







文章目录
前言
我们上一篇博客也介绍了,当搜索引擎要响应用户查询的时候,需要把索引加载到内存中。这个过程有两个难点:
- 大量的IO操作
- 庞大的倒排索引结构
为了解决这个问题,我们需要对数据量进行压缩,这样这两个问题可以一并得到缓解,这也就是索引压缩。一般来说,倒排索引分为两个结构:单词词典和倒排列表。所以,对索引的压缩也就会分为这两个部分去压缩。

词典压缩
我们先看这样一种倒排索引的情况,在这种情况下对于单词词典的每个元素我都要留够足够的空间,那么在这种情况,我们每个元素就要花8字节的空间(一个汉字两字节)。

但是对于关键词汽车来说,明明四个字节的空间就够用,我浪费了4个字节的空间,这是对内存极大的不尊重,不符合勤俭节约的美德。所以就有了如下的改进措施,将单词连续存储在某个内存空间,原先存储单词的部分被替换为<单词起始位置,单词长度>这样一个元素代替。

那么在查找关键词的时候,传统的想法可能是假如搜索索引这个关键词的,我们根据hash算法知道它在0号桶,那么我们就开始把0号桶中的元素翻译长单词词典,这个时候<10,4>被翻译成MySQL,和查找词索引比对;不是,接着翻译下一个元素,直到找到索引这个单词。这样假设0号桶中有m个元素,那么这个过程最多会经过m次翻译过程。这样相当于拿时间去换取空间了。
那么其改进策略也很好想,我们从关键词入手,把它和词汇表进行比对这个就可以得到索引这个词在词汇表中对应的元素是<6,2>,又知道它在0号桶,那么根据二分查找便可以很快的定位到元素了。
不过这个过程也有缺陷,在关键词和词汇表比对的时候,其实有很多元素不是在0号桶中的,那么为啥还要比对呢?这里一个好的想法就是把词汇表拆开,每个桶一个词汇表,这样就可以达到时间和空间的相对优化。
倒排列表压缩
单词对应的倒排列表一般由<文档编号,词频信息,单词位置信息>这个三元组组成。因为是顺序存储,所以通常的做法是存储其差值。经过差值转换之后,文档编号和单词位置信息通常会被转换为大量小整数,而词频信息本身就是小整数。而我们要压缩的就是这三类数据。

而评价一个压缩策略主要是三个维度:压缩率、压缩速度以及解压速度。其中第一个是空间考量,另外是两个时间考量。
一元编码和二进制编码
一元编码和二进制编码是所有压缩算法的基础,所以我们有必要好好讲讲。
一元编码,对于一个数字x,会用x-1个二进制数1和一个数字0来表示这个整数。那么对于5这个元素,其就会被表示成11110这样的5位。那么对于1011011101111011110这么一串二进制数便会被翻译成12345 。而二进制编码则是很常见的用二进制去表示10进制,就不多解释了。
变长比特算法
Elias Gamma算法
Elias Gamma算法利用分解函数将待压缩的数字分解成两个因子e和d,之后用一元编码和二进制编码来表达这两个因子。那么对于数字x,其组成便如如下公式:
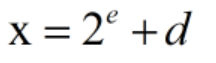
这样得到分解因子之后,我们对因子e+1采用一元编码的方式;对因子d采用比特宽度为e的二进制表示。最终的表现形式就是UnaryCodeing(e+1):BinaryCoding(d)
那么假设x为11,那么我们便可以得到e = 3,d = 4 。对e+1采用一元编码为1110,对于d则采用二进制编码100。那么x便可以表示为1110:100 。
Elias Delta算法
Elias Delta算法基于Elias Gamma算法,其可以看作利用两次Elias Gamma算法,将数字x分解为3个因子,其中d不变,对e会进行二次压缩。最终的表现形式就是UnaryCodeing(E+1):BinaryCoding(D):BinaryCoding(d)
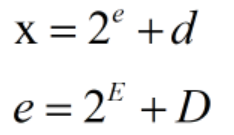
这样还是假设x为11,那么可以得到e = 3,d = 4。这个时候对e进行二次压缩,得到E = 1,D = 1,这样e便可以被表示为101。那么最终x便会被表示为10:1:100 。这样空间上还会比Elias Gamma少一位,对于大数值来说Elias Delta的压缩效果无疑是更好。
Golomb算法
Golomb算法会根据分解函数将待压缩的数值分为两个因子,分别采用一元编码和二进制编码来进行数据压缩表示。和上面的算法不同的是它们采用的函数时不同的,最终表现形式为:UnaryCodeing(Arg1):BinaryCoding(Arg2)

