







一致哈希算法:如何分群,突破集群的“领导者”限制?
通过分集群,突破单集群的性能限制
使用哈希算法有什么问题?
问题:节点数量从3变成4,那么之前的hash(KEY)%3=1,就变成了hash(KEY)%4=0。所以这时候再查询,KEY对应的数据,存储在节点A上,而不是节点B上
解决方案:迁移数据,3节点增加一个节点,需要迁移75%的数据
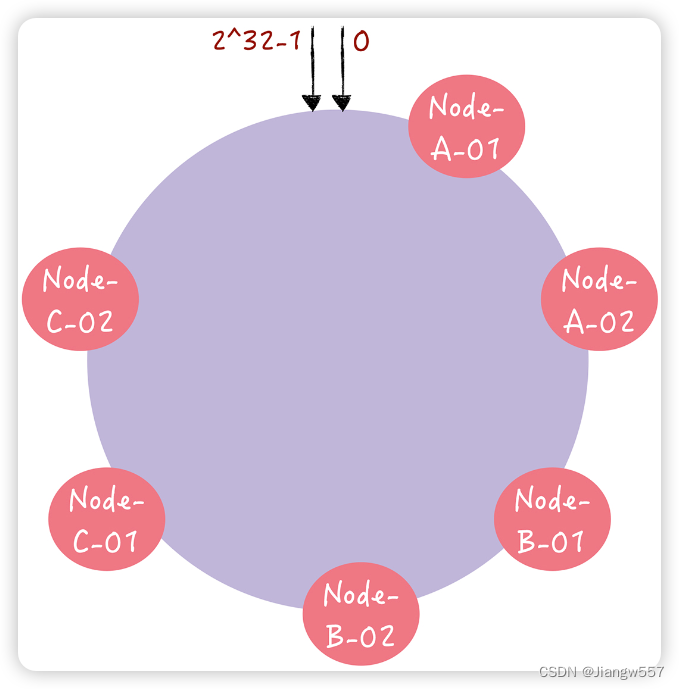
如何使用一致哈希实现哈希寻址?
步骤:
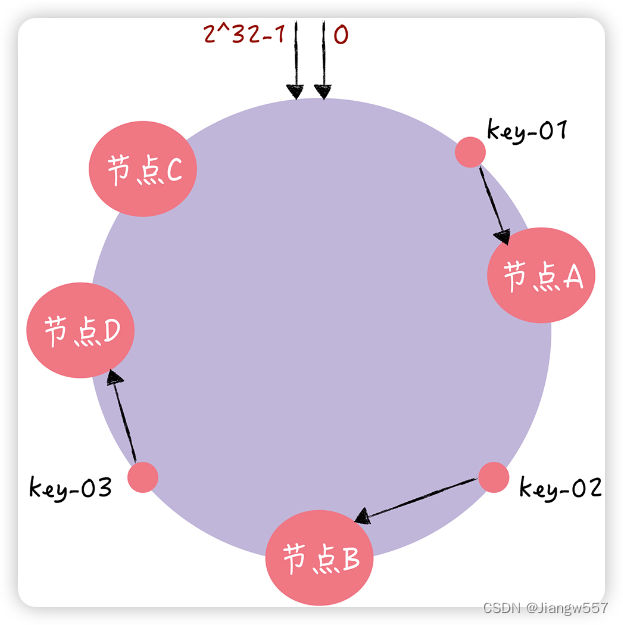
首先,将 key 作为参数执行 c-hash() 计算哈希值,并确定此 key 在环上的位置;
然后,从这个位置沿着哈希环顺时针“行走”,遇到的第一节点就是 key 对应的节点。
