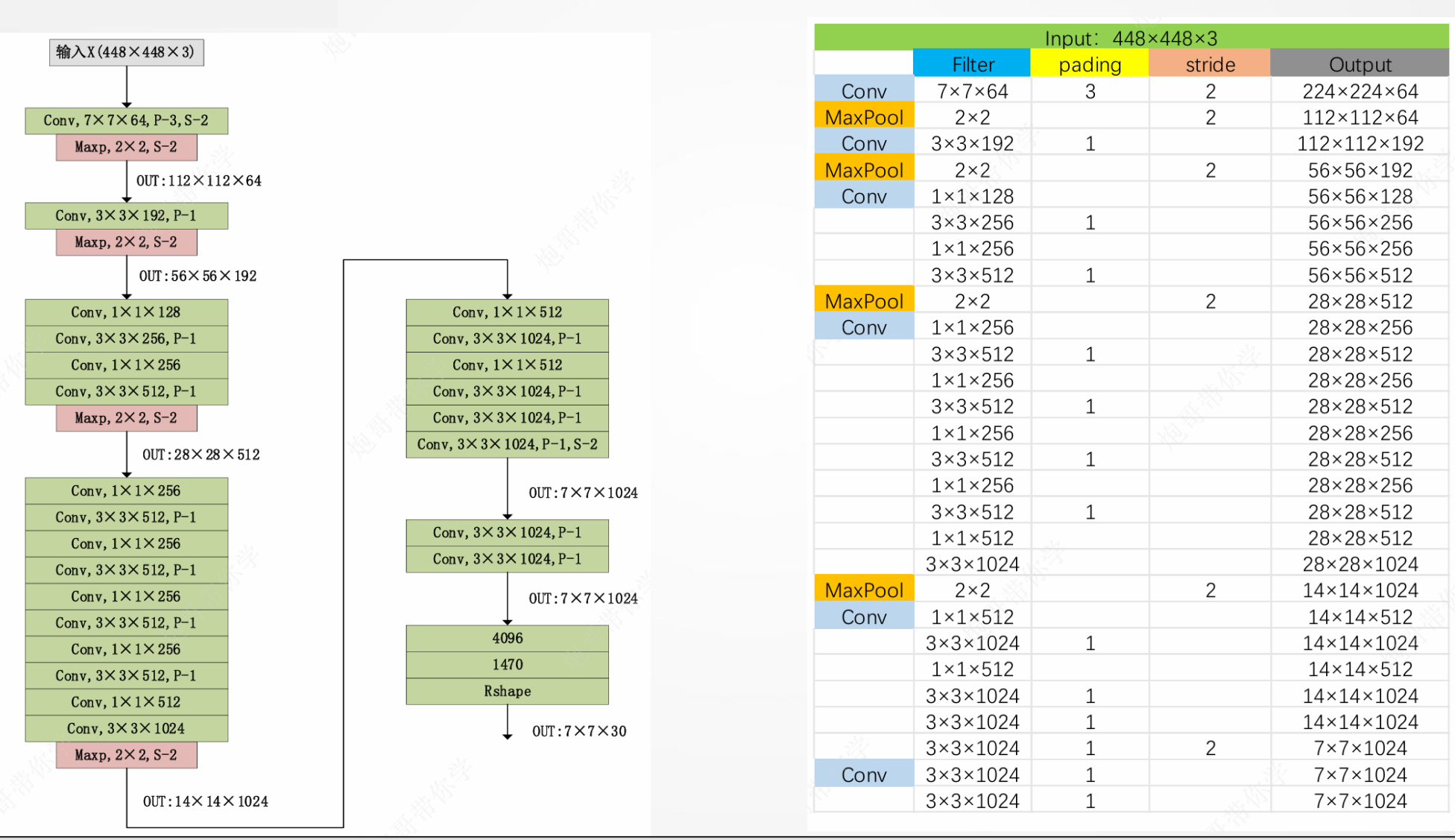
YOLO网络输入:YOLO v1在PASCAL VOC数据集上进行的训练,因此输入图片为448×448×3。实际中如为其它尺寸,需要resize或切割成要求尺寸。
YOLO模型处理:𝟕 × 𝟕网格划分
- 将图片分割为
个grid(S = 7),每个grid cell的大小都是相等的。
- 每个格子都可以检测是否包含目标。
- YOLO v1中,每个格子只能检测一种物体(但可以不同大小)。
YOLO网络输出:
输出是一个7 × 7 × 30的张量。对应7 × 7个cell
