







哈夫曼树
哈夫曼树是一种应用广泛的二叉树,可用来构造最优编码,用于信息传输、数据压缩等方面。
我们先来了解一些基本概念
路径:路径是指从一个结点到另一个结点之间的分支序列。
路径长度:是指从一个结点到另一个结点经过的分支数目。
结点的权:实际应用中,人们常常给树的某个结点赋予一个具有某种实际意义的实数,称该实数为这个结点的权。
树路径长度:从树根到每一结点的路径长度之和
带权路径长度:从树根到该结点的路径长度与该结点的权的乘积。
树的带权路径长度:树的带权路径长度为树中从根到所有叶子结点的各个带权路径长度之和,记为WPL
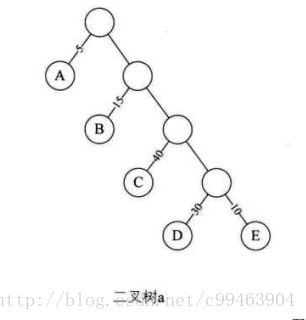
如下图:该树根结点到D结点的路径长度为4,该树的路径长度20,该树的带权路径长度
WPL=5*1+15*2+40*3+30*4+10*4=315
研究树的路径长度PL和带权路径长度WPL,目的在于寻找最优。
带权路径长度WPL最小的二叉树称为哈夫曼树。
哈夫曼树是由n个带权叶子结点构成的所有二叉树中带权路径长度最短的二叉树,又称为最优二叉树。
构建哈夫曼树
(1)初始化:用给定的n个权值{w1,w2,……,wn}构造n棵二叉树并构成的森林F={T1,T2,……,Tn},其中每一棵二叉树Ti(1<=i<=n)都只有一个权值为wi的根结点,其左、右子树为空。
(2)找最小树。在森林F中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、右子树,标记新二叉树的根结点权值为其左、右子树的根结点权值之和。
(3)删除与加入。从F中删除被选中的那两棵二叉树,同时把新构成的二叉树加入到森林F中。
(4)重复②③步,直到森林中只含有一棵二叉树为止,此时得到的二叉树就是哈夫曼树。
我们来演示一个例子,相信大家会一目了然。
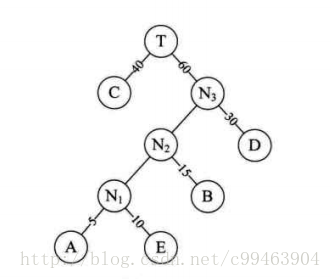
给定一组权值{5,10,15,30,40},构造哈夫曼树。
(1)先取最小的两个结点5,10,构成新的结点的左、右孩子,注意相对较小的为左孩子。
(2)这时新子树的权值为15,放入F中,再取最小的两个结点15,15构成新的结点,重复以上步骤
哈夫曼树算法实现
//创建结点类
public class HuffmanNode<T> {
//存储数据
public T data;
//结点的权值
public int weight;
//左右孩子结点
public HuffmanNode<T> left;
public HuffmanNode<T> right;
public HuffmanNode() {
super();
}
public HuffmanNode(T data, int weight) {
super();
this.data = data;
this.weight = weight;
}
public HuffmanNode(T data) {
super();
this.data = data;
}
public HuffmanNode(T data, int weight, HuffmanNode<T> left, HuffmanNode<T> right) {
super();
this.data = data;
this.weight = weight;
this.left = left;
this.right = right;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
//实现创建哈夫曼树算法
//传入参数为结点集合
public static HuffmanNode createTree(List<HuffmanNode> nodes) {
int count=0;
// 只要nodes数组中还有2个以上的节点
while (nodes.size() > 1) {
//先对结点按照权值进行排序,排序算法可以自己实现
quickSort(nodes);
//获取权值最小的两个节点
HuffmanNode left = nodes.get(nodes.size()-1);
HuffmanNode right = nodes.get(nodes.size()-2);
//生成新节点,新节点的权值为两个子节点的权值之和
HuffmanNode parent = new HuffmanNode(++count, left.weight + right.weight);
//让新节点作为两个权值最小节点的父节点
parent.left = left;
parent.right = right;
//删除权值最小的两个节点
nodes.remove(nodes.size()-1);
nodes.remove(nodes.size()-1);
//将新节点加入到集合中
nodes.add(parent);
}
