







声明一下总结这些之前还没有学泛型.所以所敲代码警告较多。
1.
一级接口:Collection,
二级接口:List Set
三级实现类:ArrayList类,LinkedList类, HashSet类, LinkedHashSet类, TreeSet类
其中,
注意事项:一级接口指向三级实现子类(ArrayList类, LinkedList类, HashSet类,LinkedHashSet类, TreeSet类 )的时候,例如 Collection con =new ArrayList();其中ArrayList()可用其他三级实现子类代替
con.add("aa");
con.add(newString("AA"));
con.contains(new String("AA"));//返回true
con调用contains(object obj)的时候 ,集合判断是否包含某个对象时,调用的是equals()方法,判断内容,如果内容一样返回true,否则返回false.
当然在调用自定义类的时候,需要对自定义类重写equals()方法.详情请看JavaSE第十二天的Contains注意事项.
con.add(newPerson("tom",12));
con.contains(newPerson("tom",12));//返回 false 如果不对Person重写equals方法,这个会返回false,(con集合里面明明有newPerson("tom",12)这个对象,用我们上面说的调用equals方法按道理是返回true的为啥结果会返回false呢?) 原因是自定义类没有重写equals()方法,直接调用系统(Object)的equals方法是不行的,该方法是比较地址的,这个时候去自定义类里面source里面右击找到一个Generate hashCode()and equals()点击自动生成这个方法,hashCode()暂时不需要 自动会生成的,要不要无所谓.
List接口:是Collection的子接口,存放数据的特点 有序,可以出现重复元素,既然有序,就是可以对元素的下标进行存储.
(1).ArrayList类:
是List的实现子类.其使用的数据存储结构是数组,特点:查改快,增删慢,理解:之所以查改快,是因为数组是根据下标index进行操作的,所以其查询更改效率更高;
而相应的,要是对其进行增加和删除,会在内存空间中重新开辟空间,因为数组在一开始定义的时候就确定了内存大小.要是进行增加操作会开辟更大一点的空间,删除操作同理.所以其增加删除效率会低.
(2)LinkedList类:
也是List的实现子类.其使用的数据存储结构是链表,特点:查改慢,增删快,理解:之所以查改慢,是因为链表是没有索引值进行快速的查询,其要一个一个遍历才可以对元素进行查找或修改操作.
效率着实太慢.而相应的增删快,只需要根据元素值增加或修改即可.不需要关心它放在那里,放进去就行了,修改同理,这样效率就很高.
Set接口:也是Collection的子接口,存放的数据是无序的,且不能出现重复的元素.
无序!=随机 这里的无序指的是元素在内存中的存储位置是无序的
不可重复:就是当向集合中添加A和B元素的时候,如果A和B相等,A添加进去,B就不能添加进去了.
(1)HashSet类:其使用的数据结构是哈希表 查询慢 增删快 查询根据迭代器iterator一个一个查询元素,而增删是根据元素进行添加删除的操作.效率较高.
对Set集合不可出现重复元素的说明:
Set set = new HashSet();
set.add("456");
set.add("123");
set.add(666);
set.add(new String("AA"));
set.add(new String("AA"));
set.add(new Dog("tom", 18)); //=====>>A
set.add(new Dog("tom", 18)); //=====>>B
System.out.println(set);
运行上面的代码结果如下图

A添加进去了,B就添加不进去了,上图结果显示是可以添加进去的.(疑问:跟我们理解的set类不允许出现重复元素不是相矛盾吗?)
提出疑问:Set集合是怎么判断两个元素是否重复?
解答:是根据两个方面进行判断的,分别是hashCode()和equals()方法
首先先判断hashCode()值,在判断equals(),hashCode():每个对象都有一个哈希值,然后根据哈希值的不同,会把元素存储到内存中不同的位置
hashCode()它的作用决定元素在内存中位置,方便根据哈希值快速定位元素的内存位置,如果内存中没有元素,则直接插入
如果不一样直接插入,一样在对equals()方法进行比较,,如果一样就不插入,不一样就插入.
