






原文:TRex Frequently Asked Questions
TRex team<trex.tgen@gmail.com>
version 0.2
1. FAQ
1.1. 常规
1.1.1. TREX是什么?
TRex是基于DPDK、运行在标准英特尔处理器上的快速、真实的开源流量生成工具。它支持有状态和无状态两种流量生成模式。
1.1.2.TRex的常见用例是什么?
- 具有TCP栈的有状态网络设备的大规模基准测试,比如:防火墙/NAT/DPI(数据处理设备)
- 模拟大规模DDOS攻击,参考Why TRex is Our Choice of Traffic Generator Software
- 对交换机进行大规模灵活性测试(e.g. RFC2544)- 参考fd.io
- 针对大量客户端/服务器进行控制器的基准测试
- 电子设计验证测试(electronic design verification testing)和生产测试
- 路由协议测试,比如:OSPF/BGP/RIP
1.1.3.谁在用TRex?
Cisco systems, Intel, Imperva, Melanox, Vasona networks 等等.
1.1.4.什么是有状态和无状态操作模式?
“Stateful”模式用于测试网络设备,该设备可以保存每个流(5元组)的状态。通常这是通过在被测设备的成对接口上注入预先录制的捕获文件,并动态更改src/dst IP/port来完成的。在高级有状态模式下,它通过在TCP/UDP协议之上注入L7数据来完成。(这里可以理解为TRex可以解析抓取的pcap文件,修改源ip,源端口,目的ip,目的端口模拟大规模报文交互)
“Stateless”模式用于测试网络设备,该设备不会管理任何的流的任何状态(而是以每个数据包为基础进行操作)。这通常通过向被测设备注入定制的数据包流来完成。(这个感觉类似于pktgen)
详情参考 in-depth comparisson 。
1.1.5.TRex可以在具有虚拟网卡的虚拟机上运行吗?
可以,目前需要2-3个cpu和4GB内存。对于VM用例,如果需要,可以通过使用以下配置显著降低内存需求(以支持更少的并发流为代价)。configuration
限制:
- 使用vSwitch将最大PPS限制在1MPPS左右(DPDK-OVS/VPP可以解决这个问题)
- 延迟结果将不准确。
对于高性能设置(多队列),最好在trexd_cfg.yaml中添加rx_desc: 4096。详情参见 platform_yaml_cfg_argument and software mode。
1.1.6.哪些网卡被支持/为什么不是所有DPDK支持的网卡TRex都支持?
- 我们使用网卡的特定功能。并不是所有的网卡都具有我们需要的高速功能。
- 我们在实验室对每个推荐的网卡都进行了回归测试,我们不声称支持我们实验室中没有的网卡。你可以在这个连接中找到网卡的支持列表 here.重点看“Supported NIcs”表。
- 您仍然可以使用任何使用AF_PACKET PMD的linux网卡,但它不会具有低延迟/高性能。
1.1.7思科的虚拟机接口卡能支持吗?
可以,从2.12版本后开始支持,限制参考these limitations。特别要注意的是需要一个新的固件版本。VIC13xx/VIX12xx/VIX14xx
1.2.100Gbs NIC QSFP+能支持吗?
支持Mellanox Connect4/5 和Cisco VIC14xx。
1.2.1.有GUI吗?
有的,被不同的开发组进行开发,也是开源的。您可以在 here找到无状态模式和包编辑器的GUI。
1.2.2.每个TRex应用程序支持的最大端口数是多少?
32。
1.2.3.我无法看到TRex服务器上所有32个端口的统计信息
因为受到控制台空间限制,我们只显示前四个端口的统计信息。因为所有端口的计数都被纳入统计了,所以全局统计数据(比如total TX)都是正确的。您可以使用GUI/控制台或Python API来查看所有端口的统计信息。
1.2.4.我可以在同一台机器上运行多个TRex服务吗?
第一种选择是在同一台物理机器上安装多个VM来运行多个TRex实例。
第二种选择是使用不同的配置文件来运行不同的TRex实例(--cfg argument)
配置文件如下:
- port_limit: 2
version: 2
interfaces: ['86:00.2', '86:00.1'] <--- different ports
prefix: instance2 <--- unique prefix
zmq_pub_port: 4600 <--- unique ZMQ publisher port
zmq_rpc_port: 4601 <--- unique ZMQ RPC port
limit_memory: 1024 <--- limit used memory
...
platform: <--- this section should use unique cores
master_thread_id: 0
latency_thread_id: 1
dual_if:
- socket: 0
threads: [2,3,4]
...1.2.5.我可以在同一个TRex服务器实例中使用多种类型的端口吗?