return nodes.get(0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
哈夫曼编码
了解完哈夫曼树后,我们来看看它的应用,哈夫曼树的出现当年是为了解决远距离通信(电报)的数据传输问题。
例如我们要传递”BADCADFEED“这段内容,数据是以二进制形式进行传递的。
我们假设字母对应的二进制编码如下 :

那么我们实际传递的数据就是001000011010000011101100100011,何况这才是几个字符,如果一篇非常长的文章,那么数据量就很可怕了。但每个字母的出现频率是不同的,哈夫曼编码的思想是:给使用频率较高的字符编以较短的编码。怎么理解呢?我们上面任何一个字符都是3位,都为定长编码,而我们就可以采用不定长的编码,然后让频率较高的字符编上较短的编码。
我们用个例子来说明一下
(1)假设我们的六个字母出现的频率为A 27 , B 8 , C 15 , D 15 , E 30 , F 5,合起来为100%,然后我们构造哈夫曼树按照频率来排序这些字符。
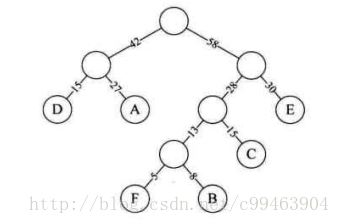
(2)然后我们将权值左分支改为0,右分支改为1.
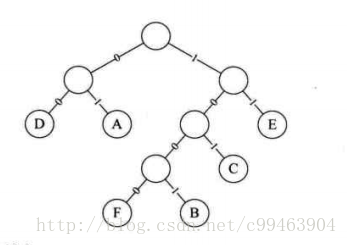
(3)此后我们对字符以从树根到结点所经过的路径来编码。 此时就会得到不定长编码,如下

(4)此时我们再将刚才的字符进行编码,得到1001010010101001000111100,就会发现数据被压缩了。
可是这时我们接收到这种不定长的编码时,该如何解码呢?我们需要先了解一些概念
前缀编码:如果在一个编码系统中,任一字符的编码都不是其他任何字符编码的前缀,则称这种编码为前缀编码。例如一组编码1000,100,10,1001就不是前缀编码。
哈夫曼编码:一般地,设需要编码的字符集为{d1,d2,……dn},各个字符在电文中出现的频率集合为{w1,w2……wn},以d1,d2……dn作为结点,以其频率作为结点权值构造一棵哈夫曼树,对树中的左分支赋予0,右分支赋予1(也可规定左1右0),则从根结点到叶子结点经过的路径分支组成的01序列便作为该字符的编码,这就是哈夫曼编码。
哈夫曼编码的特性
哈夫曼编码是前缀编码。
哈夫曼编码是最优前缀编码。即哈夫曼编码能使各种报文(由这n种字符构成)对应的二进制串的平均长度最短。
至于算法的实现,这里就不再给出代码,网上有很多实现代码,当然大家可以自己手动写一个。
二叉查找树
二叉查找树,又称二叉排序树,具有如下性质
若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值
若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值
它的左、右子树也分别为二叉排序树
//树的结点类
public class TreeNode<T> {
//存储数据
public T data;
//指向左孩子和右孩子结点
public TreeNode<T> left,right;
public TreeNode(T data, TreeNode<T> left, TreeNode<T> right) {
super();
this.data = data;
this.left = left;
this.right = right;
}
public TreeNode(T data) {
super();
this.data = data;
}
public TreeNode() {
this.data = null;
this.left = null;
this.right =null;
}
public String toString() {
return this.data.toString();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
//我们使用泛型保证传入的对象必须具有比较的性质
public class BinarySearchTree<T extends Comparable> {
public TreeNode<T> root;
public BinarySearchTree() {
super();
}
public BinarySearchTree(T x) {
super();
root=new TreeNode<>(x);
}
//判断该树是否为空
public boolean isEmpty() {
return root==null;
}
public boolean contains(T x) {
return contains(x,root);
}
//判断当前树是否包含某个对象,对象必须实现Comparable接口或者手动实现比较器,使用递归来完成
public boolean contains(T x,TreeNode<T> root) {
if(root==null) {
