






 本文深入解析KubeProxy的四种运行模式:userspace、iptables、ipvs及kernelspace,探讨其工作原理、性能特点及适用场景,为Kubernetes集群网络流量管理和优化提供全面指导。
本文深入解析KubeProxy的四种运行模式:userspace、iptables、ipvs及kernelspace,探讨其工作原理、性能特点及适用场景,为Kubernetes集群网络流量管理和优化提供全面指导。
引言
Kube Proxy 是 Kubernetes 生态的核心组件之一,主要负责处理访问 Service 的流量(包括通过 Cluster IP 以及 Node Port),自动将 Client 对 Kubernetes Service 的请求代理到正确的 Pod 或 Node 后端。截止 1.18 版本,Kube Proxy 能够支持的运行模式有 4 种,其平台支持情况如下表:
| Mode | Linux | Windows |
|---|---|---|
| userspace | Y | Y |
| iptables | Y | N |
| ipvs | Y | N |
| kernelspace | N | Y |
注意:userspace 模式在实现上其实细分为 Linux 的 userspace 和 Windows 平台的 winuserspace,工作原理基本一致。之所以分两套实现,笔者以为主要是 Linux 的 userspace 实现仍部分依赖了 Linux 内核的 iptables 功能,而 Windows 平台由于没有 iptables 支持,所以使用了另外的机制(将 ClusterIP 绑定到网卡) 单独实现了一番。
userspace 模式
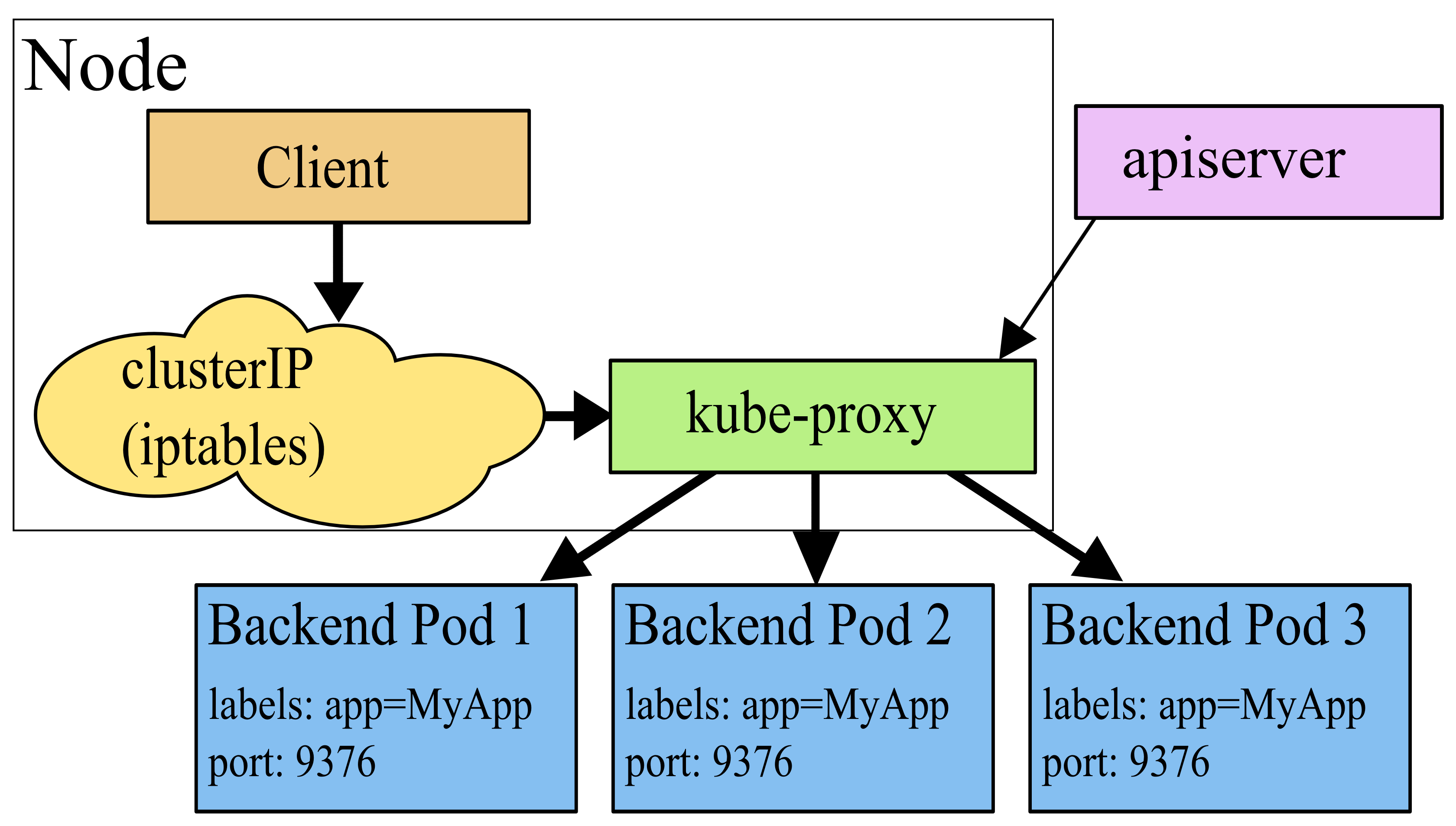
在 userspace 模式下,kube-proxy 通过监听 K8s apiserver 获取关于 Service 和 Endpoint 的变化信息,在内存中维护一份从ClusterIP:Port 到后端 Endpoints 的映射关系,通过反向代理的形式,将收到的数据包转发给后端,并将后端返回的应答报文转发给客户端。