不可以,配置文件中的所有端口的网卡类型必须一致。 想运行不同类型网卡的解决方法是运行多个TRex实例,请参见上面的小节。
1.2.6.在带有PCI直通的VM上运行TRex或在裸机上运行TRex,哪个更好?
这个答案依赖于你的预算和需求。裸机上运行TRex会有更低的延迟和更高的性能。VM具有通常使用VM时获得的优点。
1.2.7.我有哪些途径报告一个问题?
您有两个选择:
- 可以发送邮件到支持组:trex.tgen@gmail.com
- 可以在github页面开启一个问题
1.2.8.我的4x10Gb/秒端口的英特尔X710网卡,我无法获得线速?
4x10Gb 端口的x710da4fh 网卡发送64字节报文的最大速率是40MPPS(所有端口的和)(不能达到理论上60MPPS上限)。但它性能仍然好于达到~30MPPS的 Intel x520(82559 based)(一个网卡两个端口)。
1.2.9.TRex能在Azure/AWS上运行吗?
可以,Azure使用带有安全保障的Mellanox CX-4,详细支持见附录。它也支持AWS,但性能不同。
1.2.10.买哪一款Mellanox 100gbps更好?
对于CX-4,最好使用MCX456A-ECAT(双100gb端口),而不是MCX455A-ECAT(单100gb端口)。对于CX-5,最好使用ConnectX-5 Ex EN版本,该版本具有两个端口,运行速度更快(Ex)。部件号为MCX516A-CDAT (PCIe4.0)。MCX516A-CCAT和MCX515A-CCAT会慢一点。详情参见ConnectX-5
1.2.11.我的2x40Gb/秒端口的XL710网卡,我无法获得线速?
带有2个40G端口的XL710-da2可以达到最大速率是40MPPS/50Gb(所有端口的总数),而不是带有小数据包(64B)的60MPPS。英特尔在生产双端口网卡时考虑到了冗余用例,不打算达到80G线速。更多信息请参见 xl710_benchmark.html 。
1.2.12.TRex如何计算吞吐量,这部分源代码位于何处?
详情参考邮件列表here.
1.2.13.我想对这个项目有所贡献
你有几种方法可以提供帮助:
- 下载产品,使用它,并报告问题(如果没有问题,我们也会很高兴听到成功的故事)。
- 如果您使用该产品并有改进建议(对产品或文档),我们将很高兴听到。
- 如果你修复了一个bug,或者开发了一个新功能,我们非常欢迎你在GitHub中创建pull request。
更多详情参考 CONTRIBUTING
1.2.14.发布过程是怎样的?我如何知道新版本何时可用?
它是一个持续的集成。最新的内部版本在我们实验室的几个计划上进行了24/7回归测试。一旦我们测试充分,我们会发布到GitHub(通常每隔几周)。我们不会为每个新版本发送电子邮件,因为对某些人来说可能太频繁了。我们会在邮件列表中发布重要的特性。当然,你可以随时查看GitHub。
1.3.安装和启动
1.3.1.我可以在不安装的情况下试用TRex吗?
可以,有docker版本。
1.3.2.我如何获得TRex,我需要什么样的硬件?
你有如下选择:
1.3.3在操作系统安装过程中,屏幕倾斜/错误“超出范围”/分辨率不支持等。
- Fedora - 安装过程中选择"Troubleshooting"在基本图形模式下安装。
- Ubuntu - 试试Ubuntu服务器,它有文本安装。
- Centos 7.x/8.x
1.3.4.如何确定TRex端口和测试设备的端口之间的关系?
用下面的命令运行TRex,检查DUT接口上的传入数据包计数。
sudo ./t-rex-64 -f cap2/dns.yaml --lm 1 --lo -l 1000 -d 100
或者,您可以在无状态模式下运行TRex,从每个端口发送流量,并查看DUT接口上的计数器。
1.3.5.如何确定Virtual OS端口和Hypervisor端口的对应关系?
比较接口名字和MAC地址,比如:
> ifconfig
eth0 Link encap:Ethernet HWaddr 00:0c:29:2a:99:b2
...
