







目录
1.前言
前面的文章写了一篇,大数据方面的基础知识,目的是希望大数据小白可以对大数据能有个清楚的认识,我们前面提到了大数据的本质,其实就是 分布式 系统,各种分布式的系统,相信读了上一篇文章后,能够对大数据清楚的认识,如果还没有读的,快去读一下吧。
好了,我们再回顾下HDFS的基本概念。
2. HDFS架构
2.1 架构定义
HDFS(Hadoop Distributed File System)是 Hadoop 生态系统中的基础组件,它提供了分布式文件系统的实现,能够在廉价的机器上构建大规模、高容错性的分布式文件系统。
HDFS 的设计目标是高可靠性、高吞吐量和高容错性,它采用了 Master/Slave 架构,其中 NameNode 负责管理文件系统的元数据,DataNode 负责存储文件数据。 HDFS 的架构比较简单,但是它的设计思想非常巧妙,它通过采用一系列的设计和优化,在廉价的机器上实现了高可靠性、高吞吐量和高容错性。 本文将详细介绍 HDFS 的架构原理,帮助你更好地理解 HDFS。
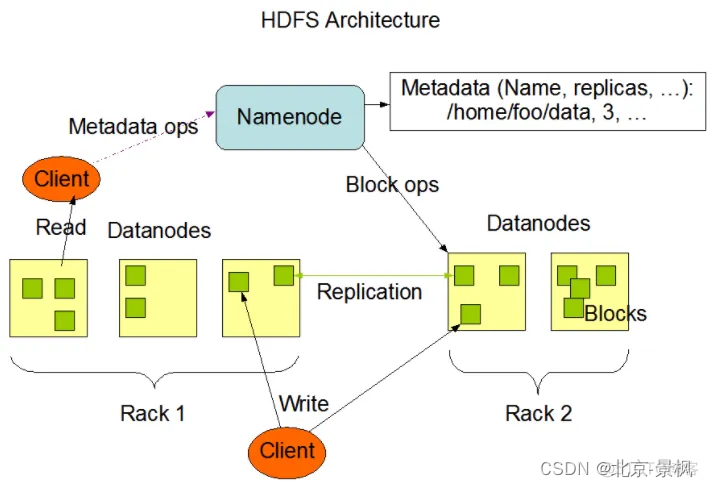
2.2 揭秘架构
上文中是HDFS架构的定义,我们在揭秘上面的定义之前,先来回想下大数据诞生的背景,是由于数据量的增多,存储 + 计算的难题,存储在过去即便可以跟的上,Orcale 的高昂的硬件使用费维护费(SSD固态和普通硬盘的价格),DBA的高额的人力成本投入,都让存储这块变得捉襟见肘,再加上数据量的巨增,计算耗时拉长,让人难以接受,这些问题推动了,大数据技术的衍生。因此HDFS 在设计之初,就是要在普通的机器上运行(可以降低成本),而普通机器的出问题概率高因此 高可靠、高容错性也就很关键,并且使大规模的扩容变的很容易,易于维护,并且具有高吞吐的特性,这些都得益于,HDFS优秀的设计思想,它通过采用一系列的设计和优化。
我们理解了他的设计初衷,设计背景,他优秀的设计又是什么呢?
我们先看下他的结构,从架构设计上,采用了非常经典的“Master/Slave ”架构设计,想要了解的可以看下我写的普及主从设计模式的文章。
小白初探架构模式—常用的设计模式 我们接着往下看。
我们先引入几个问题:hdfs 是分布式文件系统,他是个文件系统,就是类似linux 系统的东西,我们想哈,文
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1819
1819











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











