







redo log相关
redo log了解嘛?给我介绍介绍它的作用吧
答: 这个是InnoDB存储引擎独有的日志,用于MySQL工作过程中宕机时进行数据恢复的文件,从而保证数据的持久性以及完整性。
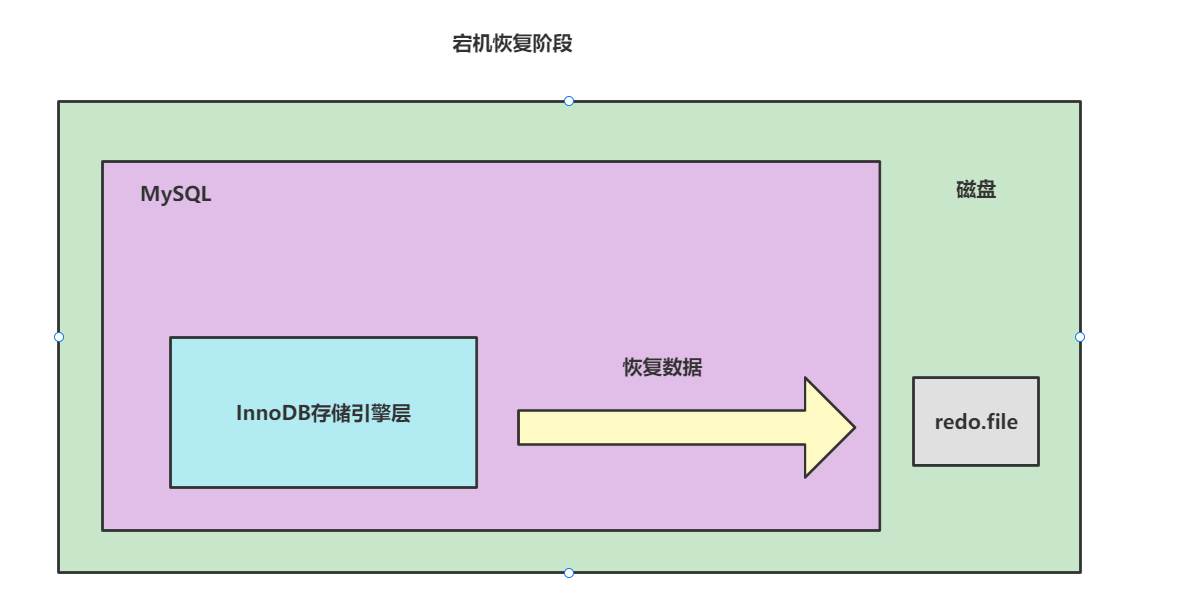
redo log是怎么工作的知道吗?
答: 我们都知道数据库数据基本单位也是和操作系统一致的,都是以页为单位,为了尽可能减少IO次数,MySQL在进行数据查询会优先将数据查询并存储到Buffer Pool中。这样下次再有相同的查询就可以直接去Buffer Pool中获取。
当我们从数据库中获取到数据并对其进行修改操作之后,这个修改操作就会优先被存放到redo log buffer中,最终就会被写入到redo log file中。
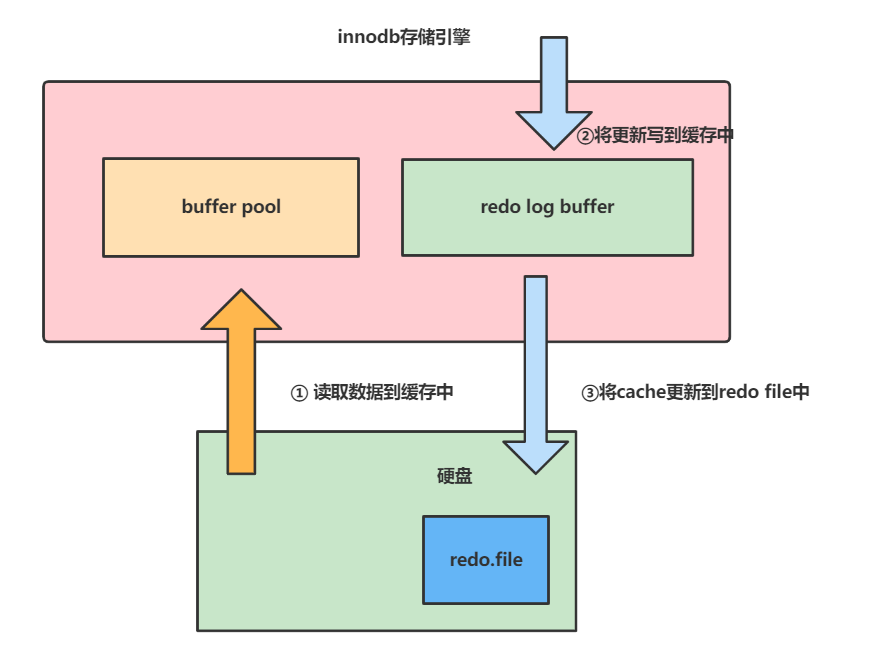
知道redo log的写入磁盘的时机嘛?
