







注意的点:
select * :查询全部的列,并不建议写。由于后续的更新数据库表中的列并不是一成不变的 → 建议制定查询的列名
insert into j22_user_t (id,username,password,age,gender) values (?,?,?,?,?):当你的数据库的列增加或减少之后,执行会发生问题。建议制定插入数据的列,降低程序的耦合性。
表名不要只写一个user,容易和数据库中的关键字混淆。
多表映射(查询)
一对一、一对多、多对多查询
javabean构造关系
数据库表构造关系
多表映射要做的事情就是:查询结果的封装
一对一:User UserDetail
一对多:User Order
多对多:Student Course → 双向的一对多
- 一对一
a. javabean之间关系

b. 数据库表之间关系
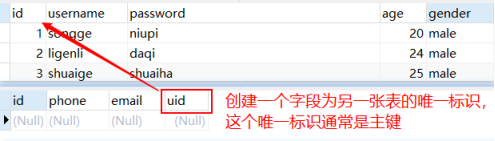
- 一对多
a. javabean之间关系

b. 数据库表之间关系
在“多”的表中创建“一”表的唯一标识(通常主键)

多对多
本质上就是双向的一对多 → 互为一对多
a. javabean之间关系

b. 数据库表之间关系
通过中间表维护

一对一查询
- 分次查询


如果查询多条记录:

查询的记录数可以是0、1、或多个。

- 连接查询(通常使用左连接)
左连接能够保证左表信息的查询,保证左表的javabean的查询结果的封装
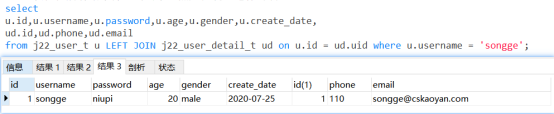
也就是说,保证满足条件的左表,即user信息都可以查询出来。


小结
一对一:
联系:都使用association标签 → 都使用了property属性
区别:
分次查询:column和select属性
连接查询:javaType属性
一对多查询
javabean之间关系

数据库表之间关系
在“多”的表中创建“一”表的唯一标识(通常主键)

- 分次查询


- 连接查询


多对多查询
本质上就是双向的一对多 → 互为一对多
javabean之间关系
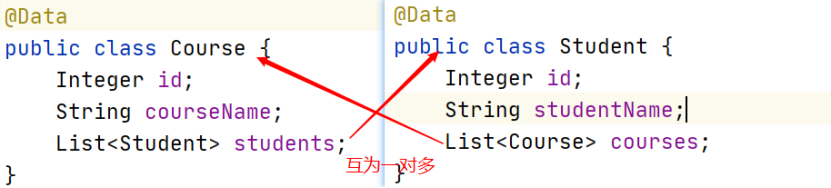
数据库表之间关系

- 分次查询

a. student对course的一对多

b. course对student的一对多

- 连接查询

a. student对course的一对多

b. course对student的一对多

选择
可以选择分次查询
也可以选择连接查询
也可以在service层中做遍历来进行封装

settings(了解)
一、缓存
查询:执行完某个查询 → 执行相同的查询 → 使用之前查询过的结果
- 一级缓存(默认开启)
sqlSession级别
a. 同一个sqlSession生成的同一个Mapper执行相同查询

b. 同一个Session生成的不同mapper

c. 一级缓存何时失效?
sqlSession 执行commit会失效


- 二级缓存(需要条件)
namespace级别 → 就需要保证使用同一个接口下的方法
需要的三个条件:
1、settings 中配置 cacheEnabled=true(当然,不配置的话默认也是true)
2、javabean需要序列化,即implements Serializable
3、映射文件中需要增加<cache/>标签

使用:

也就是说执行sqlSession.commit()的时候,清空了一级缓存,但是把这些内容放到了二级缓存中。
二、懒加载
单例 → 讲过懒加载
在mybatis中,懒加载用于多表映射中。
比如:user和userDetail、user和orders
懒加载针对的是分次查询: 当要去获得右一或右多的时候才去执行第二次查询
懒加载默认没有开启 → 如何开启懒加载 → settings lazyLoadingEnabled=true
 开启lazyLoadingEnabled = true后,分次查询就已经是懒加载了。
开启lazyLoadingEnabled = true后,分次查询就已经是懒加载了。

想要立即加载:association或collection标签中,增加fetchType=“eager”

注意:执行对象打印时会使用到toString方法,如果你对toString重写了,就会获取第二次查询的对象
debug时也会使用到toString


作业: 练习多表查询
创建球队(BallArmy)和球员(Player)的一对多查询
创建user和userdetail的一对一查询
分次和连接查询分别实现
只列出 dao的查询接口和 对应的mapper映射即可。
见Homework14















 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











