







文章目录
一、机器准备
准备三台虚拟机master、slave1、slave2,内存4G,磁盘空间40G。
关闭防火墙,配置固定ip,使其相互ping通。
配置

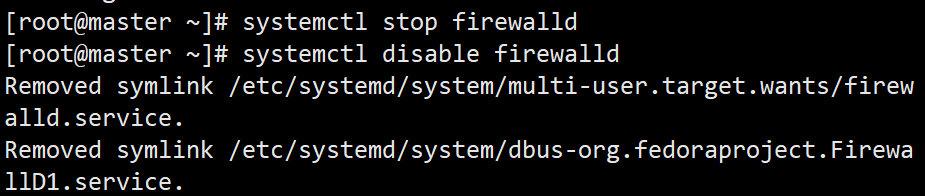
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
配置ip

ip分配
master:192.168.188.200
slave1:192.168.188.201
slave2:192.168.188.202
映射
vi /etc/hosts

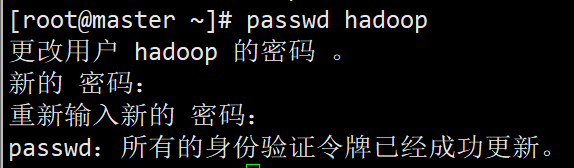
新建hadoop用户



二、安装JDK
安装步骤
检查JAVA是否安装
java -version

解压压缩包
tar -zxvf jdk-8u181-linux-x64_oracle.tar.gz

移至安装目录
mv jdk1.8.0_181/ /usr/local/

设置环境变量
编辑profile,这个是所有用户登录都会运行的文件
vim /etc/profile
在文件末尾加上环境变量语句
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH

重新运行profile
source /etc/profile
检查PATH
echo $PATH

检查Java
java -version

shell脚本
vi install_jdk.sh
chmod +x install_jdk.sh
source install_jdk.sh
#!/bin/bash
(java -version 1> /dev/null 2> /dev/null);
if test $? -eq 0
then
echo 'java已经安装了';
java -version;
else
echo '请输入jdk安装包的绝对地址(默认/root/jdk-8u181-linux-x64_oracle.tar.gz)'
read java_tar;
if test -z $java_tar
then
java_tar=/root/jdk-8u181-linux-x64_oracle.tar.gz;
fi
if [[ ! -f "$java_tar" ]]
then echo "文件不存在";
fi
echo '解压jdk压缩包'
tar zxvf $java_tar;
java_dir=$(dirname $java_tar);
echo '将jdk移至安装目录'
(mv "${java_dir}/jdk1.8.0_181" /usr/local);
echo '设置环境变量';
export JAVA_HOME=/usr/local/jdk1.8.0_181;
export JRE_HOME=${JAVA_HOME}/jre;
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib;
export PATH=${JAVA_HOME}/bin:$PATH;
echo 'export JAVA_HOME=/usr/local/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH'>> /etc/profile;
echo "检查PATH:${PATH}";
echo "检查java:";
java -version;
fi
三、安装zookeeper
安装过程
解压缩
tar -zxvf apache-zookeeper-3.6.2-bin.tar.gz

移至安装目录
mv apache-zookeeper-3.6.2-bin /usr/local/zookeeper
新建数据存储目录
mkdir -p /home/hadoop/data/zookeeper/zkdata
mkdir -p /home/hadoop/data/zookeeper/zkdatalog
更改目录权限
chown -R hadoop:hadoop /usr/local/zookeeper
chown -R hadoop:hadoop /home/hadoop
修改配置文件
配置zoo.cfg zoo.cfg是zoo_sample.cfg复制来的
这里zoo.cfg是生效文件,zoo_sample.cfg是模板文件
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
将12行修改,改变数据存放目录

修改后
dataDir=/home/hadoop/data/zookeeper/zkdata
dataLogDir=/home/hadoop/data/zookeeper/zkdatalog

在最后一行加入语句
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
设置环境变量
vim /etc/profile
在文件末尾加上环境变量语句
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH
重新运行profile
source /etc/profile
检查PATH
echo $PATH

配置zk开机自启动
创建zk的服务描述文件,使其可以被systemd识别
vim /usr/lib/systemd/system/zookeeper.service

