







转自:MySQL5.7 — Character Set、Unicode - 知乎
版本:MySQL5.7
操作系统:Win10

一、字库、字符集、编码、XX码
在冯诺依曼结构体系中,信息都以二进制的方式在计算机中存储。信息是指令还是数据取决于CPU是如何读取的。当CPU通过代码段寄存器和指令指针寄存器寻址时(CS:IP),取出的信息就被认为是指令,当CPU通过数据段寄存器和内存单元相对地址进行寻址时(DS:[xxxx]),取出的信息就被认为是常规数据。
如同DS与CS决定了二进制信息是代码还是数据一样,我们也需要一些方式来对数据赋予不同的意义,比如这些数据表示的是字符还是数字。
假如我们有一些不相同的字符,这些字符的集合就被叫做字库表,如果赋予字库表中每一个字符一个代号,则字库表中所有的字符和代号就组成了字符集,而将字符集中的字符的代号翻译成计算机能够存储的二进制数据的操作就叫做编码,编码的二进制结果就叫做xx码。
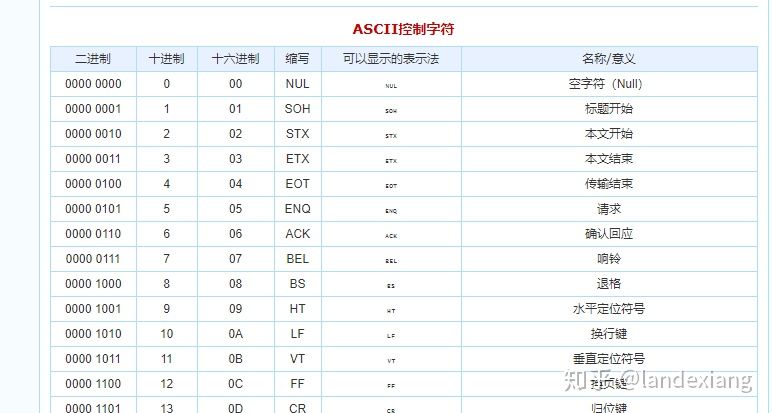
在上世纪,美国佬发明了一种名为ASCII的编码,在ASCII的字符集中,一共有128个不相同的字符,其中每个字符都有一个0-127之间的十进制数字作为代号。
而ASCII码就是ASCII字符代号的二进制表示。由于计算机的存储单元为byte,字节。一个字节分为8bit,位。即1字节能表示2^8 = 256个不同的状态,所以存储一个ASCII码到计算机上只需要使用一个字节。比如在ASCII字符集中,空格字符的代号为32,则其ASCII码为:
32 -> 0001 1010
但是随着计算机的普及,要表示的信息越来越多,比如需要表示其他语言的符号等。此时可以考虑扩展ACSII的字库和字符集。但由于ASCII码只用一个字节来存储,也最多只能表示256个不同的字符,除去原来的已经存在的128个,也只能扩展128个字符而已,可是单单汉字就有最起码几万个,所以使用一个字节来存储字符的编码信息已经遇到瓶颈了。
为了满足实际需求,必须考虑用多个字节来存储字符的编码信息。但是在计算机发展的过程中,出现了一个比较头疼的问题:
- 由于语言、文化等差异,产生了许多不同的字库和字符集
而Unicode字符集的出现就是为了解决这个问题,Unicode的字库中收录了世界上所有出现过的计算机字符,可以说Unicode字符集是世界上最大最全的字符集。
我们可以在Unicode官网上看到所有Unicode字符集所收录的字符
Unicode字库一直在被补充,现在被分为17个不同的区间,可以看做一个数据表中的17行。而每行中又可以看做具有65535列,具体的x行x列就对应着字符集中的一个字符,通常列的坐标被我们称为码点,即一行中有65535个码点。
ASCII字符集中,简单粗暴的使用一个0-128范围的数字作为字符的代号。Unicdoe字符代号是由字符所属的平面以及码点来确定的。先来看几个Unicode字符代号长什么样子:

