







1.1ARM7流水线
ARM7采用典型的三级流水线的冯.若伊曼结构。每条指令分取址,译码,执行三个阶段,分别在不同的功能部件上依次独立完成。取指部件完成从存储器装载一条指令,通过译码部件产生下 一周期数据路径需要的控制信号,完成寄存器的解码,再送到执行单元完成寄存器的读取、ALU运算及运算结果的写回,需要访问存储器的指令完成存储器的访 问。流水线上虽然一条指令仍需3个时钟周期来完成,但通过多个部件并行,使得处理器的吞吐率越位每个周期一条指令,达0.9MIPS/MHz的指令执行速度。
1.2. 为何ARM7中PC=PC+8
此处解释为何ARM7中,CPU地址,即PC,为何有PC=PC+8这一说法:
首先,对于ARM7对应的流水线的执行情况,如下面这个图所示:
图 1.1. ARM7三级流水线状态
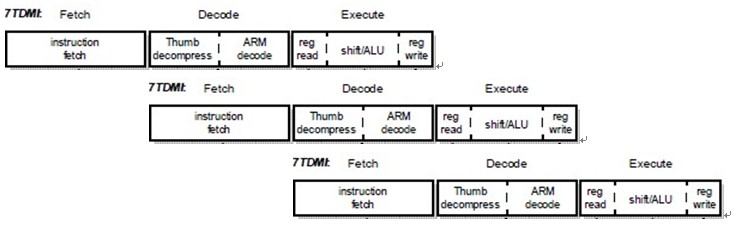 |
然后对于三级流水线举例如下:
图 1.2. ARM7三级流水线示例
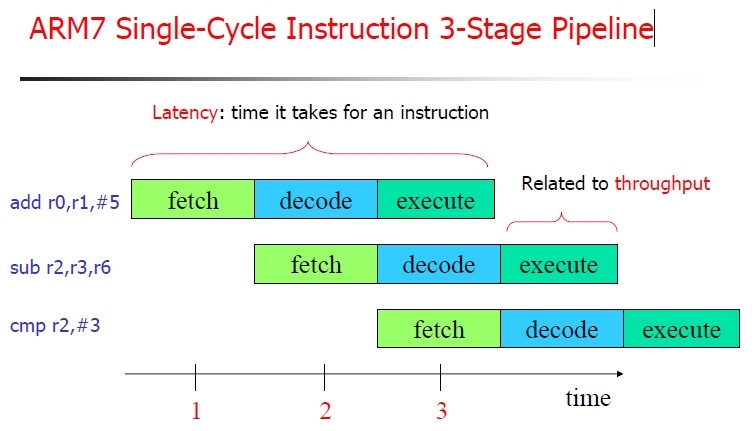 |
从上图,其实很容易看出,第一条指令:
add r0, r1,$5
执行的时候,此时PC已经指向第三条指令:
cmp r2,#3
的地址了,所以,是PC=PC+8.
2.1 ARM9流水线
ARM9系列处理器的流水线分为取指、译码、执行、访存、回写。取指部件完成从指令存储器取指;译码部件读取寄存器操作数,与三级流水线中不占有数据路径 区别很大;执行部件产生ALU运算结果或产生存储器地址(对于存储器访问指令来讲);访存部件访问数据存储器;回写部件完成执行结果写回寄存器。把三级流 水线中的执行单元进一步细化,减少了在每个时钟周期内必须完成的工作量,进而允许使用较高的时钟频率,且具有分开的指令和数据存储器,减少了冲突的发生, 每条指令的平均周期数明显减少。
2.2. 为何ARM9和ARM7一样,也是PC=PC+8
ARM7的三条流水线,PC=PC+8,很好理解,但是AMR9中,是五级流水线,为何还是PC=PC+8,而不是
PC
=PC+(5-1)*4
=PC + 16,
呢?
