







现有网络模型的使用及修改
本节主要讲解与图像相关的 torchvision

本节主要讲解 Classification 里的 VGG 模型,数据集仍为 CIFAR10 数据集(主要用于分类)
网站 : torchvision.models — Torchvision 0.11.0 documentation
1.数据集 ImageNet
先创建Python文件module_pretrained.py
注意:数据集 ImageNet必须要先有 package scipy
在 Terminal 里输入
pip list
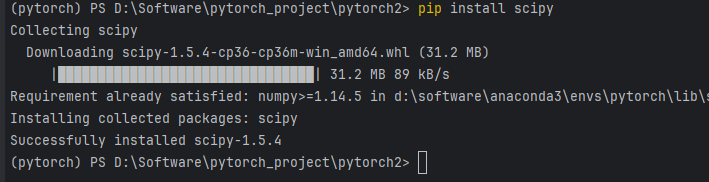
寻找是否有 scipy,若没有的话输入
pip install scipy
参数及下载
1.ImageNet 参数:

2.下载 ImageNet 数据集:
import torchvision.datasets
train_data = torchvision.datasets.ImageNet("./data_image_net",split='train',download=True,
transform=torchvision.transforms.ToTensor())
./xxx表示当前路径下,…/xxx表示返回上一级目录
多行注释快捷键:ctrl+/

运行后会报错:
RuntimeError: The dataset is no longer publicly accessible. You need to download the archives externally and place them in the root directory.
提示我们该数据不在公开访问,必须手动下载然后放到根目录中

下载地址:
Imagenet 完整数据集下载_wendell 的博客-CSDN博客_imagenet下载
数据集有100 多个G,太大了
按住 Ctrl 键,点击 ImageNet,查看其源码:
2.VGG16 模型
VGG 11/13/16/19 常用16和19
(1)参数
参数 pretrained=True/False

-
pretrained 为 False 的情况下,只是加载网络模型,参数都为默认参数,不需要下载
-
为 True 时需要从网络中下载,卷积层、池化层对应的参数等等(在ImageNet数据集中训练好的)
import torchvision.models vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True vgg16_true = torchvision.models.vgg16(pretrained=True) print('ok')
断点打在 print(‘ok’) 前,debug 一下,等待vgg16下载完成,建议复制控制台出现的链接到迅雷下载更快,下载完成后放到对应文件夹
https://download.pytorch.org/models/vgg16-397923af.pth

debug结果如图:

vgg16_true ——> classifier ——> Protected Attributes ——> modules ——> ‘0’(线性层) ——> weight

为 false 的情况,同理找到 weight 值:

总结:
- 设置为 False 的情况,相当于网络模型中的参数都是初始化的、默认的
- 设置为 True 时,网络模型中的参数在数据集上是训练好的,能达到比较好的效果
(2)vgg16 网络架构
import torchvision.models
vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
控制台运行结果:
VGG(
(features): Sequential(
# 输入图片先经过卷积,输入是3通道的、输出是64通道的,卷积核大小是3×3的
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# 非线性
(1): ReLU(inplace=True)
# 卷积、非线性、池化...
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
# 最后线性层输出为1000(vgg16也是一个分类模型,能分出1000个类别)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)

