







//联系人:石虎 QQ: 1224614774昵称:嗡嘛呢叭咪哄

什么是HTML
- HTML其实是HyperText Markup Language的缩写, 超文本标记语言
HTML的作用
- 1.首先利用记事本保存了一个标题和两段描述, 然后修改纯文本文件的扩展名为.html, 然后再利用浏览器打开
郑伊健
郑伊健,1967年10月4日出生于中国香港,籍贯广东恩平,香港影视演员、流行男歌手。1988年参加新秀歌唱大赛加入无线电视,因拍摄“阳光柠檬茶”广告而入行,拜罗文为师。[1]
1991年加盟BMG唱片公司以歌手身份出道。1995年开始,凭借在《古惑仔》系列电影中饰演陈浩南一角走红。1996年凭借《古惑仔》主题曲《友情岁月》获得十大中文金曲奖。1996年至1997年连续两次获得”台湾十大偶像”奖。-
2.打开之后发现显示的格式不对, 不对的原因是因为在纯文本文件中所有文字都是同级别的, 浏览器不知道哪些文字代表什么意思. 也就是浏览器不知道哪些文字是标题, 哪些文字是段落...., 所以导致了显示的格式不正确
-
正是因为如此, 所以HTML应用而生. HTML就只有一个作用,
它是专门用来描述文本的语义的. 也就是说我们可以利用HTML来告诉浏览器哪些是标题, 哪些是段落.- 这些用于描述其它文本语义的文本, 我们称之为
标签. 并且这些用于描述文本语义的标签将来在浏览器中是不会被显示出来的 - 所以正是因为HTML的这些标签是专门用来描述其它文本语义的, 并且在浏览器中不会被显示出来, 所以我们称这些文本为
"超文本", 而这些文本又叫做标签, 所以HTML被称之为"超文本标记语言"
- 这些用于描述其它文本语义的文本, 我们称之为

<h1>郑伊健</h1>