如上图中所看到的,其格式为
U+{平面号}{码点} 平面号为1字节的16进制数 码点为2字节的16进制数
当平面号有前导0时可以省去不在字符代号中显式的写出,比如上图中用红色框标注的U+1F535写全应该为U+01F535、U+26A2写全应该为U+0026A2。U+1F91A就表示这个字符的平面号为1,码点为63770(F91A)
字符在字符集中的代号是给人看的,字符存储到计算机上最终还是二进制数据,即需要对代号进行编码。ASCII的编码方式就是直接将字符代号对应的十进制数字转换成二进制数字,首先我们来思考一下,对于Unicode字符的代号,采用和ASCII一样的编码方式是否可行?例如U+1F535这个字符直接用固定的三个字节来存储,即01 F5 35。
首先答案是当然可行,但是这样会带来一些问题。Unicode字库作为世界上最大的字库,其肯定包含了ASCII字库中的所有字符,原本只需要1个字节就能存储的ASCII码,如果采用上面所说的编码方案,就需要3个字节来存储,无疑会浪费大量的计算机资源。
由于牛逼的程序员们都有强迫症,所以针对Unicode字符集,没有采用类似于ASCII码类似的固定长度的编码方式,而是推出了可变长度的编码方式,也就是我们所熟悉的utf-8、utf-16等编码方式。即一个字符集下可能有多种编码方式。
先来看想utf-8是如何进行可变长度的编码的,如下所示是utf-8编码表示Unicode字符集中所有的字符的方式
Unicode符号范围 (十六进制) | UTF-8编码方式 (二进制)
-------------------------------------------------------------------
00 00 00 - 00 00 7F | 0xxxxxxx
00 00 80 - 00 07 FF | 110xxxxx 10xxxxxx
00 08 00 - 00 FF FF | 1110xxxx 10xxxxxx 10xxxxxx
01 00 00 - 10 FF FF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
从上图可以看到位于第0平面,且码点范围为[00, 7F]的字符只需要一个字节来表示,而这些字符恰好就对应着ASCII字符集中的128个字符。
uft-8的编码规则为:
- 对于单字节的编码,字节的第一位设为0,后面7位用来表示字符的 Unicode 代号。因此对于ASCII字符集中的字符,其ASCII码和utf-8编码相同
- 对于n字节的编码(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的所有二进制位,用来表示这个符号的 Unicode代号 。
从utf-8编码规则来看,其最多为4个字节,也就是说utf-8最多能存储长度为6 * 3 + 3 = 21bit的数据。Unicode字符集只有17个平面,所以只需要5bit就可以表示其所有的平面,而剩下的最大码点值为65535,仅需要16bit进行表示,5 + 16 = 21bit,这也说明utf-8编码刚好能编码Unicode字符集中的所有字符,同时也达到了可变长度的目的,节省了计算机资源。
