






前言
工作中有个需求,gRPC Server端只有一个leader对外提供服务,其余follower只用于当leader故障时顶替Leader自动选主,follower不对外提供服务。
如何实现gRPC客户端请求gRPC server端域名时,请求仅落到gRPC server端的Leader?
这里用到了gRPC原生的负载均衡、健康检查,名称解析等功能。下面将分别介绍其原理。
1、相关原理
1.1、gRPC负载均衡
1.1.1、gRPC负载均衡原理
gRPC官网文档关于负载均衡的介绍:https://github.com/grpc/grpc/blob/master/doc/load-balancing.md
gRPC的负载均衡,是以每次调用为基础,而不是以每个连接为基础。这句话可以理解为,即使服务端收到的所有请求都来自同一个客户端,我们仍会将这些请求在gRPC服务端的所有服务器上实现负载均衡。
1.1.2、gRPC客户端负载均衡概述
grpc 客户端提供了API,用户可自己实现负载均衡策略,并通过此API应用到gRPC。
负载均衡策略负载:
- 从resolver接收 配置更新 即 server端服务器地址列表
- 对服务器创建subchannels并管理连接
- 设置总连接状态(通常通过聚合subchannels的连接状态来计算)
- 为发送到每个channel上的RPC请求,确定使用哪个subchannel发送
- gRPC提供了许多LB策略,主流的有pick_first(默认的LB策略)、round_robin、grpclb等。此外还有许多其他LB策略来支持xDS,尽管默契他们还不能直接配置。
1.1.3、负载均衡工作流
负载均衡策略是通过命名解析和客户端与服务端连接的gRPC客户端工作流来实现。
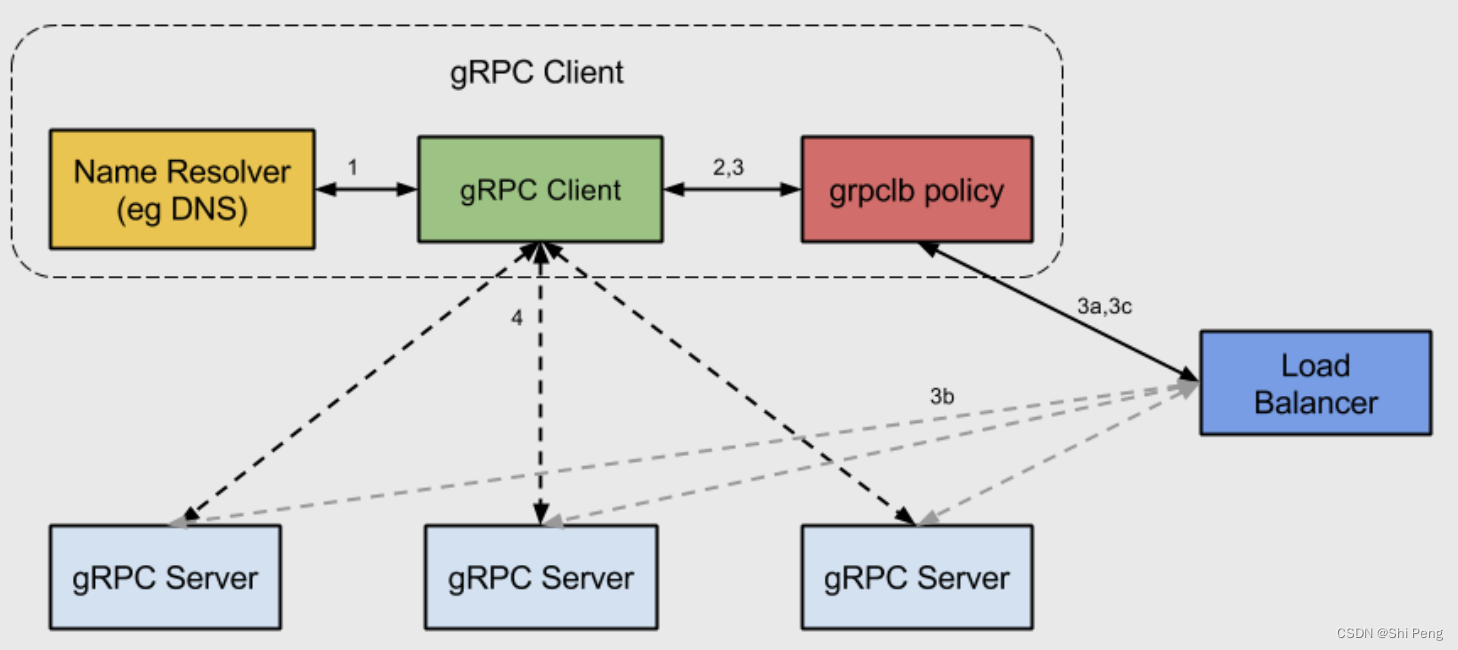
- 启动时,gRPC客户端会发出对服务端域名的命名解析请求。域名将被解析为IP列表,由gRPC客户端的service config指明采用哪种负载均衡策略,并配置一些属性。
- gRPC客户端实例化负载均衡策略,并把service config、IP列表等传递给他
- 负载均衡策略为IP列表上的服务器地址创建一组subchannels。同时他也监听subchannels的连接状态,并决定每个subchannel何时应建立连接。
- 对于每个RPC请求,负载均衡策略决定使用那个subchannel。
下面将详细讲解grpcLB策略。
1.1.4、gRPC负载均衡策略详解
1.1.4.1、pick_first
pick_first是默认的LB策略,不需要配置。
pick_first从resolver获取IP列表,并按顺序逐个尝试建立连接,直到找到一个可连接的地址。如果IP列表中没有一个可连接成功的,则在连接重试时把chunnel状态设置为TRANSIENT_FAILURE。
如果成功连接到了一个地址,会把chunnel状态设置为READY,之后所有发送到此RPC上的请求都会被发送到这个地址。如果此连接后续断开了,在pick_first策略会把此channel的状态置为IDLE,直到有应用请求前到来,他才会重连。
1.1.4.2、round_robin
round_robin LB策略是通过在service config中选的,他不需要额外任何配置。
round_robin策略从resolver中解析出地址列表,并为每个地址创建一个subchannel,并持续监听每个subchannel的连接状态:一旦某个subchannel连接断开了,round_robin策略会采用connection backoff策略进行自动重连,
round_robin根据subchannels的状态设置channel的链接状态:
- if 任一个subchannel是READY状态,那么channel的状态就是READY。
- else if 任一个subchannel的状态为CONNECTING,channel的状态为CONNECTING(CONNECTING表示正在连接)。
- else if 任一个subchannel的状态为IDEL,channel的状态为IDEL(IDEL表示连接断开)。
