






前言:
1.本文为个人开发笔记,其他阅读者需熟悉JAVA且对HTML有基本的认识
2.为什么我选择火狐?因为chrome需要下载对应版本的驱动我用的浏览器版本比较新,一直没找到匹配的驱动,所以选择了火狐。火狐就到官网下载一个最新版的就行(我是这样)。
准备:
1.火狐下载地址(建议安装在默认地址,emm只是建议)
2.以下地址三选一
github驱动下载地址(往下面滚动一下,下载对应OS版本,我是win64)
百度网盘驱动下载地址 (提取码:syk6)
阿里云盘驱动下载地址
3.JDK1.8/JDK 11
配置:
将下载好的geckodriver.exe放到谷歌浏览器的安装目录。(github上下载需要解压)
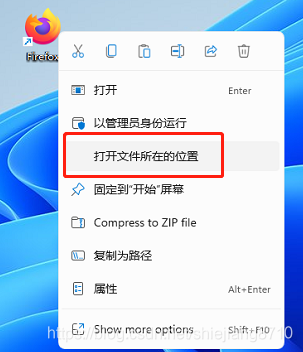
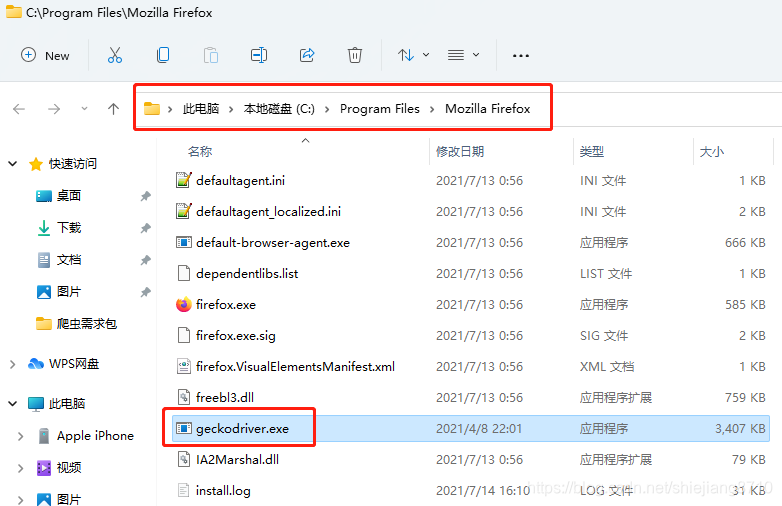
开搞:
1.新建MAVEN项目或springboot项目
(不会的童鞋请自行百度,现在应该没有人用eclipse了吧.。吧。。 )
(我新建的是springboot项目我还有其它需求,其实MAVEN项目就可以了)
2.打开pom.xml,引入selenium
<!-- https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java -->
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
引入了之后如果是红色的还报错可以Reload一下,让maven 自己再下载一下。
3.代码
先看下下面GIF动图,如何获取xpath和css选择器。打开百度网站按F12,检查代码。
我相信大部分同学应该都是知道的。