<p>郑伊健,1967年10月4日出生于中国香港,籍贯广东恩平,香港影视演员、流行男歌手。1988年参加新秀歌唱大赛加入无线电视,因拍摄“阳光柠檬茶”广告而入行,拜罗文为师。[1] </p>
<p>1991年加盟BMG唱片公司以歌手身份出道。1995年开始,凭借在《古惑仔》系列电影中饰演陈浩南一角走红。1996年凭借《古惑仔》主题曲《友情岁月》获得十大中文金曲奖。1996年至1997年连续两次获得”台湾十大偶像”奖。</p>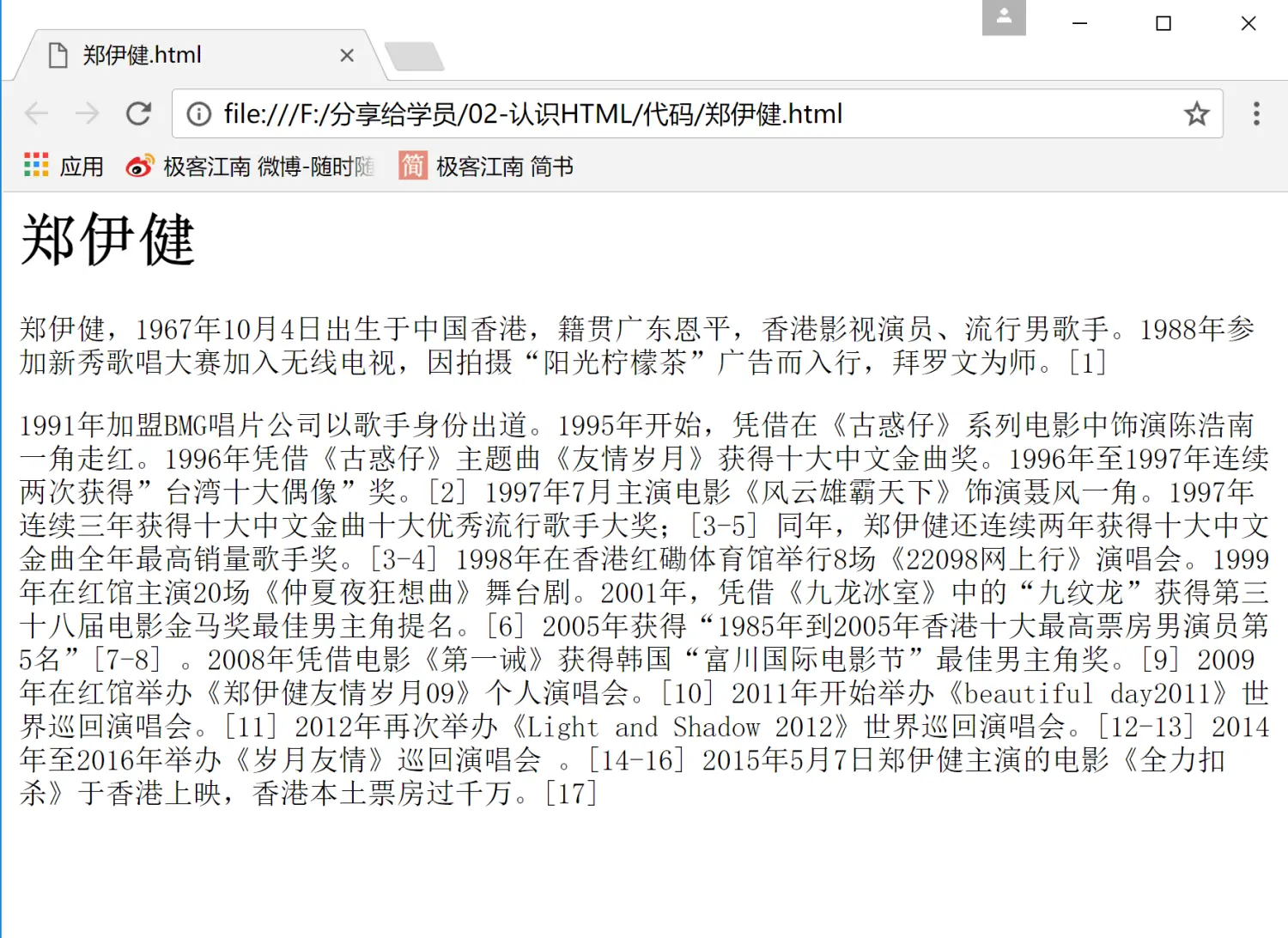
-
注意事项:
- 虽然我们利用H1标签描述一段文本之后, 这段文本在浏览器中显示出来会被放大和加粗, 看上去我们是利用HTML的标签修改了被描述的那段文本的样式. 但是一定要记住,
HTML只有一个作用, 它是专门用来给文本添加语义的, 而不是用来修改文本的样式的
- 虽然我们利用H1标签描述一段文本之后, 这段文本在浏览器中显示出来会被放大和加粗, 看上去我们是利用HTML的标签修改了被描述的那段文本的样式. 但是一定要记住,
-
H1标签它的作用是什么?
- 错误: H1标签可以用来修改文字的大小, 并且还可以将文字加粗
- 正确: H1标签的作用是用来告诉浏览器, 哪些文字是标题. 也就是H1标签是专门用于给指定的文字
添加标题语义的
HTML发展史

IETF简介
- IETF是英文Internet Engineering Task Force的缩写, 翻译过来就是"互联网工程任务组"
- IETF负责定义并管理因特网技术的所有方面。包括用于数据传输的IP协议、让域名与IP地址匹配的域名系统(DNS)、用于发送邮件的简单邮件传输协议(SMTP)等
W3C简介
-
W3C是英文World Wide Web Consortium的缩写, 翻译过来就是W3C理事会或万维网联盟, W3C是全球互联网最具权威的技术标准化组织.