- else if 所有subchannel的状态都为 TRANSIENT_FAILURE(TRANSIENT_FAILURE表示重试后仍连接失败),channel的状态为 TRANSIENT_FAILURE。
当一个subchannel为TRANSIENT_FAILURE状态时,在他连接成功并状态恢复为READY之前,他的状态会被一直认为是TRANSIENT_FAILURE。这里没有从TRANSIENT_FAILURE到CONNECTING的状态转换。
当一个RPC请求发送到channel,round_robin策略会找出所有subchannel列表中处于READY状态的subchannel,为每个RPC请求轮训分配READY的subchannel。
1.1.4.2.1、gRPC Connection Backoff 协议
当客户端与服务端连接失败时,通常不希望立即重试(为了避免对网络或服务端的大量访问),而是采用某种方式的指数backoff。
backoff的参数如下:
- INITINAL_BACKOFF:第一次失败后等待多久后重试,默认值1秒
- MULTIPLIER:重试失败后的回退倍数,默认值1.6
- JITTER:随机backoff数值,默认值0.2
- MAX_BACKOFF:backoff的上限,默认值120秒
- MIN_CONNECT_TIMEOUT:连接超时时间,默认值20秒
推荐的backoff算法
以指数方式将连接重试开始时间back off到MAX_BACKOFF,并伴有JITTER:
ConnectWithBackoff() {
current_backoff = INITIAL_BACKOFF
current_deadline = now() + INITIAL_BACKOFF
while (TryConnect(Max(current_deadline, now() + MIN_CONNECT_TIMEOUT))
!= SUCCESS) { // 只要未成功,就不断重试
SleepUntil(current_deadline)
current_backoff = Min(current_backoff * MULTIPLIER, MAX_BACKOFF)
current_deadline = now() + current_backoff +
UniformRandom(-JITTER * current_backoff, JITTER * current_backoff)
}
}
1.1.4.3、grpclb
此grpclb策略目前已被弃用,官方推荐改用xDS(https://github.com/grpc/grpc/blob/master/doc/grpc_xds_features.md)。
此LB策略最初旨在为gRPC的LB策略提供扩展机制。其目的是,客户端只能实现round_robin等简单算法,而不是直接在客户端添加新的LB策略,对于复杂的LB算法都交由look-aside(后备的)load balancer来提供。
gRPC依赖load balancer提供负载均衡配置和server端地址列表。load balancer会在 ”handler server不可用“ 或 ”健康检查出问题“ 时更新服务器列表,并做出任何复杂决策,并通知到客户端。load balancer可与后端服务器通信以搜集连接负载及健康信息。
当gRPC客户端与load balancer失去联系时,grpclb策略将临时使用resolver返回的地址列表。
grpclb策略通过resolver返回的attribute获取load balancer的地址列表。
xDS主要应用于service mesh中,在mesh中由sidecar连接到xDS server进行数据交互,由sidecar来控制流量的分发。xDS是一种无proxy的客户端负载均衡方案。
2、gRPC健康检查
gRPC health checking官方文档:https://github.com/grpc/grpc/blob/master/doc/health-checking.md
2.1、gRPC服务端健康检查原理
health check用于检测gRPC服务器是否能处理RPC请求。
客户端对服务端Server的健康检查可以点对点进行,也可以通过控制系统(如负载均衡)进行。服务端server在还没有准备好接受请求、正在关闭等情况下返回“不健康”。如果客户端在某时间窗口没有收到健康检查的响应,或者响应中显示“不健康”,客户端可以根据服务端server返回的状态做相应的策略。