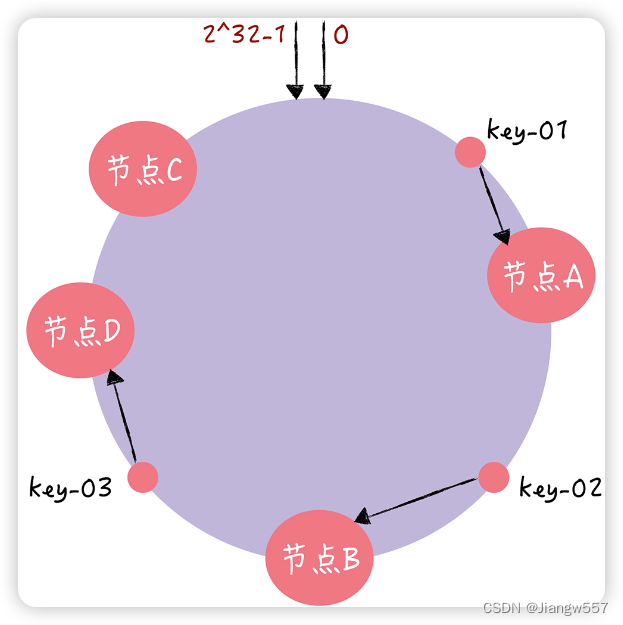
一个节点故障:只影响寻址到节点B和节点C之间的数据,寻址到其他哈希环空间的数据不会受到影响
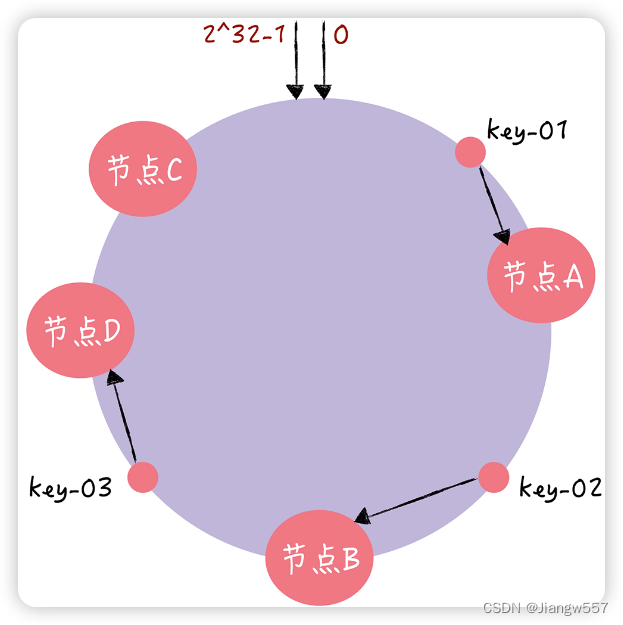
增加一个节点:受影响的数据仅仅是,会寻址到新节点和前一节点之间的数据,其它数据也不会受到影响。
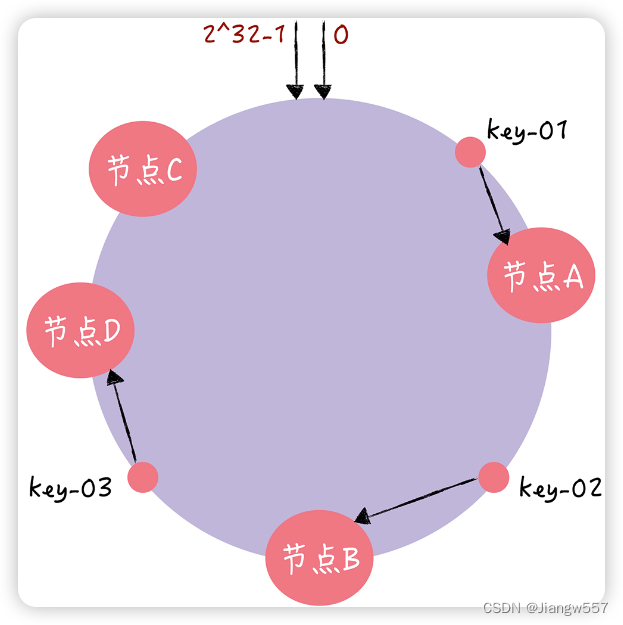
增加 1 个节点,变为 4 节点集群,只需要迁移 24.3% 的数据
其他问题
- 一致性哈希算法具有较好的容错性和可扩展性
- 如何让数据访问分布的比较均匀:虚拟节点
















 1887
1887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