答: 写入磁盘的时机是由MySQL系统参数设置决定的,我们可以键入下面这条SQL查看innodb_flush_log_at_trx_commit这个参数的设定值
SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
这个参数的值有有1、2、3:
- 每次进行修改写入到
redo log buffer,然后redo log buffer会将数据写道page cache中,由log thread每个1s调用操作系统函数fsync将数据写入到redo.file中。很可能因为服务器崩溃或者宕机导致丢失1s的数据。

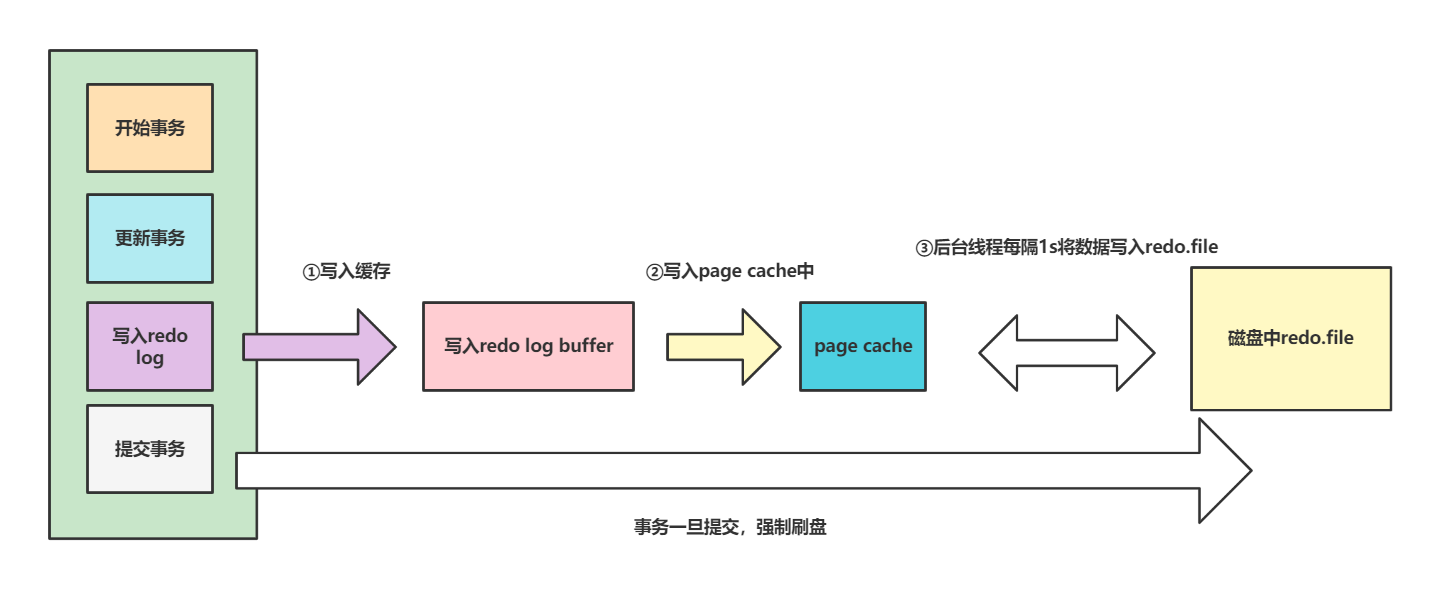