一个gRPC service用作简单的client到server和其他控制系统如负载均衡的健康检查机制。使用gRPC service来实现健康检查有如下好处:
- 他本身是一个gRPC service, 进行健康检查的格式与普通的RPC相同
- 具有丰富的语义,如per-service健康状态
- 作为gRPC服务,他能重用所有的现有的计费、配额等基础设置,这样server可以完全控制健康检查service的访问
2.2、gRPC健康检查服务定义
一个gRPC server通过下面的proto定义来生成一个check service:
syntax = "proto3";
package grpc.health.v1;
message HealthCheckRequest {
string service = 1;
}
message HealthCheckResponse {
enum ServingStatus {
UNKNOWN = 0;
SERVING = 1;
NOT_SERVING = 2;
SERVICE_UNKNOWN = 3; // Used only by the Watch method.
}
ServingStatus status = 1;
}
service Health {
rpc Check(HealthCheckRequest) returns (HealthCheckResponse);
rpc Watch(HealthCheckRequest) returns (stream HealthCheckResponse);
}
客户端可以通过调用Check方法(需要设置超时时间)来查询服务器的健康状况,客户端可以通过设置service name来检查对应service的健康状况。
服务器应该手动注册所有service,并单独设置每个service的状态,包括empty service name及其状态。
对于收到的每个请求,如果在注册表中能找到其service name,则一定会回复OK状态的响应,且status field设置为SERVING或NOT_SERVING;如果在注册表中找不到其service name, 服务器会返回NOT_FOUND gRPC status。
server使用空字符串作为server总体健康状态的key, 这样如果客户端对特定服务的健康状态不感兴趣时就可以使用空HealthCheckRequest来查询server的状态。server只可以做service name的精确匹配,而不支持通配符匹配。但service所有者可以自由地实现客户端和服务端都同意的更复杂的匹配语义。
如果健康检查RPC在指定时间内没有完成,客户端可以认为此server不健康,然后执行服务端挂掉的策略。
客户端也可以调用watch方法来执行流式健康检查,server会立即回复当前service状态的消息给客户端;之后每当service状态发生变更,server都会马上给client发送通知。
gRPC服务端将服务的最新状态,更新到一个channel通道里,健康检查服务Watcher会从此channel通道里获取此服务的最新状态,如果发现此最新状态跟之前的状态不一样,服务端会将此最新状态发送给客户端。
3、gRPC 服务发现与name解析
3.1、服务发现简介
通俗解析下服务发现:客户端要跟服务端建立连接,需要知道服务端的IP+Port,但一个服务对应的IP+Port可能会经常变更,所以给服务取个名字,客户端通过此名字跟服务端建立连接,客户端底层使用服务发现系统,解析此名字来获取真正的IP+Port,并在服务端IP+Port发生变更时,重新建立连接。这样的系统成为name-system。
3.2、gRPC Name Resolution
gRPC默认的name-syatem是DNS。
在实际的部署中,可以使用多种name-system,gRPC提供的API很通用,可支持一些列name-system及相应的语法。
gRPC官网name resolution文档:https://github.com/grpc/grpc/blob/master/doc/naming.md#name-syntax
3.2.1、Name语法
