








写在前面
这篇博客,一是补课,之前DataWhale的论文阅读,我因为参与课题申报等原因,没有仔细的去研读Bert系最新的几篇论文;二来,也是为自己带的预研团队开一个头,让坚持阅读原始论文和敢于创新能在一开始是就刻入我们团队的骨髓。
1 研究动机
本文并没有对于Bert模型架构有原创性的改动,而是将立足点放在如何更好的通过调参来挖掘Bert模型的潜能。这里的调参,除了传统意义的模型超参数外,也包括模型的一系列设计选择。
2 研究内容和方法
本文的研究方式,可以看成是非常传统的控制变量法的模式,来探究不同的设计决策对于Bert模型的影响。
- 静态遮词 vs 动态遮词
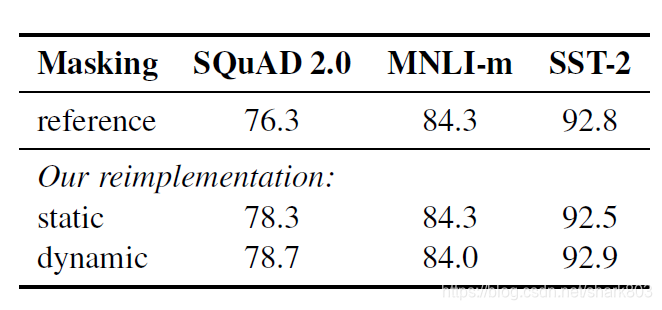
这是一个有意思的改进, 原版bert的预训练只会在训练开始随机选择15%的词进行遮掩,但是一经选定,就会固定下来,不论训练多少个epoch。而动态遮词,则是会将数据进行副本备份,然后不同的副本随机遮词。举例,如果训练40轮,有10个副本,那么则只有4个epoch是采用同样的遮词。下图引用了文章中给出的实验效果,从表格中的数据来看,动态遮词略有提升,但其实并不明显。作者给出的解释是尽管动态遮掩只有些微提升,但是考虑到其的其他效率优势,就在之后的实验中全部采用这种方式。
