










10. 1分组查询关键字 group by 用法
-- group:组,分组
-- by:通过... -- group by...:通过...进行分组
-- 说明:group by 字段名/聚合函数, 意思是先通过给定的【字段名/聚合函数】先进行
分组,再对分组后的数据进行分别处理。
-- 查询时,什么时候需要对数据进行分组?
-- 一般查询问题为“每个...”,“各个...”的时候,需要对数据进行分组
举例:查询员工表中每个部门人员的平均工资,查询结果显示部门编号、平均工资
Select avg(salary),department_id
From hrdb.employees
Group by department_id; -- 使用关键字 group by 通过部门编号进行分组
-- 说明:先通过部门编号对 employees 表里的数据进行分组,再对每个组中的数据求平均
工资
举例:查询员工表中每个职位人员的平均工资,查询结果显示职位编号、平均工资
SELECT AVG(salary),job_id
FROM hrdb.employees
GROUP BY job_id; -- 通过职位编号将人员进行分组(先对人员分组,再求每组中人员的
平均工资)
10.2 使用 group by 关键字进行多字段分组
举例:查询不同部门中,不同职位的人员的平均工资,查询结果显示部门编号、职位编号、平均工资
SELECT department_id,job_id,AVG(salary)
FROM hrdb.`employees` GROUP BY department_id,job_id; -- 多字段分组,字段之间用逗号隔开,先按部门分组,再对不同部门中的不同职位进行分组
举例:查询部门编号为 70 的部门的人员的工资之和
方法一:
SELECT department_id,SUM(salary)
FROM hrdb.`employees` WHERE department_id=70;
方法二:
SELECT department_id,SUM(salary)
FROM hrdb.`employees` GROUP BY department_id
HAVING department_id=70; -- 使用 having 关键字对分组后的每组数据求和后进行过
滤。
10.3 对 group by 分组后的结果数据使用 having 关键字进行过滤
-- 说明:having 关键字,可以对分组后的数据进行过滤,类似于 where 的作用,但又不
同于 where. -- having 后的过滤条件,可以跟字段,也可以跟聚合函数【avg()等】。
举例:查询员工表中不同部门人员的平均工资,查询结果要求只显示
平均工资高于 12000 的部门编号、平均工资
SELECT AVG(salary),department_id
FROM hrdb.`employees` GROUP BY department_id
HAVING AVG(salary)>12000; -- 使用 having 子句对平均工资进行过滤,符合条件的留
下,显示在结果中
举例:查询员工表中不同部门人员的平均工资,查询结果要求只显示
部门编号低于 60 的部门编号、平均工资
SELECT AVG(salary),department_id
FROM hrdb.`employees` GROUP BY department_id
HAVING department_id<60; -- 按部门分组的数据处理,使用 having 条件过滤,查询
结果只保留部门编号低于 60 的
-- 重要总结(面试题)
-- having 和 where 的区别:
-- 1)数据未分组的情况下使用 where 能够对数据进行过滤;
-- 2)在数据经过 group by分组后,having可以对分组后的数据进行过滤,where不行;
-- 3)having 后可以跟字段、分组函数;
-- 4)where 后不能跟分组函数,只能跟字段;
如下为错误写法:
SELECT
AVG(salary), department_idFROM
hrdb.`employees` WHERE AVG(salary)<15000; -- 错误
10.4 对查询结果使用 order by 关键字进行排序
-- 说明:mysql 中查询,查询结果默认按升序(从上到下,按从小到大)排列
-- 升序排列:
-- 方法一:不加排序关键字
-- 方法二:使用关键字 ASC
-- 降序排列:
使用关键字 DESC
-- 排序关键字使用语法:order by 字段名 [asc|desc],意思是通过给定的字段名将查询结
果进行排序(升序或者降序)
-- order,顺序,排序
-- by,通过...的意思
-- order by...意思是通过给定的条件进行排序
-- order by 后可以跟:字段名,别名,函数名
举例:查询员工表中所有人员的工资,查询结果按工资高低升序排列,结果显示员工编号、
工资
方法一:
SELECT employee_id,salary FROM hrdb.`employees` ORDER BY salary; -- 不指定排序方式的情况下,默认按升序排列方法二:
SELECT employee_id,salary FROM hrdb.`employees` ORDER BY salary ASC;
举例:查询不同部门的平均工资,查询结果按平均工资高低进行降序排列,
查询结果显示部门编号、平均工资
SELECT AVG(salary),department_id
FROM hrdb.`employees` GROUP BY department_id -- 通过部门编号进行分组
ORDER BY AVG(salary) DESC; -- 使用关键字 DESC 说明是按平均工资高低进行降序排列