- 每次进行修改操作后将数据写入到
redo log buffer中,一旦事务被提交,就会自动调用操作系统函数fsync将数据写入的磁盘中的redo.file文件中。若设置为这个级别,当服务器宕机,若当前事务没有提交,这部分数据丢失也无妨,事务提交的话,那么这个操作就会被写到磁盘中,照样可以恢复。
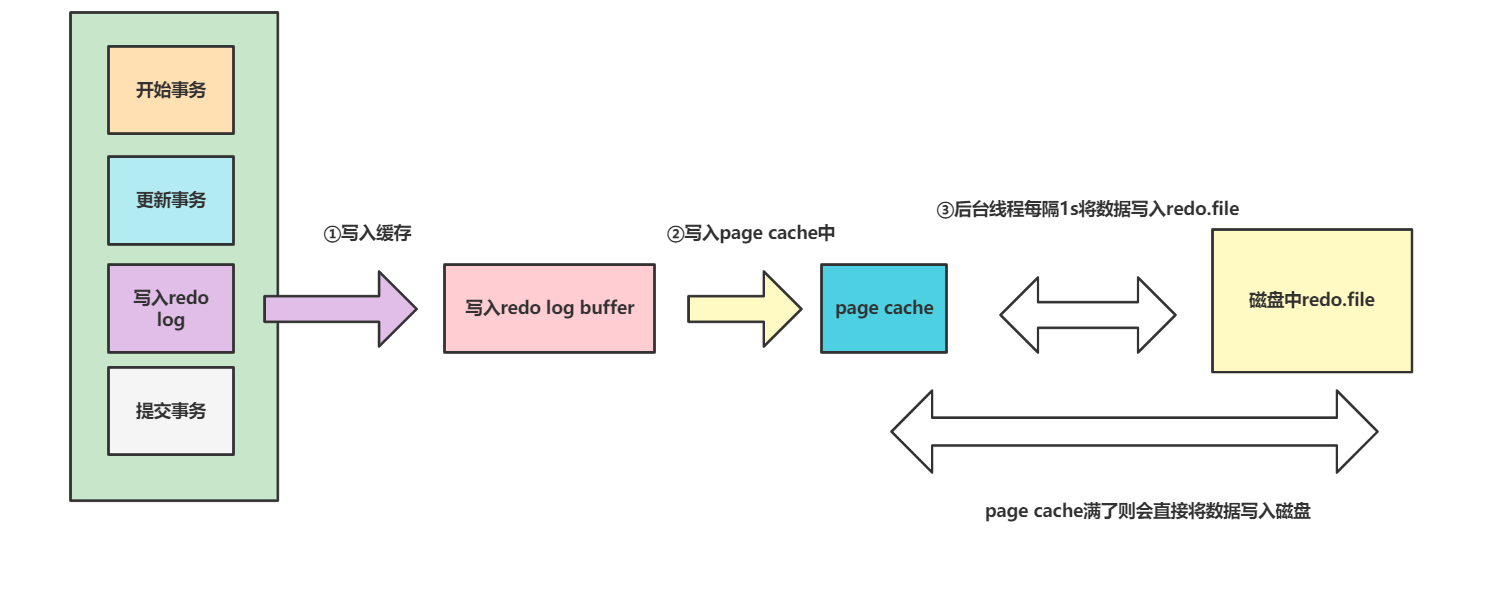
- 配置为3时整体是和1差不多的,区别是写入
page cache之后并不是每隔1s将数据写入到磁盘中,而是当page cache满了之后才会将数据写入到redo.file中。注意,设置为3出现宕机或者服务器挂了的情况,有可能会损失1s的数据。
日志文件组是什么?它是如何工作的?
