







转载自:Akka入门系列(四):akka cluster原理
在前面remote actor一章提到过,akka remoting是Peer-to-Peer的,所以基于remote功能的cluster是一个去中心化的分布式集群。
Akka Cluster将多个JVM连接整合在一起,实现消息地址的透明化和统一化使用管理,集成一体化的消息驱动系统。最终目的是将一个大型程序分割成若干子程序,部署到很多JVM上去实现程序的分布式并行运算(单机也可以起很多节点构成集群)。更重要的是, Akka Cluster集群构建与Actor编程没有直接的联系,集群构建是在ActorSystem层面上,实现了Actor消息地址的透明化,无需考虑目标运行环节是否分布式,可以按照正常的Actor编程模式进行开发。
我们知道,分布式集群是由若干节点组成的,那么节点的发现及状态管理是分布式系统一个比较重要的任务。Akka Cluster中将节点的生命周期划分为:
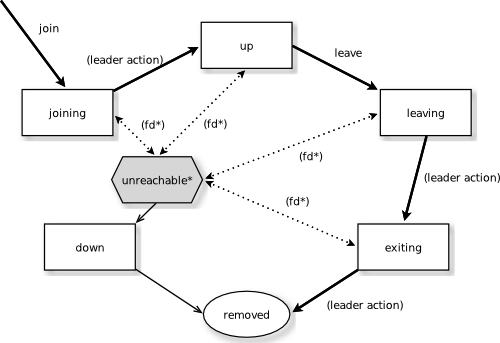
- joining - 当尝试加入集群时的初始状态
- up - 加入集群后的正常状态
- leaving / exiting - 节点退出集群时的中间状态
- down - 集群无法感知某节点后,将其标记为down
- removed - 从集群中被删除,以后也无法再加入集群
其实当参数akka.cluster.allow-weakly-up-members启用时(默认是启用的),还有个weakly up,它是用于集群出现分裂时,集群无法收敛,则leader无法将状态置为up的临时状态。这个后面再解释。
图中还有两个特殊的名词:
- fd* - 这个表示akka的错误检测机制
Faiulre Detector被触发后,将节点标记为unreachable - unreachable* -
unreachable不是一个真正的节点状态,更多的像是一个flag,用来描述集群无法与该节点进行通讯。当错误检测机制侦测到这个节点又能正常通讯时,会移除这个flag。
市面上大多数产品的分布式管理一般用的是注册中心机制,例如zk、consul或etcd。其实是节点把自己的信息注册到所使用的注册中心里,而master通过接受注册中心的通知得知新节点信息。显然本质上是一种master/slave的架构。这种架构有两个问题:
master节点一般是单一的,一旦挂了影响就比较大(所以很多master都采用了HA机制),也就是所谓的系统单点故障;
通常节点的地址发现是要走master去获取的,当系统并发大时,master节点就可能成为性能瓶颈,即单点性能瓶颈。
Akka可能就是考虑这两点,采用了P2P的模式,这样任何一个节点都可以作为”master”,任何的节点都可以用来寻找其他节点地址。那它是怎么做到的呢?答案是Gossip协议和CRDT。
Akka Gossip
基本介绍
Gossip协议
Gossip协议简单来说,就是病毒式的将信息扩散到整个集群,无法确定何时完成完全扩散,但最终是会到达完全扩散状态的(最终一致性),即收敛。具体介绍可以参考我转载的一片文章——P2P 网络核心技术:Gossip 协议,这里就不再重复叙述,着重介绍下Akka是怎么使用Gossip的。
