







1. 第三方库
爬虫基本都会用到的第三方库:
- requests,优雅而简单的HTTP库,主要作用是模仿浏览器请求,获取爬取页面的HTML文件,给BeautifulSoup4用。
- BeautifulSoup4,可以从HTML或XML文件中提取数据,可以快速上手使用。
2. 网页分析
我的理解,爬虫一定是根据爬取网页的HTML编写代码,分析你要爬取的内容在HTML的哪个标签中,这个标签跟其他标签有什么不同之处,比如属性不同,属性值不同等。需要稍微了解一些基础的HTML、CSS语法,只是基本了解即可。
我们爬取电影天堂中最新电影这个子版块。用requests获取到最新电影版本的HTML文件,交给BeautifulSoup解析。
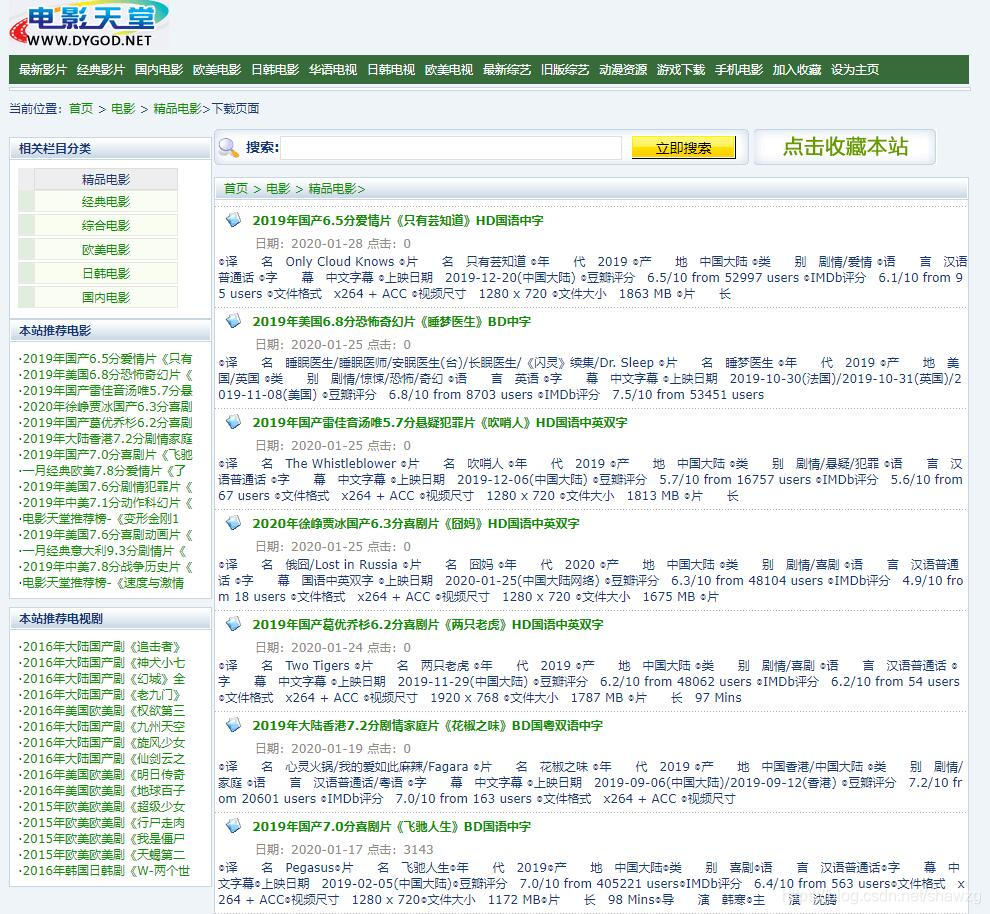
通过查看HTML源码,我们可以发现所有最新发布电影的连接都在ul标签中的table标签里。取出a标签中href属性的值,这个就是电影的详情页面URL。我们取到这个URL后,就可以用requests来请求这个页面的HTML文件,然后继续用BeautifulSoup解析,获取电影的下载地址。
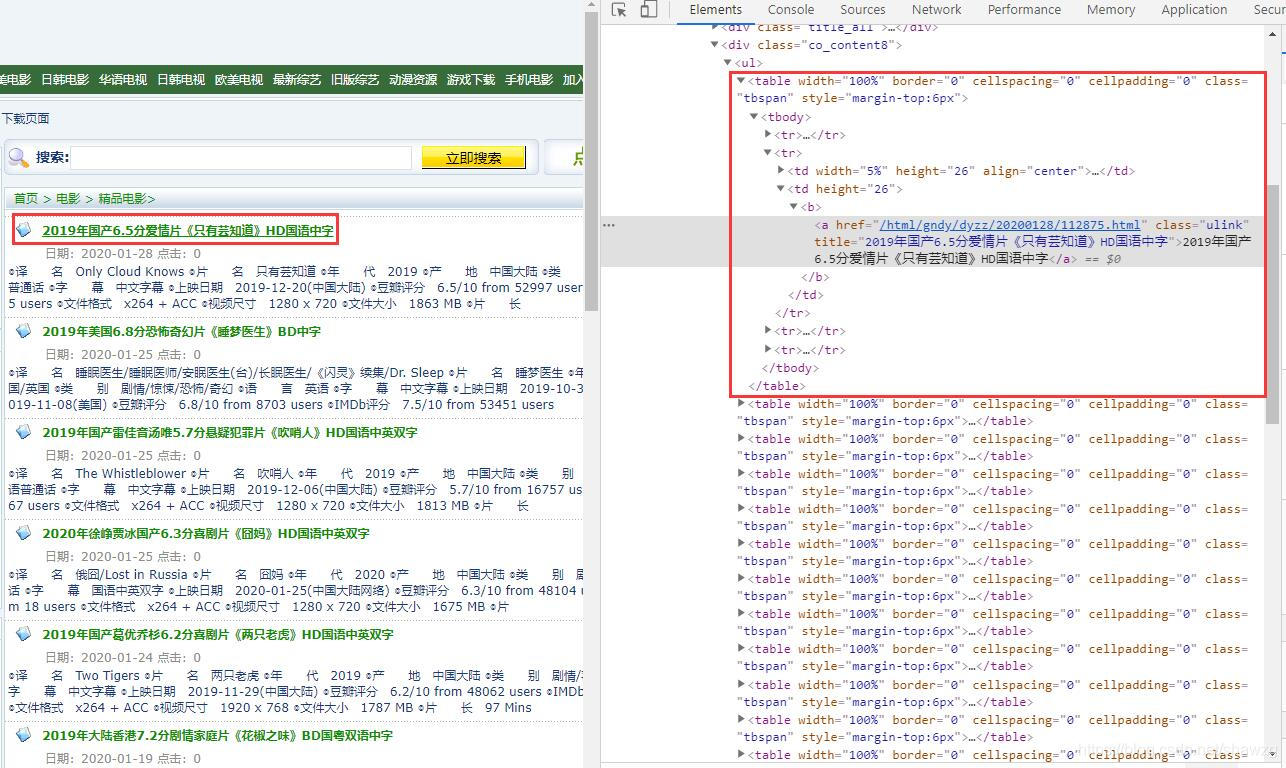
在电影的详情页面,我们关注的是迅雷下载地址,查看HTML网页元素,找到这个下载地址所在的标签,仍然通过BeautifulSoup来解析href值。这个就是该电影的迅雷下载地址了。