以下例子为例:
Set set = new HashSet(); //其中HashSet可以有 LinkedHashSet 和TreeSet代替 但是TreeSet有个细节就是排序的问题后面再讲,其自定义类要继承 Comparable接口实现CompaerTo方法的重写.
set.add("456");
set.add("123");
set.add(666);
set.add(newString("AA"));
booleancontains = set.contains(new String("AA"));
System.out.println(contains);
set.add(newString("AA"));
set.add(new Dog("tom", 18));
booleancontains2 = set.contains(new Dog("tom", 18));
System.out.println(contains2); //true
set.add(newDog("tom", 18));
System.out.println(set);
System.out.println("AA".hashCode());
System.out.println("AA".hashCode());
System.out.println(newDog("tom", 18).hashCode());
System.out.println(newDog("tom", 18).hashCode());
System.out.println(newDog("tom", 18).equals(new Dog("tom", 18)));
//上述没有对Dog类hashCode()重写但是对equals()重写了.运行结果如下图:
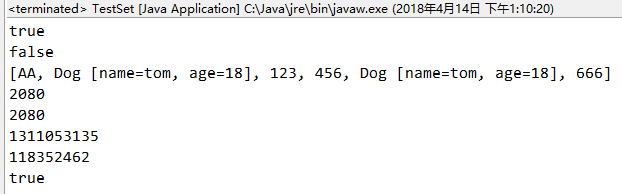
(一)对上述结果解释如下:
①第一个true 因为String是系统类,系统已经对String重写了hashCode()和equals()方法,我们只需知道equals方法重写就行了 因为contains()用到的是equals()方法.
②第二个false 因为Dog类没有对hashCode()方法重写 红色的newDog("tom", 18)的哈希值跟橙色的new Dog("tom", 18)的哈希值不一样,所以判断的结果是false
③第三个结果 为什么我们肉眼看到的两个相等的Dog元素为什么可以添加进去,因为Dog类没有重写hashCode()方法,系统认为他们hashCode()是不一样的,所以hashCode()不一样第二个Dog元素就直接插入进去了.
④第四个结果 两个String类型的AA的哈希值都是2080,因为系统String类重写了重写了hashCode()和equals()方法,两者的哈希值肯定是一样的.equals()得出的结果也是一样的.(equals()运行结果看①).
⑤第五个结果true 因为Dog类重写了equals()方法.
//上述对Dog类hashCode()重写但是没有对equals()重写了.运行结果如下图:
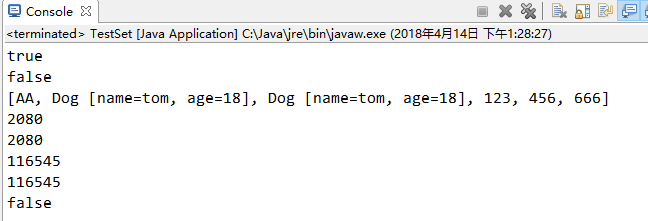
(二)对上述结果解释如下:
①第一个true同(一)中的①.
②第二个false,虽然重写了hashCode(),哈希值一样 比较equals()方法,但是Dog没有重写equals()方法,使用的Object(因为Object是所有类的父类)中的equals()方法,该equals()方法比较的是地址,很明显new对象了 地址肯定不一样所以是false.
③第三个结果 为什么我们肉眼看到的两个相等的Dog元素为什么可以添加进去,虽然重写hashCode()得到的方法是一样的哈希值,哈希值一样了还得比较equals()方法,但是equals()方法Dog没有重写调用父类的equals()方法,该equals()方法比较的是地址,也是new出来的对象,地址明显不一样,所以equals()得到的值也不一样,所有第二个Dog元素就可以直接添加进去了.
④第四个结果 String()重写了hashCode()方法和equals()方法 ,其哈希值肯定是一样的两个2080.两个116545同理String 因为Dog类重写了hashCode()方法,所以其哈希值是一样的
⑤第五个结果false Dog类没有重写equals()方法,调用的是Object的equals()方法,该equals()方法比较的是地址,两个new出来的对象地址肯定不一样,所以结果false.
