







分布式缓存是分布式系统面对高并发高性能要求的关键组件。缓存可以极大的减轻db的访问压力,当然缓存涉及到分布式要考虑的问题也很多,主要有:更新模式、失效机制、淘汰策略、常见问题(缓存穿透、缓存击穿、缓存雪崩)等。
缓存解决的问题:
- 提升访问性能,redis、memcached等的访问效率明细比关系型db的访问效率高出一个数量级。
- 缓解db压力,缓存能够过滤掉大部分频繁访问的数据,极大缓解db压力。
适用场景:
- 对于性能要求高,比如一些秒杀活动场景。
- 对于数据实时性要求不高,对一些读多写少的数据,适用缓存就很有必要。
一、缓存的更新模式
现在主流的缓存的更新模式有以下三种:
-
Cache Aside:缓存更新时先更新数据库,然后在让缓存失效。
-
Read/Write Through:先更新缓存,缓存负责同步更新数据库。
-
Write Behind Caching:先更新缓存,缓存定时异步更新数据库。
1、Cache Aside 模式(重点,主流)
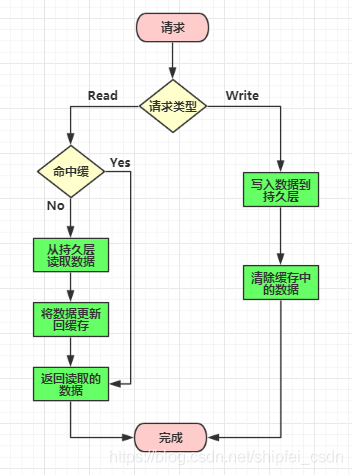
Cache Aside模式是目前最主流的缓存模式(缓存更新时先更新数据库,然后在让缓存失效),具体流程如下:
- 命中:应用程序从 cache 中取数据,取到后返回。
- 失效:应用程序先从 cache 取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
代码示例,
// Read
data = cache.get(id);
if (data == null) {
data = db.get(id);
cache.put(id, data);
}
// Write
db.save(data);
cache.invalid(data.id);
注意我们上面所提到的,缓存更新时先更新数据库,然后在让缓存失效。那么为什么不是直接更新缓存呢?这里有一些缓存更新的坑,我们需要避免入坑。
常见大坑:
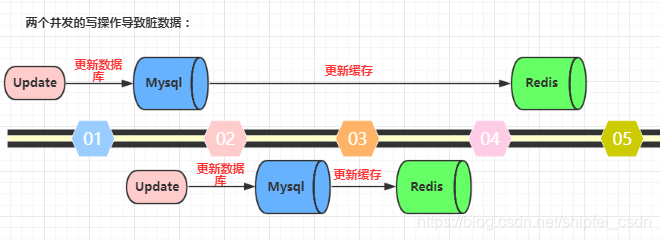
1)大坑一:先更新数据库,再更新缓存。这种做法最大的问题就是两个并发的写操作导致脏数据。如下图(以Redis和Mysql为例),两个并发更新操作,数据库先更新的反而后更新缓存,数据库后更新的反而先更新缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是脏数据。
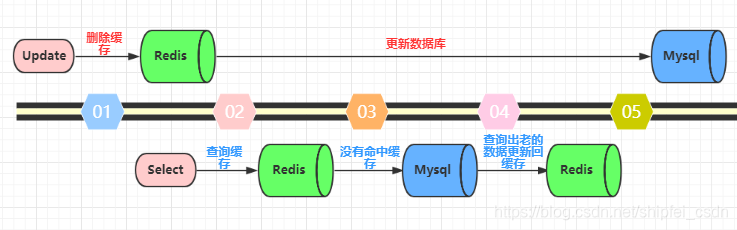
2)大坑二:先删除缓存,再更新数据库。这个逻辑是错误的,因为两个并发的读和写操作导致脏数据。如下图(以Redis和Mysql为例)。假设更新操作先删除了缓存,此时正好有一个并发的读操作,没有命中缓存后从数据库中取出老数据并且更新回缓存,这个时候更新操作也完成了数据库更新。此时,数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
3)大坑三:先更新数据库,再删除缓存。这种做法其实不能算是坑,在实际的系统中也推荐使用这种方式。但是这种方式理论上还是可能存在问题。如下图(以Redis和Mysql为例),查询操作没有命中缓存,然后查询出数据库的老数据。此时有一个并发的更新操作,更新操作在读操作之后更新了数据库中的数据并且删除了缓存中的数据。然而读操作将从数据库中读取出的老数据更新回了缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
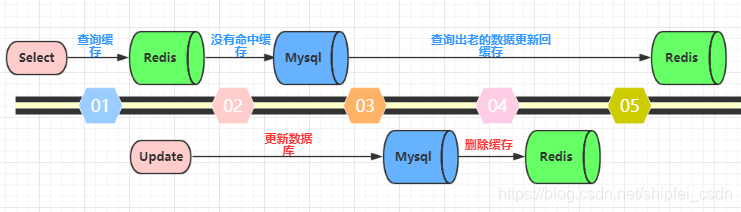