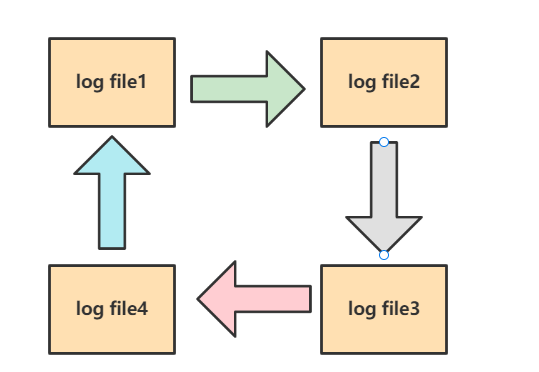
答: 其实我们上面所说的redo log并不是单指一个文件,它是由一组日志文件构成的,如下图所示,依次从从1开始写,文件1写满了,就将数据写到文件2,最后写到文件4。
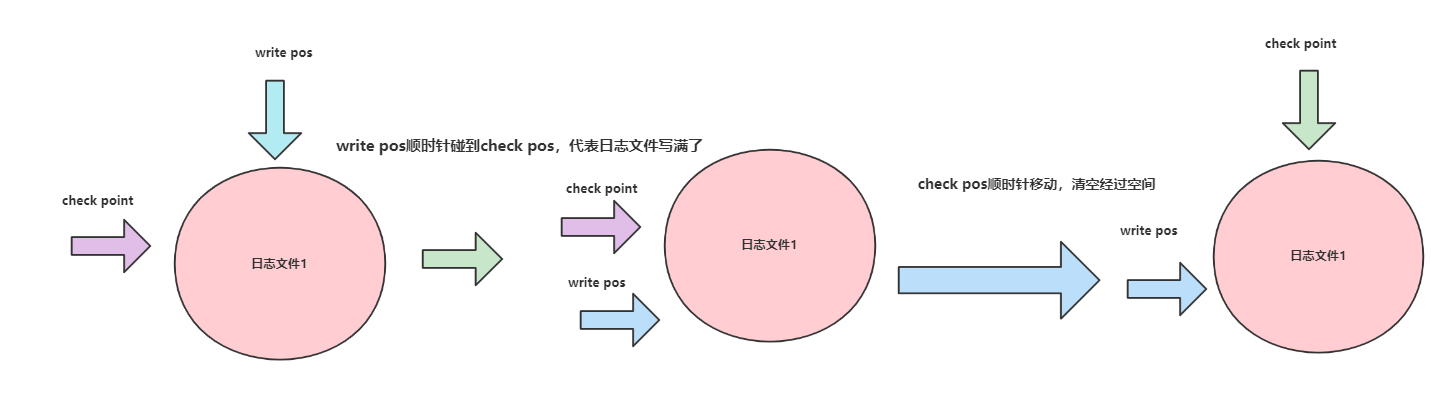
说完整体我们再来说说细节,如下图所示,每个日志文件写入时都是从write pos开始写,完成写入write pos后移,一旦write pos和checkpoint碰起来就说明文件满了,此时innodb就会通过让checkpoint往后移,所经过的位置就代表可以使用的位置,知道write pos再次和checkpoint碰起来,它才会继续往后移动。
我感觉redo log buffer没什么用,为什么InnoDB不索引直接将数据写入磁盘呢?
答: 页是操作系统的基本单位,一页差不多16kb,而我们每次操作的数据可能也就几byte,为了几byte的数据操作1页的数据未免有些大材小用了,所以我们将每次redo log数据写入到缓存,交由缓存按照一定时机进行刷盘。
binlog相关
bin log是什么?作用是什么呢?
答: bin log实际上是一个物理日志,当我们对某个数据页进行修改操作时我们就会将这个操作写到bin log中,当我们数据库需要进行主备、主从复制等操作时,都可以基于bin log保证数据一致性。
那bin log缓冲区了解嘛?
