







今天我们新建第一个爬虫程序,爬取[伯乐在线]网站上一个网页的内容。
创建项目
[按照上一篇文章所讲的,你已经建好一个虚拟环境并安装好了 scrapy]
首先,打开控制台,进入虚拟环境,输入 scrapy startproject jobbole 新建一个名字为 jobbole 的项目。
输入 tree/F jobbole 查看文件下的目录结构。
│ scrapy.cfg
│
└─jobbole
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
├─spiders
│ │ __init__.py
│ │
│ └─__pycache__
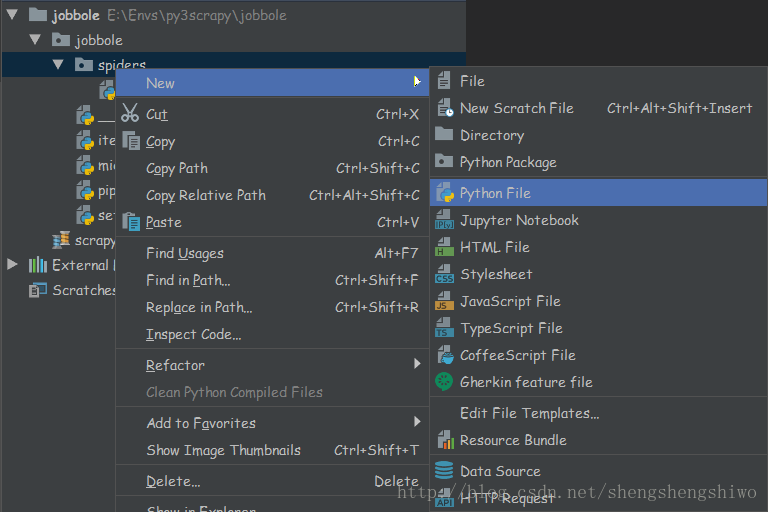
└─__pycache__用 PyCharm 打开该文件夹,并在 spider 文件夹下新建一个 Python File 文件,取名为 jobbole_spider。
在编写程序之前,我们先分析一下所要抓取的网页,登录伯乐在线网站,随便打开一篇文章:http://python.jobbole.com/89004/
我们要提取这个网页的标题,发布时间,标签,评论数,点赞数等等。
提取数据
学习如何使用 Scrapy 提取数据的最好方法是尝试使用 Scrapy shell的选择器。
在控制台输入 scrapy shell "http://python.jobbole.com/89004/"
会看到:
2018-02-11 14:10:26 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://python.jobbole.com/89004/> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x0000016D64CD9A90>
[s] item {}
[s] request <GET http://python.jobbole.com/89004/>
[s] response <200 http://python.jobbole.com/89004/>
[s] settings <scrapy.settings.Settings object at 0x0000016D64CD9B70>
[s] spider <DefaultSpider 'default' at 0x16d64f822b0>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>下面用响应对象使用 CSS 选择元素:
提取标题,输入:response.css(".type-post h1::text").extract_first()
>>> response.css(".type-post h1::text").extract_first()
'15 分钟用 ML 破解一个验证码系统'提取创建时间,输入:response.css(".entry-meta-hide-on-mobile::text").extract_first().strip()[:-2]
>>> response.css(".entry-meta-hide-on-mobile::text").extract_first()
'\r\n\r\n 2018/01/29 · '
>>> response.css(".entry-meta-hide-on-mobile::text").extract_first().strip()
'2018/01/29 ·'
>>> response.css(".entry-meta-hide-on-mobile::text").extract_first().strip()[:-2]
'2018/01/29'提取标签,输入:response.css(".entry-meta a::text").extract()
>>> response.css(".entry-meta a::text").extract()
['实践项目', ' 1 评论 ', 'OpenCV', 'tensorflow', '机器学习']提取点赞数,输入:response.css(".vote-post-up h10::text").extract_first()
>>> response.css(".vote-post-up h10::text").extract_first()
'5'提取收藏数,输入:response.css(".bookmark-btn::text").extract_first()
>>> response.css(".bookmark-btn::text").extract_first()
' 12 收藏'提取评论数,输入response.css(".hide-on-480::text").extract()[-1]
>>> response.css(".hide-on-480::text").extract()[-1]
' 1 评论'这里需要说明的是,调用
.extract()返回的是一个列表,而当你想返回列表中的第一个值,可以调用extract_first()。
除了使用extract()和extract_first()方法之外,还可以使用re()正则表达式进行提取页面信息。比如,对于收藏数和评论数,我们仅仅是想提取数字而已,所以得把上面抓取到的内容进行正则匹配。
fav_nums = response.css(".bookmark-btn::text").extract_first()
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css(".hide-on-480::text").extract()[-1]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)当我们提取标签的时,发现其中['实践项目', ' 1 评论 ', 'OpenCV', 'tensorflow', '机器学习']还有1 评论,这并不是我们希望看到的,所以我们得用正则匹配把无用的信息剔除掉。
tag_list = response.css(".entry-meta a::text").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)到此为止,我们的程序代码就已经分析完成了。
主要代码:
import scrapy
import re
class jobboleSpider(scrapy.Spider):
name = "jobbole_spider"
start_urls = ['http://python.jobbole.com/89004/']
def parse(self, response):
fav_nums = response.css(".bookmark-btn::text").extract_first()
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css(".hide-on-480::text").extract()[-1]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
tag_list = response.css(".entry-meta a::text").extract()
tag_list = [element for element in tag_list if not element.strip().endswith("评论")]
tags = ",".join(tag_list)
for quote in response.css(".grid-8"):
yield{
'title': quote.css(".type-post h1::text").extract_first(),
'create_data': quote.css(".entry-meta-hide-on-mobile::text").extract_first().strip()[:-2],
'tags': tags,
'praise_nums': quote.css(".vote-post-up h10::text").extract_first(),
'fav_nums': fav_nums,
'comment_nums': comment_nums,
}
另外,要想在PyCharm上运行此程序,还需要新建一个main.py函数
import os
import sys
from scrapy.cmdline import execute
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "jobbole_spider"])运行main.py函数,得到运行结果。
2018-02-11 15:31:57 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://python.jobbole.com/robots.txt> (referer: None)
2018-02-11 15:31:57 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://python.jobbole.com/89004/> (referer: None)
2018-02-11 15:31:58 [scrapy.core.scraper] DEBUG: Scraped from <200 http://python.jobbole.com/89004/>
{'title': '15 分钟用 ML 破解一个验证码系统', 'create_data': '2018/01/29', 'tags': '实践项目,OpenCV,tensorflow,机器学习', 'praise_nums': '5', 'fav_nums': '13', 'comment_nums': '1'}
2018-02-11 15:31:58 [scrapy.core.engine] INFO: Closing spider (finished)感兴趣的朋友可以自己抓取网页上的正文内容。
欢迎关注我的个人公众号。
















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