所以 out_features = 1000
3.如何利用现有网络去改动它的结构?
train_data = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
CIFAR10 把数据分成了10类,而 vgg16 模型把数据分成了 1000 类,如何应用这个网络模型呢?
- 把最后线性层的 out_features 从1000改为10
- 在最后的线性层下面再加一层,in_features为1000,out_features为10
利用现有网络去改动它的结构,避免写 vgg16
很多框架会把 vgg16 当做前置的网络结构,提取一些特殊的特征,再在后面加一些网络结构,实现功能。
(1)添加
以 vgg16_true 为例讲解,实现上面的第二种思路:
# 给 vgg16 添加一个线性层,输入1000个类别,输出10个类别
vgg16_true.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
print(vgg16_true)
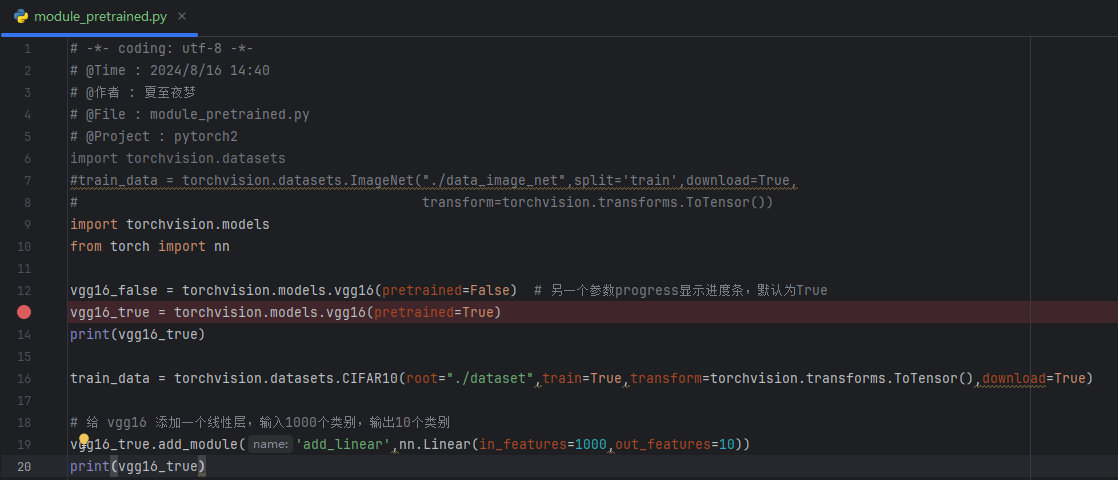
结果如图:
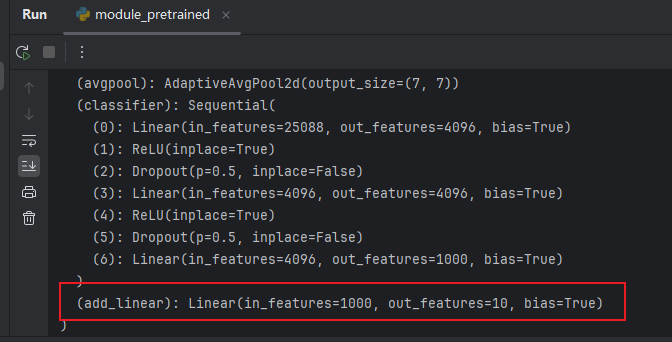
如果想将 module 添加至 classifier 里:
# 给 vgg16 添加一个线性层,输入1000个类别,输出10个类别
vgg16_true.classifier.add_module('add_linear',nn.Linear(in_features=1000,out_features=10))
print(vgg16_true)
结果如图:
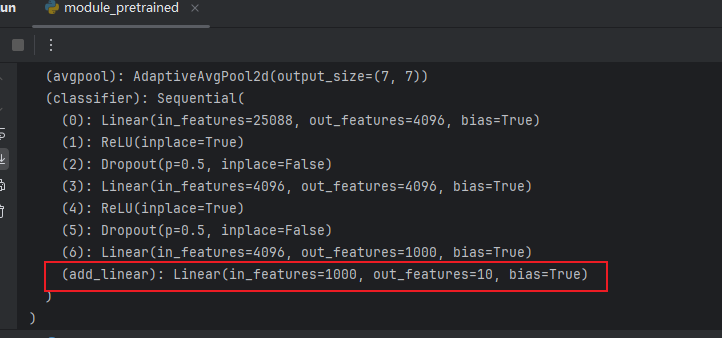