该模式下,kube-proxy 会为每个 Service (每种协议,每个 Service IP,每个 Service Port)在宿主机上创建一个 Socket 套接字(监听端口随机)用于接收和转发 client 的请求。默认条件下,kube-proxy 采用 round-robin 算法从后端 Endpoint 列表中选择一个响应请求。
[root@machine ~]# kubectl get svc --all-namespaces
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 8d
kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 8d
[root@machine ~]# netstat -apn | grep kube-proxy
tcp6 0 0 :::39748 :::* LISTEN 21092/kube-proxy
tcp6 0 0 :::46122 :::* LISTEN 21092/kube-proxy
tcp6 0 0 :::10256 :::* LISTEN 21092/kube-proxy
tcp6 0 0 :::43892 :::* LISTEN 21092/kube-proxy
正如我们看到的,kube-proxy 会根据 Service IP(包括 CLUSTER-IP 和 EXTERNAL-IP)、协议以及端口号确定一个 Socket,在宿主机上打开一个监听端口。客户端访问 Service 的流量会被分别路由到对应的 Socket 监听端口得到处理。Service 到 Socket 的重定向路由,在 Linux 平台采用 iptables 实现(在 Windows 平台通过将 Service ClusterIP 绑定到网卡实现)。
Linux iptables 根据目的 Service 定向到指定的 Socket 监听端口的规则示意:
[root@machine ~]# iptables -t nat -S
-A KUBE-PORTALS-CONTAINER -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https" -m tcp --dport 443 -j REDIRECT --to-ports 46122