但是,仔细想一想,这种并发的概率极低。因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。但是为了避免这种极端情况造成脏数据所产生的影响,我们还是要为缓存设置过期时间。
2、Read/Write Through 模式
在Read/Write Through 模式中,缓存代理了DB读取、写入的逻辑,可以把缓存看成唯一的存储。先更新缓存,缓存负责同步更新数据库。
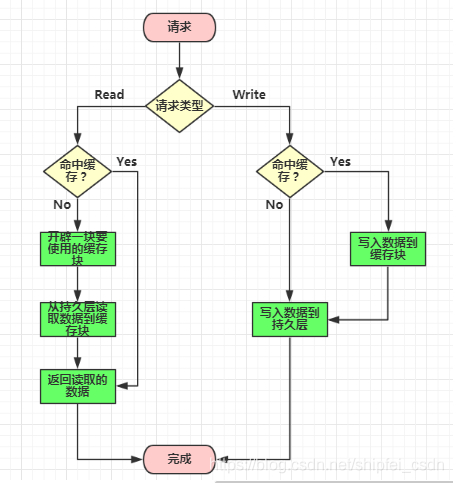
1)Read Through
Read Through 模式就是在查询操作中更新缓存,也就是说,当缓存失效的时候,Cache Aside 模式是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载。
2)Write Through
Write Through 模式和 Read Through 相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库(这是一个同步操作)。
3、Write Behind Caching模式
这种模式下所有的操作都走缓存,缓存里的数据再通过异步的方式同步到数据库里面。所以系统的写性能能够大大提升。
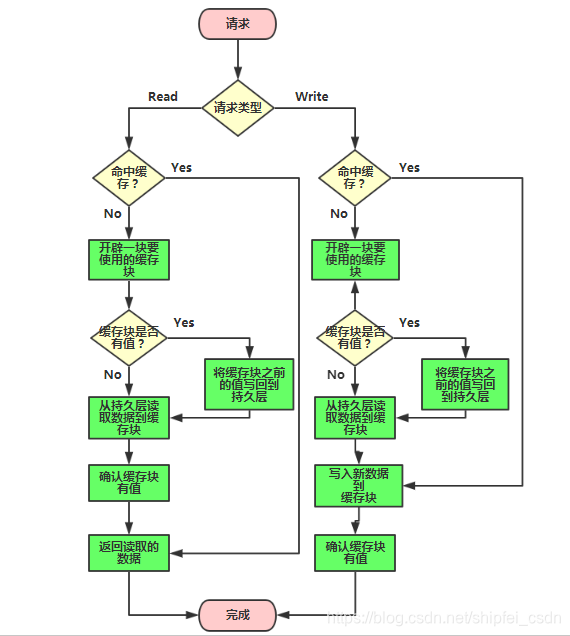
三种模式总结:
- Cache Aside 更新模式实现起来比较简单,但是需要维护两个数据存储,一个是缓存(Cache),一个是数据库。Read/Write Through 更新模式只需要维护一个数据存储(缓存),但是实现起来要复杂一些。
- Write Behind Caching 更新模式和Read/Write Through 更新模式类似,区别是Write Behind Caching 更新模式的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。优点是直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
- 缓存是通过牺牲强一致性来提高性能的。所以使用缓存提升性能,就是会有数据更新的延迟。这需要我们在设计时结合业务仔细思考是否适合用缓存。然后缓存一定要设置过期时间,这个时间太短太长都不好,太短的话请求可能会比较多的落到数据库上,这也意味着失去了缓存的优势。太长的话缓存中的脏数据会使系统长时间处于一个延迟的状态,而且系统中长时间没有人访问的数据一直存在内存中不过期,浪费内存。
二、缓存的失效机制
一般而言,缓存系统中都会对缓存的对象设置一个超时时间,避免浪费相对比较稀缺的缓存资源。对于缓存时间的处理有两种,分别是主动失效和被动失效。
1、主动失效
主动失效是指系统有一个主动检查缓存是否失效的机制,比如通过定时任务或者单独的线程不断的去检查缓存队列中的对象是否失效,如果失效就把他们清除掉,避免浪费。主动失效的好处是能够避免内存的浪费,但是会占用额外的CPU时间。
2、被动失效
被动失效是通过访问缓存对象的时候才去检查缓存对象是否失效,这样的好处是系统占用的CPU时间更少,但是风险是长期不被访问的缓存对象不会被系统清除。
三、缓存的淘汰策略
缓存淘汰,又称为缓存逐出,是指在存储空间不足的情况下,缓存系统主动释放一些缓存对象获取更多的存储空间。对于大部分内存型的分布式缓存(非持久化),淘汰策略优先于失效策略,一旦空间不足,缓存对象即使没有过期也会被释放。一般LRU用的比较多,可以重点了解一下。
1、LRU