//上述对Dog类hashCode()和equals()都重写了.运行结果如下图:
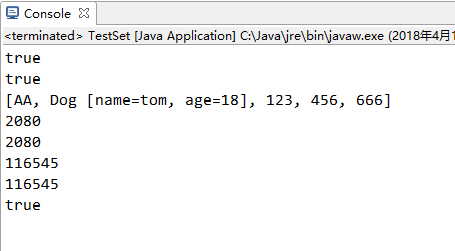
(三)对上述结果解释如下:
第一个true同(一)/(二)中的①;
第二结果true Dog类重写了hashCode()和equals()方法,红色的newDog("tom", 18)上面的橙色的new Dog("tom", 18)得出的哈希值和equals是一样的,所有返回ture;
第三个结果 Dog类重写了hashCode()和equals()方法,所以肉眼看到的两个元素是一样的这次通过重写的hashCode()方法和equals方法()判断的就真的是一样的了.所有只添加了其中一个元素.
第四个结果 String()重写了hashCode()方法和equals()方法 ,其哈希值肯定是一样的两个2080.两个116545同理String 因为Dog类重写了hashCode()方法,所以其哈希值是一样的
第五个结果 true Dog类重写了equals()方法,所以是true.
(2)LinkedHashSet类 其存储的数据结构是哈希表+链接列表 查询快,增删慢 根据链接列表查询较快 增删要使用迭代器一个一个遍历找到这个元素才可以删除 .
哈希表存储结构将元素可以随机放入内存中,链接列表维护了一个有序的存储顺序迭代的时候就按照链接列表中的顺序去迭代正是有了链接列表的存在,所以元素插入的顺序和取出的顺序是一致的
迭代器:
//有error的会发生并发修改异常,你在使用迭代器和foreach()千万不要修改集合的长度(不能删不能添加),但是有ture的修改集合的长度(即增删操作)不会发生并发异常.
/*for(Object object : source) {
//强转数据类型
Bookbook=(Book) object;
if(book.getName().equals(name)){
source.remove(object);
}
}*/ //error
for(int i = 0; i < source.size(); i++) {
Objectobject=source.get(i);
Bookbook=(Book) object;
if(book.getName().equals(name)){
source.remove(object);
}
}//true
/* Iteratoriterator=source.iterator();
while(iterator.hasNext()) {
Bookbook = (Book) iterator.next();
if(book.getName().equals(name)){
//使用迭代器来做删除操作
source.remove(book);
}
}* //error
/*ListIteratorlistIterator = source.listIterator();
while(listIterator.hasNext()) {
Bookbook = (Book) listIterator.next();
if(book.getName().equals(name)){
//使用迭代器来做删除操作
listIterator.remove();
}
}*///true
(3)TreeSet类 无序不重复
TreeSet会对插入的元素进行排序
排序的依据?
①自然排序:依赖于元素的compareTo()方法,以为这compareTo只有中只有实现了compareTo方法才能排序
Integer String都实现了compareTo()方法排序,前提是Integer和String类继承Comparable接口.
一个对象的CompareTo()、hashCode()、equals()结果应该一致.