CRDT
P2P的分布式系统中,理论上每个节点都能处理外部的请求,以及向其他节点发送请求。而系统中存在的共享变量,可能在同一时间会被两个不同节点的请求用到,即并发安全问题。一般解决方案是队列或自旋,后者本质上还是一种变相的队列。排队就牵扯到两个问题:
- “谁先来的”
很多人下意识会觉得用时间戳就可以了嘛,但在分布式集群中,每个节点如果是一台单独的服务器,那么每个节点的时间戳未必相同(比如未开启Ntp)。
- “同时来的怎么办”
就像git,能merge就merge,不能merge就解决冲突。
CRDT就是用于解决解决分布式事件的先后顺序及merge问题的数据结构的简称,即Conflict-Free Replicated Data Types的缩写,它的作用是保证最终一致性,出处参阅这份论文。白话文 谈谈CRDT 和CRDT介绍这两篇文章讲的通俗易懂,多的就不再重复了。Akka中节点的状态就是一个特殊的CRDT,使用向量时钟Vector Clock实现方案,关于向量时钟Vector Clock可以参见我转发的这篇文章Vector Clock/Version Clock。
Akka的gossip协议发送的具体内容如下:
final case class Gossip( |
- members 存放该节点知道的其他节点
- seen 已经收到本次gossip的节点们,每个节点当接受到一个新的gossip消息时,会把自己放到seen里面,作为响应返回给发送者
- reachability 这个由错误检测机制
Faiulre Detector的心跳模块来维护,用来判断节点是否存活。正常情况下records应该是空的,当有节点处于Unreachable时,才会有记录加到records里。 - version 向量时钟,用于冲突检测和处理
种子节点 SeedNode
SeendNode一般是提前配置好的一组节点。它用于接受其他节点(可以是种子节点)的加入集群的请求。不同节点,在Akka Cluster中启动时会有不同的逻辑:
- 如果是种子节点,并且是排序后的种子节点数组中排第一的,它会在一个规定的时间内(默认5秒)去尝试加入已存在的集群,即发送
InitJoin消息到其他种子节点。如果未能成功加入,则自己将创建一个新的Cluster。 - 如果是种子节点,但并不是数组中排第一的,则会向其他种子节点发送
InitJoin消息,如果失败将不断重试,直到能成功加入第一个返回响应的已加入集群的种子节点对应的Cluster。 - 如果是普通节点,则会向其他种子节点发送
InitJoin消息,如果失败将不断重试,直到能成功加入第一个返回响应的已加入集群的种子节点对应的Cluster。
这里有一点值得注意,为什么是加入第一个返回响应的种子节点所在的集群?这个问题后面再解释。
过程详解
下面用一个简单的场景来解释整个交互过程,假定我们有两个节点n1和n2,其中n1是种子节点。我们让n2先启动。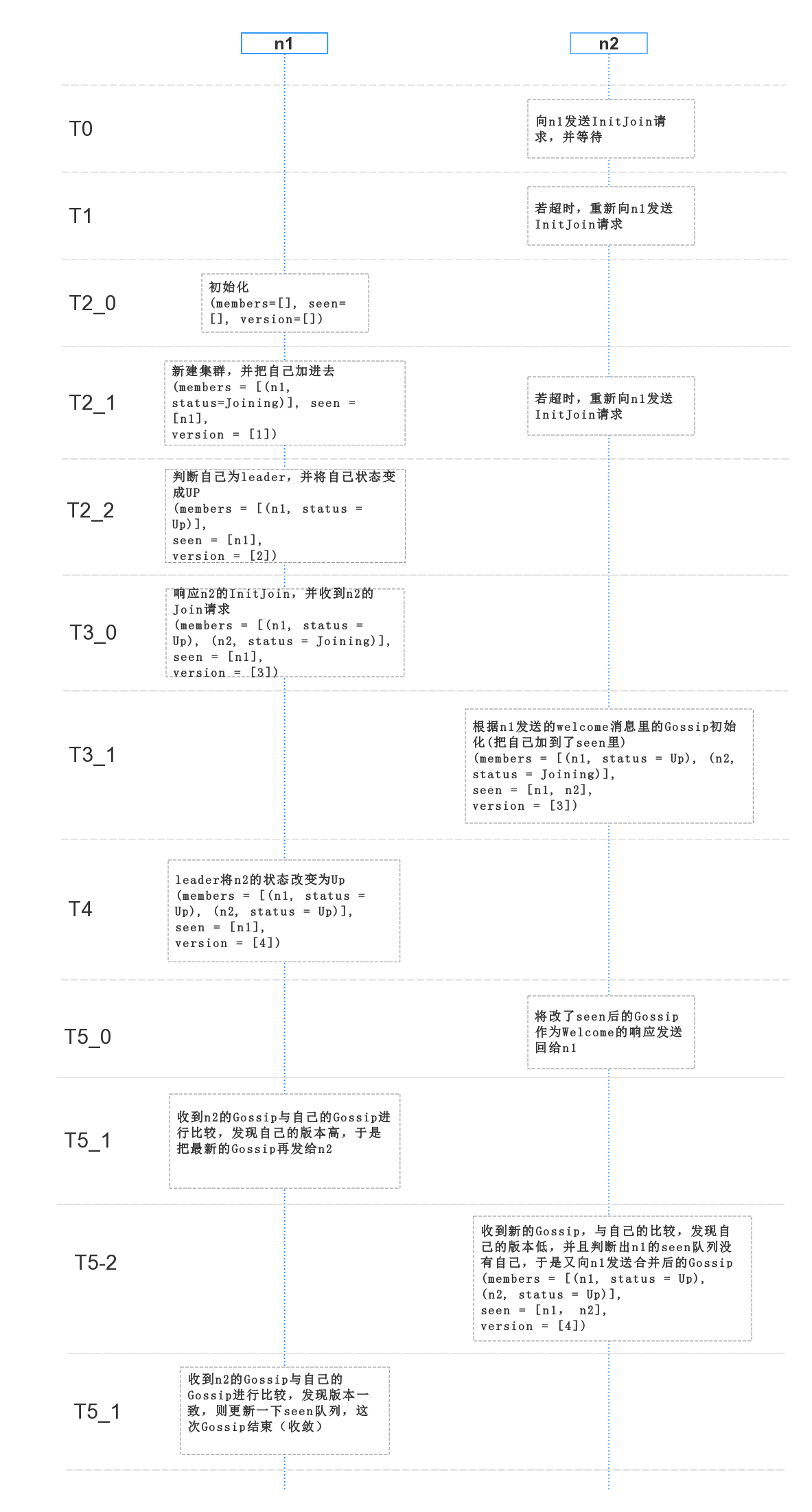
上图中的T0、T1表示时间轴,但只是为了方便将步骤拆解,便于理解。其中T4和T5并没有必然的时间前后关系,这里只是假定T4在前,步骤基本是类似的,T5在前也只是稍有不同。
