



一、Rocksdb概述
文档:https://github.com/facebook/rocksdb/wiki/RocksDB-Overview
1.1、简介
RocksDB 最初由Facebook开发,作为一款用于处理各种存储介质上的服务器工作负载的存储引擎,最初专注于快速存储(尤其是闪存)。它是一个 C++ 库,用于存储任意大小的字节流形式的键和值。它支持点查找和范围扫描,并提供不同类型的 ACID 保证。
RocksDB 在可定制性和自适应性之间取得了平衡。RocksDB 具有高度灵活的配置设置,可以调整以在各种生产环境中运行,包括 SSD、硬盘、ramfs 或远程存储。它支持各种压缩算法,并提供了用于生产支持和调试的优秀工具。
RocksDB 借鉴了开源leveldb项目的重要代码以及Apache HBase的理念。其初始代码是从开源 leveldb 1.5 中分叉而来的。
1.2、高层架构
RocksDB 是一个键值存储接口的存储引擎库,其中键和值是任意字节流。RocksDB 按排序顺序组织所有数据,常用操作包括Get(key)、NewIterator()、Put(key, val)、Delete(key)和SingleDelete(key)。
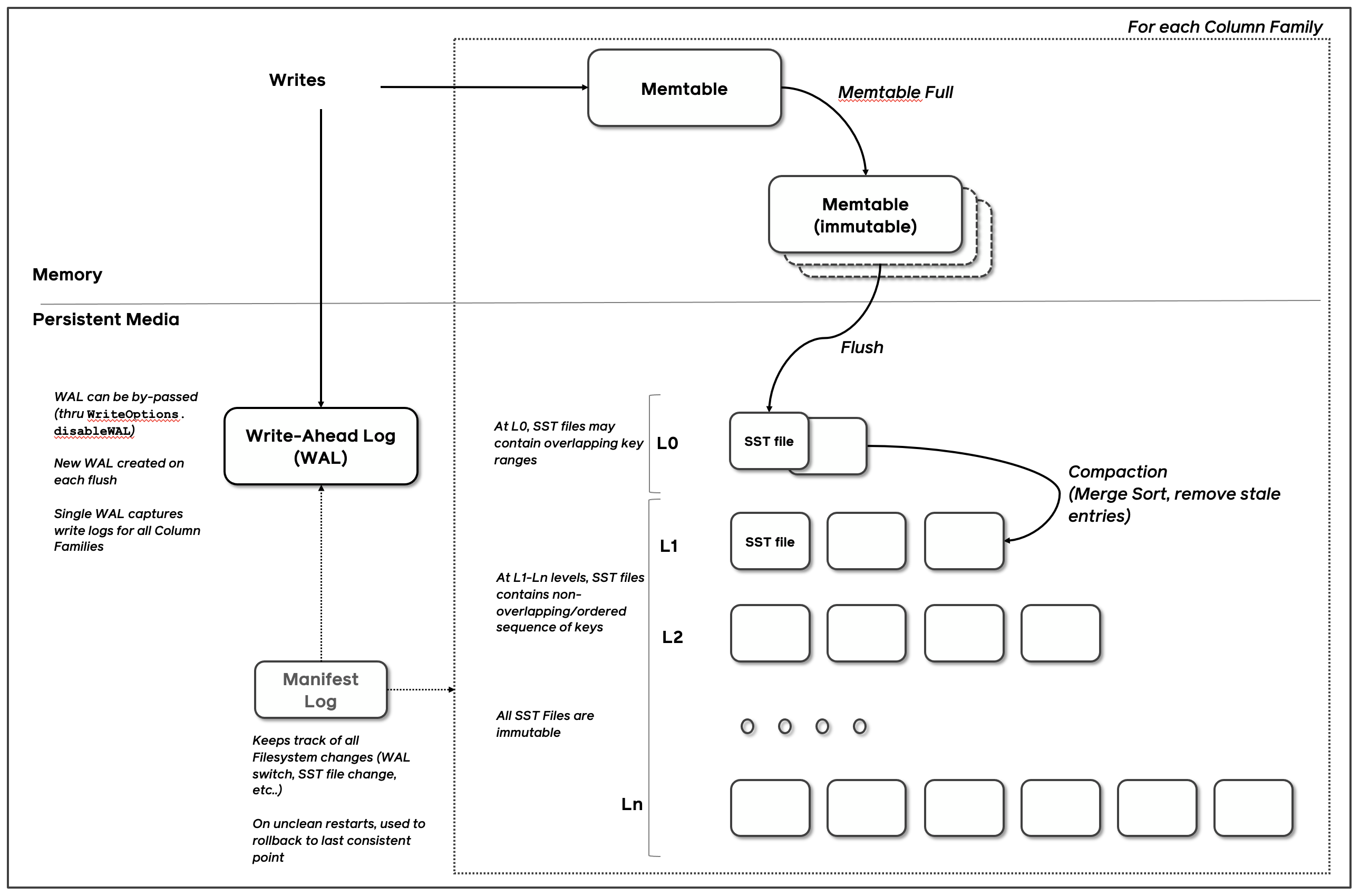
RocksDB 的三个基本结构是memtable、sstfile和logfile。memtable是一种内存数据结构——新的写入操作会被插入到memtable中,并可选择写入logfile(又称预写日志 (WAL))。logfile 是存储系统中按顺序写入的文件。当 memtable 写满时,它会被刷新到存储系统中的sstfile中,并且可以安全地删除相应的 logfile。sstfile 中的数据经过排序,以便于查找键。
1.3、Features
1.3.1、Column Families
RocksDB 支持将数据库实例划分为多个列族。所有数据库都创建一个名为“default”的列族,用于未指定列族的操作。
RocksDB 保证用户在跨列族时获得一致的视图,即使在启用 WAL 或原子刷新的情况下,也能在崩溃恢复后保持一致性。它还通过WriteBatchAPI 支持跨列族的原子操作。
1.3.2、Updates
APIPut会将单个键值对插入数据库。如果该键已存在于数据库中,则先前的值将被覆盖。APIWrite允许以原子方式在数据库中插入、更新或删除多个键值对。数据库保证单次调用中的所有键值对Write都会插入数据库,或者一个也不会插入。如果数据库中已存在任何键,则先前的值将被覆盖。APIDeleteRange可用于删除某个范围内的所有键。
1.3.3、Gets, Iterators and Snapshots
键和值被视为纯字节流。键和值的大小没有限制。该GetAPI 允许应用程序从数据库中获取单个键值对。该MultiGetAPI 允许应用程序从数据库中检索一组键值对。通过调用返回的所有键值MultiGet对彼此一致。
数据库中的所有数据都按逻辑顺序排列。应用程序可以指定键的全序比较方法。APIIterator允许应用程序对数据库进行范围扫描。应用Iterator程序可以定位到指定的键,然后从该点开始逐个键地进行扫描。该IteratorAPI 还可用于对数据库中的键进行反向迭代。创建时,会创建一个数据库的一致时间点视图Iterator。因此,通过返回的所有键都Iterator来自数据库的一致视图。