下面就需要好好解释一番了。
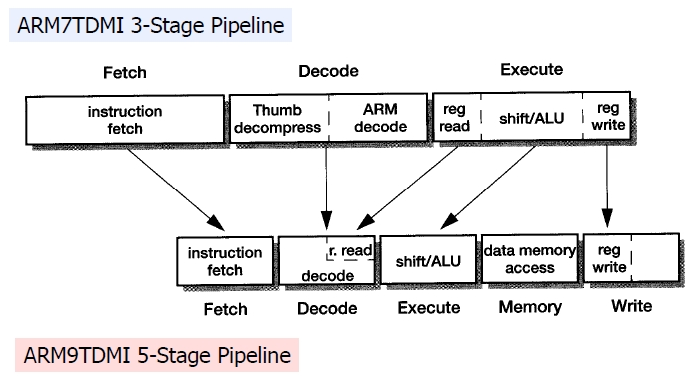 |
下面开始对为何ARM9也是PC=PC+8进行解释。
先列出ARM9的五级流水线的示例:
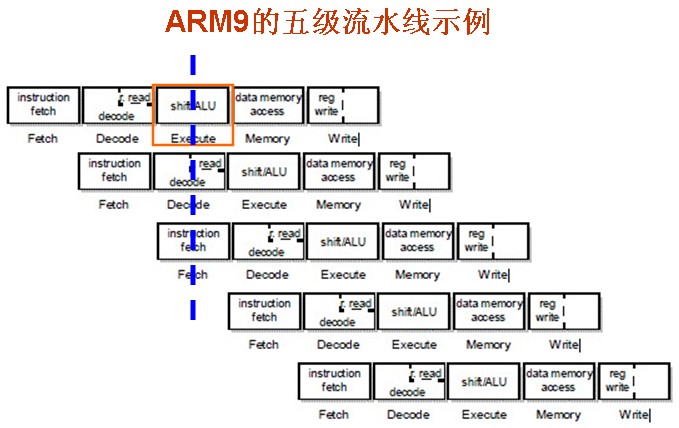
举例分析为何PC=PC+8
然后我们以下面uboot中的start.S的最开始的汇编代码为例来进行解释:
00000000 <_start>:
0: ea000014 b 58 <reset>
4: e59ff014 ldr pc, [pc, #20] ; 20 <_undefined_instruction>
8: e59ff014 ldr pc, [pc, #20] ; 24 <_software_interrupt>
c: e59ff014 ldr pc, [pc, #20] ; 28 <_prefetch_abort>
10: e59ff014 ldr pc, [pc, #20] ; 2c <_data_abort>
14: e59ff014 ldr pc, [pc, #20] ; 30 <_not_used>
18: e59ff014 ldr pc, [pc, #20] ; 34 <_irq>
1c: e59ff014 ldr pc, [pc, #20] ; 38 <_fiq>
00000020 <_undefined_instruction>:
20: 00000120 .word 0x00000120
下面对每一个指令周期,CPU做了哪些事情,分别详细进行阐述:
在看下面具体解释之前,有一句话要牢记,那就是:
PC不是指向你正在运行的指令,而是
PC始终指向你要取的指令的地址
认识清楚了这个前提,后面的举例讲解,就容易懂了。
- 指令周期Cycle1
- 取指
PC总是指向将要读取的指令的地址(即我们常说的,指向下一条指令的地址),而当前PC=4,
所以去取物理地址为4对对应的指令
ldr pc, [pc, #20]
其对应二进制代码为e59ff014。
此处取指完之后,自动更新PC的值,即PC=PC+4(单个指令占4字节,所以加4)=4+4=8
- 取指
- 指令周期Cycle2
- 译指
翻译指令e59ff014
- 同时再去取指
PC总是指向将要读取的指令的地址(即我们常说的,指向下一条指令的地址),而当前PC=8,
所以去物理地址为8所对应的指令“ldr pc, [pc, #20]” 其对应二进制代码为e59ff014。
此处取指完之后,自动更新PC的值,即PC=PC+4=8+4=12=0xc
- 译指
- 指令周期Cycle3
- 执行(指令)
执行“e59ff014”,即
ldr pc, [pc, #20]
所对表达的含义,即PC
= PC + 20
= 12 + 20
= 32
= 0x20
此处,只是计算出待会要赋值给PC的值是0x20,这个0x20还只是放在执行单元中内部的缓冲中。
- 译指
翻译e59ff014
- 取指
此步骤由于是和上面(1)中的执行同步做的,所以,未受到影响,继续取指,而取指的那一时刻,PC为上一Cycle更新后的值,即PC=0xc,所以是去取物理地址为0xc所对应的指令
ldr pc, [pc, #20]
对应二进制为e59ff014
- 执行(指令)
其实,分析到这里,大家就可以看出:
在Cycle3的时候,PC的值,刚好已经在Cycle1和Cycle2,分别加了4,所以Cycle3的时候,PC=PC+8,而同样道理,对于任何一条指令的,都是在Cycle3,指令的Execute执行阶段,如果用到PC的值,那么PC那一时刻,就是PC=PC+8。
所以,此处虽然是五级流水线,但是却不是PC=PC+16,而是PC=PC+8。
进一步地,我们发现,其实PC=PC+N的N,是和指令的执行阶段所处于流水线的深度有关,即此处指令的执行Execute阶段,是五级流水线中的第三个,而这个第三阶段的Execute和指令的第一个阶段的Fetch取指,相差的值是 3 -1 =2,即两个CPU的Cycle,而每个Cycle都会导致PC=+PC+4,所以,指令到了Execute阶段,才会发现,此时PC已经变成PC=PC+8了。
回过头来反观ARM7的三级流水线,也是同样的道理,指令的Execute执行阶段,是处于指令的第三个阶段,同理,在指令计算数据的时候,如果用到PC,就会发现此时PC=PC+8。