#T0、T1时刻只是为了表明n2在启动时,如果没有种子节点响应,则会一直等待重试
#T2时刻种子节点自己新建一个集群,由于新集群只有它自己,members和seen是一样的,所以把自己作为集群的leader。
leader
- Gossip协议中没有
leader选举过程 leader只是一个角色,任何节点均可以是leaderleader的确定非常简单:集群收敛后,当前members队列按IP进行排序,排第一位置的节点就是整个集群的leaderleader并非一直不变,如果集群有新节点加入或某节点退出,导致发生Gossip过程,收敛后都会重新确定leaderleader的职责是更新节点在集群中的状态以及将集群的成员移入或移出集群
注意,这里有个地方容易被误解:“n1和n2构成一个集群,不是在T5才收敛吗?怎么在T2就确定
leader了?”
其实当第一个种子节点新建cluster时,由于只有它一个,即seen和members里内容一样,它判断当前集群已收敛,就把自己当作leader了。所以才有了T2_2和T4。
#T3时刻是n1响应n2的InitJoin请求,具体交互过程如下: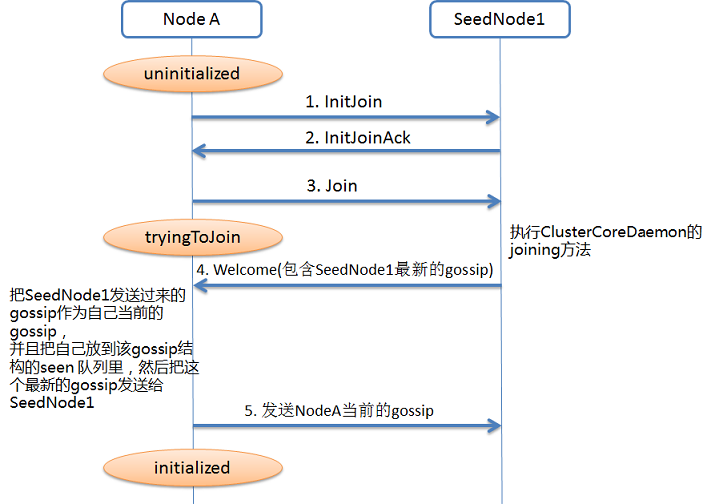
#T3_0种子节点收到n2的Join消息后,会做两件事:
- 更新当前Gossip的向量时钟;
- 清空当前Gossip的seen队列,然后把自己加进去。(后续发起Gossip交互时,会优先选择那些没在seen队列中的成员)
#T4时刻因为作为fd能正常与n2进行心跳,n1作为leader就被通知将n2提升为Up状态
#T5时刻是一个CRDT的对比过程,对比两个Goissp的version,即VectorClock,比较的结果有三种:
- Same: 相同,则进行seen队列合并就可以了
- Before: 本地新,则向对端发送本地的Gossip,本地不变
- After: 对端新,则更新本地的Gossip。如果对端的Gossip的seen里没有包含本地,则将自己添加到seen里发送给对端,以减少一次两者间的Gossip交互。
#T5时刻最后集群达到了收敛
Gossip 收敛
从上面的图里可以看到节点初始化时会把自己加入到members里,回传回去,同时,节点在收到新的Gossip时,会把自己加入到seen里面。那么,在一开始,members和seen中的节点数是不同的。
当Gossip传递的消息被整个集群都消化掉的时候,可以称作当前集群的Gossip收敛。靠以下条件判断Gossip收敛:
- 集群中不存在
unreachable的节点,或者unreachable的节点应该均处于down或exiting状态 - 正常节点均处于
up或leaving状态,且members里的节点都在seen里,即集群中所有的节点都收到过该Gossip
代码演示
说了那么多文字,Akka Cluster提供了监控ClusterEvent的方法,我们可以用代码来校验下上面的知识。
添加依赖















 689
689

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