 上述就是整个爬虫的思路。爬取其他网站,也是同样的方法。
上述就是整个爬虫的思路。爬取其他网站,也是同样的方法。
3. 参考代码
我把代码中print方法删了,在你需要的地方自行添加print吧,或者直接用Pycharm打断点查看变量也很方便直观。
# -*- coding: utf-8 -*-
import requests
import urllib3
from bs4 import BeautifulSoup, SoupStrainer
import re
import json
from datetime import date, datetime, timedelta
# InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised.
# See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class DyttSpider :
def __init__(self) :
# 电影天堂主页,用于后续拼接URL
self.__index_url = 'https://www.dygod.net'
# 电影天堂最新电影页面
self.__new_film_page_url = 'https://www.dygod.net/html/gndy/dyzz/index.html'
self.__headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.99 Safari/537.36 Vivaldi/2.9.1705.41'}
self.__new_film_detail_url = list()
self.__new_film_download_url = list()
self.__query_date = date.today() - timedelta(days = 1)
def __is_query_publish_day(self, str_date) :
"""
是否满足发布的日期
"""
query_date = datetime.strptime(str_date, '%Y-%m-%d').date()
return True if self.__query_date == query_date else False
def __get_new_film_detail_url(self) :
response = requests.get(url = self.__new_film_page_url, headers = self.__headers, verify = False)
# response.encoding = requests.utils.get_encodings_from_content(response.text)
# 中文乱码,GB2312无效
response.encoding = 'GBK'
# 加快爬取速度,只分析关注部分
parse_only = SoupStrainer('div', attrs = {'class' : 'co_content8'})
soup = BeautifulSoup(response.text, 'html.parser', parse_only = parse_only)
table_tags = soup.find_all("table", attrs = {'class' : 'tbspan'}, recursive = True)
for table_tag in table_tags :
# 正则表达式匹配电影下载的发布日期
publish_date = re.search('\d{4}-\d{1,2}-\d{1,2}', table_tag.find('font', attrs = {'color' : '#8F8C89'}).string)
# publish_date = re.search('\d{4}-\d{1,2}-\d{1,2}', '日期:2019-12-25')
if not publish_date or not self.__is_query_publish_day(publish_date.group(0)) :
continue
link_tag = table_tag.find('a')
if link_tag.get('title') and link_tag.get('href') :
self.__new_film_detail_url.append({'data' : publish_date[0],
'title' : link_tag.get('title'),
'link' : self.__index_url + link_tag.get('href')})
def __get_new_film_download_url(self) :
for film_detail in self.__new_film_detail_url :
response = requests.get(url = film_detail['link'], headers = self.__headers, verify = False)
# response.encoding = requests.utils.get_encodings_from_content(response.text)
# 中文乱码,GB2312无效
response.encoding = 'GBK'
# 加快爬取速度,只分析关注部分
parse_only = SoupStrainer('div', attrs = {'class' : 'co_content8'})
soup = BeautifulSoup(response.text, 'html.parser', parse_only = parse_only)
table_tags = soup.find_all("table", recursive = True)
downloads = list()
for table_tag in table_tags :
downloads.append(table_tag.find('a').get('href'))
self.__new_film_download_url.append({'data' : film_detail['data'],
'title' : film_detail['title'],
'link' : downloads})
def spider(self) :
self.__get_new_film_detail_url()
self.__get_new_film_download_url()
if __name__ == '__main__' :
dytt_spider = DyttSpider()
dytt_spider.spider()
打印self.__new_film_download_url这个变量值,是如下的结构:
[
{
“data”: “2020-01-12”,
“title”: “一月经典意大利9.3分剧情片《海上钢琴师》BD英意双语中英双字”,
“link”: [
“magnet:?xt=urn:btih:d11ab04bd6d5f6ca10d119b660638c1e9f4011bf&dn=[电影天堂www.dytt89.com]海上钢琴师BD英意双语中英双字.mp4”
]
},
{
“data”: “2020-01-12”,
“title”: “2019年中美7.8分战争历史片《决战中途岛》HD国语中字”,
“link”: [
“magnet:?xt=urn:btih:9b47724df2ce45a23cd867a1ad926eed51a5ed36&dn=[电影天堂www.dytt89.com]决战中途岛HD国语中字.mp4”
]
}
]
4. 后续完善
- 是否可以将爬取到的下载地址直接发送到指定的邮箱里呢?当然是可以的。可以参考我之前写的另一篇博客《Python通过SMTP协议使用QQ邮箱发送邮件》。这样,如果网站每天都有更新,你的邮箱每天都会收到一封邮件啦。

- 每次都要手动执行脚本,太麻烦了,可以让这个脚本每天都自己执行吗?也是可以的,可以看看这个第三方库APScheduler,全称是Advanced Python Scheduler,一个轻量级的 Python 定时任务调度框架。
郑重说明
本文只限技术交流,请在法律允许的范围内合法爬虫!

















 9958
9958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