> sudo ./dpdk_setup_ports.py -s
03:00.0 'VMXNET3 Ethernet Controller' if=eth0 drv=vmxnet3 unused=igb_uio如果在TRex 侧ifconfig 看不到网卡,运行:
sudo ./dpdk_nic_bind.py -b <driver name> 1 <PCI address> 2
1 driver name - vmxnet3 for VMXNET3 and e1000 for E1000
2 03:00.0 for example
We are planning to add MACs to ./dpdk_setup_ports.py -s1.3.6.TRex流量不能被Wireshark 抓取,所以我无法捕获来自TRex端口的流量?
TRex使用DPDK获取端口的所有权(操作系统这时不能操作此端口),因此使用Wireshark是不可能抓到数据包的。可以使用带端口镜像的交换机捕获流量。(前提是TRex和被测设备之间使用交换机进行连接)
1.3.7.第一次运行,igb_uio.ko问题
Q
Command:
sudo ./t-rex-64 -f cap2/dns.yaml -c 4 -m 1 -d 10 -1 1000
Output:
Loading kernel drivers for the first time
ERROR: We don’t have precompiled igb_uio.ko module for your kernel version
Will try compiling automatically.
Automatic compilation failed.
You can try compiling yourself, using the following commands:
$cd ko/src
$make
$make install
$cd -
Then try to run TRex again
A
对于被支持操作系统的常见内核,通常我们已经预编译了igb_uio.ko。如果您使用不同的内核(由于软件包更新或操作系统版本略有不同),则需要编译该模块。
只需按照上面打印的说明操作即可。
注意:你可能需要额外的Linux软件包:
-
Fedora/CentOS:
-
sudo yum install kernel-devel-`uname -r`
-
sudo yum group install "Development tools"
-
-
Ubuntu:
-
sudo apt install linux-headers-`uname -r`
-
sudo apt install build-essential
-
1.3.8.在ESXI/KVM中运行TRex,出现WATCHDOG crash
错误如下:
terminate called after throwing an instance of 'std::runtime_error'
what(): WATCHDOG: task 'ZMQ sync request-response' has not responded for more than 1.58321 seconds - timeout is 1 seconds
*** traceback follows ***
./_t-rex-64-o() [0x48aa96]
/lib/x86_64-linux-gnu/libpthread.so.0(+0x10340)
__poll + 45
/home/trex/v2.05/libzmq.so.3(+0x26642)
/home/trex/v2.05/libzmq.so.3(+0x183da)
/home/trex/v2.05/libzmq.so.3(+0x274c3)
/home/trex/v2.05/libzmq.so.3(+0x27b95)
/home/trex/v2.05/libzmq.so.3(+0x3afe9)
TrexRpcServerReqRes::fetch_one_request(std::string&)
TrexRpcServerReqRes::_rpc_thread_cb() + 1062
/usr/lib/x86_64-linux-gnu/libstdc++.so.6(+0xb1a40)
/lib/x86_64-linux-gnu/libpthread.so.0(+0x8182)
clone + 109- 设置不少于8G的RAM:如果没有足够的RAM,尝试设置low_end 标识: Low end
- 设置将TRex VM的HT Core sharing设置成None:
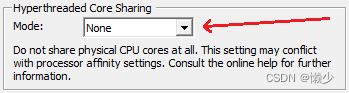 (或者关闭HT,设置内核亲和性,不同的虚拟机不能共享cpu核)
(或者关闭HT,设置内核亲和性,不同的虚拟机不能共享cpu核)
1.4.有状态
1.4.1.TRex有状态模式怎么使用?
首先准备YAML配置文件,参考here,然后,你可以在here找到一些基本的例子。
1.4.2.TRex连接到交换机,我在TRex启动时观察到许多丢弃的数据包。
交换机可以在使能生成树功能。TRex在启动时重置端口,使交换机也重置端口,生成树在稳定之前会丢弃数据包。关闭生成树可以解决这种现象。在Cisco nexus上,您可以使用spanning-tree port type edge来执行此操作。您也可以使用-k <num> 标志启动TRex。这将在开始实际测试之前发送k秒的数据包,让生成树有时间稳定下来。这个问题我们将会在改进“Stateful” and “Stateless” RPC中解决。
1.4.3.我看不到任何RX包。
最常见的原因是MAC地址的问题。如果您的端口以环回方式连接,请仔细执行 this操作。
如果环回对您有效,请继续 here。
如果您在配置文件中手动设置了MAC地址,请再次检查是否正确。
如果你的配置文件中有ip和default_gw,你可以通过运行TRex 添加-d 1标志来调试初始ARP解析过程(将在初始化阶段后1秒停止TRex,所以你可以向上滚动并查看初始化阶段日志),和-v 1,这将列出ARP解析的结果(“dst MAC:…”)。你也可以试试-v 3,这将打印更多的调试信息,以及ARP数据包TX/RX交互和统计信息。
被测设备侧(DUT)— 如果配置了静态ARP,请检查配置是否正确。如果您依赖TRex免费ARP消息,请查看TRex初始化阶段后的DUT ARP表并验证其正确性。
1.4.4.为什么性能很低?