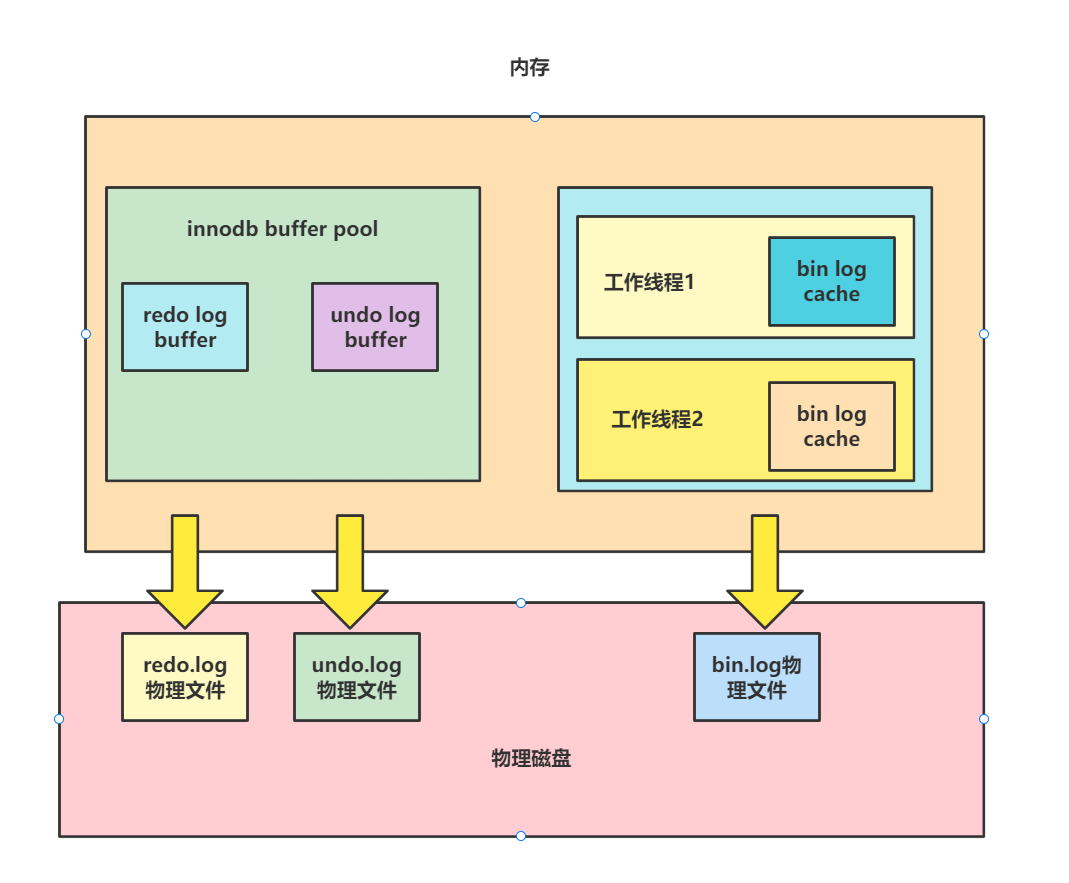
答: 如下图所示,bin log缓冲区和我们的redo log和undo log缓冲区有那么点不同,可以看到redo log和undo log缓存都在存储引擎的共享缓冲区缓冲区buffer pool中,而bin log则是为每个工作线程独立分配一个内存作为bin log缓冲区。
需要补充的是bin log之所以是在每个线程中,是为保证不同存储引擎的兼容性,bin log是innodb独有的,如果将bin log放到共享缓冲区时很可能导致兼容性问题,将bin log缓冲区设置为每个线程独享也保证了事务并发的安全性。
bin log记录格式有哪些知道吗?