return false;
}
int result=x.compareTo(root.data);
if(result<0) {
return contains(x,root.left);
}else if(result >0) {
return contains(x,root.right);
}else{
return true;
}
}
public T findMax() {
return findMax(root);
}
//查找最大值
public T findMax(TreeNode<T> root)
{
if(root==null) {
return null;
}else if(root.right==null) {
return root.data;
}
return findMax(root.right);
}
public T findMin() {
return findMin(root);
}
//查找最小值
public T findMin(TreeNode<T> root) {
if(root==null) {
return null;
}else if(root.left==null) {
return root.data;
}
return findMin(root.left);
}
public void insert(T x) {
if(root==null) {
this.root=insert(x,this.root);
}else {
insert(x,this.root);
}
}
//插入操作
public TreeNode insert(T x,TreeNode root) {
if(root==null) {
return new TreeNode(x,null,null);
}
int result =x.compareTo(root.data);
if(result<0) {
root.left=insert(x,root.left);
}else if(result>0){
root.right=insert(x,root.right);
}
return root;
}
public void remove(T x) {
remove(x,root);
}
//删除操作
/*删除操作比较麻烦,因为需要考虑好几种情况
*1.删除的是叶子结点,直接删除
*2.删除的有一个子结点,可以直接将其子结点移动到这个位置
*3.如果有两个结点,我们也可以先让左子树移动到当前位置,然后对右子树重新排序,但是这个方法效率很低。
* 所以我们可以找到一个替代该结点的结点,这个结点就是右子树的最小结点,这样整棵树的结构不会有任何变化
*/
public TreeNode<T> remove(T x,TreeNode<T> root) {
if(root==null) {
return null;
}
int result=x.compareTo(root.data);
if(result<0) {
remove(x,root.left);
}else if(result>0) {
remove(x,root.right);
}else if(root.left!=null&&root.right!=null) {
root.data=findMin(root.right);
root.right=remove(root.data,root.right);
}else {
root=(root.left!=null)?root.left:root.right;
}
return root;
}
public void preOrder(TreeNode<T> p) {
if (p != null) {
// 访问当前结点
System.out.print(p.data.toString() + " ");
// 按先根次序遍历当前结点的左子树,递归调用
preOrder(p.left);
// 按先根次序遍历当前结点的右子树,递归调用
preOrder(p.right);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
虽然二叉查找树查询插入等平均操作效率都有提高,但是有一些很特别的情况,我们来考虑一下 。
例如有一个已排好序的数组{35,37,47,51,58,62,73,88,93,99},那么我们插入这些元素构成的二叉排序树如下图

这时候很明显查找效率要经过很多次比较,效率大大降低。我们希望二叉树是平衡的,即其深度与完全二叉树相同,均为[log2n]+1,这样查找的时间复杂度就为O(logn),近似于折半查找,因此如果我们想要进行二叉排序查找,最好将其构造成平衡的二叉排序树。
AVL树
AVL树是i带有平衡条件的二叉排序树,一棵AVL树其每一个结点的左子树和右子树的高度最多差一。我们将二叉树结点的左子树深度减去右子树深度的值称为平衡因子BF,AVL树上所有结点的平衡因子只可能是-1、0、1.