PS: 文中没有明确指出动态遮掩的其他优势,但我个人理解,其实是通过遮掩来做数据增强。
- NSP(下一句预测)任务的取舍
因为bert的下游任务中有MNLI这种判断两句关系的,所以在读bert的时候,大家是非常接受 bert对于两个任务的设定。论文中也说了学术界也对于去掉NSP是否会损失模型性能存在争议。
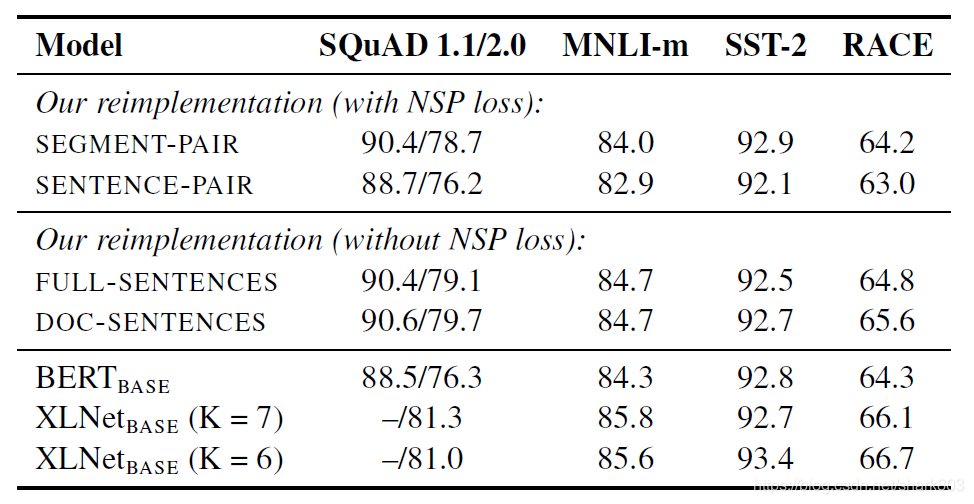
其实单句的sentence pair 因为文本长度不足,学不到长依赖肯定会损失性能,但是对于多句输入,NSP任务,是否必要,作者依然采用控制变量法来比较了 sentence-pair (Bert原版), full sentence (多句,甚至可以通过特殊分隔符实现跨文章),doc sentence(多句,不跨文章,但是需要动态调整batch size) 。前者添加NSP loss,后两者均不添加。下表数据表明,去掉NSP任务,会提高模型性能。个人理解,这也说明,预训练语言模型,最本质的性能提升手段还是学习长依赖。
- 输入策略选择
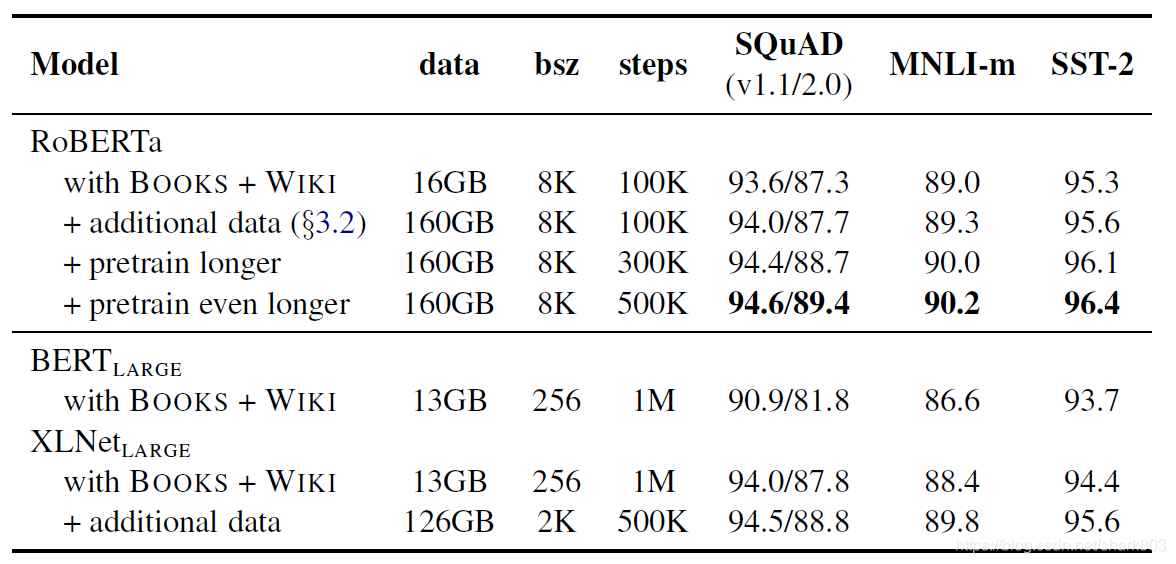
