








以犬夜叉为例,分享一下制作动态人物排序图的方法。最终的效果图如下:
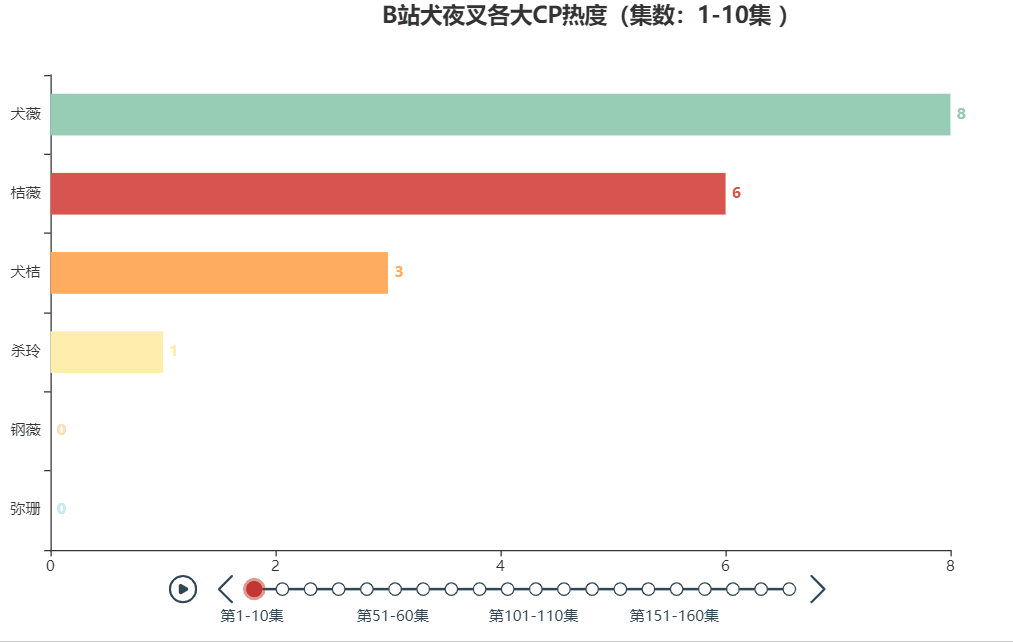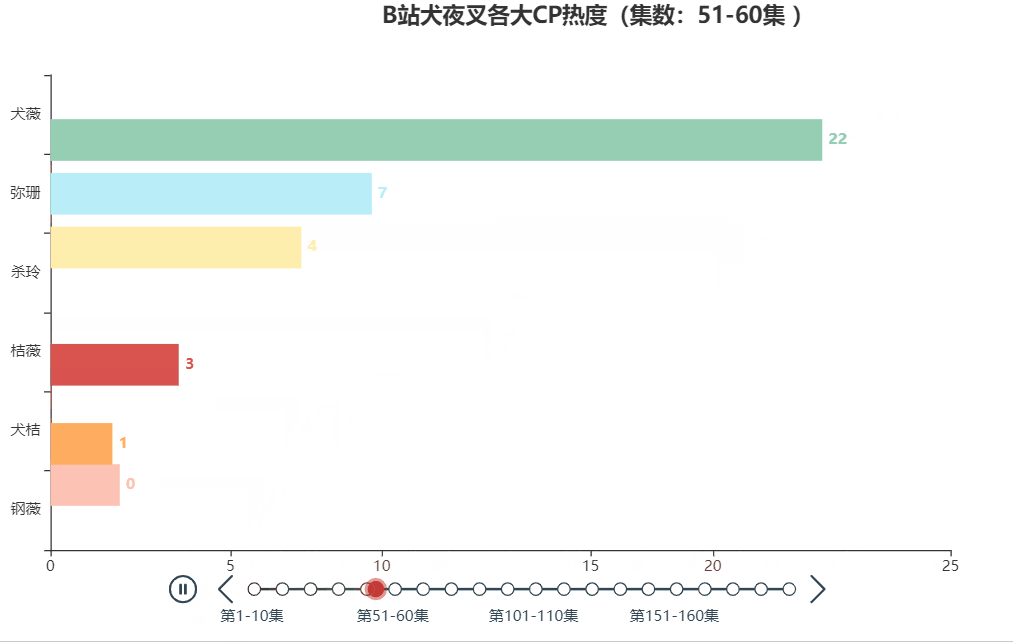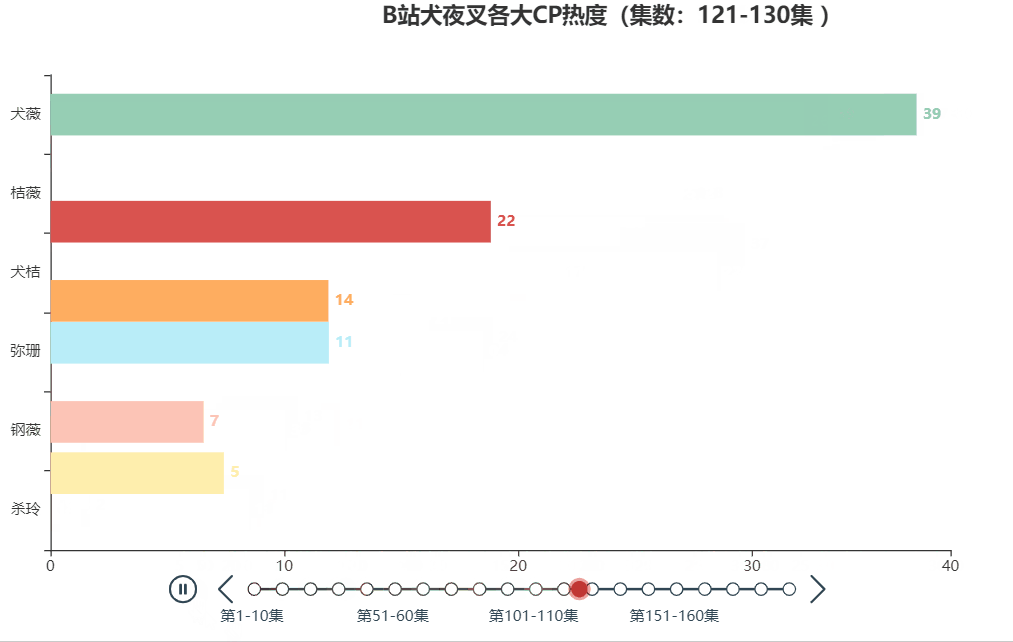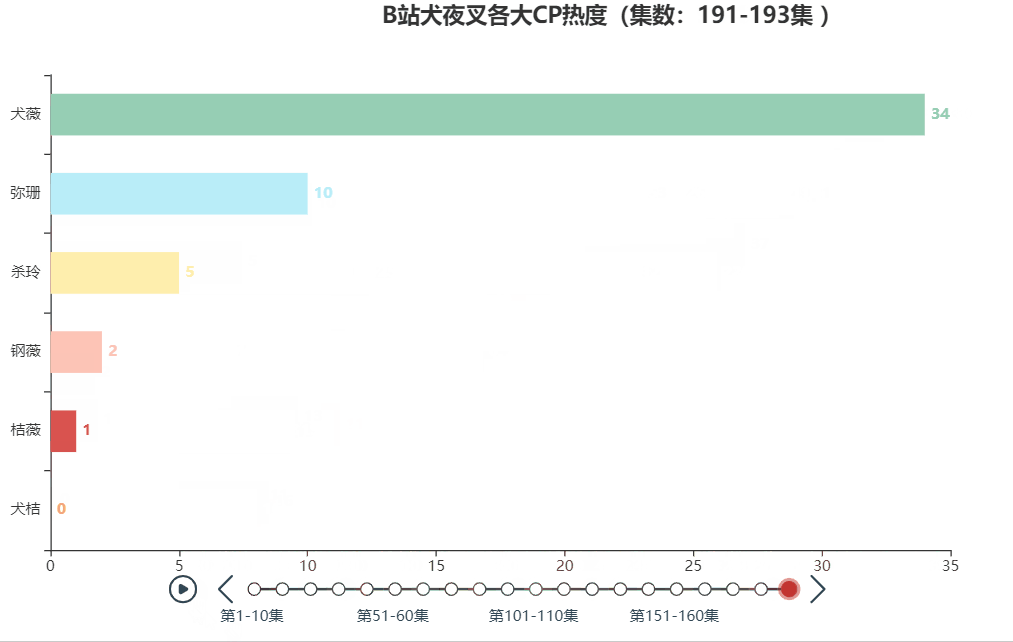
一、数据来源与处理
1.1 数据来源
本文的案例数据来自于B站犬夜叉TV版+完结版弹幕(共193话),具体爬取方法可见B站柯南弹幕爬取及可视化。通过观察弹幕的称呼习惯,可对各大CP的简称进行汇总,如下所示
| CP简称 | 具体含义 |
|---|---|
| 犬薇 | 犬夜叉和戈薇 |
| 杀玲 | 杀生丸和玲 |
| 桔薇 | 桔梗和戈薇 |
| 弥瑚 | 弥勒和珊瑚 |
| 钢薇 | 钢牙和戈薇 |
| 犬桔 | 犬夜叉和桔梗 |
统计方法同样参考之前分享的博客B站柯南弹幕爬取及可视化,将上述内容保存为role.txt即可。
1.2 集数次数合并处理
考虑到制作轮播图,时间轴不宜过长。在此,对每10集CP的讨论次数进行合并。在H2单元格输入函数=SUM(OFFSET(B$2:B$10,(ROW(A1)-1)*10,)),即实现对1-10集犬薇CP讨论次数求和,具体如下图所示
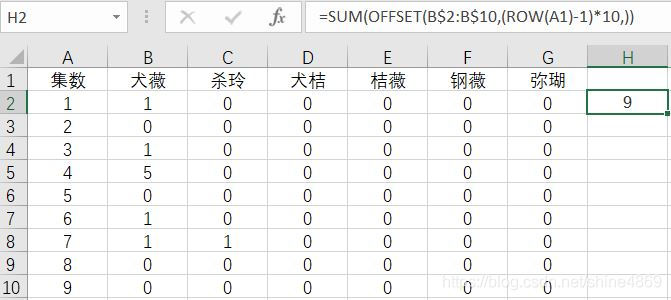
下拉填充,整理可得
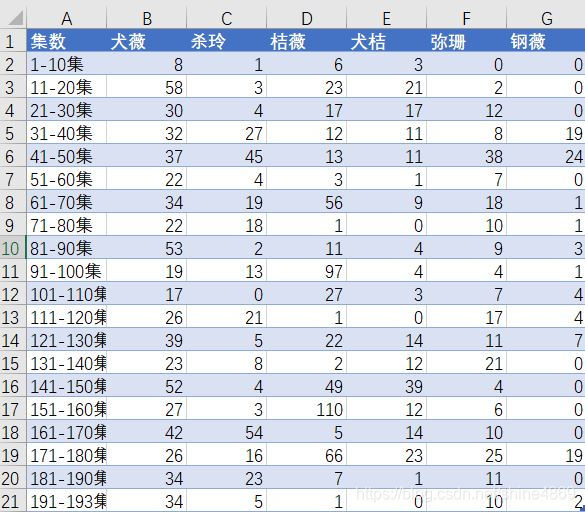
考虑后续Pyecharts作图方便,还需将此数据转为长数据格式(对除集数以外的列进行逆透视操作,具体做法可参考五分钟学会四种宽数据转长数据方法),最终数据形式如下图所示(颜色列用于后续作图区分各组CP的颜色)