如下图,图1是平衡二叉树。图二不是,因为平衡二叉树的前提首先是一棵二叉排序树。图三不是平衡二叉树的原因是结点58的左子树高度为2,右子树为空,BF大于1,所以不平衡。
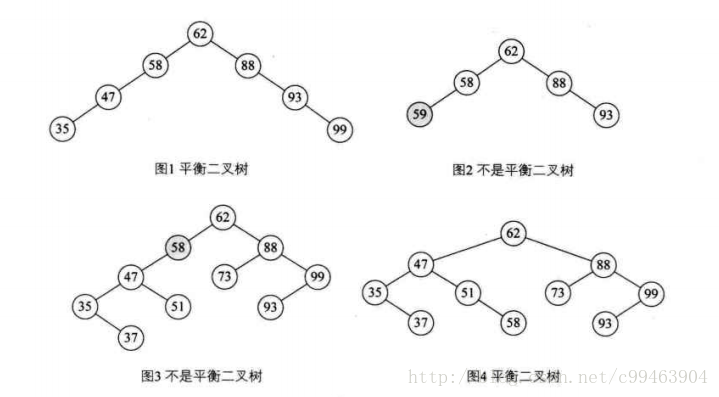
距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树,我们称为最小不平衡子树。
如下图,当新插入结点37时,距离它最近的平衡因子绝对值超过1的结点是58,所以从58开始以下的子树为最小不平衡子树。
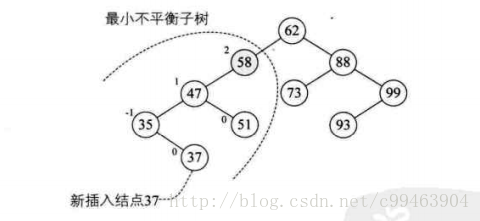
平衡二叉树实现原理
平衡二叉树构建的基本思想就是在构建二叉排序树的过程中,每插入一个结点时,先检查是否因为插入而破坏了树的平衡性,若是,找出最小不平衡子树。在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使其成为新的平衡子树。
我们用个例子来说明一下。
我们现在有一个数组{3,2,1,4,5,6,7,10,9,8},我们根据二叉排序树的特性来构建。
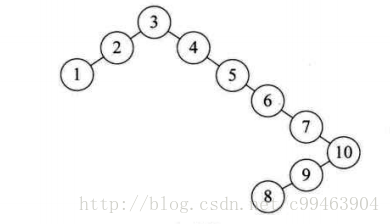
虽然它完全符合二叉排序树的定义,但是高度太高,严重影响查找的效率,我们需要研究如何将其构建成平衡二叉树。
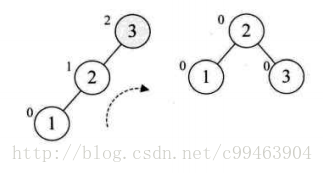
对与前两位3,2我们正常的构建,到了第三个数1时,我们会发现结点3的平衡因子变成了2,此时整棵树为最小不平衡子树,所以我们需要调整一下。因为BF值为正,我们将树右旋(顺时针旋转),这样三个结点BF值为0,非常平衡。
这时我们增加4结点,仍然是平衡二叉树。
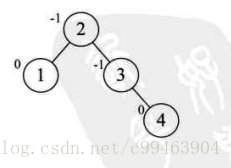
我们增加5结点,结点3的BF值为-2,因为BF为负值,我们将其左旋(逆时针旋转)
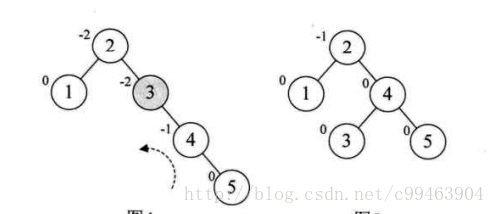
接下来我们增加6结点,发现根结点的BF值为-2,我们需要对根结点进行左旋,注意本来结点3是结点4的左孩子,旋转后需要满足二叉排序树的定义,所以变成结点2的右孩子。
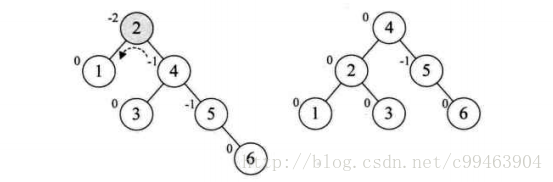
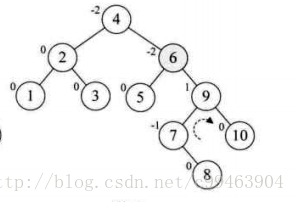
接下来增加结点7,同样需要左旋。
增加结点10,结构无任何变化。
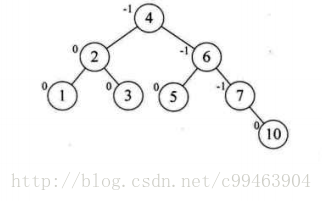
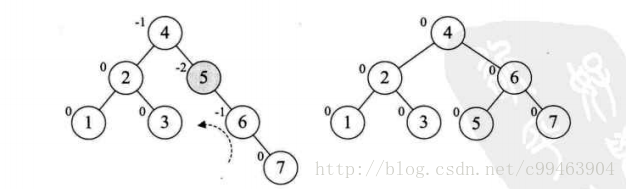
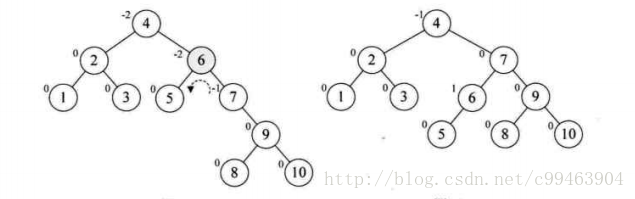
再增加结点9,此时结点7的BF值为-2,理论上我们需要旋转最小不平衡子树7、9、10即可,但是左旋后,结点9就成了10的右孩子,这是不符合二叉排序树的性质的
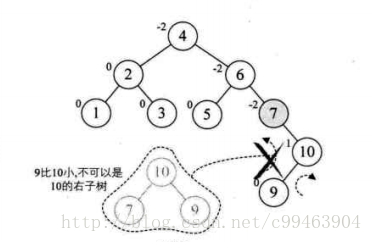
我们仔细观察一下,发现根本原因在于结点7的BF为-2,结点10的BF为1,一正一负,符号并不统一,前面的几次旋转,符号都是统一的,这就是不能旋转的关键,不统一我们就需要先将符号统一,我们先对结点9和10进行右旋,使得结点10成了9的右子树,结点9的BF为-1,此时就与结点7的BF值符号统一了。然后再以结点7进行左旋。
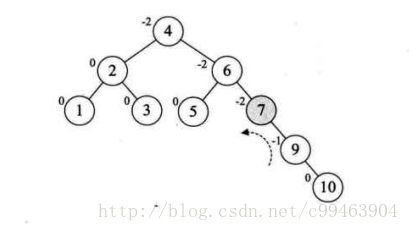
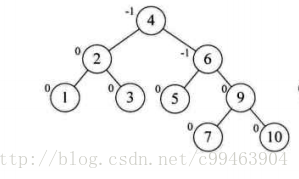
接着插入8,情况与刚才类似。
平衡二叉树实现
//平衡二叉树的结点类
public class AvlNode<T> {
//结点的数据
T element;