gRPC采用的命名语法遵循RFC 3986中定义的RUI语法:
scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
例如:

- schema:要使用的服务发现解析器,如未指定默认为DNS
- host:要通过DNS解析的host
- port:为每个地址返回的端口,如未指定,则使用443(对于insecure channels,默认为80)
3.2.2、Resolver Plugins
gRPC客户端库使用指定schema来选出正确的resolver插件,并对其传递指定的name字符串
resolver能联系到权威机构并返回解析结果给gRPC客户端库,返回的内容包括:
- 解析出的地址列表(IP和Port),每个地址可以有预期相关的一组属性(key/value对),这些属性可用于负载均衡策略
- Service Config
Resolver插件的API让resolver持续监听endpoint,并返回变更的解析结果。
2、请求仅落到leader的实现方案
2.1、设置健康检查接口的状态
下面场景下会设置server健康检查的状态:
2.1.1、设置状态为SERVING
1、服务启动时
health.SetServingStatus(``, serving)
2、follower变为leader时
在gRPC server端,如当前节点是follower,他会定时检测leader心跳是否超时,如果是,会发起leader竞选,如果成功当选为leader, 他会把当前节点的健康检查状态设置为SERVING
health.SetServingStatus(serviceName, serving)
2.1.2、设置状态为NOT_SERVING
1、服务启动失败时
服务启动时,会监听依赖服务的地址,如连接失败,则设置服务状态不可用:
health.SetServingStatus(serviceName, notServing)
health.SetServingStatus(``, notServing)
2、服务关闭时
health.SetServingStatus(serviceName, notServing)
health.SetServingStatus(``, notServing)
3、leader变为follower时
- 如当前节点是leader,他会定时发送leader心跳,如果他假死复活,发现他已不是leader,他会把当前节点的检查检查状态置为NOT_SERVIING
health.SetServingStatus(serviceName, notServing)
2.1.3、查询此server是否健康
func IsServing() bool {
rep, _ := health.Check(
context.Background(),
&grpchealth.HealthCheckRequest{Service: ``})
return rep.GetStatus() == serving
}
2.1.4、查询此节点是否为leader
func IsLeader() bool {
rep, _ := health.Check(
context.Background(),
&grpchealth.HealthCheckRequest{Service: serviceName})
return rep.GetStatus() == serving
}
2.2、gRPC客户端如何使用健康检查接口
2.2.1、通过ServiceConfig配置gRPC客户端
serviceConfig := `{
"loadBalancingPolicy": "round_robin",
"healthCheckConfig": {
"serviceName": "xx.v1.ControllerService"
}
}`
options := []grpc.DialOption{
grpc.WithTransportCredentials(insecure.NewCredentials()),
grpc.WithDefaultServiceConfig(serviceConfig),
}
address := `dns://域名:80`
conn, err := grpc.Dial(address, options...)