-A KUBE-PORTALS-HOST -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https" -m tcp --dport 443 -j DNAT --to-destination 192.168.137.139:46122
userspace 模式工作原理示意:
iptables 模式
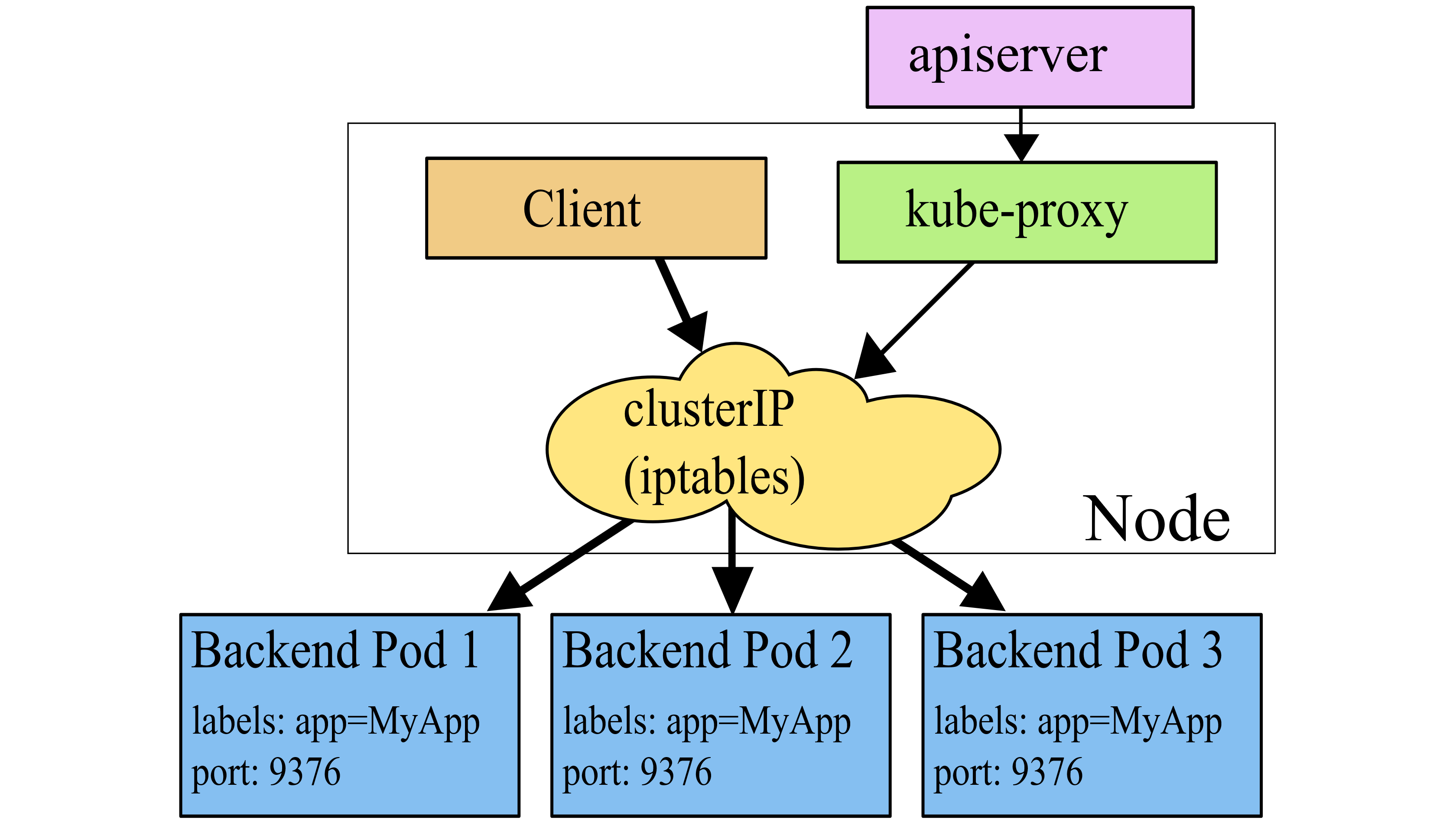
在 iptables 模式下,kube-proxy 依然需要通过监听 K8s apiserver 获取关于 Service 和 Endpoint 的变化信息。不过与 userspace 模式不同的是,kube-proxy 不再为每个 Service 创建反向代理(也就是无需创建 Socket 监听),而是通过安装 iptables 规则,捕获访问 Service ClusterIP:Port 的流量,直接重定向到指定的 Endpoints 后端。默认条件下,kube-proxy 会 随机 从后端 Endpoint 列表中选择一个响应请求。ipatbles 模式与 userspace 模式的不同之处在于,数据包的转发不再通过 kube-proxy 在用户空间通过反向代理来做,而是基于 iptables/netfilter 在内核空间直接转发,避免了数据的来回拷贝,因此在性能上具有很大优势,而且也避免了大量宿主机端口被占用的问题。
但是将数据转发完全交给 iptables 来做也有个缺点,就是一旦选择的后端没有响应,连接就会直接失败了,而不会像 userspace 模式那样,反向代理可以支持自动重新选择后端重试,算是失去了一定的重试灵活性。不过,官方建议使用 Readiness 探针来解决这个问题,一旦检测到后端故障,就自动将其移出 Endpoint 列表,避免请求被代理到存在问题的后端。
[root@machine ~]# iptables -t nat -S
-A KUBE-SEP-XVJ25MO2MX75T34R -s 192.168.137.139/32 -j KUBE-MARK-MASQ