//指向其左右孩子
AvlNode<T> left,right;
//高度
int height;
public AvlNode() {
super();
}
public AvlNode(T element, AvlNode<T> left, AvlNode<T> right, int height) {
super();
this.element = element;
this.left = left;
this.right = right;
this.height = height;
}
public AvlNode(T element) {
super();
this.element = element;
}
//返回树的高度
public int getHeight(AvlNode<T> t) {
return t==null?-1:height;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
public class AvlTree<T extends Comparable> {
//根结点
AvlNode<T> root;
public AvlTree() {
super();
}
//获取树的高度
public int getHeight(AvlNode<T> t) {
if(t!=null)
return t.getHeight(t);
return -1;
}
//先序遍历平衡二叉树
public void preOrder(AvlNode<T> p) {
if (p != null) {
// 访问当前结点
System.out.print(p.element.toString() + " ");
// 按先根次序遍历当前结点的左子树,递归调用
preOrder(p.left);
// 按先根次序遍历当前结点的右子树,递归调用
preOrder(p.right);
}
}
//插入操作
public void insert(T value) {
root=insert(value,root);
}
public AvlNode<T> insert(T value,AvlNode<T> tree){
if(tree==null)
return new AvlNode<T>(value);
int result=value.compareTo(tree.element);
if(result>0) {
tree.right=insert(value,tree.right);
}else if(result<0) {
tree.left=insert(value,tree.left);
}
//平衡二叉树
return balance(tree);
}
//左旋操作
private AvlNode<T> rotateWithRightChild(AvlNode<T> p){
AvlNode<T> k1=p.left;
p.left=k1.right;
k1.right=p;
p.height=Math.max(getHeight(p.left), getHeight(p.right))+1;
k1.height=Math.max(getHeight(k1.left), p.height)+1;
return k1;
}
/**
* 右旋操作
*
*
*/
private AvlNode<T> rotateWithLeftChild(AvlNode<T> p){
AvlNode<T> k1=p.right;
p.right=k1.left;
k1.left=p;
p.height=Math.max(getHeight(p.left), getHeight(p.right))+1;
k1.height=Math.max(getHeight(k1.right), p.height)+1;