同理,假如ARM9的五级流水线,把指令的Execute执行阶段,设计在了第四个阶段,那么就是PC=PC+(第4阶段-1)*4个字节 = PC= PC+12了。
所以,经过两个cycle的增4,就到了指令执行的时候,此时PC已经增加了8了,即使你指令执行的时候,没有用到PC的值,其也还是已经加了8了。而一般来说,大多数的指令,肯定也都是没有用到PC的,但是其实任何指令执行的那一时刻,也已经是PC=PC+8,而多数指令没有用到,所以很多人没有注意到这点罢了。
![[提示]](http://www.crifan.com/files/res/docbook/images/tip.png) | PC(execute)=PC(fetch)+ 8 |
|---|---|
| 对于PC=PC+8中的两个PC,其实含义不完全一样.其更准确的表达,应该是这样: PC(execute)=PC(fetch)+ 8 其中: PC(fetch):当前正在执行的指令,就是之前取该指令时候的PC的值 PC(execute):当前指令执行的计算中,如果用到PC,则此时PC的值。 |
| 不同阶段的PC值的关系 |
|---|---|
| 对应地,在ARM7的三级流水线(取指,译指,执行)和ARM9的五级流水线(取指,译指,执行,存储,写回)中,可以这么说: PC, 总是指向当前正在被取指的指令的地址, PC-4,总是指向当前正在被译指的指令的地址, PC-8,总是指向当前的那条指令,即我们一般说的,正在被执行的指令的地址。 |
【总结】
ARM7的三级流水线,PC=PC+8,
ARM9的五级流水线,也是PC=PC+8,
根本的原因是,两者的流水线设计中,指令的Execute执行阶段,都是处于流水线的第三级。
3.1. 流水线的缺点
流水线系统最大限度地利用了CPU资源,使每个部件在每个时钟周期都工作,大大提高了效率。但是,流水线有两个非常大的问题:相关和转移。
在一个流水线系统中,如果第二条指令需要用到第一条指令的结果,这种情况叫做相关。以上面哪个5级流水线为例,当第二条指令需要取操作数时,第一条指令 的运算还没有完成,如果这时第二条指令就去取操作数,就会得到错误的结果。所以,这时整条流水线不得不停顿下来,等待第一条指令的完成。这是很讨厌的问 题,特别是对于比较长的流水线,比如20级,这种停顿通常要损失十几个时钟周期。目前解决这个问题的方法是乱序执行。乱序执行的原理是在两条相关指令中插 入不相关的指令,使整条流水线顺畅。比如上面的例子中,开始执行第一条指令后直接开始执行第三条指令(假设第三条指令不相关),然后才开始执行第二条指 令,这样当第二条指令需要取操作数时第一条指令刚好完成,而且第三条指令也快要完成了,整条流水线不会停顿。当然,流水线的阻塞现象还是不能完全避免的, 尤其是当相关指令非常多的时候。
另一个大问题是条件转移。在上面的例子中,如果第一条指令是一个条件转移指令,那么系统就会不清楚下面应该执 行那一条指令?这时就必须等第一条指令的判断结果出来才能执行第二条指令。条件转移所造成的流水线停顿甚至比相关还要严重的多。所以,现在采用分支预测技 术来处理转移问题。虽然我们的程序中充满着分支,而且哪一条分支都是有可能的,但大多数情况下总是选择某一分支。比如一个循环的末尾是一个分支,除了最后 一次我们需要跳出循环外,其他的时候我们总是选择继续循环这条分支。根据这些原理,分支预测技术可以在没有得到结果之前预测下一条指令是什么,并执行它。 现在的分支预测技术能够达到90%以上的正确率,但是,一旦预测错误,CPU仍然不得不清理整条流水线并回到分支点。这将损失大量的时钟周期。所以,进一 步提高分支预测的准确率也是正在研究的一个课题。 越是长的流水线,相关和转移两大问题也越严重,所以,流水线并不是越长越好,超标量也不是越多越好,找到一个速度与效率的平衡点才是最重要的。
| 3.2关于直接改变PC的值,会导致流水线清空的解释 |
|---|
| 把PC的值直接赋值为0x20。而PC值更改,直接导致流水线的清空,即导致下一个cycle中的,对应的流水线中的其他几个步骤,包括接下来的同一个Cycle中的取指的工作被取消。在PC跳转到0x20的位置之后,流水线重新计算,重新一步步地按照流水线的逻辑,去一点点执行。当然要保证当前指令的执行完成,即执行之后,还有两个cycle,分别做的Memory和Write,会继续执行完成。 |















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