(2)修改
以上为添加,那么如何修改呢?
以 vgg16_false 为例:
vgg16_false = torchvision.models.vgg16(pretrained=False) # 另一个参数progress显示进度条,默认为True
print(vgg16_false)
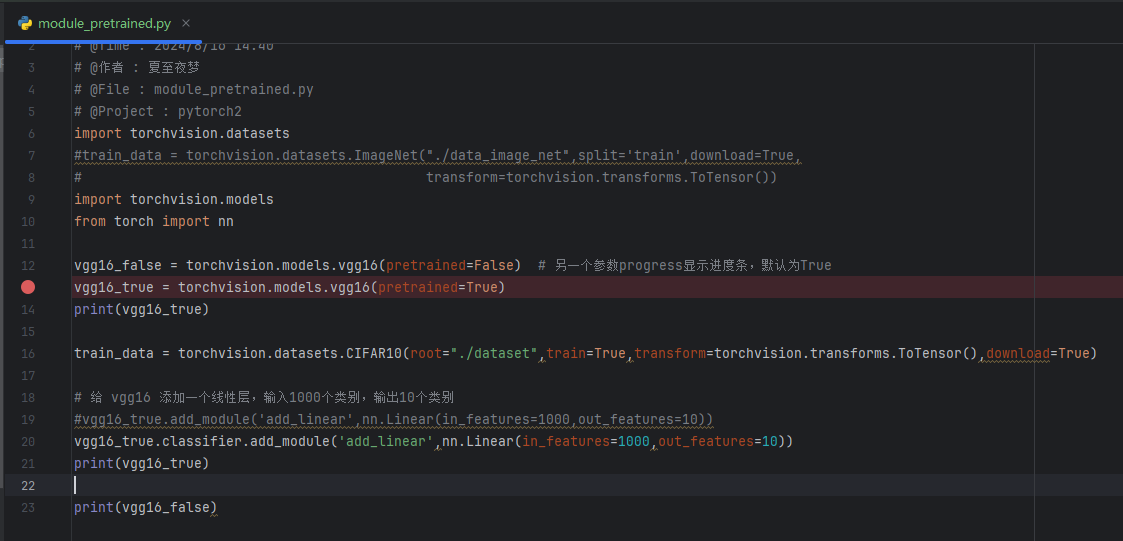
结果如下:
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
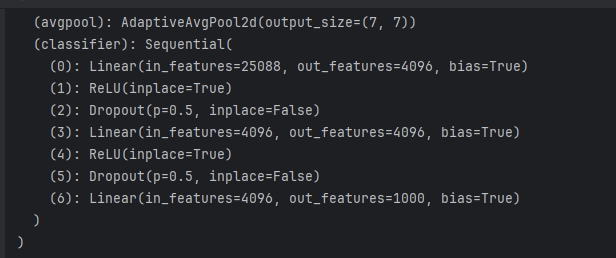
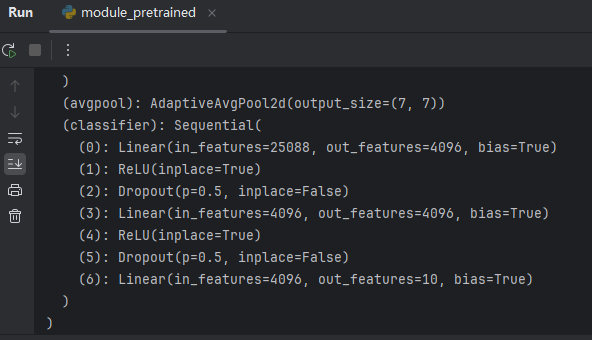
想将最后一层 Linear 的 out_features 改为10:
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
结果如下:
本节:
- 如何加载现有的一些 pytorch 提供的网络模型
- 如何对网络模型中的结构进行修改,包括添加自己想要的一些网络模型结构
ut_features 改为10:
vgg16_false.classifier[6] = nn.Linear(4096,10)
print(vgg16_false)
[外链图片转存中…(img-QIMto85N-1724861998315)]
结果如下:
[外链图片转存中…(img-eYkCFxhp-1724861998315)]
本节:
- 如何加载现有的一些 pytorch 提供的网络模型
- 如何对网络模型中的结构进行修改,包括添加自己想要的一些网络模型结构


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