TRex的性能取决于许多因素:
- 确保trex_cfg.Yaml配置最优,请参阅手册中的"platform"部分
- 更多的并发流将降低性能
- 带有一/两个数据包的短流(e.g. cap2/dns.yaml )会获得最差的性能
1.4.5.TRex TCP栈基于哪个版本?
BSD4.3, 为了支持高规模的流和性能,代码进行了大量修改
1.4.6.如何运行YAML配置文件并将结果捕获到pcap文件中?
你可以使用模拟器。参见simulator,模拟器的输出可以加载到Excel中。CPS可以调优。
1.4.7.我想在TRex中发送更多的活跃流量,我该怎么做呢?
默认支持的最大流是1M(从TRex的角度来看)。DUT可能会有更多,因为老化较慢)。当活动流达到较高数量时,您将得到“out of memory”错误消息
为了支持更多的活动流,你应该在配置文件的“memory” 部分添加“dp_flows” 参数。详情参见here
example of CFG file
- port_limit : 4
version : 2
interfaces : ["02:00.0","02:00.1","84:00.0","84:00.1"] # list of the interfaces to bind run ./dpdk_nic_bind.py --status
memory :
dp_flows : 10048576 #11 more flows 10Mflows
1.4.8.加载一个大的YAML文件会引发一个错误,没有足够的内存用于特定的池2048?
您应该增大引发错误pool的参数,例如traffic_mbuf_2048
example of CFG file
- port_limit : 4
version : 2
interfaces : ["02:00.0","02:00.1","84:00.0","84:00.1"] # list of the interfaces to bind run ./dpdk_nic_bind.py --status
memory :
traffic_mbuf_2048 : 8000 #11 for mbuf for 2048
您可以在运行TRex时使用-v 7来验证配置是否有效
1.4.9.我想在DUT上有更多的活动流,我该怎么做呢?
在将TRex配置到其最大CPS容量之后,请考虑以下内容:由于老化的性质(DUT不知道流何时结束,而TRex知道),在UDP流的情况下,DUT将有更多的活动流。为了人为地增加TRex中活动流的长度,您可以在YAML文件中配置更大的IPG。这将使每个流持续更长时间。或者,您也可以增加PCAP文件中的IPG。
1.4.10.我得到一个错误:ip的数量应该至少是线程的数量。
client和server的数量范围应该至少是线程的数量。线程数等于(端口对数)* (-c value)
1.4.11.有些传入帧是SCTP类型的,为什么?
默认的延迟数据包是SCTP,您可以在命令行中省略-l ,或者将其更改为ICMP。有关更多信息,请参阅手册。
1.5.无状态
1.5.1.TRex无状态模式怎么使用?
首先准备YAML配置文件,参考here,然后,您可以在here查看无状态手册。您可以直接跳转到tutorials section。
1.5.2.是否支持pyATS作为客户端框架?
可以,支持python2和python3
1.5.3.Python API不能在我的Mac(ZMQ库问题)上工作
我们使用Python ZMQ包装器。它需要对每个平台进行编译,我们支持许多平台,但不是所有平台。如果ZMQ不是包的一部分,则需要为您的平台构建ZMQ。
from .trex_stl_client import STLClient, LoggerApi
File "../trex_stl_lib/trex_stl_client.py", line 7, in <module>
from .trex_stl_jsonrpc_client import JsonRpcClient, BatchMessage
File "../trex_stl_lib/trex_stl_jsonrpc_client.py", line 3, in <module>
import zmq
File "/home/shilwu/trex_client/external_libs/pyzmq-14.5.0/python2/fedora18/64bit/zmq/__init__.py", line 32, in <module>
_libzmq = ctypes.CDLL(bundled[0], mode=ctypes.RTLD_GLOBAL)
File "/usr/local/lib/python2.7/ctypes/__init__.py", line 365, in __init__
self._handle = _dlopen(self._name, mode)
OSError: /lib64/libc.so.6: version `GLIBC_2.14' not found (required by /home/shilwu/trex_client/external_libs/pyzmq-14.5.0/python2/fedora18/64bit/zmq/libzmq.so.3)1.5.4.是否支持多用户?