APISnapshot允许应用程序创建数据库的时间点视图。Get和IteratorAPI 可用于从指定的快照读取数据。从某种意义上说,Snapshot和Iterator都提供了数据库的时间点视图,但它们的实现不同。短期/前台扫描最好通过迭代器完成,而长时间/后台扫描最好通过快照完成。 会对Iterator与数据库的该时间点视图相对应的所有底层文件保留引用计数 - 这些文件在Iterator被释放之前不会被删除。Snapshot另一方面, 不会阻止文件删除;相反,compaction过程会理解解Snapshots 的存在并承诺永远不会删除任何现有Snapshot 中可见的键。
Snapshots在数据库重启后不会保留:重新加载 RocksDB 库(通过服务器重启)会释放所有预先存在的Snapshots。
1.3.4、Transactions
RocksDB 支持多操作事务。它支持乐观和悲观模式
1.3.5、Prefix Iterators
大多数 LSM 树引擎无法支持高效的范围扫描 API,因为它需要查看多个数据文件。但是,大多数应用程序不会对数据库中的键范围进行纯随机扫描;相反,应用程序通常在键前缀内进行扫描。RocksDB 利用了这一点。应用程序可以配置Options.prefix_extractor以启用基于键前缀的过滤。Options.prefix_extractor设置 后,前缀的哈希值也会添加到布隆过滤器中。Iterator指定键前缀(在 中ReadOptions)的 会使用布隆过滤器来避免查找不包含具有指定键前缀的键的数据文件。
1.3.6、Persistence
RocksDB 具有预写日志 (WAL)。所有写入操作(Put、Delete和Merge)都存储在名为 memtable 的内存缓冲区中,也可以选择插入到 WAL 中。重启时,它会重新处理日志中记录的所有事务。
WAL 可以配置为存储在与 SST 文件存储不同的目录中。这在某些情况下是必要的,例如当你希望将所有数据文件存储在非持久的快速存储中时。同时,你可以通过将所有事务日志放在较慢但持久的存储上来确保没有数据丢失。
每个 Put 操作都有一个标志,通过 WriteOptions 设置,用于指定该 Put 是否应插入到事务日志中。WriteOptions 还可以指定在声明 Put 操作已提交之前,是否对事务日志发出 fsync 调用。
在内部,RocksDB 使用批量提交机制将事务批量写入日志,以便能够通过一次 fsync 调用(把文件的缓冲区内容强制写入到磁盘上)潜在地提交多个事务。
1.3.7、Data Checksuming
RocksDB 使用Checksum来检测存储中的损坏。这些Checksum是针对每个 SST 文件块(通常大小在 4K 到 128K 之间)的。块一旦写入存储,就不会被修改。RocksDB 还维护一个完整文件Checksum(参见完整文件Checksum和校验和交接),并可选地对每个键值对进行Checksum。
1.3.8、Multi-Threaded Compactions
在进行写操作时,需要进行压缩以提高空间效率、读取(查询)效率和及时数据删除。压缩会移除已删除或被覆盖的键值绑定,并重新组织数据以提高查询效率。如果配置得当,压缩可以在多个线程中进行。