if err != nil {
log.Fatalf("grpc.Dial(%q): %v", address, err)
}
defer conn.Close()
2.2.2、gRPC客户端请求怎样落到server端leader节点
上述配置采用了round_robin负载均衡策略,从上述关于round_robin章节的描写:
“当一个RPC请求发送到channel,round_robin策略会找出所有subchannel列表中处于READY状态的subchannel,为每个RPC请求轮训分配READY的subchannel”
对于我们只有一个leader的场景,只有leader所在节点的状态是READY的,所以gRPC客户端的请求会被分配给leader所在的节点上。
2.2.3、当leader故障会发生什么
如果leader故障了:
1、开始时gRPC客户端访问leader节点会超时,这是round_robin策略会自动重连,但由于leader节点故障了,此时重连失败,gRPC channel状态变为TRANSIENT_FAILURE。
2、follower有定时任务检测到leader心跳超时,会有一个follower自动被选举为leader,此新leader 的service的健康检查状态会变为SERVING,round_robin通过不断重试会跟此节点建立连接成功,此时channel状态变为READY,当客户端有请求来时,会发给此新的leader节点。
3、负载均衡源码分析
3.1、gRPC的平衡器Balancer
gRPC客户端负载均衡实现架构图:
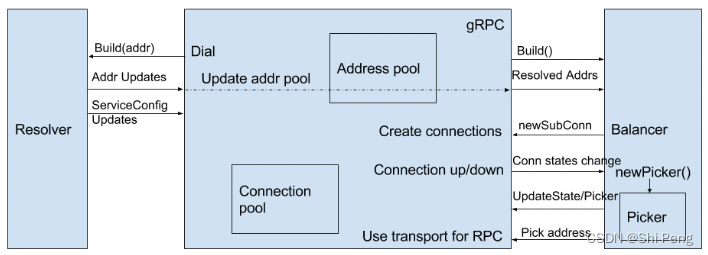
可以看出,一个Balancer中内置了一个picker模块,Balancer完成下述功能:
- 与resolver通信,接收resolver通知的server列表更新,维护Connection Pool及每个连接的状态
- 对于从resolver获取到的server列表,为每个地址建立一个长连接,并监控每个连接的状态,及时更新到Connection Pool。
- 创建Picker,Picker执行的算法,就是真正的LB逻辑,当客户端访问gRPC提供的方法时,通过Picker选择一个存活的连接返回给客户端,然后调用UpdatePicker更新LB算法的内存状态,为下一次调用做准备
Balancer源码分析:https://github.com/grpc/grpc-go/blob/master/balancer/balancer.go
Balancer的核心代码如下图:
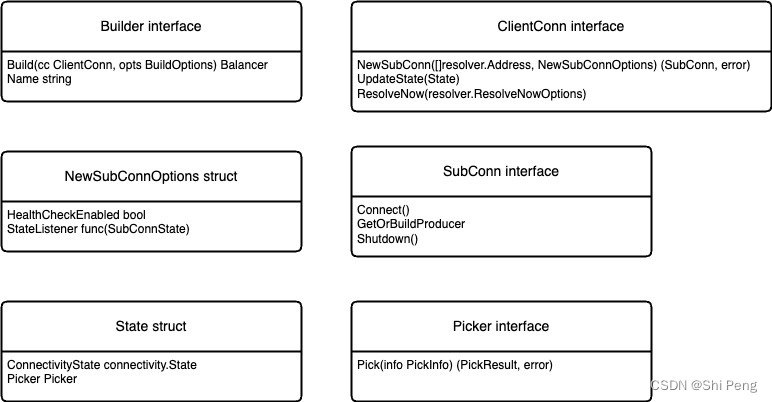
Balancer通过Register方法进行注册
// Register registers the balancer builder to the balancer map. b.Name
// (lowercased) will be used as the name registered with this builder. If the
// Builder implements ConfigParser, ParseConfig will be called when new service
// configs are received by the resolver, and the result will be provided to the
// Balancer in UpdateClientConnState.
//
// NOTE: this function must only be called during initialization time (i.e. in
// an init() function), and is not thread-safe. If multiple Balancers are
// registered with the same name, the one registered last will take effect.
func Register(b Builder) {
name := strings.ToLower(b.Name())
if name != b.Name() {
// TODO: Skip the use of strings.ToLower() to index the map after v1.59
// is released to switch to case sensitive balancer registry. Also,
// remove this warning and update the docstrings for Register and Get.
logger.Warningf("Balancer registered with name %q. grpc-go will be switching to case sensitive balancer registries soon", b.Name())
}
m[name] = b
}
- Register的入参是Builder接口,Builder接口包含方法Build,其入参为ClientConn接口(一个ClientConn表示一个客户端实例与gRPC server之间的连接)。
- ClientConn接口中的NewSubConn方法入参[]resolver.Address推荐仅传入一个地址,另一个入参为NewSubConnOptions接口
- NewSubConnOptions接口的HealthCheckEnable属性表示负载均衡创建SubConn是否采用健康检查service状态为SERVING的来建立连接,另一个方法监听SubConnState的变更.