答: 有三种,分别是:
row
这种格式主要用于保证数据实时性的,例如我们执行下面这段SQL
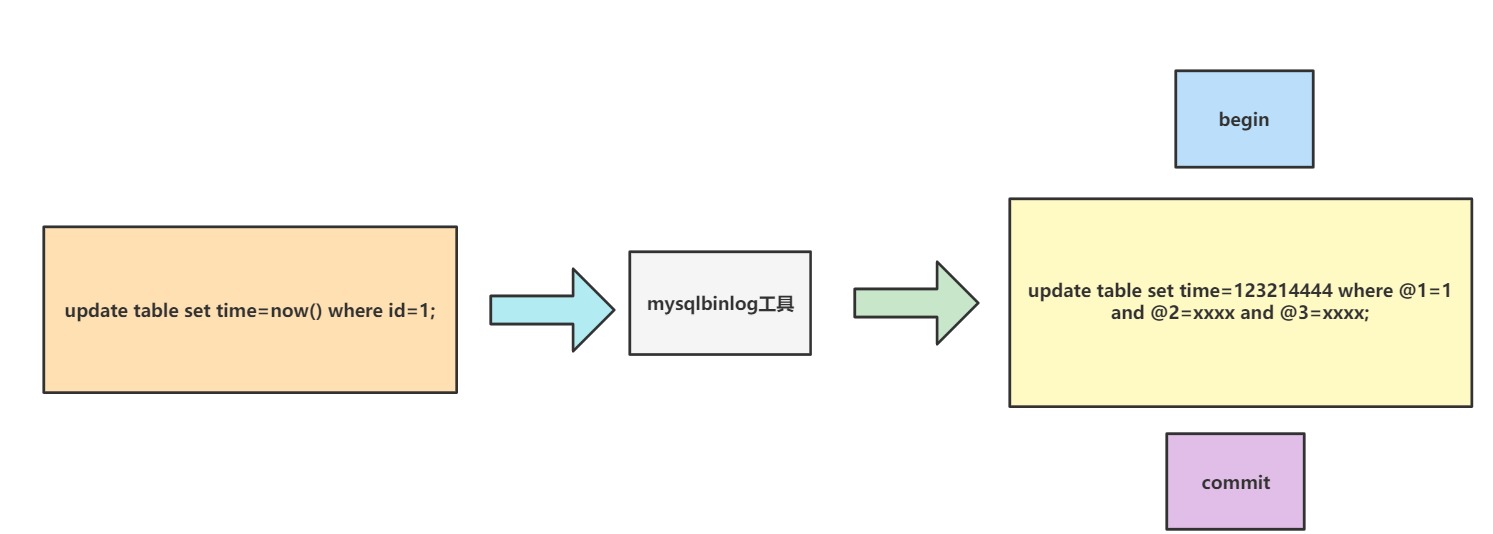
update table set time=now() where id=1;
如果我们将其存到bin log之后很长一段时间才提交事务完成修改,那么时间就会有所延迟,所以MySQL为了保证数据实时性,就会将写入bin log中的SQL用row格式,如下图所示,可以看到row格式的SQL语句时间是当前时间的具体值,并且where条件写死了当前条件列,确保数据一致性。
当然这样做的缺点也很明显,首先这条语句就非常占用内存,进行恢复和同步时,执行时间也是非常不友好的。
stament
这种就不多赘述了,语句长什么样存到bin log的就是什么样。
mixed
这种格式就是为了上述两种方案的混合体,如果操作可能出现数据不一致问题则用row格式,反之使用stament格式。
bin log文件日志格式知道吗?
答: 我们可以通过下面这条SQL语句看到我们本地的bin log文件
show binary logs;
输出结果如下所示,可以看到bin log的格式基本都是mysql-bin.0000xxx
mysql-bin.001606 440052 No
mysql-bin.001607 111520 No
bin log是怎么完成写入的知道嘛?