-A KUBE-SEP-XVJ25MO2MX75T34R -p tcp -m tcp -j DNAT --to-destination 192.168.137.139:6443
-A KUBE-SERVICES -d 10.96.0.1/32 -p tcp -m comment --comment "default/kubernetes:https cluster IP" -m tcp --dport 443 -j KUBE-SVC-NPX46M4PTMTKRN6Y
-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS
-A KUBE-SVC-NPX46M4PTMTKRN6Y -j KUBE-SEP-XVJ25MO2MX75T34R
正如上面 iptables 规则列出的,访问 10.96.0.1 443 端口的流量会被交由 KUBE-SVC-NPX46M4PTMTKRN6Y 处理,KUBE-SVC-NPX46M4PTMTKRN6Y 继而跳转到 KUBE-SEP-XVJ25MO2MX75T34R,最终 DNAT 到目的 Node 的 6443 端口,这正是 kubernetes apiserver 的监听地址。因此,iptables 模式下,完全通过 iptables 自身就实现了流量转发,不需要为每个 Service 打开 Socket 监听端口了。注意,这里最上边那条是 DNAT 的配对策略,DNAT 的回包需要做 UN-DNAT(即 SNAT/MASQ)。
iptables 模式工作原理示意:
ipvs 模式
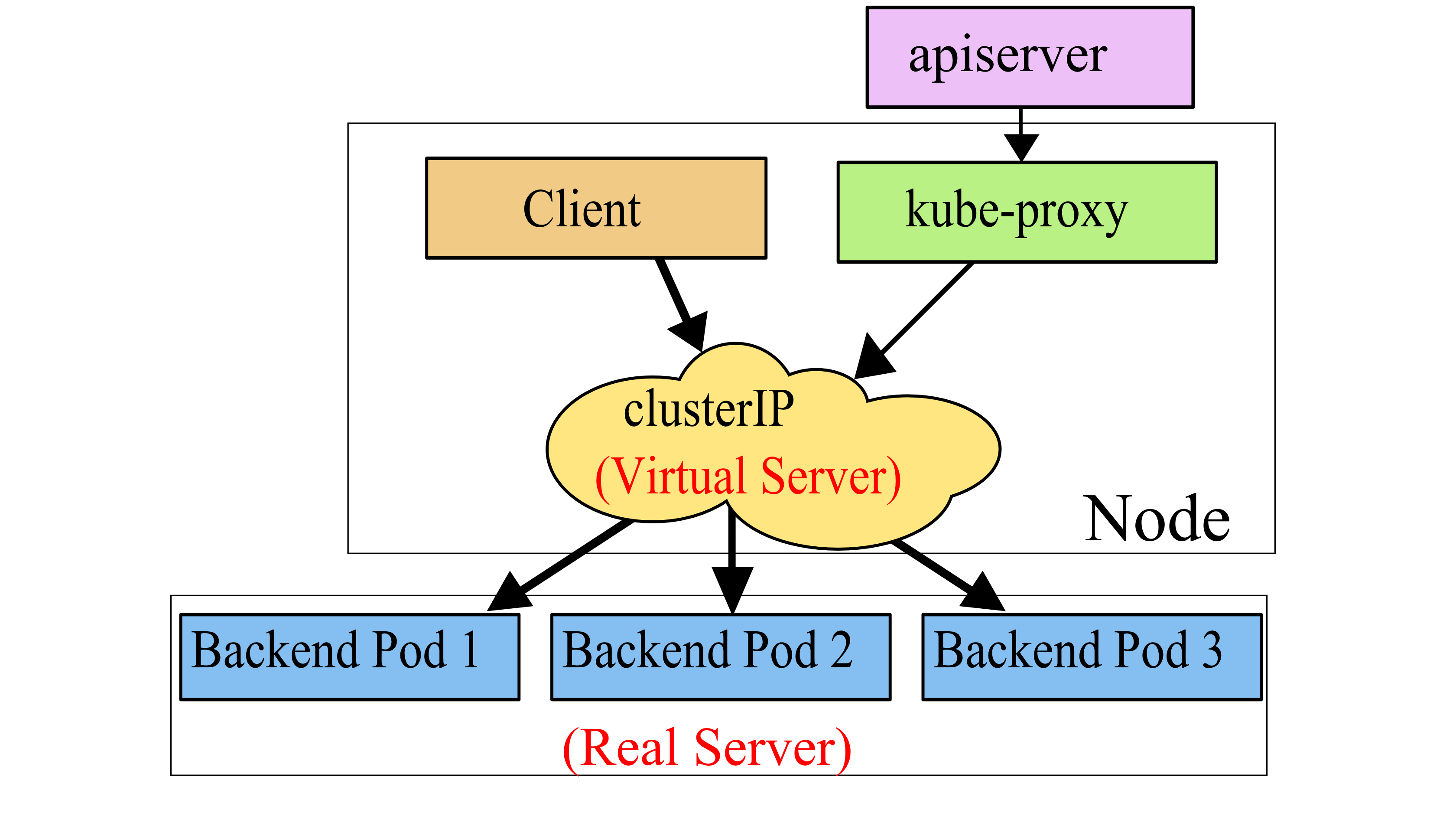
在 ipvs 模式下,kube-proxy 通过监听 K8s apiserver 获取关于 Service 和 Endpoint 的变化信息,然后调用 netlink 接口创建 ipvs 规则,并周期性地同步 Kubernetes Service/Endpoint 与 ipvs 规则,保证状态匹配。当客户端请求 Service 时,ipvs 会将流量重定向到指定的后端。