输入内容
[Unit]
Description=Zookeeper
After=network.target
[Service]
Type=forking
User=hadoop
Group=hadoop
Environment=ZOO_LOG_DIR=/usr/local/zookeeper/apache-zookeeper-3.6.2-bin/bin
Environment=JAVA_HOME=/usr/local/java/jdk1.8.0_181
WorkingDirectory=/usr/local/zookeeper/apache-zookeeper-3.6.2-bin/bin
ExecStart=/usr/local/zookeeper/apache-zookeeper-3.6.2-bin/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/apache-zookeeper-3.6.2-bin/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/apache-zookeeper-3.6.2-bin/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target

启动服务管理程序
systemctl daemon-reload

将zookeeper设为自启动
systemctl enable zookeeper

检查zk是否成功设置自启动
systemctl is-enabled zookeeper

使用systemctl启动zk服务
systemctl start zookeeper

jps

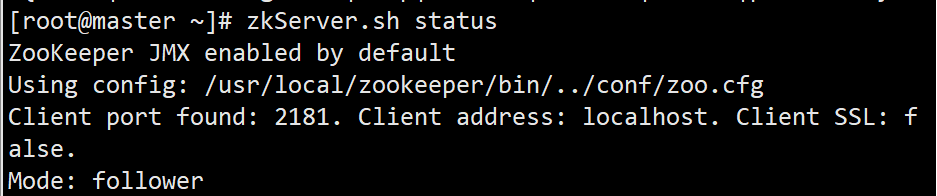
检查服务状态
systemctl status zookeeper.service -l

启动zookeeper
注意zookeeper需要所有在配置文件中写入的节点都开启时才启动,所有我们需要同时开启所有节点,如果某一结点等待了6秒仍没有等到所有节点同时开启会自动关闭。
systemctl start zookeeper
shell脚本
zkServer.sh status 1> /dev/null 2> /dev/null;
if test $? -ne 127
then
echo 'zookeeper已经安装了';
zkServer.sh status;
else
echo '请输入zookeeper安装包的绝对地址(默认/root/apache-zookeeper-3.6.2-bin.tar.gz)'
read zk_tar;
if test -z $zk_tar
then
zk_tar=/root/apache-zookeeper-3.6.2-bin.tar.gz;
fi
if [[ ! -f "$zk_tar" ]]
then echo "文件不存在";
fi
echo '解压zookeeper压缩包'
tar zxvf $zk_tar;
zk_dir=$(dirname $zk_tar);
echo '将zookeeper移至安装目录';
(mv "${zk_dir}/apache-zookeeper-3.6.2-bin" /usr/local/zookeeper);
echo '新建数据存储目录';
mkdir -p /home/hadoop/data/zookeeper/zkdata;
mkdir -p /home/hadoop/data/zookeeper/zkdatalog;
echo '更改目录权限';
chown -R hadoop:hadoop /usr/local/zookeeper
chown -R hadoop:hadoop /home/hadoop
echo '修改配置';
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg;
sed -i "s#dataDir=.*#dataDir=/home/hadoop/data/zookeeper/zkdata\ndataLogDir=/home/hadoop/data/zookeeper/zkdatalog#g" /usr/local/zookeeper/conf/zoo.cfg;
echo 'server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888'>>/usr/local/zookeeper/conf/zoo.cfg;
echo '请输入本机的zookeeper_id';
read zk_id;
echo $zk_id> /home/hadoop/data/zookeeper/zkdata/myid;
echo '设置环境变量';
export ZOOKEEPER_HOME=/usr/local/zookeeper;
export PATH=${ZOOKEEPER_HOME}/bin:$PATH;
echo 'export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=${ZOOKEEPER_HOME}/bin:$PATH'>>/etc/profile;
echo '检查PATH';
echo $PATH;
echo '设置zookeeper自启动'
echo '[Unit]
Description=Zookeeper
After=network.target
[Service]
Type=forking
User=hadoop
Group=hadoop
Environment=ZOO_LOG_DIR=/usr/local/zookeeper/bin
Environment=JAVA_HOME=/usr/local/jdk1.8.0_181
WorkingDirectory=/usr/local/zookeeper/bin
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target'>/usr/lib/systemd/system/zookeeper.service;
systemctl daemon-reload
systemctl enable zookeeper
echo '请使用systemctl start zookeeper启动zookeeper,所有节点六秒内同时启动即可';
fi
四、配置免密登录
基本步骤
令master,slave1,slave2,分别生成密钥对,取所有公钥存储在master中,这样所有的节点就可以免密登录master了,接着将master的公钥存储文件复制给slave1和slave2,至此完成配置。
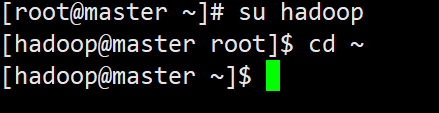
切换用户
因为我们配置免密登录的目的是给hadoop集群使用,而hadoop软件使用的用户是hadoop用户所以我们应该配置hadoop用户的免密登录,而不是root用户。
su hadoop
cd ~
生成密钥对
master:
ssh-keygen -t rsa