每个cell对应2个包围框(boundingbox, bb),预测不同大小和宽高比,对应检测不同目标。每个bb有5个分量,分别是物体的中心位置(𝑥, 𝑦)和它的高(ℎ)和宽(𝑤),以及这次预测的置信度。
YOLO模型输出:
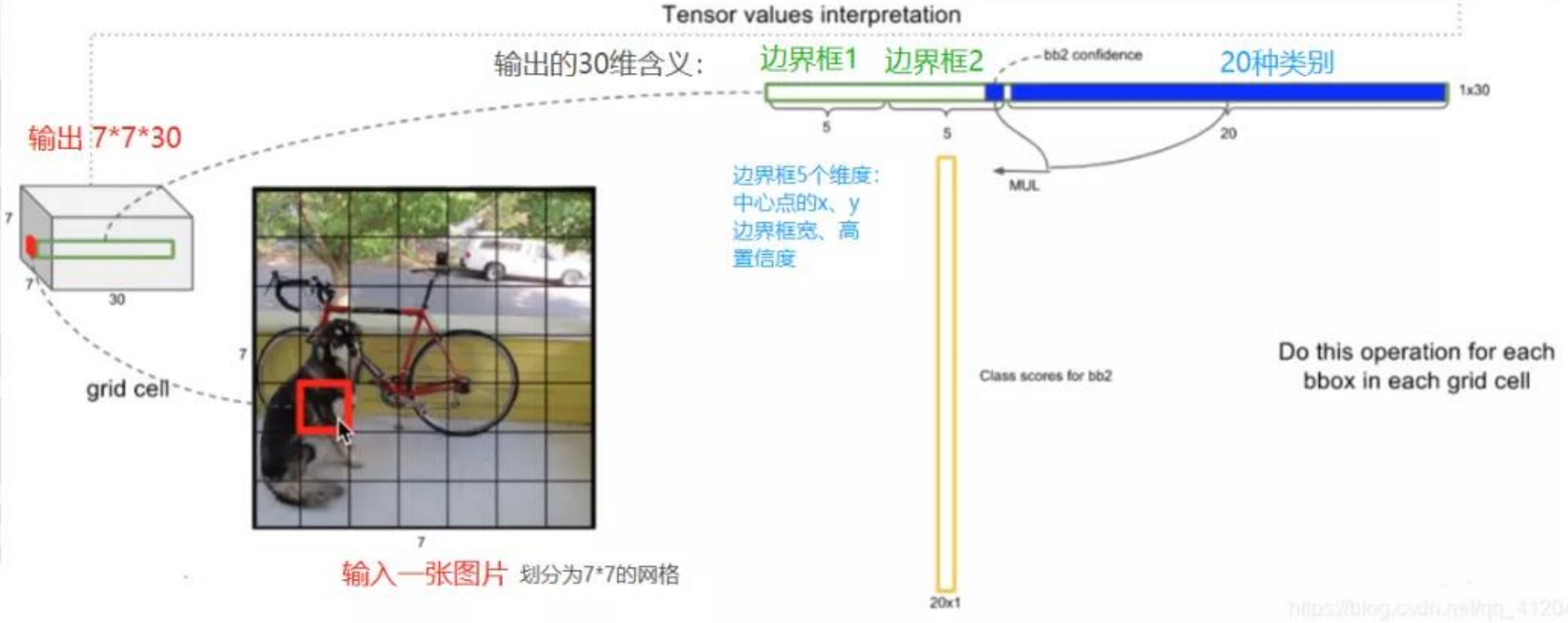
在上面的例子中,图片被分成了49个框,每个框预测2个bb,因此上面的图中有98个bb



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