举例:查询员工表不同部门的人员的平均工资,查询结果按平均工资高低降序排列,结果显
示员部门编号、平均工资
SELECT department_id,AVG(salary) av -- av 为 AVG(salary)的别名,在查询语句中可以使用别名代替这个函数
FROM hrdb.`employees` GROUP BY department_id
ORDER BY av DESC; -- 查询结果中使用别名 av 代替 AVG(salary)进行降序排列
10.5 查询关键字 limit 的用法-分页查询
-- 说明:limit 限制的意思,在 sql 语句可以对查询结果进行过滤
-- 在 mysql 中,limit m,n,意思是从第 m+1 条数据开始取数据,连续取 n 条数据,显示在
查询结果中。
举例:查询员工表中所有人员的工资,查询结果按工资高低降序排列,结果显示工资前四高的员工编号、工资
SELECT employee_id,salary
FROM hrdb.`employees` ORDER BY salary DESC -- 根据薪资高低降序排列
LIMIT 0,4; -- 相当于 limit 4,取前四条数据
举例:查询员工表中所有人员的工资,查询结果按工资高低降序排列,结果显示工资第四高的员工编号、工资
SELECT employee_id,salary
FROM hrdb.`employees` ORDER BY salary DESC
LIMIT 3,1;
举例:查询不同部门的平均工资,查询结果按平均工资高低进行降序排列,查询结果显示前 4 条数据的部门编号、平均工资
SELECT AVG(salary),department_id
FROM hrdb.`employees` GROUP BY department_id -- 根据部门编号分组
ORDER BY AVG(salary) DESC -- 根据平均薪资高低降序排列
LIMIT 4; -- 取平均工资最高的四条数据
举例:查询不同部门的平均工资,查询结果显示平均工资高于 8000 的数据,查询结果按平均工资高低进行降序排列,只显示前 4 条数据的部门编号、平均工资
SELECT AVG(salary),department_id -- 查询平均工资,部门编号
FROM hrdb.`employees` -- 从员工表中查询数据GROUP BY department_id -- 依据部门编号进行分组
HAVING AVG(salary)>8000 -- 筛选平均工资高于 8000 的分组,符合条件的留下
ORDER BY AVG(salary) DESC -- 对筛选后的数据,按平均薪资高低进行降序排列
LIMIT 4; -- 在排序后的数据中,取平均工资最高的前四条
-- 总结:查询时,先分组,再对分组结果过滤,再排序,再取指定的数据
举例:查询员工表中所有人员的工资,查询结果按工资高低降序排列,查询结果显示第 8
高人员的工资、姓名、职位编号
SELECT first_name,last_name,salary,job_id
FROM hrdb.`employees` ORDER BY salary DESC
LIMIT 7,1; -- 在查询结果中,从第 7 条数据的下一条开始取,只取一条数据,就是第 8
10.6 使用 like 关键字进行模糊查询
-- 说明:模糊查询,使用查询关键字 like,like 意思是类似于,像...的意思
-- 模糊查询,支持两种字符匹配符号:
-- 下划线_:下划线可以代替任意单个字符
-- 百分号%:可以代替任意个任意字符(0 个、1 个或者多个字符) -- 百分号和下划线可以组合到一起与 like 关键字配合使用
举例:查询员工表中员工编号第二位为 2 的员工的编号、姓名
SELECT employee_id,first_name,last_name
FROM hrdb.`employees` WHERE employee_id LIKE "_2%"; -- _代替第一位字符,%代替 2 后的所有字符举例:查询员工表中员工编号第三位为 2 的员工的编号、姓名
SELECT employee_id,first_name,last_name
FROM hrdb.`employees` WHERE employee_id LIKE "__2%";
举例:查询员工表中员工编号最后一位为 2,倒数第 2 位为 1 的员工的编号、姓名
SELECT employee_id,first_name,last_name
FROM hrdb.`employees` WHERE employee_id LIKE "%12";
举例:查询员工表中职位编号第一位为 A 的职位编号、姓名
SELECT job_id,first_name,last_name
FROM hrdb.`employees` WHERE job_id LIKE "a%";
举例:查询员工表中 first_name 第一位为 a,第三位为 i 的员工编号、姓名
SELECT employee_id,first_name,last_name
FROM hrdb.`employees` WHERE first_name LIKE "a_i%";
举例:查询不同职位的平均工资,要求查询职位编号包括 a,
职位平均工资高于 3000 的职位编号,
查询结果按平均工资高低进行降序排列,只显示前 2 条数据的职位编号、平均工资。
方法一:
SELECT job_id,AVG(salary)
FROM hrdb.`employees`WHERE job_id LIKE "%a%" GROUP BY job_id
HAVING AVG(salary)>3000
ORDER BY AVG(salary) DESC