ipvs 相比 iptables 的优势在于通过 hash table 实现了 O(1) 时间复杂度的规则匹配。当 Service 和 Endpoint 的数量急剧增加时,iptables 的匹配表项会变得十分庞大,而其采用的顺序匹配模式会严重影响其性能。相反,ipvs 无论在小规模集群还是大规模集群,都拥有几乎相同的性能表现,因此相比其他代理模式,能提供更高的网络吞吐量,更能满足大规模集群扩展性和高性能的需要。同时,ipvs 支持对后端的健康检查和连接重试,可靠性相比 iptables 更佳。此外,ipvs 模式还为用户提供了多种负载均衡策略以供选择,例如:
- rr: round-robin (轮询,
默认采用) - lc: least connection (最少连接数)
- dh: destination hashing (根据目的哈希)
- sh: source hashing (根据源哈希)
- sed: shortest expected delay (最小延迟)
- nq: never queue (不排队等待,有空闲 Server 直接分配给空闲 Server 处理,否则通过 sed 策略处理)
ipvs 仍然使用 iptables 实现对数据包的过滤、SNAT 或 MASQ,但使用 ipset 来存储需要执行 MASQ 或 DROP 的源地址和目的地址,从而保证在大量 Service 存在的情况下,iptables 表项数量仍能维持在常数级。
通过 ipvsadm、ipset 工具可以查看 Service ClisterIP:Port 到后端 Pod/Node 映射关系。
[root@machine ~]# iptables -t nat -S
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
-A KUBE-SERVICES -m set --match-set KUBE-CLUSTER-IP dst,dst -j ACCEPT
[root@machine ~]# ip addr show dev kube-ipvs0
68: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether fe:04:6f:5a:01:3e brd ff:ff:ff:ff:ff:ff
inet 10.96.0.10/32 brd 10.96.0.10 scope global kube-ipvs0