我们可以看到,两个因子最后的取值都和这个变量b有关,在Golomb算法中,设定这个b的取值为待压缩数值序列的平均值Avg*0.69,0.69是个经验参数。
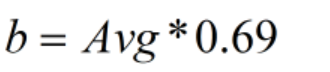
我们假设有如下的待压缩数值
11 12 34 55 23
首先我们计算平均值:Avg = 27
之后计算出参数:b = 18
假设对于X = 11,那么我们就可以计算出Arg1 = 11/18 = 0;Arg2 = 11/18 = 11。那11经过Golomb算法之后,得到的数值便是0:1011。
Rice算法
Rice和上面的Golomb算法相似,只是对b的取值不同。其要求b必须是小于Avg的最大的2的整数次幂的结果,即
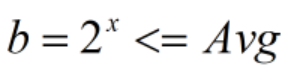
注:
Rice算法这样取值的原因是为了方便移位操作以快速运算
那么在上面11的例子中b=16。
那么便可得在Rice算法中的Arg1=0;Arg2=10。那11经过Rice算法之后,得到的数值也是0:1011。
变长字节算法
前面的算法基本单位都是比特,所以是变长比特算法。变长字节算法则是以字节为基本单位,为了确定两个连续数字压缩后的边界,需要利用字节中一个比特位作为边界判断符号。所以,一个字节概念上被划分为两部分,其中一个比特位用来做边界判断;其他七个比特位采用二进制编码存储压缩数据。对于边界位来说,如果为0就表示这个是压缩数据的最后一个字节,如果是1则相反。
SimpleX 系列算法
SimpleX系列算法是一种字对齐算法,我们就以Simple9算法为例。
Simple9算法会以32个比特位来作为一个压缩单位,这32位会被分为两部分,其中4个比特位会被作为管理数据存储区,剩下28个比特位作为压缩数据存储区。
假设管理区域中B=7,那就表示这个区域可以存放4个0~127范围的数字。而对其进行解码的时候,我们就直接读取4个字节的数据,然后读取4bit的元信息,根据元信息去解析后面存储位的信息。

PForDelta算法
PForDelta算法是一种解压速度很快的倒排文件压缩算法,其基本出发点是尽可能一次性压缩和解压多个数值。其对于代编码的K个数值,找出其中10%比例的大数,根据剩下90%范围决定应该采取的比特宽度,而10%的大叔当作异常数据单独存储。
以下面这组数为例:
24 40 9 13 31 67 19 44 22 10
其中的大数为67,大数不会进行压缩。其会被存储到异常数据存储区,之后由一个异常链表头指向。而对于正常的小数,我们首先要做的就是找出小数中的最大数以确定需要的比特宽度,算法则可以采用Gamma等算法进行压缩。最后会形成以下的数据信息:

静态索引裁剪
上面的压缩算法都属于无损压缩,而静态索引裁剪属于有损压缩。其会通过主动抛弃一部分不重要的信息来达到更好的数据压缩效果。其出发点基于如下:对于用户来说,其往往只需要返回一部分相关度最高的网页,相关较低的网页不同返回,那么这些就不要压缩了。在此基础上,整个静态索引裁剪主要有两种思路:单词为中心的索引裁剪、文档为中心的索引裁剪。
单词为中心索引裁剪
对于某个单词来说,其对应的倒排列表记载了出现这个单词的文档编号信息,那么其裁剪对线便是单词对应倒排列表中的文档。
假设我们经过一个相似性计算函数func(word,doc)计算出倒排列表项相似性,结果如下:

最简单的方法是设定一个阈值b = 0.35,小于这个阈值的文档都从倒排列表中删除。

但是通过上图我们可以看到,如果阈值设置的过大就会导致结果过少。所以我们还可以再加一个限制条件:设置一个最少文档数 k=3,保证最少会有三个结果。

以文档为中心的索引裁剪
和以单词为中心的索引裁剪不同的是,以文档为中心的索引裁剪可以认为旨在建立索引之前进行的数据预处理措施。可以说,一个是事后处理,一个是事前处理。
文档中包含很多单词,有些单词对于文档的主题表现是可有可无的。那么以文档为中心的索引裁剪首先会判断文档所包含单词的重要性,经过计算之后,只留下重要的单词建立索引,无关单词不建立单词到这个文档的索引。这样每个文档就会缩水,然后在此基础上建立倒排索引,这样就可以达到减少索引大小的目的。
参考文献
[1] 这就是搜索引擎
















 2104
2104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