支持。多个TRex客户端可以连接到同一个TRex服务器。
1.5.5.我可以创建损坏的数据包吗?
可以。您可以使用Scapy构建任何想要的包。但是,没有办法创建损坏的L1字段数据包(如以太网FCS),因为这些通常由NIC硬件处理。
1.5.6.为什么性能很低?
会降低性能的主要因素有:
- 太多的并发流。
- 复杂的编程字段。
添加“cache”指令可以提高性能。参见here
可以试试:
$start -f stl/udp_1pkt_src_ip_split.py -m 100%
vm = STLScVmRaw( [ STLVmFlowVar ( "ip_src",
min_value="10.0.0.1",
max_value="10.0.0.255",
size=4, step=1,op="inc"),
STLVmWrFlowVar (fv_name="ip_src",
pkt_offset= "IP.src" ),
STLVmFixIpv4(offset = "IP")
],
split_by_field = "ip_src",
cache_size =255 # the cache size 1
);1 cache
1.5.7.我想生成免费的IPv6 ARP/NS 。
参考here的例子。
1.5.8.我如何创建确定性随机流变量?
对每个流使用random_seed
return STLStream(packet = pkt,
random_seed = 0x1234,
mode = STLTXCont())1.5.9.我可以在不同的流变量之间进行同步吗?
不可以。每个流都有自己独立的字段引擎程序。
1.5.10.Java/TCL API而不是Python API
Java SDK
1.5.11.我在哪里可以找到使用TRex的RFC2544的参考?
1.5.12.你推荐TRex HLTAPI吗?
TRex对HLTAPI有最低限度的基本支持。对于简单的用例(没有延迟和每个流统计),它可能会工作。对于高级用例,原生API没有替代方法,原生API具有完全的控制权,并且在大多数情况下更易于使用。
1.5.13.我可以使用TRex测试Qos吗?
可以。使用Field Engine,你可以用不同的TOS构建流,并获得每个流的统计数据/延迟/抖动。
1.5.14.TRex可以模拟的支持的路由协议有哪些?
See Bird
1.5.15.延迟和流统计信息
延迟流是否支持线速?
不支持。延迟流由rx软件处理,只有一个核心来处理流量。为了解决这个问题,你可以创建一个较低速度的延迟流(例如PPS=1K),和另一个相同类型的没有延迟的流。延迟流将对DUT队列进行采样。例如,如果所需的延迟分辨率为10usec,则不需要以高于100KPPS的速度发送延迟流——通常队列是随时间构建的,因此不可能出现一个数据包有延迟而同一路径上的另一个数据包没有相同延迟的情况。无延迟流可以是全线速率(例如100MPPS)。
Example
stream = [STLStream(packet = pkt,
mode = STLTXCont(pps=1)), 1
# latency stream
STLStream(packet = pkt,
mode = STLTXCont(pps=1000),
flow_stats = STLFlowLatencyStats(pg_id = 12+port_id)) 21 非延迟流将被放大
2 延迟流,速度将恒定1KPPS
延迟流具有恒定的1PPS速率,并且不会被倍增器放大。为什么?