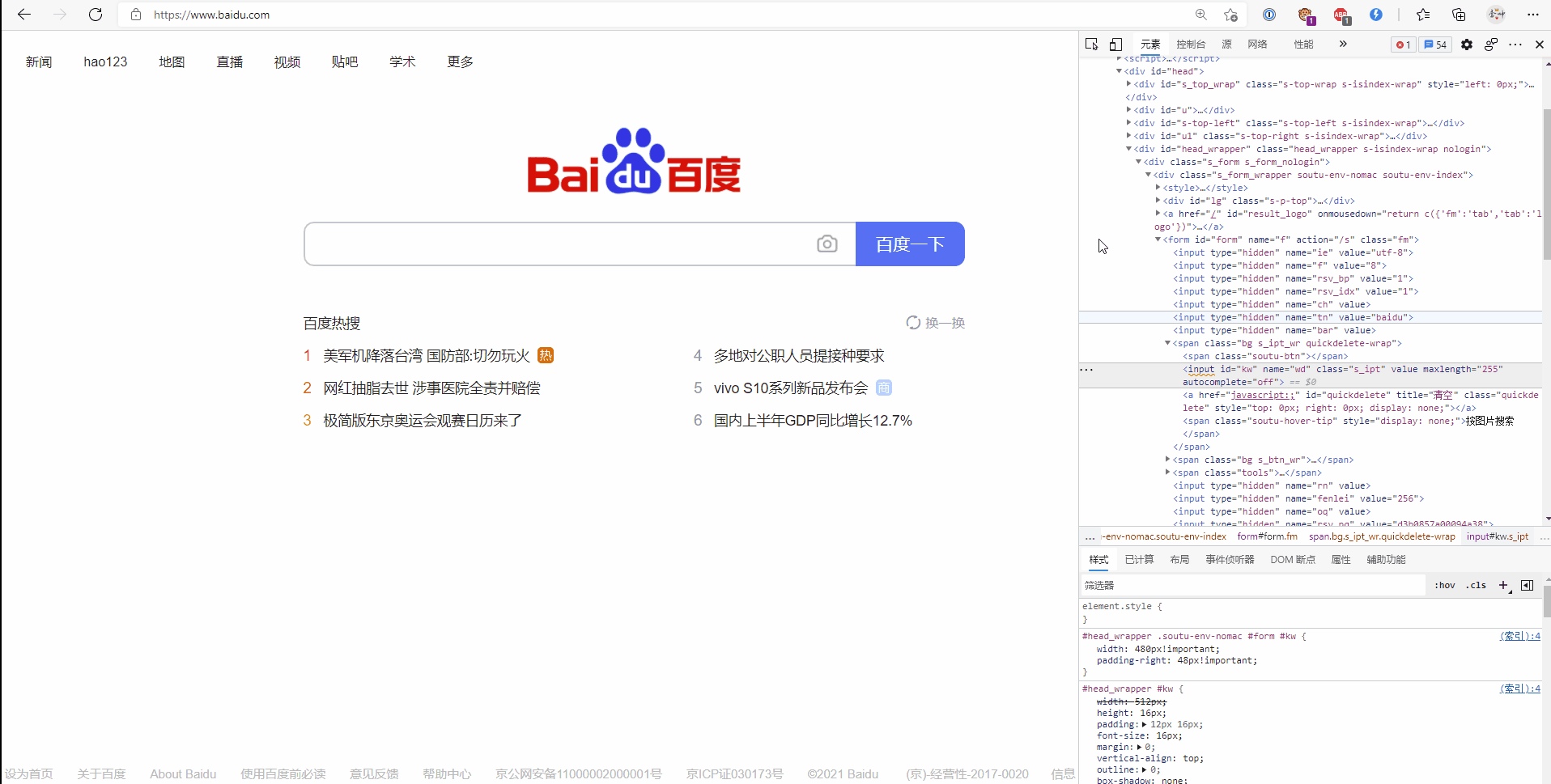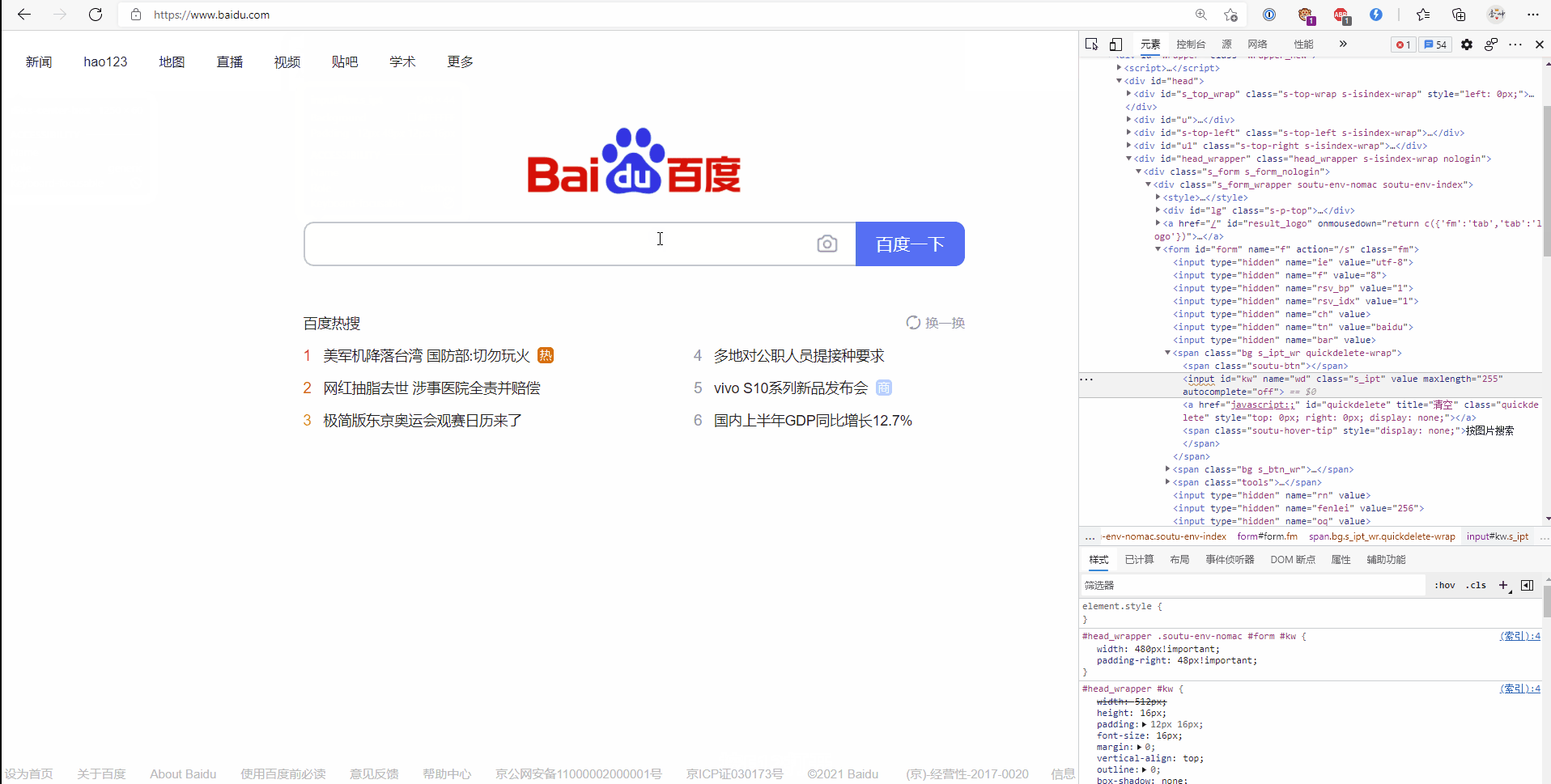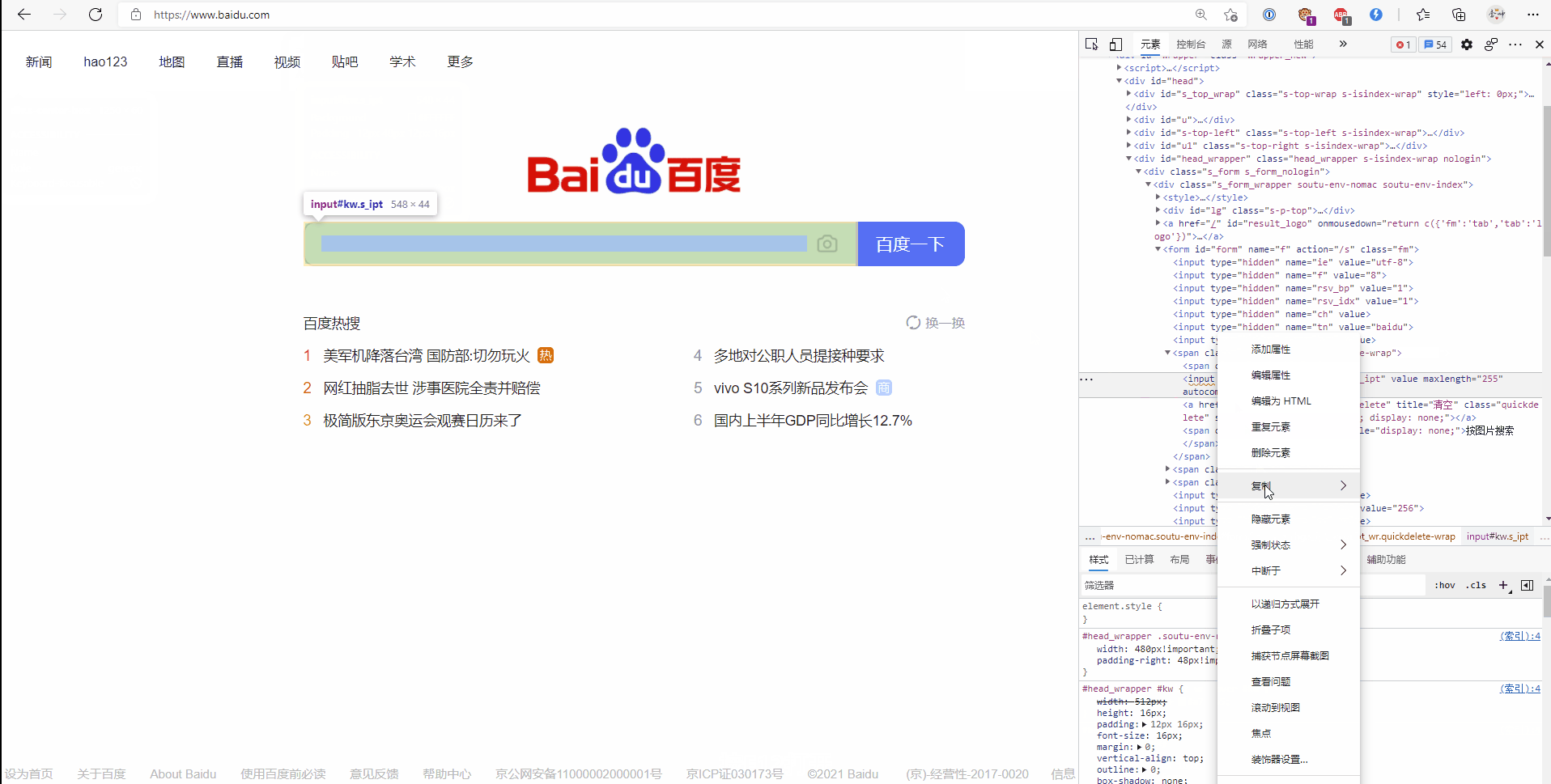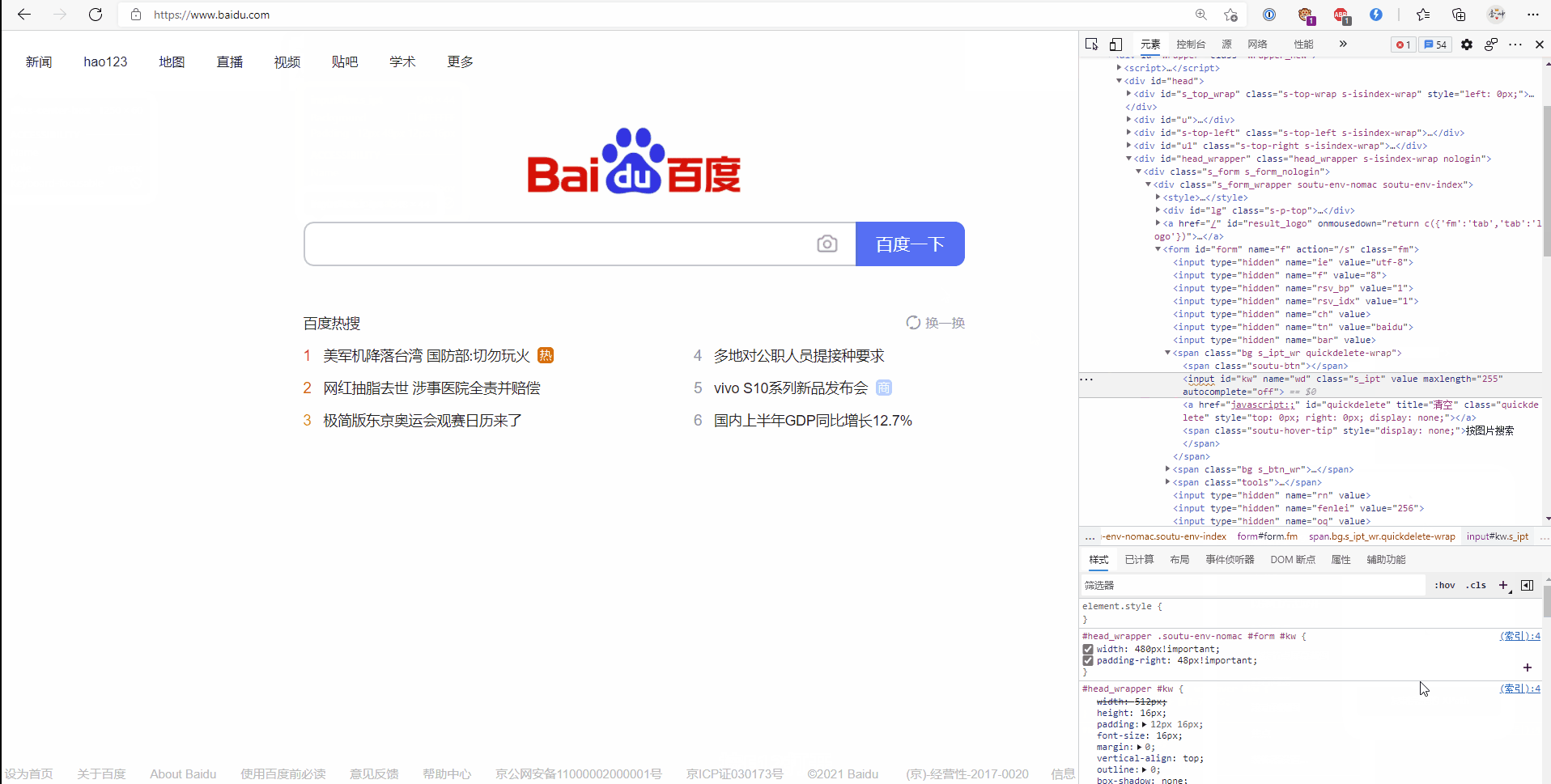
直接上代码
import org.openqa.selenium.*;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.firefox.FirefoxOptions;
import org.openqa.selenium.html5.LocalStorage;
import org.openqa.selenium.html5.WebStorage;
import org.openqa.selenium.remote.Augmenter;
import java.util.Set;
import java.util.concurrent.TimeUnit;
/**
* @ClassName: TestRequest
* @author: LiShuai
* @create: 2021-07-12 15:14
**/
public class TestSelenium {
/**
* 访问的目标地址
*/
private static final String URL = "https://www.baidu.com/";
public static void test() throws InterruptedException {
// 没有安装在默认目录的童鞋需要加上这个,第二个参数是你的firefox.exe路径