整个数据库存储在一组 SST 文件中。当内存表(memtable)满时,其内容会被写入 LSM 树的 Level-0(L0)文件中。RocksDB 在将内存表刷新到 L0 文件时,会移除重复和被覆盖的键。在压缩过程中,一些文件会定期被读取并合并成更大的文件,通常会进入下一个 LSM 级别(例如 L1,直到 Lmax)。
LSM 数据库的整体写入吞吐量直接依赖于压缩发生的速度,特别是当数据存储在像 SSD 或 RAM 这样的快速存储中时。RocksDB 可以配置为从多个线程发出并发的压缩请求。观察到,当数据库位于 SSD 上时,相比于单线程压缩,采用多线程压缩时持续的写入速率可能提高多达 10 倍。
1.3.9、Compaction Styles
Level 风格压缩和 Universal 风格压缩在数据库中以固定数量的逻辑级别存储数据。较新的数据存储在 Level-0(L0),而较旧的数据存储在更高编号的级别,直到 Lmax。L0 中的文件可能有重叠的键,但其他级别中的文件通常形成每个级别的单一排序运行。
Level 风格压缩(默认)通常通过最小化每个压缩步骤中涉及的文件数量来优化磁盘占用与逻辑数据库大小(空间扩展),即将 Ln 中的一个文件与所有重叠的 Ln+1 文件合并,并用新的 Ln+1 文件替换它们。
Universal 风格压缩通常通过一次合并多个文件和级别来优化写入到磁盘的总字节数与逻辑数据库大小(写入扩展),这需要更多的临时空间。与 Level 风格压缩相比,Universal 通常导致较低的写入扩展,但空间和读取扩展较高。
FIFO 风格压缩在文件过时时删除最旧的文件,可用于类似缓存的数据。在 FIFO 压缩中,所有文件都位于 Level 0。当数据的总大小超过配置的大小(CompactionOptionsFIFO::max_table_files_size)时,我们会删除最旧的表文件。
我们还允许开发人员开发和实验自定义的压缩策略。因此,RocksDB 提供了适当的钩子来关闭内置的压缩算法,并提供其他 API 以允许应用程序操作自己的压缩算法。如果设置了 Options.disable_auto_compaction,则会禁用原生压缩算法。GetLiveFilesMetaData API 允许外部组件查看数据库中的每个数据文件,并决定合并和压缩哪些数据文件。调用 CompactFiles 来压缩您想要的文件。DeleteFile API 允许应用程序删除被认为过时的数据文件。
1.3.10、Metadata storage
manifest log文件用于记录所有数据库状态的变化。压缩过程会向数据库添加新文件并删除现有文件,并通过将这些操作记录在 MANIFEST 中使其持久化。
1.3.11、Avoiding Stalls
后台compaction线程也用于将memtable内容刷新到存储文件中。如果所有后台compaction线程都忙于执行耗时较长的压缩操作,那么突然的写入操作可能会迅速填满memtable,从而阻碍新的写入操作。可以通过配置 RocksDB 保留一小组线程专门用于将memtable 内容刷新到存储来避免这种情况。
1.3.12、Compaction Filter
某些应用程序可能希望在压缩时处理键。例如,具有内置过期时间(TTL)支持的数据库可能会删除过期的键。这可以通过应用程序定义的压缩过滤器(Compaction-Filter)来实现。如果应用程序希望持续删除某个特定时间之前的数据,可以使用压缩过滤器来丢弃已过期的记录。RocksDB 的压缩过滤器使应用程序能够在压缩过程中修改键的值或完全删除某个键。例如,应用程序可以在压缩过程中持续运行数据清理程序。