valid_lft forever preferred_lft forever
inet 10.96.0.1/32 brd 10.96.0.1 scope global kube-ipvs0
valid_lft forever preferred_lft forever
[root@machine ~]# ipset list
Name: KUBE-CLUSTER-IP
Type: hash:ip,port
Revision: 2
Header: family inet hashsize 1024 maxelem 65536
Size in memory: 16656
References: 2
Members:
10.96.0.10,tcp:53
10.96.0.10,tcp:9153
10.96.0.10,udp:53
10.96.0.1,tcp:443
[root@machine ~]# ipvsadm -ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.96.0.1:443 rr
-> 192.168.137.139:6443 Masq 1 1 0
TCP 10.96.0.10:53 rr
-> 10.80.1.233:53 Masq 1 0 0
TCP 10.96.0.10:9153 rr
-> 10.80.1.233:9153 Masq 1 0 0
UDP 10.96.0.10:53 rr
-> 10.80.1.233:53 Masq 1 0 0
如上所示的,首先系统通过 iptables 允许访问 KUBE-CLUSTER-IP ipset 的流量进入,并通过在虚拟网卡 kube-ipvs0 上配置 VIP 的方式,告诉内核识别 VIP 为本机 IP,从而走 iptables 的 INPUT 链,继而通过 IP Virtual Server 找到 Real Server 提供服务。
注意:由于 KUBE-CLUSTER-IP 的类型为 hash:ip,port,在 --match-set KUBE-CLUSTER-IP dst,dst 匹配规则中,第一个 dst 表示将 set 中的 IP 作为目的地址,第二个 dst 表示将 set 中的 Port 作为目的端口。