答: 整体流程如下图所示,当我们开始事务时,将修改写入bin log中,一旦事务提交,就会将bin log通过write写入到bin log cache中,然后根据我们配置的参数将cache内容调用操作系统内核方法fsync将结果写入到bin log 物理文件中。
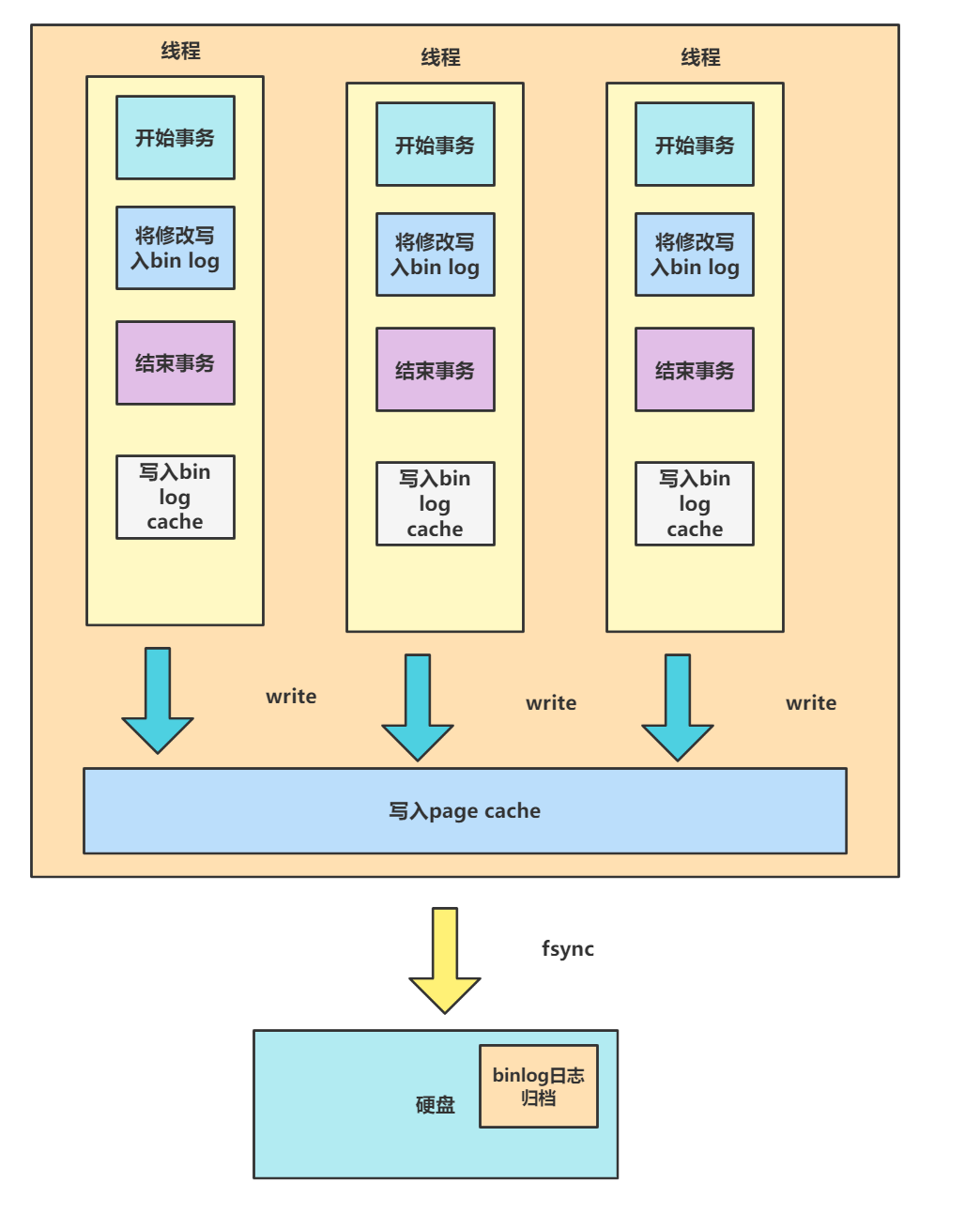
而调用系统函数fsync的实际是根据MySQL系统参数决定的,这个系统变量查询SQL如下
SHOW VARIABLES LIKE 'sync_binlog';
而sync_binlog值分别三种:
0.当配置为了0时,每次事务提交都只会write,fsync调用时机是由系统决定的。
1.当配置设置为1时,每次事务提交都会调用fsync。
N. 当配置为N,代表提交了N个事务之后就会将page cache中的数据通过fsync进行刷盘。
bin log和redo log的区别可以说说嘛?