二、MySQL中的Character Set
1、基本概念
在前面一节中我们了解了字符集和编码的基本概念,同时也知道了Unicode通常指的是世界上最大的字符集。
Character Set是MySQL中的关键字,如果直接翻译过来的话就是字符集。
我们可以使用
show character set
命令来查看MySQL所支持的所有character set:
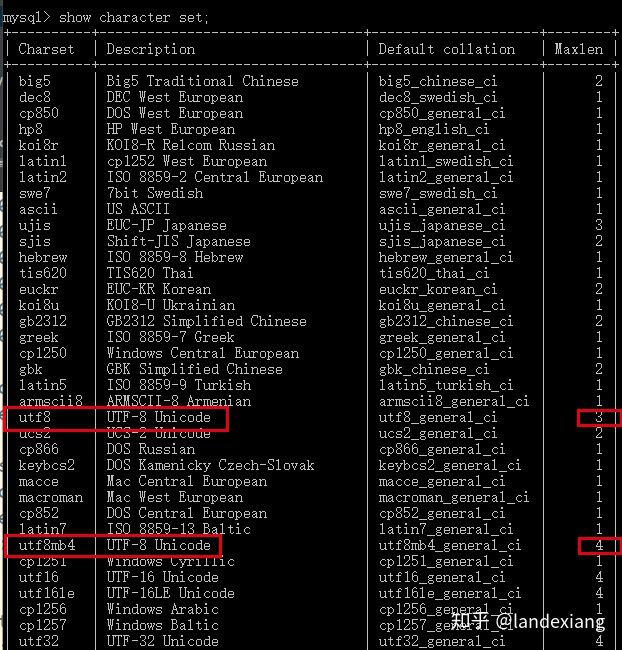
第一栏的Charset是MySQL中Character Set的名字,Description这一栏表明了其所使用的编码方式和字符集。比如上图中的utf8这个Character Set,在MySQL中表示所使用的编码方式为UTF-8,使用的字符集为Unicode,并且限制了最大长度为3字节。不过这里我们可能会产生疑问,在上一节中我们已经得知,UTF-8编码作为一个可变长度的编码,最长应该是4字节,为什么这里要限制为3呢?其实这是由于历史原因,在mysql支持UTF-8编码时,Unicode还没有平面一说,3个字节也就是说:
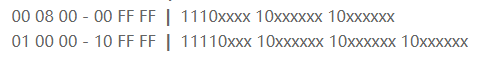
其最长的有效位只有6 + 6 + 4 = 16bit,即两个字节,刚好只能表示Unicode字符集一个平面的65535个码点值,而没有多余的位置去表示具体表示哪个平面,所以默认也就是第0平面,至于现在所说的17个平面是后来才产生的概念。如果有特别的需求,需要用到Unicode字符集中的所有字符,我们可以切换成utf8mb4 Character Set,其完全向下兼容utf8 Character Set,并且最大长度为4字节,这个也是目前真正意义上的UTF-8编码。
2、MySQL中字符集的设置 — server级
MySQL中有许多关于字符集的设置,可以通过
show variables like '%char%'
来查看server级的字符集设置,如下图所示
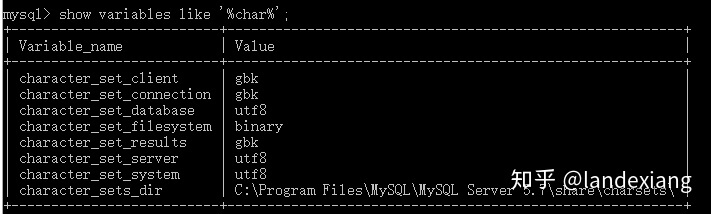
character_set_client:
我们使用的命令行工具或者MySQL Workbench都属于客户端,与MySQL服务器通过tcp进行通信,端口为3306:
我们在命令行中敲入的命令,被当做一个字符串,根据CMD命令行工具的字符集设置转化为二进制数据通过tcp发送给MySQL服务器,然后MySQL服务器经过一系列的解析,优化等处理将字符串转化为自己可以执行的语法树。我们都知道tcp发送的是二进制数据,MySQL需要将接受到的二进制数据根据该参数设置的字符集进行解码。
测试方法如下,首先将该参数设置为ASCII码
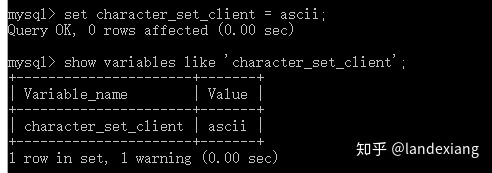
向MySQL服务器发送一个建表语句,包含一个中文备注:

接下来查看MySQL最终执行的建表语句:
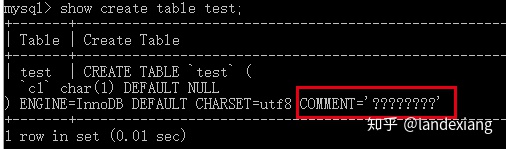
可以看到由于字符集设置的问题,导致中文乱码。所以我们应该让该参数值和我们所使用的MySQL客户端的字符集保持一致,我使用的MySQL客户端是CMD命令行工具:
可以在标题栏右键选择属性
查看当前CMD命令行所使用的编码方式
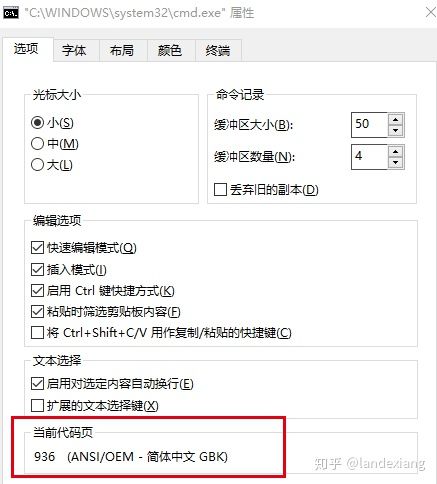
如上图所示,我的CMD客户端的字符集为GBK,所以也要将MySQL服务器的该参数设置为GBK才能正常工作。
character_set_connection:
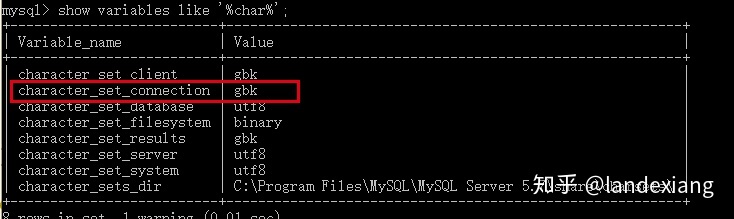
正确的设置character_set_client能让我们在客户端输入的sql命令被MySQL服务器正确的拿到。MySQL服务器拿到sql语句之后开始解析构建语法树,如果在解析时发现有字符串常量的存在,则需要需要使用character_set_connection所设置的character_set进行编码,作为临时数据保存在内存中。我们可以很容易的通过字符串的字节长度来进行验证:
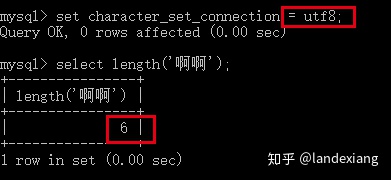
当character_set_connection设置为gbk字符集时,一个汉字应该占用2个字节:
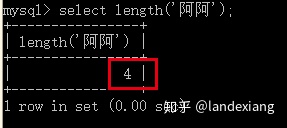
当character_set_connection设置为utf8字符集时,一个汉字应该占用3个字节:
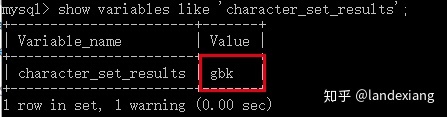
character_set_results:
当MySQL需要返回给客户端数据时,比如返回查询结果,会根据character_set_results的设置进行转码,然后后再发送给MySQL客户端。还是以CMD命令行客户端为例,客户端字符集默认为gbk,character_set_results默认设置也是gbk,MySQL服务器在返回数据前会进行一个utf8字符串到gbk字符串的转码,所以我们的查询结果可以正常显示。
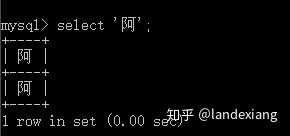
正常情况下,我们直接select一个字符串常量不会有任何问题:
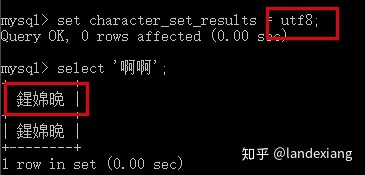
但是如果我们将该参数设置为utf8,可以看到由于CMD命令行环境中的字符集为gbk,所以汉字会乱码:
character_set_system:
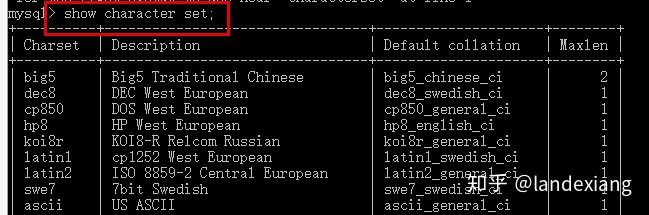
上面的三个设置都是对数据起作用的,而character_set_system作用的目标为数据库的元数据。MySQL认为表示数据库的基本信息,但是又不属于数据库的数据内容的数据,就叫做元数据,比如数据库名,表明,列名信息等,你可以简单理解为数据库的结构层面的信息。对应到具体的实体来说就是使用show命令查看的内容或者是使用select命令从INFORMATION_SCHEMA数据库中查询的内容,比如说字符集:
show命令查看所有的字符集:
从INFORMATION_SCHEMA数据库的对应表中查看字符集:
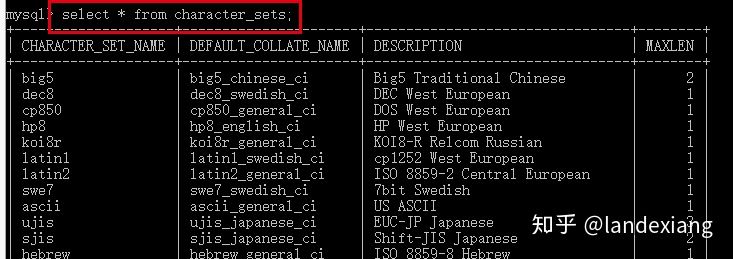
系统字符集设置中的character_set_system选项,就是存储数据库元数据的字符集,默认为utf8:

而且该选项是只读的,我们没有 办法进行设置 :
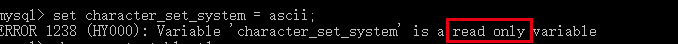
我们通过创建一个含有中文列名的表进行测试:
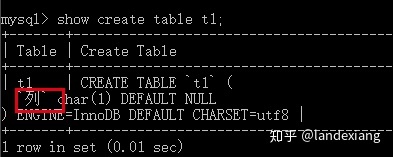
INFORMATION_SCHEMA.COLUMNS表中记录了mysql数据库中所有的列的元数据,可以看到具有列名这个列:
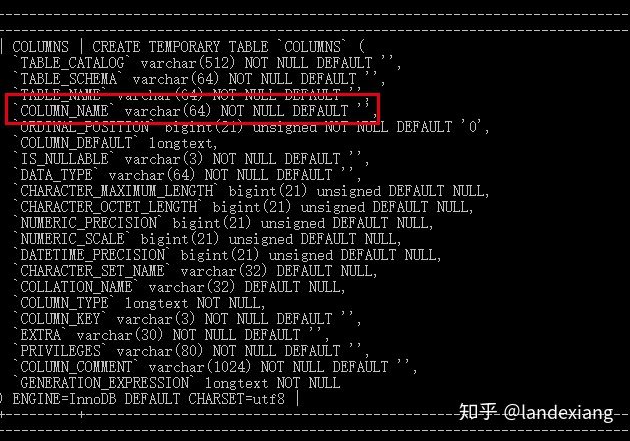
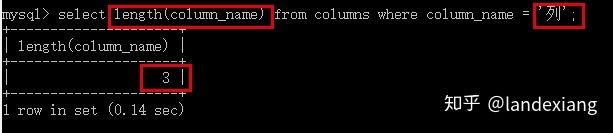
由于存储元数据的字符集是utf8,所以通过length函数,我们可以看到列名 '列' 占用的字节数为3,
character_set_server:
首先让我们来了解一些基本知识,整个MySQL的结构为:MySQL服务器 -> database -> tables -> column -> row,其中前四个为数据库的元数据,最后一个为数据库的内容。无论是数据库的元数据还是数据库的内容都需要持久化到磁盘上。元数据的在存储时使用的字符集是统一的,通过character_set_system变量进行控制。而数据库的内容在存储时,所采用的字符集主要是由其column的字符集决定的,我们可以在建表时指定列的字符集,如下图所示:

但在建表时,为列单独设置字符集这一操作是可选的,也就是说我们可以不为列单独设置,还是以这个刚创建的表为例:
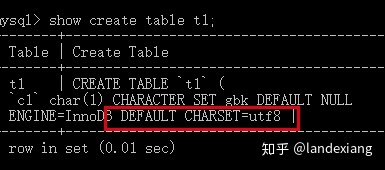
可以看到数据表有一个默认的字符集utf8,即如果我们不为列单独设置字符集,则默认继承其所在表的字符集,这很容易进行测试,首先来添加一个没有设置字符集的列:

通过show命令可以看到其并没有单独的字符集设置:

我们向这两个列中各插入一个汉字:
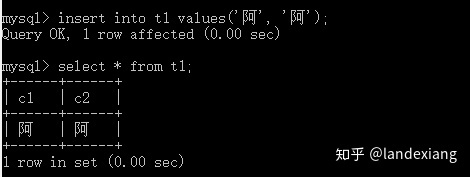
可以看到gbk字符集的c1列占用了2个字节,设置为utf8的c2列占用了3个字节

过虽然可以为列单独设置字符集,但在日常开发中我们仅仅对表进行显式的字符集指定
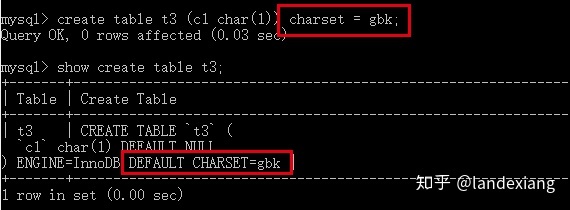
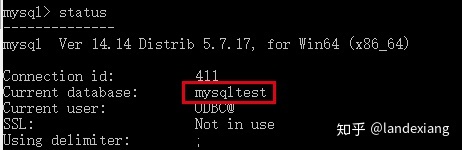
看到这里我们可能会产生一个问题,在上一个测试中,并没有显式的设置数据表t1的字符集,其默认的字符集utf8是从哪来的呢?答案是其所属的数据库。首先使用status命令可以看到当前所处的数据库为mysqltest:
通过show命令查看数据库的建表语句,可以看到当前数据库的默认字符集为utf8

如同建表一样,我们可以在创建数据库时显式的指定数据库的字符集:
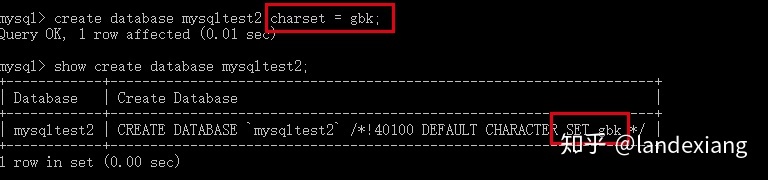
在mysqltest2中创建的表如果不显式的指定字符集,其字符集默认就是gbk,继承于其所在的数据库:

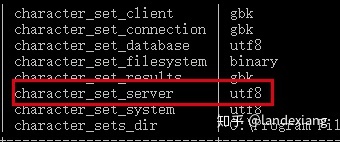
有了前面的思考,我们自然而然的会想到一个新的问题,我们在创建数据库时如果不显式指定字符集,其默认字符集是从哪里继承而来的?答案就是character_set_server选项:
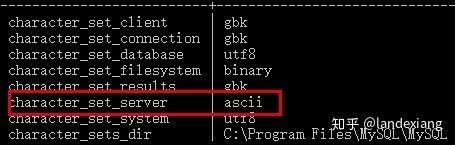
我们将其改成ascii,然后重新创建一个数据库,但是不显式指定字符集:
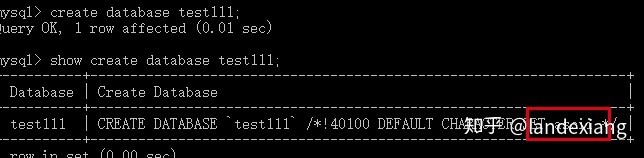
而很多朋友可能会下意识的认为新建数据库的字符集应该继承于character_set_database参数,事实上不是,可以在文档中找到这句话:
The character set used by the default database. The server sets this variable whenever the default database changes. If there is no default database, the variable has the same value as character_set_server.
The global character_set_database and collation_database system variables are deprecated in MySQL 5.7 and will be removed in a future version of MySQL.
曾用于设置数据库的默认字符集,但是现在已经不生效了,数据库的默认字符集有character_set_server选项决定,如果没有设置该选项值,其默认情况下和character_set_server相同。在MySQL5.7中已经不推荐使用该参数,并且以后会被删除掉。
三、小结
我们在平时使用MySQL时,如果没有特别的需要,尽量不要去修改其默认的字符集设置。并且有以下几个建议:
保持character_set_client、character_set_connection、character_set_results相同
表的字符集尽量使用默认从character_set_server配置的
尽量不单独指定表和列的字符
character_set_server最好配置成utf8mb4















 4622
4622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