ipvs 模式工作原理示意:
kernelspace 模式
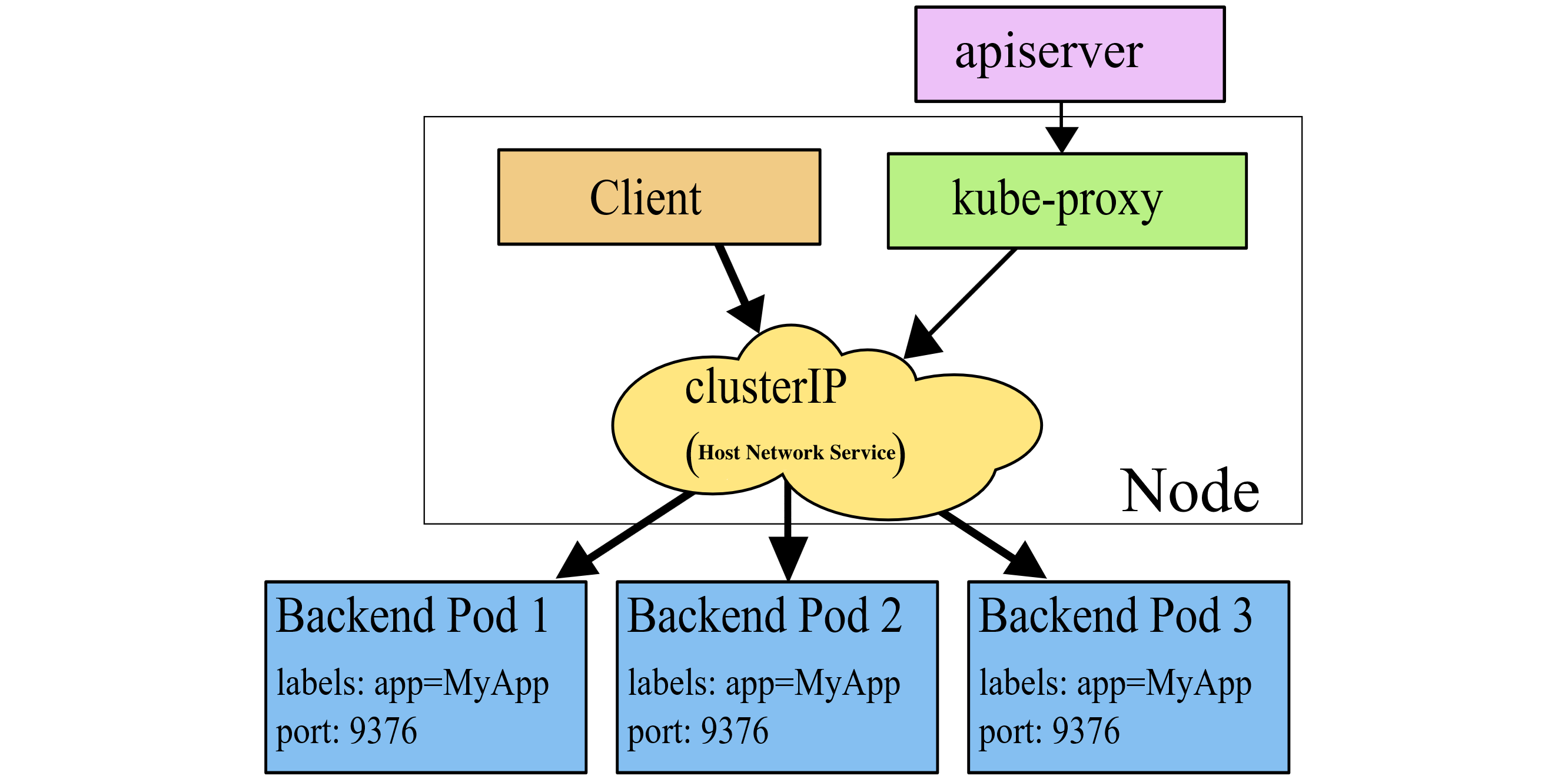
kernelspace 也可以说是 winkernel 模式,因为它只应用于 Windows 平台。在 winkernel 模式下,kube-proxy 通过监听 K8s apiserver 获取关于 Service 和 Endpoint 的变化信息,然后通过 HNS (Host Network Service) 接口直接配置 Windows 内核的 LoadBalancer 以及 Endpoint ,实现基于 winkernel 的 Kubernetes Service 代理服务。
winkernel 模式相对 winuserspace 模式的改进与 iptables 模式相对 userspace 模式的改进类似,即避免了主动创建大量的 Socket 监听,也免去了频繁且低效的用户态-内核态数据拷贝,直接通过配置系统的 LoadBalancer 和 Endpoint 实现代理,性能上具有明显优势。
winkernel 模式工作原理示意:
附加:设置会话保持
在以上几种模式中,客户端对 Service ClusterIP:Port 的访问都被透明代理到合适的后端,客户端不会感知到 Kubernetes、Service 或是 Pod。默认条件下,代理后端认为每次请求都是独立的,会分别按照策略选择后端进行响应。如果你希望来自同一个客户端的请求每次都被同一个后端响应(即会话保持),可以通过设置 Kubernetes Service 的 service.spec.sessionAffinity 字段为 “ClientIP”,保证同一 Client 对 Service 的请求被定向转发到同一 Endpoint(其内部其实是通过一个 Map 结构记录了 Client 与 Endpoint 的对应关系)。同时,你还可以通过设置 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 字段定义会话保持的最长时间,默认是 3 小时。

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









