






每次请求都需要加载10m的纯真IP qqwry.dat 文件,自己测试不会发现问题,但如果访问量上去了,会影响每次请求的相应效率,并且会消耗一定的io读写,故打算优化
优化方案
每个IP区间之间不存在交集,每个查找只要按score查找区间[ip2long(ip), ip2long(ip) + N],N的值必需足够大,确保结束IP的值大于当前区间的结束IP。这个有点难理解,举个栗子:
有3个区间
Value Score
36 60
61 67
68 68查找IP=50时,查找的score为[50, 50 + N],且要满足50 + N >= 60,否则就无法找到[36, 60]这个区间。
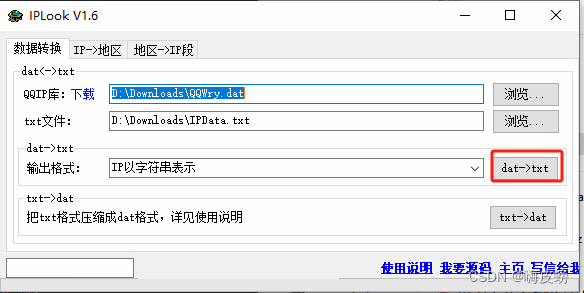
qqwry.dat 转为txt文件
首先下载IPLook软件,操作如下
写入redis
<?php
if (ini_set('memory_limit', '256M')) {
echo 'Memory limit set to 256M successfully' . "\n";
} else {
echo 'Failed to set memory limit to 256M' . "\n";
}
$IPData = file_get_contents('IPData.txt');
$IPData = explode("\n", $IPData);
var_dump(count($IPData));
var_dump($IPData[0]);
var_dump($IPData[1]);
unset($IPData[0]);
$redis = new Redis();
$redis->connect('127.0.0.1', 6379);
$redis->select(15);
foreach ($IPData as $key => $val) {
$val = explode("\t", $val);
// var_dump($val);
$item = [
'StartIP' => ip2long($val[0]),
'EndIP' => ip2long($val[1]),
'Country' => trim($val[2]),
'Local ' => trim($val[3]),
];
// $redis->set('mykey', 'Hello, Redis!');
// var_dump($item['EndIP']);
$redis->zAdd('IPData', $item['EndIP'], json_encode($item, JSON_UNESCAPED_UNICODE));
// die;
// var_dump()
}参考内容:使用Redis有序集合搭建自有IP定位解析库(纯真库)_qqwry.dat 存到 redis 中-CSDN博客















 2582
2582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