-
W3C于1994年10月在麻省理工学院计算机科学实验室成立。创建者是万维网的发明者Tim Berners-Lee
-
W3C负责web方面标准的制定,像HTML、XHTML、CSS、XML的标准就是由W3C来定制的。

Tim Berners-Lee(蒂姆·伯纳斯-李),万维网之父、html设计者、w3c创始人
百度百科
网页的固定格式
-
1.编写网页和写信一样都有一套规范和要求, 这套规范和要求中规定了写信的固定格式
-
2.写信基本结构
敬爱的江哥:
您好!
正文正文正文正文正文正文正文正文正文正文正文正文
正文正文正文正文正文正文正文正文正文正文正文正文
此致
敬礼!
你的朋友 伊健
2066年6月6日-
3.编写网页的步骤:
3.1.新建一个文本文档
3.2.利用记事本打开
3.3.编写THML代码
3.4.保存并且修改纯文本文档的扩展名为.html
3.5.利用浏览器打开编写好的文件 -
4.网页基本结构:
<html> <head> <title></title> </head> <body> </body> </html> -
5.通过观察我们发现, HTML基本结构中所有的标签都是成对出现的, 这些成对出现的标签中有一个带/有一个不带/, 那么这些不带/的标签我们称之为开始标签, 这些带/的我们称之为结束标签

html标签
-
作用:
- 用于告诉浏览器这是一个网页, 也就是说告诉浏览器我是一个HTML文档
-
注意点:
- 其它所有的标签都必须写在html标签里面, 也就是写在html开始标签和结束标签中间
head标签
-
作用:
- 用于给网站添加一些配置信息
- 例如:
- 指定网站的标题 / 指定网站的小图片
- 添加网站的SEO相关的信息(指定网站的关键字/指定网站的描述信息)
- 外挂一些外部的css/js文件
- 添加一些浏览器适配相关的内容
-
注意点:
- 一般情况下, 写在head标签内部的内容都不会显示给用户查看, 也就是说一般情况下写在head标签内部的内容我们都看不到
title标签
-
作用:
- 专门用于指定网站的标题, 并且这个指定的标题将来还会作为用户保存网站的默认标题
-
注意点:
- title标签必须写在head标签里面
body标签
-
作用:
- 专门用于定义HTML文档中需要显示给用户查看的内容(文字/图片/音频/视频)
-
注意点:
- 虽然说有时候你可能将内容写到了别的地方在网页中也能看到, 但是千万不要这么干, 一定要将需要显示的内容写在body中
- 一对html标签中(一个html开始标签和一个html结束标签)只能有一对body标签
head内部标签
meta标签
-
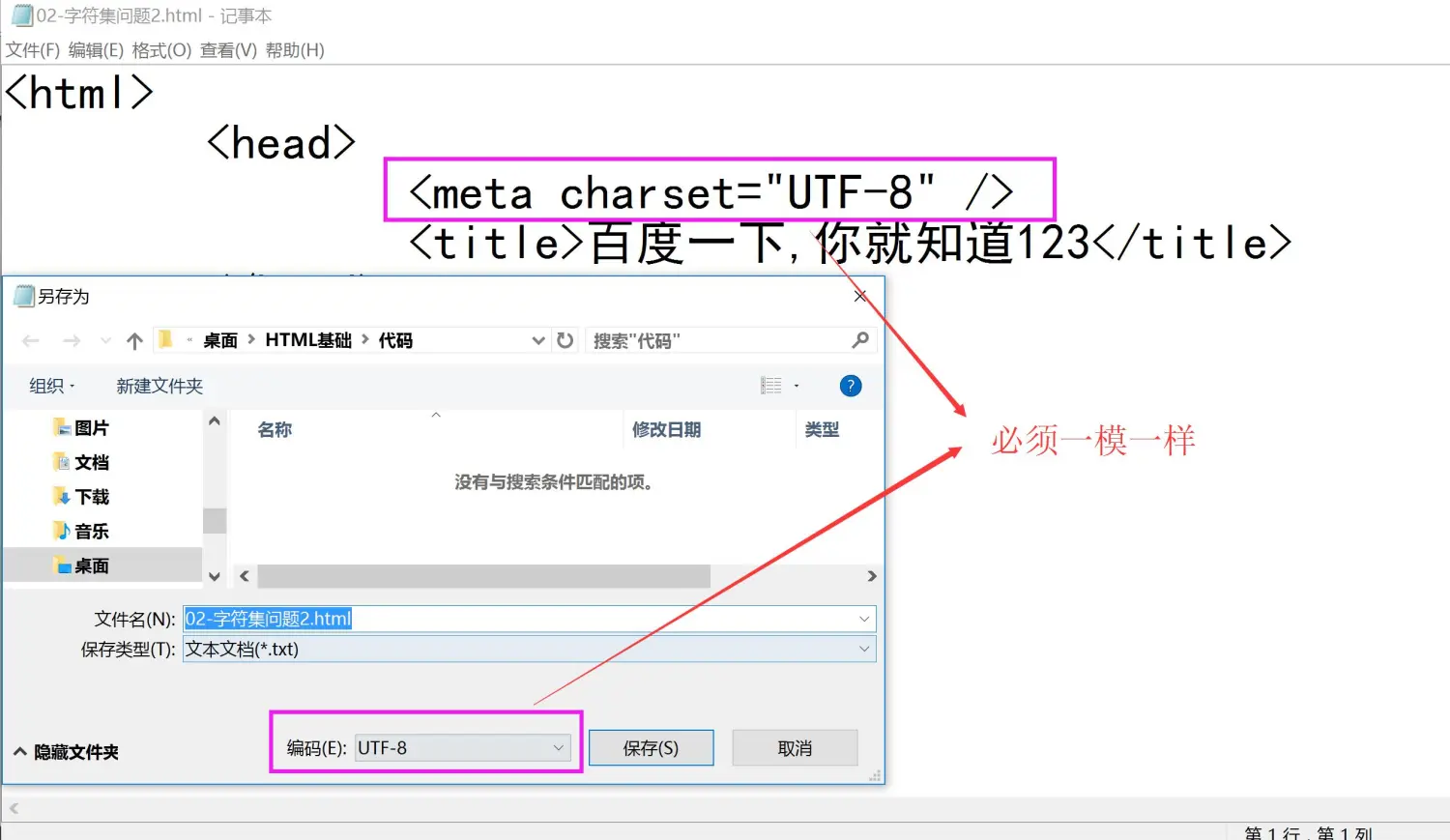
1.为什么会有乱码现象?
- 因为我们在编写网页的时候没有指定字符集

- 因为我们在编写网页的时候没有指定字符集
-
2.如何解决乱码现象?
- 在head标签中添加
<meta charset="GBK" />, 指定字符集
- 在head标签中添加
-
3.什么是字符集
- 字符集就是字符的集合, 也就是很多字符堆在一起. 其实字符集很像我们古代的"活字印刷术", 在活字印刷术中就是将很多刻有汉字的小章放到一个盒子中, 然后需要印刷文字的时候再去盒子中取这个小章出来用, 正是因为如此, 所以导致了乱码问题
- 假设北方人和南方人都拥有装满小章的盒子, 但是南方人和北方人在盒子中存储小章的顺序不太一样, 那么这个时候如果北方人和南方人都需要去取"李"字, 在南方人记忆中李字在第6个盒子的第6行的第6列中(666), 在北方人的记忆中李字在第8个盒子的第8行的第8列中(888). 那么此时如果让一个南方人去北方人的盒子中取"李"字的小章, 必然找不到,, 所以就导致了乱码问题
- 这个地方北方人的存储小章的盒子和南方人存储小章的盒子就对应网页中指定的字符集, 在网页中我们常见的字符集有两个GBK/UTF-8, GBK就对应北方人存储的盒子, UTF-8就对应南方人存储的盒子
- 所以在网页中指定字符集的意义就在于告诉浏览器我用的是哪个盒子, 你应该如何去查找才能找到对应的正确的内容

- 4.GBK(GB2312)和UTF-8区别
- GBK(GB2312)里面存储的字符比较少, 仅仅存储了汉字和一些常用外文
- 体积比较小
- UTF-8里面存储的世界上所有的文字
- 提交比较大
- GBK(GB2312)里面存储的字符比较少, 仅仅存储了汉字和一些常用外文
-
5.那么在企业开发中我们应该使用GBK(GB2312)还是UTF-8呢?