LIMIT 2;
方法二:
SELECT job_id,AVG(salary)
FROM hrdb.`employees` GROUP BY job_id
HAVING AVG(salary)>3000 AND job_id LIKE "%a%" ORDER BY AVG(salary) DESC
LIMIT 2;
10.7查询关键字 distinct 的用法
-- 说明:distinct 意思是有区别的,这里用于在查询时过滤掉重复数据
-- distinct 一般和 count()函数配合使用
举例:查询员工表中有哪些职位分类,要求查询结果不显示重复数据
SELECT DISTINCT job_id FROM hrdb.`employees`; -- 说明:在查询语句中,distinct 和某一具体字段名配合使用,可以过滤该字段的重复数据
举例:查询员工表中不同职位的个数,要求查询结果过滤掉重复数据
SELECT COUNT(DISTINCT job_id) FROM hrdb.`employees`; -- distinct 和 count()函数配合使用
错误写法:
SELECT COUNT(job_id) FROM hrdb.`employees`; -- 显示重复数据
举例:distinct 相关错误写法:查询员工表中不同职位,查询结果显示部门编号、职位编号
SELECT department_id,DISTINCT job_id
FROM hrdb.`employees`;
举例:查询不同 last_name,不同职位编号的人员的信息,查询结果显示 last_name,职位编
号,查询结果不显示重复数据
Select distinct last_name,job_id from hrdb.employees;
10.8 计数函数 count()使用注意事项:
-- count(*):统计所有记录,包括 null 相关数据
-- count(具体字段名):统计结果不包括对应字段名为 null 相关记录
举例:统计部门表中有多少个部门
SELECT COUNT(*) FROM hrdb.`departments`; -- 统计所有记录
SELECT COUNT(manager_id) FROM hrdb.`departments`; -- 不统计字段值为 null 的相
关记录
10.9多字段排序
-- 多字段排序,就是排序时,可以同时使用多个字段对查询结果数据先后进行排序,“排序
字段”之间使用逗号隔开
语法:Order by 字段 1 [[desc]|[asc]] ,字段 2 [[desc]|[asc]]
举例:查询员工表中不同员工的薪资,查询结果先按部门编号降序排列,再按薪资高低降序
排列
SELECT department_id,salary
FROM hrdb.`employees` ORDER BY department_id DESC,salary DESC;
10.10多字段分组
-- 多字段分组,就是对表中数据进行分组操作时,可以使用多个字段先后对查询结果数据
进行分组。
语法:
Group by 字段 1,字段 2
举例:查询员工表中不同部门下不同职位人员的平均工资,查询结果显示员工编号、部门编
号、职位编号、平均工资
SELECT employee_id,department_id,job_id,AVG(salary)
FROM hrdb.`employees` GROUP BY department_id,job_id;-- 先按部门编号分组,在每个部门中,再按职位编号进行分组
10.11 查询的优先级
优先级顺序:
高:()>not>and>or 低举例:查询工资低于 8000 或者高于 12000,员工编号大于 120 的人员的工资、部门编号、员工编号
SELECT salary,department_id,employee_id
FROM hrdb.`employees` WHERE (salary<8000 OR salary >12000) AND employee_id>120; -- 逻辑运算符由高到低的运算顺序为:()->NOT->AND->OR
11. 查询多个表中的数据(必须掌握!!!!!!!-面试笔试常考)
11.1 笛卡尔积查询:(了解)
从如下两个表中同时查询数据:
SELECT * FROM hrdb.`employees`; -- 107
SELECT * FROM hrdb.`departments`; -- 27
SELECT * FROM hrdb.`employees`,hrdb.`departments`; -- 2889
SELECT 27*107
11.2 内连接查询 ##通过连接条件查询两个表的数据结果示例如下:(理解)
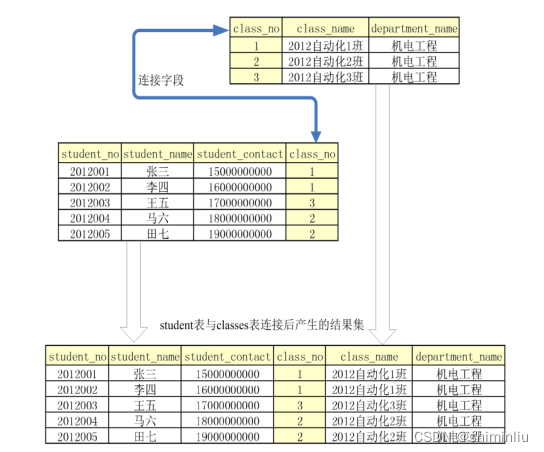
·-- 跨表查询步骤:
步骤一:分析需要查询的数据和给出的条件相关数据分布在哪些表中
步骤二:分析需要查询的数据所在表和所给条件相关数据所在表之间有哪些联系(找两个表
的相同字段,存在,即表示两个表有直接关系)
直接关系:两个表之间有数据引用(相同字段)
间接关系:两个表之间通过其他表有数据引用关系(两两之间有共同字段)
步骤三:结合其他所给条件,写查询需要的 SQL 语句
#### 别名(alias) -- 说明:在 sql 语句中,表的别名可以代替对应表,字段的别名可以代替对应字段,
-- 函数的别名可以代替对应函数
-- 别名作用:可以减少 sql 语句编写的工作量,标识数据来源
举例:查看员工表中,员工编号为 100 的员工所在的部门的部门名称
SELECT e.employee_id,d.department_name,d.department_id
FROM hrdb.`employees` AS e,departments AS d