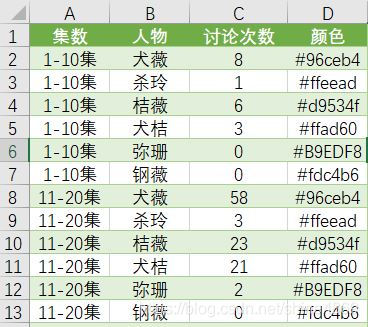
二、Pyecharts绘制时间轮播图
接下来就可以利用Pyecharts进行作图啦,代码如下:
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
import pandas as pd
import os
os.chdir('c:/users/dell/Desktop/')
def timeline_plot(file_path,index,role,count,color,title): #index为集数,role为人物,count为讨论次数
data = pd.read_csv(file_path,encoding='gbk')
episode = list(data[index])
episode1 = list(set(data[index]))
episode1.sort(key=episode.index)
tl = Timeline()
for ep in episode1:
data_sub = data[data[index]==ep].sort_values(by=count) #以每集各cp讨论次数进行排序
role_list = list(data_sub[role])
value_list = list(data_sub[count])
color_list = list(data_sub[color])
new_data = []
for j in range(len(set(role_list))):
new_data.append(
opts.BarItem(
name = role_list[j],
value = value_list[j],
itemstyle_opts = opts.ItemStyleOpts(color=color_list[j])
)
)
bar = (
Bar()
.add_xaxis(xaxis_data=role_list)
.add_yaxis(series_name='', yaxis_data=new_data , label_opts = opts.LabelOpts(position="right",font_weight="bold"),category_gap=30)
.reversal_axis()
.set_global_opts(
title_opts = opts.TitleOpts(title.format(ep),pos_left=350)
)
)
tl.add(bar, "第{} ".format(ep))
tl.add_schema(play_interval=1000, is_loop_play=False) #play_interval播放速度/ms,is_loop_play是否重复播放
tl.render("timeline_counts.html")
timeline_plot('c:/users/dell/Desktop/cp_count.csv','集数','人物','讨论次数','颜色',"B站犬夜叉各大CP热度(集数:{} )" )
更多详细的参数设置可参考Pyecharts官方文档
本文案例数据链接如下
链接:https://pan.baidu.com/s/1VcKqbBsg4kn7kHIcw8W9EA
提取码:u3n5
以上就是本文分享的全部内容~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