答: 这个问题我们可以从以下几个场景来表述一下:
使用场景
bin log常用于数据灾备以及数据同步。
redo log常用于数据恢复保证数据持久性。
数据内容
redo log存储的物理日志,即修改的数据内容
而bin log则是记录修改的动作,例如update table set name='aa' whrere id=1
生成时机
redo log生成时机是在事务执行期间就会write
而bin log是在事务提交之后才会write
生成范围
bin log是MySQL server生成的事务日志,任何存储引擎都可以使用
redo log只有innodb这个存储引擎支持。
undo log
什么是undo log?undo log有哪些作用
答: 我们都知道MySQL是需要保证原子性的,这就需要在数据持久化操作之前会这些数据进行记录的,undo log做的就是这些事,当SQL操作发生异常等情况时,我们就可以通过undo log将事务回滚确保事务的原子性。
而mvcc就是基于隐藏列、以及事务启动时某一时刻创建的read view来保证不同隔离级别下查询数据的结果,而readview就是基于隐藏列以及undo log生成的一张表,关于这方面的知识,可以参考笔者写过的这篇文章:
进阶
关于二阶段提交了解过?
答: 哦,这个就是人们常说的为什么我有了undo log,你还需要bin log呢?而且这两个日志我到底要先写哪个才能保证主从数据库的一致性呢?
对此我们不妨用反正法来说明:
- 假设我们先写bin log,当事务提交后
bin log写入成功,结果再写redo log期间,数据库挂了。重启恢复后,主数据库工具redo log恢复到bin log写入前的样子,而从数据库在工具bin log进行数据同步时发现bin log有一条写入操作,最终从数据库比主数据库多了一条数据。 - 我们再假设写
redo log,假设事务执行期间我们就写了redo log,在事务提交之后写bin log数据库挂了,我们重启数据库后主主库恢复。主库根据redo log进行灾备恢复,将我们更新的数据同时恢复回来,而从库根据bin log进行数据同步时,并没有察觉到主库刚刚写入的数据,这就导致了从库比主库少了一条数据。
所以MySQL设计者提出了二阶段提交的概念,整体步骤为:
- 在事务开始时,先写
redo-log(prepare)。 - 事务提交时,再写
bin log。 - 事务提交成功,再写
redo-log(commit)。
有了这样一个整体步骤我们不妨用两种情况来举个例子吧:
假设我们有一张user表,这张表只有id、name两个字段。我们执行如下SQL:
update user set name='aa' where id=1;
按照二阶段提交,
假如我们在redo log提交时数据库宕机,二阶段是如何保证数据一致性的呢?
首先数据库重启恢复,然后主库发现redo log日志处于prepare而且bin log也没有写入,所以一切恢复到之前的样子(事务回滚),而从库对此无感,同步时也是同步成操作失败之前的样子,一切风平浪静。
假如我们bin log进行commit成功之后数据库宕机,二阶段提交是如何保证数据库一致性的呢?
还是老规矩,数据库重启恢复,然后主库发现bin log有个commit成功的数据,虽然redo log处于prepare阶段,但是我们还是可以根据情况推断出有个当前主库有个commit成功的事务,所以redo log会根据bin log将未commit的数据commit了,然后从库根据主库的bin log发现有新增一条新数据,由此同步一条更新数据,双方都有了一条新数据,数据库一致性由此保证。
参考文献
MySQL三大日志(binlog、redo log和undo log)详解
Innodb参数innodb_flush_log_at_trx_commit详解
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