WHERE e.`department_id`=d.`department_id` AND employee_id=100;
多表查询语法:
SELECT 别名 1.字段名 1,别名 2.字段名 2
FROM 库名.表名 1 AS 别名 1,库名.表名 2 AS 别名 2
WHERE 别名 1.字段名 3=别名 2.字段名 3 AND 其他条件;
举例:查询员工表中 last_name 为 Fay 的员工所在的部门的名称
SELECT e.last_name,d.`department_name` FROM hrdb.`employees` e,hrdb.`departments` d
WHERE e.`department_id`=d.`department_id` AND last_name="Fay";
举例:查询在城市 Seattle 中工作的人员有哪些(跨三个表查询数据)
SELECT l.city,e.employee_id
FROM hrdb.`locations` l,hrdb.`departments` d,hrdb.`employees` e
WHERE l.location_id=d.location_id
AND d.department_id=e.department_id
AND l.city="Seattle"; -- 明确:数据在哪些表里:employees、locations,
-- 找出使 employees 和 locations 建立起关系的中间 departments
举例:查询在 United States of America 工作的员工有哪些人
SELECT employee_id,country_name
FROM hrdb.countries c,hrdb.`locations` l,hrdb.`departments` d,hrdb.`employees` eWHERE c.country_id=l.country_id
AND l.location_id=d.location_id
AND d.department_id=e.department_id
AND c.country_name="United States of America";
举例:查询职位名称为 Marketing Manager 的职位,有哪些员工,查询结果显示员工编号、
职位名称
SELECT j.job_title,e.employee_id
FROM hrdb.`jobs` j,hrdb.`employees` e
WHERE j.job_id=e.job_id
AND j.job_title="Marketing Manager";
举例:查询部门名称为 Purchasing 的部门,对应员工的平均工资
单表查询写法:
步骤一:先在部门表中查询出部门名称为 Purchasing 的部门所在部门的部门编号
SELECT department_id FROM hrdb.departments WHERE
department_name="Purchasing"; -- 结果为 30
步骤二:再在员工表中查询出部门编号为 30 的部门的平均工资
SELECT AVG(salary),department_id FROM hrdb.`employees` WHERE
department_id=30;
多表查询写法:
SELECT d.department_name,AVG(e.salary)
FROM hrdb.`departments` d,hrdb.`employees` e
WHERE d.department_id=e.department_idAND d.department_name="Purchasing";
举例:求工资总和比部门名称为 Finance 的部门的工资总和高的,那些部门的部门编号、
工资总和,查询结果以工资总和高低降序排列,取前两条数据
SELECT d.`department_name`, SUM(e.`salary`)
FROM hrdb.`departments` d, hrdb.`employees` e
WHERE e.`department_id`=d.`department_id`
GROUP BY d.`department_id`
HAVING SUM(e.`salary`)>(SELECT SUM(e.`salary`)
FROM hrdb.`employees` e,hrdb.`departments` d
WHERE e.`department_id`=d.`department_id`
AND d.`department_name`='Finance')
ORDER BY SUM(e.`salary`) DESC
LIMIT 2; -- mysql 中查询语句执行顺序:
开始—>From 子句—>where 子句—>Group by子句—>Having 子句—>Order by 子句—>select子句—>Limit 子句—>结果 -- [死记
11.3 子查询【嵌套查询】
1)、#子查询的概念
子查询是一个嵌套在另一个查询【主查询】内部中的查询,子查询可以达到的查询目的,使
用其他多表连接查询同样可以实现,但子查询更容易阅读和编写;1)、子查询出现在 from 子句中
-- 说明:把内层的子查询查询结果当成临时表,供外层 sql 语句再次查询
语法:
Select 查询列表 1 from (select 查询列表 2 from 库名.表名 where 条件表达式);
-- 外部查询的查询列表需要和子查询的查询列表具有相同字段或者为其子集
举例:查询 hrdb 数据库 employees 表工资大于 7000 的名字包括字母 c 的员工的
first_name,salary
SELECT f.first_name,f.salary