// System.setProperty("webdriver.firefox.bin", "D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
// 第二个参数请换成自己的驱动文件路径
System.setProperty("webdriver.gecko.driver","C:\\Program Files\\Mozilla Firefox\\geckodriver.exe");
// 可配置参数,此处设置为隐藏浏览器窗口,静默模式
// 建议先不设置这个先感受下自动化过程
// FirefoxOptions options = new FirefoxOptions();
// options.addArguments("-headless");
//定义驱动对象为 driver 对象,若设置了option传入即可
WebDriver driver = new FirefoxDriver();
// WebDriver driver = new FirefoxDriver(options);
//这个设置的意思是防止代码运行太快页面,找不到页面的元素。
//因为selenium只是模拟人工操作,代码并不知页面是否在加载转圈中
//此处设置的是当找不到元素时等待3秒,若网站速度很快是感受不到等待的哈
driver.manage().timeouts().implicitlyWait(3, TimeUnit.SECONDS);
// 打开目标网站,这里以百度为例。
// 写到这里其实可以暂停运行一下了哈,看看有没有打开网站。应该感到非常开心
driver.get(URL);
// 浏览器窗口最大化,如果是静默模式就没有必要了哈
driver.manage().window().maximize();
// 下面的才是关键
// 开始查找元素,我习惯用xpath,也推荐用xpath,
// 有的同学可能觉得xpath有点浪费纸(代码长),这个大可不必担心,我们写的是代码不浪费你纸的哈
// By.cssSelector(""); 这个是css选择器,有的人喜欢用这个。还有其它的自己可以尝试
WebElement searchInput = driver.findElement(By.xpath("//*[@id=\"kw\"]"));
// 向输入框中发送文本 “python爬虫”
searchInput.sendKeys("python爬虫");
// clear是清空输入框
// searchInput.clear();
// 模拟键盘按键,此处为模拟回车键,这样就直接搜索了
// searchInput.sendKeys(Keys.ENTER);
// 找到"百度一下" 按钮
WebElement blueButton = driver.findElement(By.xpath("/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]"));
// 模拟点击,触发点击事件。
blueButton.click();
// 可以合理的利用延时
// Thread.sleep(1000);
// 打印当前页面,到此已经结束啦
System.out.println("当前页面url:" + driver.getCurrentUrl());
// 如下是获取cookies的方法,一般老一点的网站会用cookie
// Set<Cookie> cookies = driver.manage().getCookies();
// 现在很多网站都是vue,react等单页面应用。有些验证信息会存储在localstorage或sessionStorage中
// 可以通过如下方法获取到
// WebStorage webStorage = (WebStorage) new Augmenter().augment(driver);
// webStorage.getSessionStorage(); // sessionStorage
// LocalStorage localStorage = webStorage.getLocalStorage(); // localstorage
// System.out.println("获取到的token:");
// System.out.println(localStorage.getItem("token"));
// 当我们获取到了cookie或token等验证信息的时候
// 其实通过Http发起post或get请求。很多时候不需要一个元素一个元素的抓取了。基本上就可以为所欲为了,哈哈哈
// 非单页应用跳转页面可以使用以下两个方法,具体可以百度以下,我暂时用不到。
// driver.getWindowHandles();
// driver.switchTo();
// 关闭驱动
// driver.close();
}
public static void main(String[] args) throws InterruptedException {
test();
}
}
注释掉的代码可以自己尝试下哈。废话可能有点多,还请耐心看代码。
下一章将记录利用webCollect + selenium爬虫,selenium中的一些技巧。更新了此处将会变成链接。

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