这样做的原因(除了是CPU受限的特性之外)是,大多数情况下,加载到DUT的用例使用一些通信流,并使用不同的流检查延迟。延迟流是一种“测试探针”,当你在测试其他流速率时你想让它保持恒定的速率。因此,您可以使用倍增器放大你的主要流量,而无需放大你的“测试探针”。
以下示例:
stream = [STLStream(packet = pkt,
mode = STLTXCont(pps=1)), 1
# latency stream
STLStream(packet = STLPktBuilder(pkt = base_pkt/pad_latency),
mode = STLTXCont(pps=1000), 2
flow_stats = STLFlowLatencyStats(pg_id = 12+port_id))
]1 非延迟流
2 延迟流
如果你在启动API中指定10KPPS的倍率,则延迟流(#2)将保持1000 PPS的速率,而不会被放大。如果你确实想放大延迟流,你可以使用“tunables”来做到这一点。你可以在Python配置文件中添加一个“tunables”,它指定延迟流速率,你可以将其提供给控制台或API中的“start”命令。可调参数可以用通过终端命令“start … -t latency_rate=XXXXX” 或者直接使用Python API(自动化)STLProfile.load_py(…, latency_rate = XXXXX) 来添加。你可以在here看到定义和使用可调项的示例。
延迟和流统计数据不支持所有数据包类型。
对的。我们使用网卡功能来计算数据包或指导它们由软件处理。每个网卡都有自己的能力。在here查看流统计,在here 查看延迟详情。
我使用x710/xl710卡上的流统计和python API中的rx-bps计数器(以及控制台中与rx字节相关的计数器)
显示为 N/A
这是因为在这些卡类型上,我们使用硬件计数器(相较于其他卡类型中使用软件计数)。虽然这允许统计完整的40G线速流,但不允许统计字节(只有包计数可用),因为这些网卡上的硬件缺乏此支持。从2.21版本开始,新的“--no-hw-flow-stat”标志将使x710卡的行为与其他卡一样。
TPG的数据包在低速率下被丢弃
网卡或软件重定向环已满?你是否同时发送大量数据包?请增加rx描述符的数量大于突发数据包大小,或引入isg以避免突发。
TPG首包被丢弃
你应该尝试在开始时使用一个小的速率流来预热计数器。我们分配惰性计数器,对每个计数器收到的第一个数据包执行此操作。因此,为第一个数据包付出的代价高于其他数据包。此外,请确保您已经等待了足够的时间让Rx在查询数据包之前解析数据包,如无状态文档中的Tagged Packet Group部分所述。
1.6.Bird 整合
1.6.1.BIRD是什么?
BIRD是一个“Internet Routing Daemon”,一个运行在后台的非交互式程序,在Internet类型的网络中充当动态路由器。你可以在Bird’s Doc找到更多信息,或者阅览Bird Integration章节获取有用的教程。
1.6.2.我在哪里可以找到bird配置文件的示例?
bird/cfg目录包含一些简单的bird配置文件。其中一些文件包括路由协议(RIP, BGP, OSPF…),其他文件包括IPv4和IPv6路由示例。更多信息可以在Bird’s Configuration Doc找到。
1.6.3.如何创建Bird节点?
有两种方法:
- 使用Python API:首先创建一个客户端,然后使用它的set_bird_node函数。看看这里是怎么做的: stl/add_bird_node.py
- 使用TRex控制台:首先加载Bird插件:plugin load Bird然后添加节点:plugin Bird add_node -p 0 --mac 00:00:00:01:02:03。使用plugin bird add_node -h 查看全部可用参数。
1.6.4.我的DUT的MTU和Bird不匹配,该怎么办?
当使用client.set_bird_node(..)创建Bird节点时,传递MTU参数和所需的MTU值。另一种选择是使用 client.set_mtu(mac, mtu)方法,用于设置现有Bird节点的mtu。
1.6.5.我需要使用Bird的服务模式吗?
是的,必须启用服务模式。如果没有,至少应该启用具有正确掩码和--software的过滤模式。Bird的数据包比如BGP将被重定向到rx。你可以在 Stateless service mode 或者 ASTF service mode 找到更多的信息。
1.6.6.我应该使用服务模式还是服务过滤模式?
视情况而定。Full service模式将所有的数据包转发到rx,由client处理或被抓取。这将有性能损失,因为rx必须处理比平时更多的数据包,但是您可以确保在此过程中不会丢失任何数据包。而服务过滤模式则保留了无服务性能,并使用位掩码将需要的数据包过滤到rx。注意,过滤后的服务模式需要 --software。
1.6.7.新的软件模式是否有性能损失?
是的,因为在这种模式下,所有的数据包都被更灵活的过滤器接收和检查。通过使用合适的cpu核数和合适的配置,你仍然可以达到40-100gbps的线速,这是由于服务过滤模式只将需要的数据包转发给守护进程。
1.6.8.哪个TRex版本引入了服务过滤模式?
过滤器模式是在v2.71版本引入的。

















 2103
2103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