- 如果你的网站仅仅包含中文, 那么推荐使用GB2312, 因为它的体积更小, 访问速度更快
- 如果你的网站除了中文以外, 还包含了一些其它国家的语言 , 那么推荐使用UTF-8
- 懒人推荐: 不管三七二十一, 一律写UTF-8即可
-
6.注意点:
- 在HTML文件中指定的字符集必须和保存这个文件的字符集一致, 否则还是会出现乱码
- 所以仅仅指定字符集不一定能解决乱码问题, 还需要保存文件的时候, 文件的保存格式必须和指定的字符集一致才能保证没有乱码问题
HTML标签
HTML标签分类
- 单标签
- 只有开始标签没有结束标签, 也就是由一个<>组成的
<meta charset="UTF-8" />
- 只有开始标签没有结束标签, 也就是由一个<>组成的
- 双标签
- 有开始标签和结束标签, 也就是由一个<>和一个</>组成的
<html> </html>HTML标签关系分类
- 有开始标签和结束标签, 也就是由一个<>和一个</>组成的
-
并列关系(兄弟/平级)
<head> </head> <body> </body> -
嵌套关系(父子/上下级)
<head> <meta charset="UTF-8" /> <title>百度一下,你就知道123</title> </head>
DTD文档声明
-
什么是DTD文档声明?
- 由于HTML有很多个版本的规范, 每个版本的规范之间又有一定的差异. 所以为了让浏览器能够正确的编译/解析/渲染我们的网页, 我们需要在HTML文件的第一行告诉浏览器, 我们当前这个网页是
用哪一个版本的HTML规范来编写的. 浏览器只要知道了我们是用哪一个版本的规范来编写之后, 它就能够正确的编译/解析/渲染我们的网页
- 由于HTML有很多个版本的规范, 每个版本的规范之间又有一定的差异. 所以为了让浏览器能够正确的编译/解析/渲染我们的网页, 我们需要在HTML文件的第一行告诉浏览器, 我们当前这个网页是
-
DTD文档声明格式:
<!DOCTYPE html> 注意事项:<!DOCTYPE>声明必须是 HTML 文档的第一行,位于 <html> 标签之前<!DOCTYPE> 声明不是 HTML 标签<!DOCTYPE> 声明没有结束标签<!DOCTYPE> 声明对大小写不敏感- 这个声明浏览器会看, 但是并不是完全依赖于这个声明, 浏览器有一套自己的默认的处理机制
- 不写也能运行
- H5网页里面用H4也能运行
- HTML5
之前有2大种规范, 每种规范中又有3小种规范
| 大规范 | 小规范 |
|---|---|
| HTML | Strict (严格的) |
| HTML | Transitional(过度的,普通的,宽松的) |
| HTML | Frameset(带有框架的页面) |
| XHTML | Strict (严格的) |
| XHTML | Transitional(过度的,普通的,宽松的) |
| XHTML | Frameset(带有框架的页面) |
- HTML的DTD文档声明和XHTML的DTD文档声明有何区别?