return k1;
}
//双旋转操作
public AvlNode<T> doubleWithLeftChild(AvlNode<T> k){
k.left=rotateWithLeftChild(k.left);
return rotateWithRightChild(k);
}
//双旋转操作
public AvlNode<T> doubleWithRightChild(AvlNode<T> k){
k.right=rotateWithRightChild(k.right);
return rotateWithLeftChild(k);
}
//平衡二叉树操作
public AvlNode<T> balance(AvlNode<T> t){
//当左子树比右子树高度大于1时,左旋转
if(getHeight(t.left)-getHeight(t.right)>1) {
//判断需要单旋转还是双旋转
if(getHeight(t.left.left)>=getHeight(t.left.right)) {
t=rotateWithRightChild(t);
}else {
t=doubleWithLeftChild(t);
}
}
//当右子树比左子树高度大于1时,右旋转
else if(getHeight(t.right)-getHeight(t.left)>1) {
if(getHeight(t.right.right)>=getHeight(t.right.left)) {
t=rotateWithLeftChild(t);
}else {
t=doubleWithRightChild(t);
}
}
t.height=Math.max(getHeight(t.left), getHeight(t.right))+1;
return t;
}
public AvlNode<T> remove(T x){
return remove(x,root);
}
//删除操作
public AvlNode<T> remove(T x,AvlNode<T> t){
if(t==null) {
return null;
}
int result=x.compareTo(t.element);
if(result>0) {
t.right=remove(x,t.right);
}else if(result<0) {
t.left=remove(x,t.left);
}else if(t.left!=null&&t.right!=null) {
t.element=findMin(t.right);
t.right=remove(t.element,t.right);
}else {
t=(t.left!=null)?t.left:t.right;
}
if(t==null) {
return null;
}
return balance(t);
}
//查找最小值
public T findMin(AvlNode<T> root) {
if(root==null) {
return null;
}else if(root.left==null) {
return root.element;
}
return findMin(root.left);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
<link rel="stylesheet" href="http://csdnimg.cn/release/phoenix/production/markdown_views-993eb3f29c.css">
</div>















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