slave1:同理

slave2:同理

使master获取所有子节点公钥
获取slave1的公钥
scp hadoop@slave1:/home/hadoop/.ssh/id_rsa.pub ./id_rsa.pub.slave1

获取slave2的公钥
scp hadoop@slave2:/home/hadoop/.ssh/id_rsa.pub ./id_rsa.pub.slave2

至此我们有了所有节点的公钥

写入公钥
将master公钥写入:
cat ./.ssh/id_rsa.pub >> ./.ssh/authorized_keys
其中>>是追加重定向,将cat得到的内容追加到authorized_keys中,这个文件是新建的,主要名字不要拼错不然无法生效。
将slave1,slave2公钥写入:
cat ./id_rsa.pub.slave1 >> ./.ssh/authorized_keys
cat ./id_rsa.pub.slave2 >> ./.ssh/authorized_keys
查看写入是否成功
cat ./.ssh/authorized_keys
可以看到三行加密字符串,以ssh-rsa开头,以hadoop@主机名结尾(主要查看这是是否为hadoop,这里如果是root说明之前没有切换用户)

更改authorized_keys权限
chmod 700 ./.ssh/authorized_keys
令slave1、slave2获取master储存文件
slave1:
scp hadoop@master:/home/hadoop/.ssh/authorized_keys ./.ssh/

slave2:

shell脚本
#请在master下运行,使用root运行
echo '令个节点生成密钥对'
su - hadoop -c 'ssh-keygen -t rsa';
ssh -t hadoop@slave1 'ssh-keygen -t rsa';
ssh -t hadoop@slave2 'ssh-keygen -t rsa';
echo '生成公钥储存文件';
su - hadoop -c 'cat /home/hadoop/.ssh/id_rsa.pub>> /home/hadoop/.ssh/authorized_keys';
ssh hadoop@slave1 'cat /home/hadoop/.ssh/id_rsa.pub'>>/home/hadoop/.ssh/authorized_keys;
ssh hadoop@slave2 'cat /home/hadoop/.ssh/id_rsa.pub'>>/home/hadoop/.ssh/authorized_keys;
echo '更改储存文件权限';
chmod 700 /home/hadoop/.ssh/authorized_keys;
echo '将公钥储存文件分发';
scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/authorized_keys;
scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/authorized_keys;
同理root也可以做免密,方便之后操作
echo '令个节点生成密钥对'
ssh-keygen -t rsa;
ssh -t root@slave1 'ssh-keygen -t rsa';
ssh -t root@slave2 'ssh-keygen -t rsa';
echo '生成公钥储存文件';
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys;
ssh root@slave1 'cat ~/.ssh/id_rsa.pub'>>~/.ssh/authorized_keys;
ssh root@slave2 'cat ~/.ssh/id_rsa.pub'>>~/.ssh/authorized_keys;
echo '更改储存文件权限';
chmod 700 ~/.ssh/authorized_keys;
echo '将公钥储存文件分发';
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/authorized_keys;
scp ~/.ssh/authorized_keys root@slave2:~/.ssh/authorized_keys;
五、配置Hadoop
这里使用的hadoop-3.3.0.tar.gz

