






目录
对线性表顺序存储时,如果需要频繁的进行插入与删除操作则运行的时间效率就不够理想。所以,我们提出链式结构的存储线性表,称为链表。
一、单链表的定义
在顺序表中,一个重要的特点就是连续的存储单元依次存放线性表的结点,因此结点的顺序与数据原先的顺序一致,我们称其为逻辑和物理上相邻,但是这却对内存空间的分配与使用提出更加严格的要求。但是链表不会这样。链表使用一组任意的存储单元来存放线性表中的元素,为了使数据原先的逻辑关系不丢失,在每个元素的存储结点还应该指示其后续结点的地址,这个信息称为指针。
由此我们给出链表的结点的结构:
数据域 指针域 data next
该图中结点只有一个指针域,称为单链表,但有时候需要我们构建有多个指针的链表,如:双链表、十字链表等。
关于链表结点的C语言描述如下:
/*单链表结点描述
typedef struct node
{
datatype data;
struct node *next;
}linklist;
linklist *head,p
*/
//上述链表结点定义了一个结构体node,该结构体包含了两个域,数据域data和指针域*next
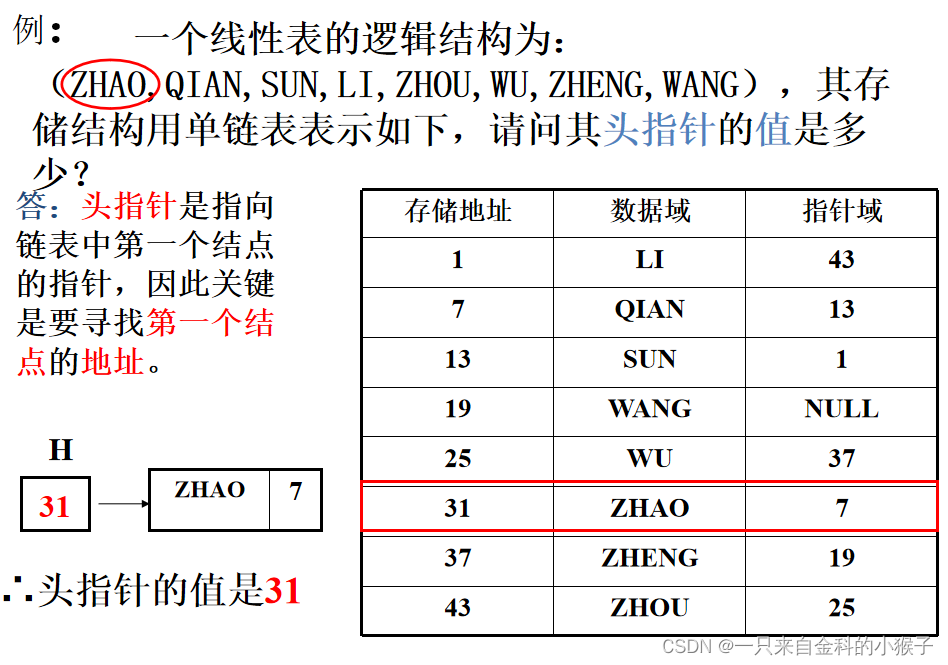

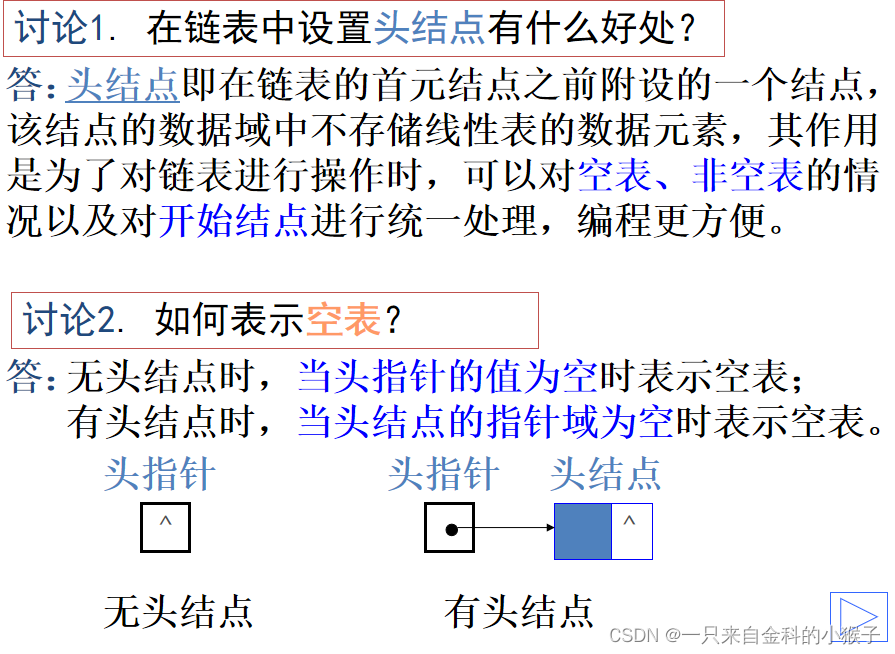
注:参考<stdlib.h>库函数,以下是几个常用函数
(1)、sizeof(x):计算变量x的长度,返回整数
(2)、malloc(m):开辟m字节长度的地址空间,并返回这段空间的首地址
(3)、free(p):释放指针p所指变量的存储空间
//将全局变量及函数提前说明:
#include<stdio.h>
#include<stdlib.h>
typedef struct node {
datatype data; //数据域
struct node *next; //指针域
}linklist *head, *p, *q; //一般需要3个指针变量
int m ; // 数据元素的个数
int m=sizeof(linklist); /* 结构类型定义好之后,每个变量的长度就固定了,m求一次即可 */
//单链表的读取(或修改)
//单链表中想取得第i个元素,必须从头指针出发寻找(顺藤摸瓜),不能随机存取
datatype Get(linklist *L, int i)
{ p=L->next; j=1;
while( j<i ){p=p->next; ++j;}
if(!p||j>i)return NULL;
e=p->data;
return e;
}
动态建立单链表主要有前插法和后插法两种
/*)
(1)、前插法:
linklist *CREATLIST()
{
char ch;
linklist *head,*p;
head=NULL;
ch=getchar();
while(ch!="$")
{
s=malloc(sizeof(linklist));
s->data=ch;
s->next=head;
head=s;
ch=getchar();
}
rewturn head;
}
(2)、后插法:
linklist *CREATLIST()
{
linklist *head,*p,*s;
char ch;
ch=getchar();