- ClientConn接口的UpdateState(State)的入参State struct有两个属性,connectivity.State表示IDLE(连接断开后),CONNECTING(正在连接),READY(连接正常),TRANSIENT_FAILURE(连接失败),SHUTDOWN(连接关闭);另一个属性为Picker
- Picker执行真正的LB算法,为gRPC请求分配一个SubConn
3.2、round_robin源码解读
源码地址:https://github.com/grpc/grpc-go/blob/master/balancer/roundrobin/roundrobin.go
// newBuilder creates a new roundrobin balancer builder.
func newBuilder() balancer.Builder {
return base.NewBalancerBuilder(Name, &rrPickerBuilder{}, base.Config{HealthCheck: true})
}
func init() {
balancer.Register(newBuilder())
}
通过调用Register方法来注册一个Balancer,可以看到,round_robin负载均衡启动了健康检查功能。
round_robin在构建连接时,仅使用READY状态的SubConn:
func (*rrPickerBuilder) Build(info base.PickerBuildInfo) balancer.Picker {
logger.Infof("roundrobinPicker: Build called with info: %v", info)
if len(info.ReadySCs) == 0 {
return base.NewErrPicker(balancer.ErrNoSubConnAvailable)
}
scs := make([]balancer.SubConn, 0, len(info.ReadySCs))
for sc := range info.ReadySCs {
scs = append(scs, sc)
}
return &rrPicker{
subConns: scs,
// Start at a random index, as the same RR balancer rebuilds a new
// picker when SubConn states change, and we don't want to apply excess
// load to the first server in the list.
next: uint32(grpcrand.Intn(len(scs))),
}
}
当picker为gRPC请求选择SubConn时,采用轮询算法:
unc (p *rrPicker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
subConnsLen := uint32(len(p.subConns))
nextIndex := atomic.AddUint32(&p.next, 1)
sc := p.subConns[nextIndex%subConnsLen]
return balancer.PickResult{SubConn: sc}, nil
}
3.3、pick_first源码解读
https://github.com/grpc/grpc-go/blob/master/pickfirst.go
pick_first也是通过Register方法注册一个Balancer:
func init() {
balancer.Register(newPickfirstBuilder())
}
pick_first调用demo:
https://github.com/grpc/grpc-go/blob/master/balancer/rls/balancer_test.go
stub.Register(childPolicyName, stub.BalancerFuncs{
Init: func(bd *stub.BalancerData) {
bd.Data = balancer.Get(grpc.PickFirstBalancerName).Build(bd.ClientConn, bd.BuildOptions)
},
ParseConfig: func(sc json.RawMessage) (serviceconfig.LoadBalancingConfig, error) {
cfg := &childPolicyConfig{}
if err := json.Unmarshal(sc, cfg); err != nil {
return nil, err
}
return cfg, nil
},
UpdateClientConnState: func(bd *stub.BalancerData, ccs balancer.ClientConnState) error {
bal := bd.Data.(balancer.Balancer)
bd.ClientConn.UpdateState(balancer.State{ConnectivityState: connectivity.Idle, Picker: &testutils.TestConstPicker{Err: balancer.ErrNoSubConnAvailable}})
bd.ClientConn.UpdateState(balancer.State{ConnectivityState: connectivity.Connecting, Picker: &testutils.TestConstPicker{Err: balancer.ErrNoSubConnAvailable}})
cfg := ccs.BalancerConfig.(*childPolicyConfig)
return bal.UpdateClientConnState(balancer.ClientConnState{
ResolverState: resolver.State{Addresses: []resolver.Address{{Addr: cfg.Backend}}},
})
},
})
调用UpdateClientConnState方法来初始化SubConn:
看pickfirst.go的UpdateClientConnState方法来创建SubConn并建立连接:
func (b *pickfirstBalancer) UpdateClientConnState(state balancer.ClientConnState) error {
...
var subConn balancer.SubConn
subConn, err := b.cc.NewSubConn(addrs, balancer.NewSubConnOptions{
StateListener: func(state balancer.SubConnState) {
b.updateSubConnState(subConn, state)
},
})
...