是二进制包,不需要编译,解压即可。
解压hadoop
tar -zxvf hadoop-3.3.0.tar.gz -C /usr/local

重命名hadoop根目录
mv /usr/local/hadoop-3.3.0/ /usr/local/hadoop

修改配置文件
.bashrc
主节点修改环境变量。
export JAVA_HOME=/usr/local/jdk1.8.0_181
export HADOOP_HOME=/usr/local/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
使之生效
source .bachrc
检查hadoop
hadoop version
子节点操作如上。
core-site.xml
vi /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- 设置主节点 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 设置data存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
hdfs-site.xml
vi /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定NameNode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!-- 指定DataNode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web 访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
</configuration>
yarn-site.xml
vi /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- 指定shuffle方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.addtess</name>
<value>master:8088</value>
</property>
</configuration>
mapred-site.xml
vi /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<!-- 指定MapReduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
workers
vi /usr/local/hadoop/etc/hadoop/workers
slave1
slave2
打包配置好的hadoop
tar -zcvf hadoop.tar.gz hadoop/
子节点获取hadoop并解压
scp root@master:/usr/local/hadoop.tar.gz ./hadoop.tar.gz
tar -zxvf hadoop.tar.gz -C /usr/local/
初始化master的namenode
su hadoop -c 'hadoop namenode -format'
启动hadoop
su hadoop -c 'start-all.sh'
检查是否启动
jps
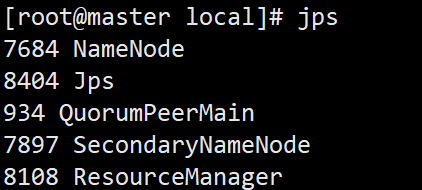
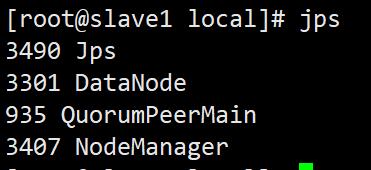
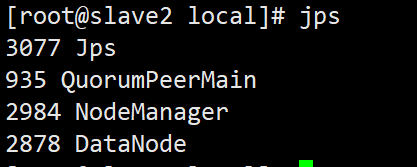
shell脚本
echo '请输入hadoop安装包的绝对地址(默认/root/hadoop-3.3.0.tar.gz)'
read hadoop_tar;
if test -z $hadoop_tar
then
hadoop_tar=/root/hadoop-3.3.0.tar.gz;
fi
if [[ ! -f "$hadoop_tar" ]]
then echo "文件不存在";
return;
fi
echo '解压hadoop压缩包'
tar zxvf $hadoop_tar;
hadoop_dir=$(dirname $hadoop_tar);
echo '将hadoop移至安装目录';
(mv "${hadoop_dir}/hadoop-3.3.0" /usr/local/hadoop);
echo '更改目录权限';
chown -R hadoop:hadoop /usr/local/hadoop
echo '修改环境变量'
echo 'export JAVA_HOME=/usr/local/jdk1.8.0_181
export HADOOP_HOME=/usr/local/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH'>>/home/hadoop/.bashrc
echo '修改配置';
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 设置主节点 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 设置data存放路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>'>/usr/local/hadoop/etc/hadoop/core-site.xml;
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定NameNode数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!-- 指定DataNode数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web 访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9868</value>
</property>
</configuration>'>/usr/local/hadoop/etc/hadoop/hdfs-site.xml;
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定shuffle方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.addtess</name>
<value>master:8088</value>
</property>
</configuration>'>/usr/local/hadoop/etc/hadoop/yarn-site.xml;
echo '<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>'>/usr/local/hadoop/etc/hadoop/mapred-site.xml;
echo 'slave1
slave2'>/usr/local/hadoop/etc/hadoop/workers
echo '向子节点传输'
scp -r /usr/local/hadoop root@slave1:/usr/local/hadoop
scp -r /usr/local/hadoop root@slave2:/usr/local/hadoop
scp /home/hadoop/.bashrc root@slave1:/home/hadoop/.bashrc
scp /home/hadoop/.bashrc root@slave2:/home/hadoop/.bashrc
echo '更改目录权限'
ssh root@slave1 "chown -R hadoop:hadoop /usr/local/hadoop"
ssh root@slave2 "chown -R hadoop:hadoop /usr/local/hadoop"
echo '初始化namenode'
su hadoop -c '/usr/local/hadoop/bin/hadoop namenode -format'
echo '启动hadoop'
su hadoop -c '/usr/local/hadoop/sbin/start-all.sh'















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