1.3.13、ReadOnly Mode
数据库可以以只读模式打开,在这种模式下,数据库保证应用程序无法修改任何内容。这会导致更高的读取性能,因为经常遍历的代码路径完全避免了锁的使用。
1.3.14、Database Debug Logs(aka. Info Logs)
默认情况下,RocksDB 将详细日志写入名为 LOG* 的文件。这些日志主要用于调试和分析正在运行的系统。用户可以选择不同的日志级别(参见DBOptions.info_log_level)。此 LOG 可以配置为按指定的周期滚动。日志接口是可插拔的。用户可以插入不同的日志记录器
1.3.15、Data Compression
RocksDB 支持 lz4、zstd、snappy、zlib 和 lz4_hc 压缩,以及在 Windows 下的 xpress。RocksDB 可以配置为支持底层数据的不同压缩算法,底层数据占总数据的 90%。一个典型的安装可能会为底层配置 ZSTD(如果不可用则使用 Zlib),并为其他层配置 LZ4(如果不可用则使用 Snappy)。
1.3.16、Full Backups and Replication
RocksDB 提供了一个备份 API,BackupEngine。
RocksDB 本身并不是一个复制系统,但它提供了一些辅助函数,以帮助用户在 RocksDB 之上实现自己的复制系统。
1.3.17、Support for Multiple Embedded Databases in the same process
RocksDB 的一个常见使用场景是应用程序将其数据集固有地划分为逻辑分区或分片。这种技术有助于应用程序负载均衡和快速故障恢复。这意味着单个服务器进程应该能够同时操作多个 RocksDB 数据库。这是通过一个名为 Env 的环境对象来实现的。Env 关联了一个线程池。如果应用程序希望在多个数据库实例之间共享一个公共线程池(用于后台压缩),则应该使用相同的 Env 对象来打开这些数据库。
同样,多个数据库实例可以共享相同的块缓存或速率限制器。
1.3.18、Block Cache – Compressed and Uncompressed Data
RocksDB 使用 LRU 缓存来服务读取操作。块缓存被划分为两个独立的缓存:第一个缓存未压缩的块,第二个缓存压缩的块在 RAM 中。如果配置了压缩块缓存,用户可能希望启用direct I/O,以防止在操作系统页面缓存中冗余缓存相同的数据。
1.3.19、Table Cache
表缓存是一种用于缓存打开的文件描述符的结构。这些文件描述符用于 sst 文件。应用程序可以指定表缓存的最大大小,或者配置 RocksDB 始终保持所有文件打开,以实现更好的性能。
1.3.20、I/O Control
RocksDB 允许用户以多种方式配置对 SST 文件的 I/O 操作。用户可以启用直接 I/O,以便 RocksDB 完全控制 I/O 和缓存。另一种选择是利用一些选项,让用户提示 I/O 应该如何执行。用户可以建议 RocksDB 在读取文件时调用 fadvise,在追加文件时调用定期范围同步,启用直接 I/O 等等。有关更多详细信息,请参见 I/O 部分。
1.3.21、Stackable DB