以String为例:
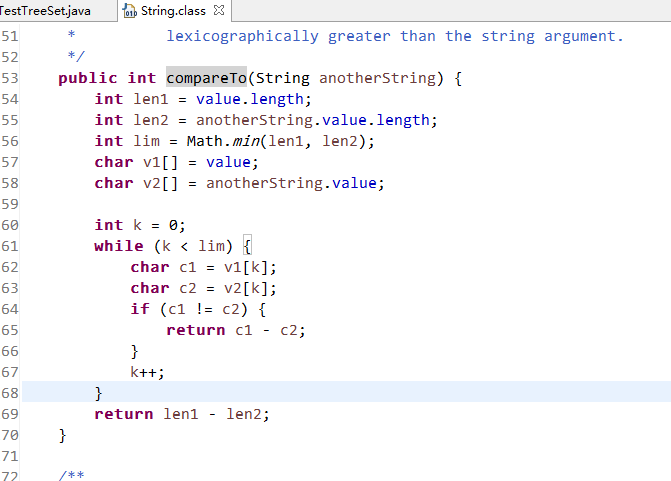
以下面的代码为例:
Setset2=new TreeSet();
set2.add(newPerson("bb", 19));
set2.add(newPerson("cc", 20));
set2.add(newPerson("aa", 18));
set2.add(newPerson("aa", 2000));
如果没有person类继承Comparable接口实现CompareTo()方法会报这样一个错:
Exception in thread"main" java.lang.ClassCastException: com.lanou3g.setdemo.Personcannot be cast to java.lang.Comparable
Comparable是一个接口,其中只有一个方法那就是CompareTo()方法.要对其进行重写
首先得继承这个接口:如下图

接着对方法进行重写如下图:

②定制排序
依赖TreeSet(TreeMap)自己构造的方法

下面这种方法是写在一个方法里面,然后在main方法里面调用simpleMethod();
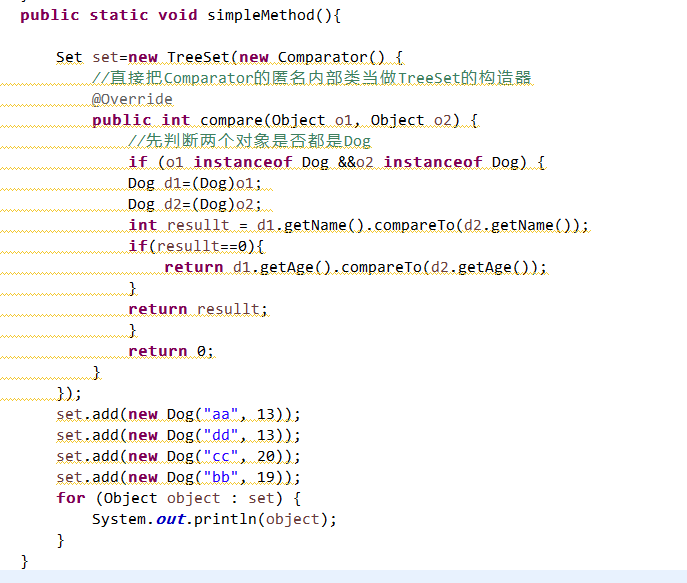
2.
一级接口:Map
Map接口,定义了所有Map下集合的公共方法;
特点:
①元素以key-vlaue的方式出现,键值对的方式
②Map中的元素也是无序的
③Map中的key值是唯一的,体现了元素不可重复性
如何遍历Map集合?
//方式一:不建议使用
// 1.现获取所有的key值
Setkeys = map.keySet();
//2.遍历存储所有的key值指的keys集合
for(Object key : keys) {
//根据key值获取map中的values值
Objectvalue = map.get(key);
System.out.println(key+"=>"+value);
}
//方式二:建议使用
//entrySet()这个方法会返回一个Set集合,集合存储的都是Entry对象
//这个对象中存储的就是对应的一对键值对key和value值
SetentrySet = map.entrySet();
for(Object o : entrySet) {
Map.Entryentry=(Map.Entry) o;
System.out.println(entry.getKey()+"==>"+entry.getValue());
}
Map集合中添加元素和修改元素是同一方法.
根据key去修改value的值.
实现子类:HashMap类,LinkedHashMap类, TreeMap类
(1).HashMap类
同Map类
(2).LinkedHashMap类:
LinkednHashMap也是存储的键值对,比着Map集合对出来个特点,它里面存储的内容是有序的,也是通过链接列表维护的,仅仅维护key值.
(3).TreeMap类
同TreeSet类,其中key数据类型必须一致.
总结重点 :Set不可出现重复元素使用add()方法如何判断两个元素是否相等?
TreeSet和TreeMap两者排序方法的总结.
Set
向集合添加元素是先判断有没有这个元素 有添加进去,没有添加失败
Map
向集合添加元素是根据key值以一种覆盖的形式添加(也可理解为修改的意思)因为Map添加元素和修改元素是同一种方法.















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