对于Bert 的输入,作者给出的结论是,选择尽可能大且多源的数据,尽可能大的batch,基于byte的词汇表。 对于batch的选择,测试结果如下表所示,选择大的batch,配合稍大的学习率,可以一定程度提高perplexity,以及下游任务的准确率。

- 综合调参
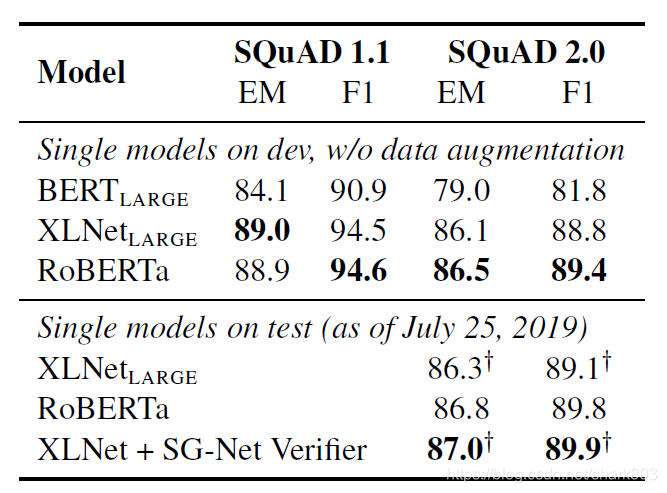
RoBERTa 全称一种鲁棒性的bert调优方法,当我们保持Bert_large架构不变,采用上述调参选择,对比原版Bert和XLnet结果如下,可以看出RoBERTa在squad, mnli和sst-2上都达到了STOA。
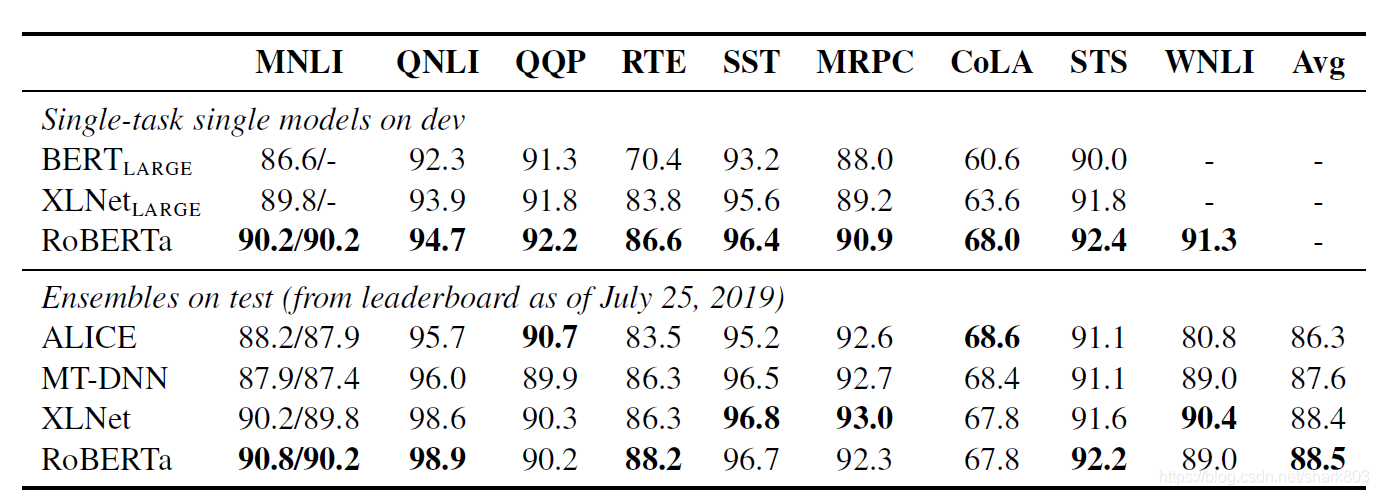
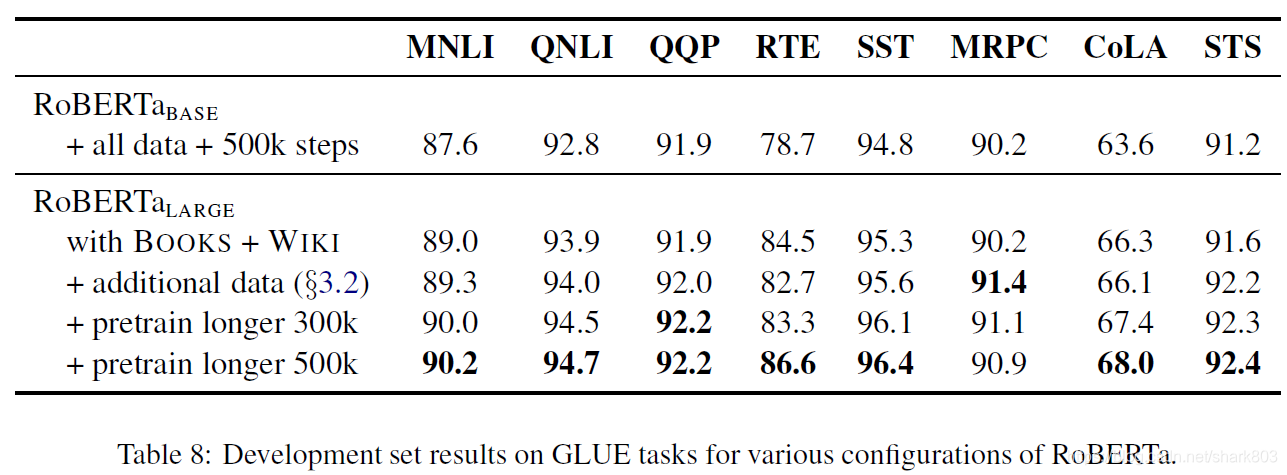
本文的实验部分后面还详细给出了RoBERTa 最好的结果,在三个benchmark GLUE, SQuaD and RACE上的表现,ROBERTa基本霸榜。这里简单贴一下实验结果,具体细节,可以参考论文的相关部分,相应的描述比较清晰。

5 超参数选择
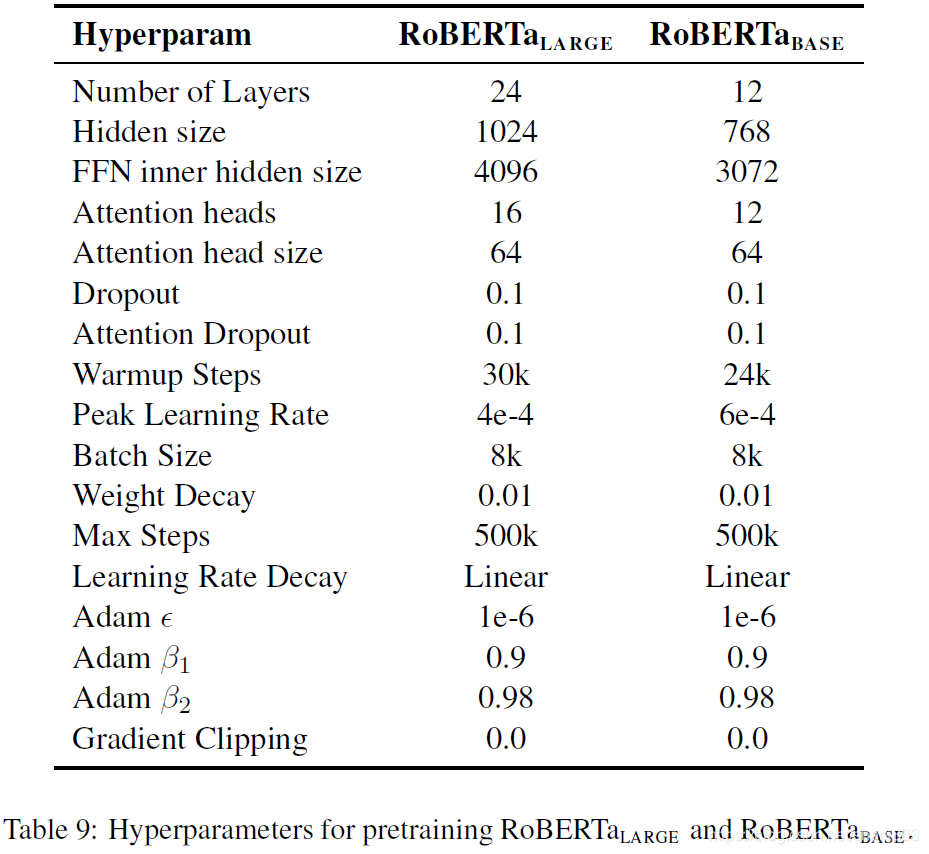
除了一些调参策略,作者也该出了具体任务的bert模型的最优参数,以及不同大小的模型预训练的超参数选择,这里也贴一下;
3 创新点分析和个人点评
之所以把创新点和个人点评合并,是个人认为这个工作虽然刷榜了GLUE等评测集,但是属于一个细致性的验证工作,并没有太多的创新。文章最大的贡献个人认为,是实验论证了NSP这个任务对于模型提升没有太大作用。至于动态遮掩,虽然是个好的方法,但是对于海量数据,以及大batch,大学习率效果是不是那么有效,有待进一步的验证或者数学上的解释。
但毋庸置疑,这是一个值得肯定的工作,甚至值得推崇。不知道什么时候,黑盒炼丹、调参侠成了对于深度学习从事着的一顶帽子,仿佛调参你上你也行,全凭玄学。实际上,玄学之说,更多的是自我嘲讽,调参恰恰是初入此道的基本功,对于模型和数据的理解和选择,其实是一个好的深度学习工程师必须走的路,也是需要时间和方法积累,这也远远好于git clone代码走通就走,不求甚解。所以,当你的算力和调参水平达到本文作者的程度,一样可以诞生有影响力的工作。 勿要眼高手低,与君共勉。















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