RocksDB 具有内置的包装机制,可以在数据库内核代码之上添加功能。这些功能通过 StackableDB API 封装。例如,生存时间(time-to-live)功能是通过 StackableDB 实现的,并不是核心 RocksDB API 的一部分。这种方法使得代码保持模块化和整洁。
1.3.22、Memtables
Pluggable Memtables(可插入内存表):
RocksDB 的内存表默认实现是跳跃列表 (Skiplist)。跳跃列表是一个有序集合 (Sorted Set),当工作负载将写入操作与范围扫描交错执行时,它是必需的构造。然而,有些应用程序不会交错写入操作和扫描操作,而有些应用程序根本不进行范围扫描。对于这些应用程序,有序集合可能无法提供最佳性能。因此,RocksDB 的内存表是可插拔的。此外,还提供了其他一些实现。该库包含三种内存表:跳跃列表内存表、向量内存表和前缀哈希内存表。向量内存表适用于将数据批量加载到数据库中。每次写入操作都会在向量的末尾插入一个新元素;当需要将内存表刷新到存储时,向量中的元素会被排序并写入 L0 中的文件。前缀哈希内存表可以高效处理获取 (Get)、放入 (Put) 和键前缀内的扫描 (Scans-within-a-key-prefix)。尽管 memtable 的可插入性不作为公共 API 提供,但应用程序可以在私有分支中提供自己的 memtable 实现。
Memtable Pipelining(内存流水线)
RocksDB 支持为数据库配置任意数量的 memtable。当 memtable 已满时,它将变为不可变 memtable,后台线程会开始将其内容刷新到存储中。同时,新的写入操作会继续累积到新分配的 memtable 中。如果新分配的 memtable 已满,它也将转换为不可变 memtable,并插入到刷新管道中。后台线程会继续将所有已流水线化的不可变 memtable 刷新到存储中。这种流水线操作可以提高 RocksDB 的写入吞吐量,尤其是在运行速度较慢的存储设备时。
Memtable Flush 期间的垃圾收集:
当将内存表刷新到存储时,会执行内联压缩过程。垃圾的清除方式与压缩相同。同一键的重复更新将从输出流中移除。同样,如果先前的写入操作被后续的删除操作隐藏,则该写入操作根本不会写入输出文件。对于某些工作负载,此功能可显著减少存储上的数据大小并降低写入放大。
1.3.23、Merge Operator
RocksDB 原生支持三种类型的记录:Put 记录、Delete 记录和 Merge 记录。当压缩过程遇到 Merge 记录时,它会调用一个由应用程序指定的方法,称为 Merge 操作符。Merge 操作可以将多个 Put 和 Merge 记录合并为一个。这一强大的特性允许通常进行读-修改-写操作的应用程序完全避免读取。它使得应用程序能够将操作意图记录为 Merge 记录,而 RocksDB 的压缩过程会延迟将该意图应用于原始值。该特性在 Merge 操作符中有详细描述。
1.3.24、DB ID
数据库创建时创建的全局唯一 ID,默认存储在 DB 文件夹中的 IDENTITY 文件中。该 ID 也可以存储在 MANIFEST 文件中。建议存储在 MANIFEST 文件中。

















 1973
1973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