b.subConn = subConn
b.state = connectivity.Idle
b.cc.UpdateState(balancer.State{
ConnectivityState: connectivity.Connecting,
Picker: &picker{err: balancer.ErrNoSubConnAvailable},
})
b.subConn.Connect()
return nil
}
可以看到,在balancer.NewSubConnOptions时并没有传递HealthCheckEnabled,即pick_first未基于健康检查service是否可用来对SubConn建立连接。
pick_first的Pick:
type picker struct {
result balancer.PickResult
err error
}
func (p *picker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
return p.result, p.err
}
// idlePicker is used when the SubConn is IDLE and kicks the SubConn into
// CONNECTING when Pick is called.
type idlePicker struct {
subConn balancer.SubConn
}
func (i *idlePicker) Pick(balancer.PickInfo) (balancer.PickResult, error) {
i.subConn.Connect()
return balancer.PickResult{}, balancer.ErrNoSubConnAvailable
}
可以看到,如果gRPC请求来事,如果SubConn为IDLE,即连接断开,则会采用idlePicker的Pick方法重连。
3.4、resolver有新地址怎样通知Balancer的
dns_resolver.watcher --> resolver_wrapper.ClientConn.UpdateState --> clientconn.updateResolverStateAndUnlock --> balancer_wrapper.updateClientConnState --> Balancer.UpdateClientConnState
resolver源码:https://github.com/grpc/grpc-go/blob/master/resolver/resolver.go
在resolover.go中有ClientConn接口:
// ClientConn contains the callbacks for resolver to notify any updates
// to the gRPC ClientConn.
//
// This interface is to be implemented by gRPC. Users should not need a
// brand new implementation of this interface. For the situations like
// testing, the new implementation should embed this interface. This allows
// gRPC to add new methods to this interface.
type ClientConn interface {
// UpdateState updates the state of the ClientConn appropriately.
//
// If an error is returned, the resolver should try to resolve the
// target again. The resolver should use a backoff timer to prevent
// overloading the server with requests. If a resolver is certain that
// reresolving will not change the result, e.g. because it is
// a watch-based resolver, returned errors can be ignored.
//
// If the resolved State is the same as the last reported one, calling
// UpdateState can be omitted.
UpdateState(State) error
// ReportError notifies the ClientConn that the Resolver encountered an
// error. The ClientConn will notify the load balancer and begin calling
// ResolveNow on the Resolver with exponential backoff.
ReportError(error)
// NewAddress is called by resolver to notify ClientConn a new list
// of resolved addresses.
// The address list should be the complete list of resolved addresses.
//
// Deprecated: Use UpdateState instead.
NewAddress(addresses []Address)
// ParseServiceConfig parses the provided service config and returns an
// object that provides the parsed config.
ParseServiceConfig(serviceConfigJSON string) *serviceconfig.ParseResult
}
可以看到,UpdateState方法用于发现有新的state变更时会被调用,他的调用方:
https://github.com/grpc/grpc-go/blob/master/resolver/dns/dns_resolver.go 的 watcher方法:
func (d *dnsResolver) watcher() {
defer d.wg.Done()
backoffIndex := 1
for {
state, err := d.lookup()
if err != nil {
// Report error to the underlying grpc.ClientConn.
d.cc.ReportError(err)
} else {
err = d.cc.UpdateState(*state)
}
var waitTime time.Duration
if err == nil {
// Success resolving, wait for the next ResolveNow. However, also wait 30
// seconds at the very least to prevent constantly re-resolving.
backoffIndex = 1
waitTime = MinResolutionInterval
select {
case <-d.ctx.Done():
return
case <-d.rn:
}
} else {
// Poll on an error found in DNS Resolver or an error received from
// ClientConn.
waitTime = backoff.DefaultExponential.Backoff(backoffIndex)
backoffIndex++
}
select {
case <-d.ctx.Done():
return
case <-internal.TimeAfterFunc(waitTime):
}
}
}
ClientConn接口的UpdateState方法实现详见:
https://github.com/grpc/grpc-go/blob/master/resolver_wrapper.go:
// UpdateState is called by resolver implementations to report new state to gRPC
// which includes addresses and service config.