head=malloc(sizeof(linklist));
head->data=ch;
p=head;
ch=getchar();
while(ch!='$')
{
s=malloc(sizeof(linklist));
s->data=ch;
p->next=s;
p=s;
ch=getchar();
}
p->next=NULL;
return head;
}/*
(1)、按序号查找:
linklist *GET(head,i)
{
int j;
linklist *P;
p=head;j=0; //从头开始扫描
while((p->next!=NULL)&&(j<i))
{
p=p->next; //扫描下一个结点
j++; //已经扫描的结点计数器
}
if(i==j) //找到了第i个结点
{
return p;
}
else //找不到,i<=0或i>n
{
return NULL;
}
}
(2)、按值查找:
linklist *LOCATE(head,key)
{
linklist *p; //从开始结点比较
p=head->next;
while(p!=NULL)
{
if(p->data!=key)
{
p=p->next; //没找到继续循环
}
else
{
break; //找到节点key,退出循环
}
}
return p;
}
*/
1、前插法:(即:在链表中(*p)结点前面插入一个元素。)
INSERTBEFORE(head,p,x)
{
linklist *s,*q;
s=malloc(sizeof(linklist)); //定义新结点*s
S->data=x;
q=head; //从头指针开始
while(q->next!=p)
{
q=q->next;
}
S->next=p; //查找*p的前驱节点*q
q->next=s; //将新结点*s插入到*p前
}
2、后插法:(即:在链表中(*p)结点后面插入一个元素。)
void INSERTAFTER( linklist * p, datatype x)
{
linklist *s;
s=(LinkList *)malloc(sizeof(linklist));
s->data=x;
s->next=p->next;
p->next=s;
}
因为后插算法的时间复杂度是O(1),而前插算法的执行时间与位置P有关,平均时间复杂度为O(n);
因此想改善前插的时间性能,可以在*p之后插入新结点*s,然后交换*s和*p的值。假设*p的值是a ,新结点的值是x,从而改进前插进程
代码如下:
INSERTBEFORE1(p,x)
{
linklist *s;
s=malloc(sizeof(linklist));
s->data=p->data;
s->next=p->next;
p->data=x;
p->next=s;
}
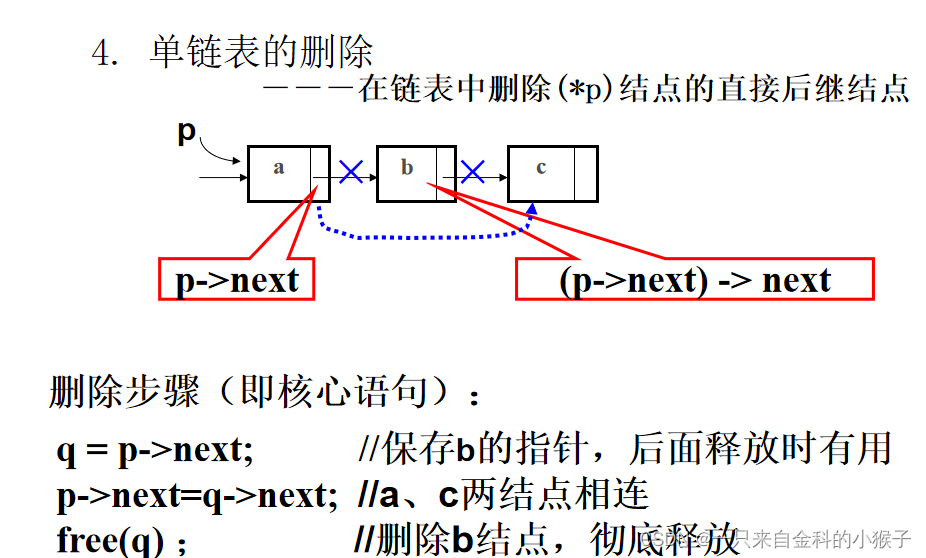
datatype DeleteAfter ( linklist *p )
{
linklist *q;
q=p->next;
p->next=q->next;
x=q->data;
free(q);
return x;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









