







上面有目录,嫌麻烦的可以直接看结论
1. 问题
之前使用java自带的压缩工具,ZipOutputStream写了一个压缩文件的方法。前几天整理代码的时候,更改了关流方式,同时整理了一下代码结构。当时没有注意重新测试这个方法,今天使用调用这个工具方法的接口时,发现生成的压缩文件不可读,出现 不可预料的压缩文件末端 的问题。
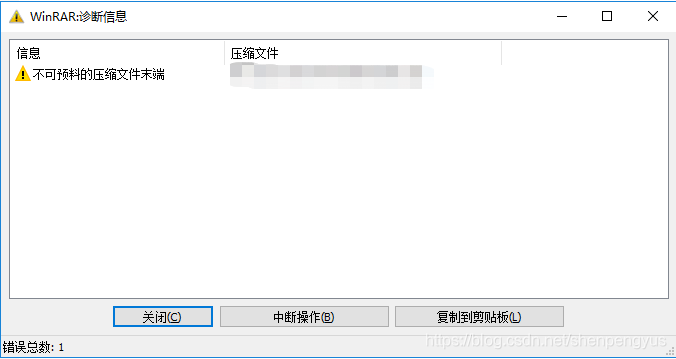
问题在于,这个压缩方法在许久之前是可以用的,于是我找出了git提交的历史记录。
这是历史记录中的代码逻辑:
public static byte[] goZip(Map<String, byte[]> fileMap) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ZipOutputStream zip = new ZipOutputStream(bos);
try {
for (Map.Entry<String, byte[]> file : fileMap.entrySet()) {
ZipEntry entry = new ZipEntry(file.getKey());
entry.setSize(file.getValue().length);
zip.putNextEntry(entry);
zip.write(file.getValue());
}
} finally {
zip.closeEntry();
zip.close();
}
return bos.toByteArray();
}
这是改动之后的代码逻辑:
public static byte[] goZip(Map<String, byte[]> fileMap) throws IOException {
try (ByteArrayOutputStream bos = new ByteArrayOutputStream();
ZipOutputStream zip = new ZipOutputStream(bos)) {
for (Map.Entry<String, byte[]> file : fileMap.entrySet()) {
ZipEntry entry = new ZipEntry(file.getKey());
entry.setSize(file.getValue().length);
zip.putNextEntry(entry);
zip.write(file.getValue());
}
zip.closeEntry();
return bos.toByteArray();
}
}
对比一下,改动的地方有两处,一是将两个流挪到了try()中改成了更优雅的写法,二是把return挪到了try块里面。
2. 过程
长话短说——
- 先把try()中new的两个流拿出来,放在try块前面初始化,改为在finally中关流 —— 结果没变;
- 又把
return bos.toByteArray();代码放到try块后面执行 —— OK; - 再尝试重新把两个流放回到try()中初始化,省去finally关流步骤 —— 仍然OK;
问题找到了——
3. 原因
表象
就是ruturn的锅,return bos.toByteArray(); 的执行是在try块里还是在外面直接影响了压缩文件的完整性;
深究
代码中,bos.toByteArray();的作用就是最终,将整个一点一点写进缓冲流的压缩文件的字节码,转换成 byte[] 数组的形式。我们知道finally块中的代码,是在try块中的 return 之前执行,但要知道,return bos.toByteArray(); 虽然再同一行,但其实是在执行 bos.toByteArray(); 之后,把对应的值缓存起来,等finally块执行之后再return,相当于还是在关流之前执行了 bos.toByteArray(); 。
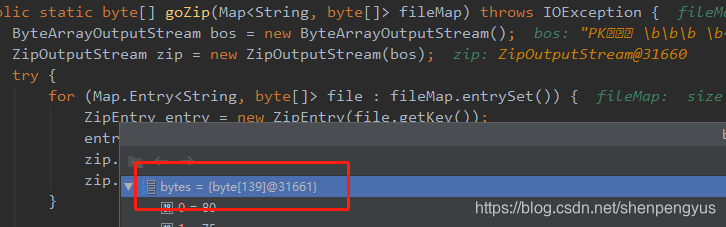
经测试,当选择一个文件内容压缩,压缩逻辑为:先关压缩流,然后将缓冲流的内容输出,此时得到的的结果是正常的压缩文件,压缩文件字节码长度是139
当将压缩代码逻辑改为:先将缓冲流的内容输出,然后关压缩流,此时得到的的结果是异常的压缩文件,压缩文件字节码长度是66
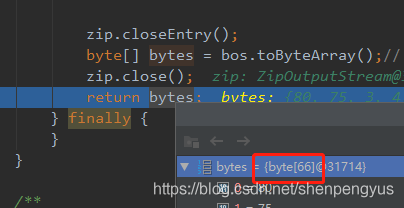
可见,异常的压缩文件丢失了一段长度。
还记得WinRAR软件报出的错误吗?“不可预料的压缩文件末端”,我们能猜测到,是结尾的某一部分丢失了。
本质
看一下 ZipOutputStream 相关的代码:
- 这是压缩输出流的构造方法,传入的是我们用于接收压缩文件内容的缓冲输出流
public ZipOutputStream(OutputStream out) {
this(out, StandardCharsets.UTF_8);
}
- 其中的
this的构造方法就是这
public ZipOutputStream(OutputStream out, Charset charset) {
super(out, new Deflater(Deflater.DEFAULT_COMPRESSION, true));
if (charset == null)
throw new NullPointerException("charset is null");
this.zc = ZipCoder.get(charset);
usesDefaultDeflater = true;
}
- 但是我们仍然不清楚最开始的入参的缓冲输出流去哪了,一直追溯到最终的地方,其实把入参赋给了它的超类成员变量
this.out
……
public FilterOutputStream(OutputStream out) {
this.out = out;
}
- 我们再看一下
close();方法对我们的缓冲输出流做了什么
public void close() throws IOException {
if (!closed) {
super.close();
closed = true;
}
}
……最终在这样一段代码里找到了它:
protected void deflate() throws IOException {
int len = def.deflate(buf, 0, buf.length);
if (len > 0) {
out.write(buf, 0, len);
}
}
其中 out.write(buf, 0, len); 的方法往我们的缓冲输出流中写入了最后一段字节。代码中的 buf 就是压缩流中的缓冲区,当缓冲区没有满的时候,最后一段内容,还没有同步到用于接收的流中,当调用 close(); 方法时,压缩流意识到马上就要结束了,需要把最后的一段内容赶快写到接收的流中。
于是我们发现了,原来关流之前,还有一段文件内容没有输出,此时我们就将缓冲流转换成字节数组就为时过早了。
但是还有一个问题,WinRAR怎么知道压缩文件末端损坏了呢?我猜测,压缩文件之所以被识别成压缩文件,一定是有一个头标识和尾标识,当 close(); 方法执行是,同时也将尾部标识写进了流中,当压缩文件字节码缺失最后一段内容的同时,也缺失了压缩文件的尾部标识。由于时间限制,我就不做对应的验证了,后续有时间想起来再验证一下我的想法。如果有哪位大佬清楚其中的原理,希望再评论中指正!十分感谢。
4. 结论
- 使用ZipOutputStream时,调用过
close();方法之后才算结束,在此之前,得到的内容是不完整的; - finally块在return之前执行,但并非在return行之前执行,finally只会在得到return的值之前执行;
- ZipOutputStream的
close();方法中对流进行了最后一段内容的输出; - 遇到问题要分析每个影响因素,并写多个样例做对照样本;
- 遇到问题看源码很多时候能出奇制胜。















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