func (ccr *ccResolverWrapper) UpdateState(s resolver.State) error {
ccr.cc.mu.Lock()
ccr.mu.Lock()
if ccr.closed {
ccr.mu.Unlock()
ccr.cc.mu.Unlock()
return nil
}
if s.Endpoints == nil {
s.Endpoints = make([]resolver.Endpoint, 0, len(s.Addresses))
for _, a := range s.Addresses {
ep := resolver.Endpoint{Addresses: []resolver.Address{a}, Attributes: a.BalancerAttributes}
ep.Addresses[0].BalancerAttributes = nil
s.Endpoints = append(s.Endpoints, ep)
}
}
ccr.addChannelzTraceEvent(s)
ccr.curState = s
ccr.mu.Unlock()
return ccr.cc.updateResolverStateAndUnlock(s, nil)
}
调用了https://github.com/grpc/grpc-go/blob/master/clientconn.go的updateResolverStateAndUnlock方法:
func (cc *ClientConn) updateResolverStateAndUnlock(s resolver.State, err error) error {
defer cc.firstResolveEvent.Fire()
// Check if the ClientConn is already closed. Some fields (e.g.
// balancerWrapper) are set to nil when closing the ClientConn, and could
// cause nil pointer panic if we don't have this check.
if cc.conns == nil {
cc.mu.Unlock()
return nil
}
if err != nil {
// May need to apply the initial service config in case the resolver
// doesn't support service configs, or doesn't provide a service config
// with the new addresses.
cc.maybeApplyDefaultServiceConfig()
cc.balancerWrapper.resolverError(err)
// No addresses are valid with err set; return early.
cc.mu.Unlock()
return balancer.ErrBadResolverState
}
var ret error
if cc.dopts.disableServiceConfig {
channelz.Infof(logger, cc.channelz, "ignoring service config from resolver (%v) and applying the default because service config is disabled", s.ServiceConfig)
cc.maybeApplyDefaultServiceConfig()
} else if s.ServiceConfig == nil {
cc.maybeApplyDefaultServiceConfig()
// TODO: do we need to apply a failing LB policy if there is no
// default, per the error handling design?
} else {
if sc, ok := s.ServiceConfig.Config.(*ServiceConfig); s.ServiceConfig.Err == nil && ok {
configSelector := iresolver.GetConfigSelector(s)
if configSelector != nil {
if len(s.ServiceConfig.Config.(*ServiceConfig).Methods) != 0 {
channelz.Infof(logger, cc.channelz, "method configs in service config will be ignored due to presence of config selector")
}
} else {
configSelector = &defaultConfigSelector{sc}
}
cc.applyServiceConfigAndBalancer(sc, configSelector)
} else {
ret = balancer.ErrBadResolverState
if cc.sc == nil {
// Apply the failing LB only if we haven't received valid service config
// from the name resolver in the past.
cc.applyFailingLBLocked(s.ServiceConfig)
cc.mu.Unlock()
return ret
}
}
}
var balCfg serviceconfig.LoadBalancingConfig
if cc.sc != nil && cc.sc.lbConfig != nil {
balCfg = cc.sc.lbConfig
}
bw := cc.balancerWrapper
cc.mu.Unlock()
uccsErr := bw.updateClientConnState(&balancer.ClientConnState{ResolverState: s, BalancerConfig: balCfg})
if ret == nil {
ret = uccsErr // prefer ErrBadResolver state since any other error is
// currently meaningless to the caller.
}
return ret
}
https://github.com/grpc/grpc-go/blob/master/balancer_wrapper.go
的updateClientConnState方法:
// updateClientConnState is invoked by grpc to push a ClientConnState update to
// the underlying balancer. This is always executed from the serializer, so
// it is safe to call into the balancer here.
func (ccb *ccBalancerWrapper) updateClientConnState(ccs *balancer.ClientConnState) error {
errCh := make(chan error)
ok := ccb.serializer.Schedule(func(ctx context.Context) {
defer close(errCh)
if ctx.Err() != nil || ccb.balancer == nil {
return
}
name := gracefulswitch.ChildName(ccs.BalancerConfig)
if ccb.curBalancerName != name {
ccb.curBalancerName = name
channelz.Infof(logger, ccb.cc.channelz, "Channel switches to new LB policy %q", name)
}
err := ccb.balancer.UpdateClientConnState(*ccs)
if logger.V(2) && err != nil {
logger.Infof("error from balancer.UpdateClientConnState: %v", err)
}
errCh <- err
})
if !ok {
return nil
}
return <-errCh
}

















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









