







🚩Java集合:浅谈LinkedList
📚1.LinkedList集合的使用
✒️1.1 LinkedList集合的简单使用
import java.util.LinkedList;
public class TestDemo {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(11);
list.add(22);
list.add(33);
list.add(11);
list.add(null);
for (Integer value : list) {
System.out.print(value + " ");
}
}
}
运行结果:
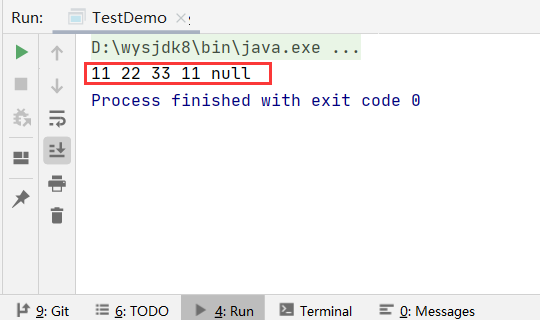
🖊️1.2 LinkedList集合特点
1.数据按照插入的顺序有序
2.数据可以重复插入
3.可以存储null值
4.底层采用双向链表的数据结构
📕2.通过JDK源码来研究LinkedList的实现
📫2.1 继承关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
类结构图:
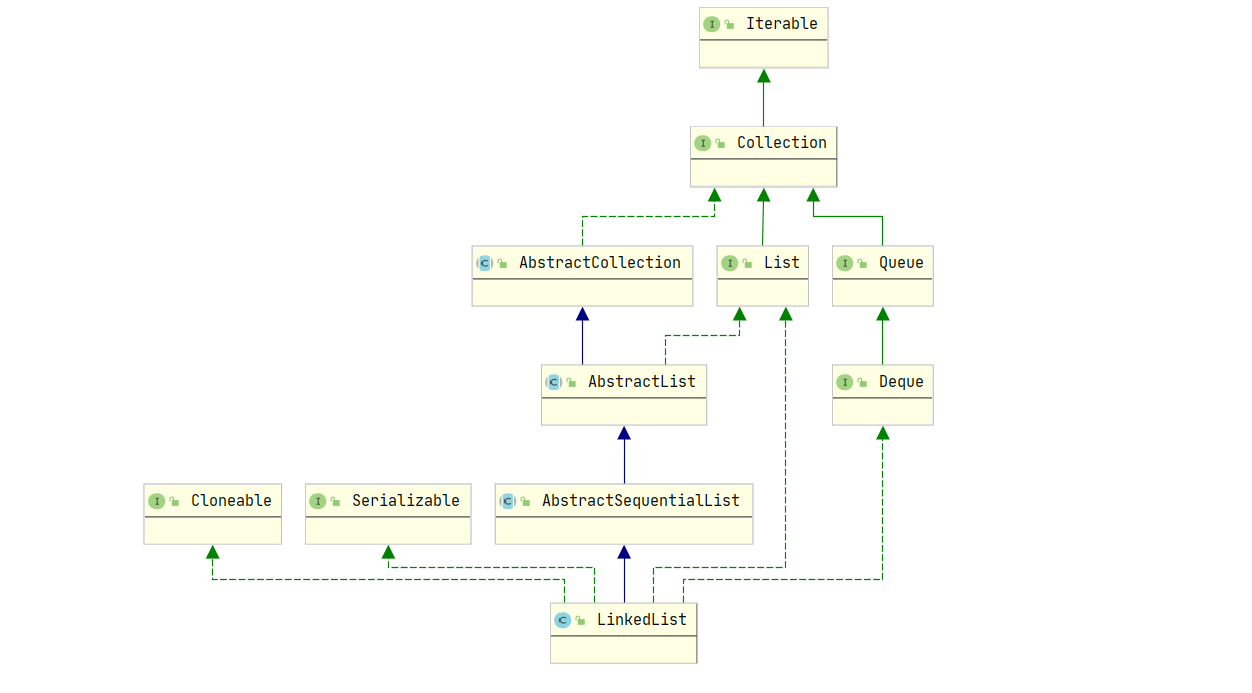
①LinkedList继承了AbstractSequentialList抽象类,AbstractSequentialList继承自AbstractList,对常见的方法做了实现,便于子类的直接复用。
②LinkedList同时也实现了List、Cloneable、java.io.Serializable接口,能够实现克隆,实现序列化。
③实现了deque接口,该接口是一个双端队列接口,继承自Queue接口,所以LinkedList也是Queue接口的实现类,可以借助该队列实现队列和栈。
📪2.2 属性和默认值
//有效数据个数
transient int size = 0;
//头结点位置
transient Node<E> first;
//尾结点位置
transient Node<E> last;
//Node类
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
从Node类中可以看出,LinkedList底层是一个双向链表的数据结构。
📬2.3 构造函数
无参构造函数
public LinkedList() {
}
有参构造函数 有参构造函数调用了无参构造函数和批量添加函数
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
📭2.4 常见方法源码解析
📑2.4.1 add: 添加元素
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
//新结点以链表的尾结点为前驱,将新结点插入到链表的尾部
final Node<E> newNode = new Node<>(l, e, null);
//更新尾结点,将新结点作为尾结点
last = newNode;
if (l == null)
//如果当前插入的是第一个结点,将头结点指向新结点,此时first = last = newNode
first = newNode;
else
//当前插入的不是第一个结点,原先链表的尾结点的next域指向新结点
l.next = newNode;
size++;//有效元素个数+1
modCount++;
}
📄2.4.2 remove:删除元素
public boolean remove(Object o) {
//判断删除元素是否为null
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//删除元素逻辑
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//判断删除元素是否为第一个元素
if (prev == null) {
//删除元素为第一个元素,头结点指向第二个元素
first = next;
} else {
//删除元素不是第一个元素
//删除元素的前一个结点的后继指向删除元素的后一个结点
//删除元素的前驱置为null
prev.next = next;
x.prev = null;
}
//判断删除元素是否为最后一个元素
if (next == null) {
//删除元素为最后一个元素,尾结点指向它的前一个结点
last = prev;
} else {
//删除元素不是最后一个元素
//删除元素的后一个结点的前驱指向删除元素的前一个结点
//删除元素的后继置为null
next.prev = prev;
x.next = null;
}
//删除结点的item置为null
x.item = null;
size--;//有效元素个数-1
modCount++;
return element;
}
结点的前驱、后继、item都置为null,方便Node结点进行回收
📃2.4.3 get:获取元素
public E get(int index) {
//检查下标的合法性
checkElementIndex(index);
return node(index).item;
}
private void checkElementIndex(int index) {
//如果下标不合法,抛出下标越界异常
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//检查下标是否在 0 和 size - 1 有限范围之间
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
Node<E> node(int index) {
// assert isElementIndex(index);
//采用二分查找的方法查找元素
//如果下标在size/2的前半部分,从前往后查找
//如果下标在size/2的后半部分,从后往前查找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
🃏3.ArrayList和LinkedList的比较
| 底层结构 | 增删的效率 | 改查的效率 | |
|---|---|---|---|
| ArrayList | 可变数组 | 较低 数组扩容 | 较高 |
| LinkedList | 双向链表 | 较高,通过链表追加 | 较低 |
如何选择ArrayList和LinkedList:
1.如果我们的改查操作比较多,选择ArrayList
2.如果我们的增删操作比较多,选择LinkedList
3.一般来说,在程序中,80%~90%都是查询,因此大部分情况下会选择ArrayList
4.在一个项目中,根据业务灵活选择,也可能这样,一个模块使用的是ArrayList,另一个模块使用的是LinkedList
















 8113
8113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