FROM (SELECT e.first_name,e.salary FROM hrdb.employees e WHERE
e.salary >7000) -- 可以理解成一张临时表
WHERE f.first_name LIKE "%c%";
错误信息解释:
错误代码: 1248
Every derived table must have its own alias
-- derived 派生
-- own 自己的
-- its 它
-- alias 别名,as 是它的缩写
每一个派生表【子查询结果生成的临时表】必须有它自己的别名
2)、子查询出现在 where 子句中
-- 说明:指把内层查询的结果作为外层查询的比较条件.-- 语法:
SELECT 字段 1 FROM 库名.表名
WHERE 字段 1 关系运算符(SELECT 字段 1 FROM 库名.表名 WHERE 字段 2 关系运算
符 字段值); -- 关系运算符指的是大于号、小于号等。
举例:查询员工表中工资比“员工编号为 104 的员工的工资”低的员工的姓名、
员工编号、工资
SELECT first_name,last_name,employee_id,salary
FROM hrdb.`employees` WHERE salary<(SELECT salary FROM hrdb.`employees` WHERE employee_id=104);
3)、子查询出现在 having 子句中
-- 语法:
Select 查询列表 1 from 库名.表名
Group by 字段名
Having 字段名 比较运算符(select 字段名 from 库名.表名 where 条件);
举例:查询部门编号大于“first_name 为 Bruce 的员工所在部门的部门编号”的那些部门
的部门编号
SELECT department_id
FROM hrdb.`employees` GROUP BY department_id
HAVING department_id>(SELECT department_id
FROM hrdb.`employees` WHEREfirst_name="Bruce");
4)、子查询操作符 ALL 的用法
-- 说明:
ALL 操作符有三种用法:
-- <>ALL(子查询语句):等价于 NOT IN() -- >ALL (子查询语句):比子查询中最大的值还要大
-- <ALL (子查询语句):比子查询中最小的值还要小
-- 特别说明:“= All”不存在
语法:
SELECT 字段 1 FROM 库名.表名
WHERE 字段1 关系运算符 all(SELECT 字段1 FROM 库名.表名 WHERE 字段2 关系运
算符 字段值);
举例:查询工资与 job_id 为 IT_PROG 的职位中所有人工资都不同的人员姓名、工资
(<>ALL 与任何一个都不相等)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary <> ALL(SELECT salary FROM hrdb.employees WHERE
job_id="IT_PROG");
举例:查询工资比 job_id 为 IT_PROG 的职位中所有人工资都要高的人员姓名、工资(>ALL
比最大的大)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary > ALL(SELECT salary FROM hrdb.employees WHEREjob_id="IT_PROG");
举例:查询工资比 job_id 为 IT_PROG 的职位中所有人工资都要低的人员姓名、工资( <ALL
比最小的小)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary < ALL(SELECT salary FROM hrdb.employees WHERE
job_id="IT_PROG");
5)、子查询操作符 ANY 的用法
-- = ANY[子查询语句]:与子查询中的数据任何一个相等
-- >ANY [子查询语句]: 比子查询中的数据最低的高 -- 比最小的大
-- <ANY[子查询语句]: 比子查询中的数据最高的低 -- 比最大的小
举例:查询工资与 job_id 为 IT_PROG 的职位中所有人工资相等的人员姓名、工资(=ANY 与
任何一个相等)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary = any(SELECT salary FROM hrdb.employees WHERE
job_id="IT_PROG");
举例:查询工资比 job_id 为 IT_PROG 的职位中最低工资高的人员姓名、工资(>ANY 比最
低的高)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary > ANY(SELECT salary FROM hrdb.employees WHERE
job_id="IT_PROG");
举例:查询工资比 job_id 为 IT_PROG 的职位中最高工资低的人员姓名、工资(<ANY 比最高的低)
SELECT first_name,last_name,salary FROM hrdb.employees
WHERE salary < ANY(SELECT salary FROM hrdb.employees WHERE
job_id="IT_PROG")















 435
435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