- XHTML本身规定比如标签必须小写、必须严格闭合、必须使用引号引起属性等等, 而HTML会更加松散没有这么严格
-
Strict表示
严格的, 这种模式里面的要求更为严格.这种严格主要体现在有一些标签不能使用- 例如font标签/u标签等
- font标签可以修改一个文本的字号、颜色、字体,但这和HTML的本质有冲突,因为HTML只能负责语义,不能负责样式,而font标签是用于修改样式的,所以在Strict中是不能使用font标签
- u标签可以给一个文本加上下划线,但这和HTML的本质有冲突,因为HTML只能负责语义,不能负责样式,而u标签是用于添加下划线是样式.所以在Strict中是不能使用u标签
-
Transitional表示
普通的, 这种模式是没有一些别的要求- 例如可以使用font标签、u标签等
- 但是在企业开发中不会使用这些标签,因为这违背了HTML的本质, 而是将这些标签作为css的钩子使用
-
Frameset表示
框架, 在框架的页面使用- 后面学到框架/NodeJS 再做详细了解
-
常见的DOCTYPE有如下几种
HTML4.01:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
XHTML 1.0
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
HTML5:
<!DOCTYPE html>- 有这么多规范我们学习过程中到底使用哪一种比较合适呢?
- 无论是HTML还是XHTML,
过去企业级开发中用的比较多的大部分都是Transitional类型的文档声明 - 但是
HTML5的时代已经到来,以上6中规范仅仅作为了解,以后都用HTML5类型的文档声明, HTML5向下兼容(求此刻WC3心里阴影面积) - 目前国内一线网站都更新到了HTML5的文档声明, 所以后续授课也是全程使用HTML5的文档声明
- www.baidu.com (B)
- www.taobao.com (A)
- www.qq.com (T)
- www.sohu.com(大奇葩)
- 无论是HTML还是XHTML,
HTML和XHTML、HTML5区别
-
在HTML的早期发展中,大部分标准都是所谓的retro-spec,即
先有实现后有标准。在这种情况下,HTML标准不是很规范,浏览器也对HTML页面中的错误相当宽容。这反过来又导致了HTML开发者写出了大量含有错误的HTML页面 -
html语言本身有一些缺陷(例如: 内容和形式不能分离;标签单一;数据不能复用等等),随着xml的兴起人们希望xml来弥补html的不足,但是目前有成千上万的网页都是用html编写的,所以完全使用xml来替代html还为时过早,于是W3C在2000年推出了xhtml1.0,建立xhtml的目的就是实现从html向xml的过度 -
为了规范HTML,W3C结合XML制定了XHTML 1.0标准,这个标准没有增加任何新的标签,只是按照XML的要求来规范HTML,并定义了一个新的MIME type application/xhtml+xml。W3C的初衷是要求浏览器对这个MIME type实行强错误检查,如果页面有HTML错误,就要显示错误信息。但是由于已有的web页面中已经有了大量的错误,很多开发者拒绝使用新的MIME type。W3C不得已,在XHTML 1.0的标准之后增加了一个附录C,允许开发者使用XHTML语法来写页面,同时使用旧的MIME type,application/html,来分发页面 -
W3C随后
在XHTML 1.1中取消了附录C,即使用XHTML 1.1标准的页面必须用新的MIME type来分发。于是这个标准并没有很多人采用 -
有了XHTML的教训,W3C在制定下一代HTML标准时(HTML5),就将
向后兼容作为了一个很重要的原则。HTML5确实引入了许多新的特性,但是它最重要的一个特性是,不会break已有的网页。你可以将任何已有的网页的第一行改成<!DOCTYPE html>,它就成也一个HTML5页面,并且可以照样在浏览器里正常的展示。 -
简而言之
- HTML语法非常宽松容错性强;
- XHTML更为严格,它要求标签必须小写、必须严格闭合、标签中的属性必须使用引号引起等等;
- HTML5是HTML的下一个版本所以除了非常宽松容错性强以外,还增加许多新的特性
.htm 和 .html扩展名区别
- DOS操作系统(win95或win98)下只能支持
长度为3的后缀名,所以是htm - 但在windows后缀长度可以大于3位,所以windows下无所谓htm与html,html是为长文件的格式命名的
- 所以htm是为了兼容过去的DOS命名格式存在的















 3120
3120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