最近最久未使用(Least Recently Used),这种策略是根据访问的时间先后来进行淘汰的,如果空间不足,会释放最久没有访问的对象(上次访问时间最早的对象)。比较常见的是通过优先队列来实现。
2、LFU
最近最少使用(Least Frequently Used),这种策略根据最近访问的频率来进行淘汰,如果空间不足,会释放最近访问频率最低的对象。这个算法也是用优先队列实现的比较常见。
3、FIFO
先进先出(First In First Out)是一种简单的淘汰策略,缓存对象以队列的形式存在,如果空间不足,就释放队列头部的(先缓存)对象。一般用链表实现。
四、缓存穿透、缓存击穿、缓存雪崩
1、缓存穿透
描述:查询DB中不存在数据,频繁穿过缓存直接查询DB,造成DB的压力。一般是网络攻击。
解决方案:
- 接口层增加校验,比如用户鉴权校验,id做基础校验,id<=0的直接拦截。
- 数据库中不存在的数据,也把对应的key写入缓存,设置较短的有效时间(如30s)防止攻击用户反复用同一个id暴力攻击。或者放入一个特殊对象(比如特定的无效对象,当然比较好的方式是使用包装对象)。
# 我们先看看最简单的青铜姿势
value = cache.get(key)
if value is None:
value = db.get(key)
# 由于value为空,实际上缓存并没有写进去,一旦这个key成为热点,db的压力将会极大
cache.put(key, value, expire)
return value
else:
return value
# 简单优化一下,升级成为白银姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
value = db.get(key)
# 即使是空对象也通过包装对象放到缓存,当然考虑到空间还可以采用特殊值(比如-1代表不存在)的方式
cache.put(key, wrapped_value(value), expire)
return wrapped_value.value
else:
return wrapped_value.value
2、缓存击穿
描述:在缓存失效的瞬间大量请求,造成DB的压力瞬间增大。
解决方案:
- 缓存更新时使用分布式锁锁住服务,防止请求穿透直达DB(主要)。
- 设置热点数据永不过期。
# 白银姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
value = db.get(key)
# 在写入缓存之前,大量的请求突然涌入,db瞬间被打垮
cache.put(key, wrapped_value(value), expire)
return wrapped_value.value
else:
return wrapped_value.value
# 在白银姿势的基础上我们再优化成黄金姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
# 查db之前加一把锁
while wrapped_value is None:
if try_lock(key):
value = db.get(key)
cache.put(key, wrapped_value(value), expire)
return wrapped_value.value
else:
# 等待10毫秒之后重试
sleep(0.01)
wrapped_value = cache.get(key)
return wrapped_value.value
else:
return wrapped_value.value
3、缓存雪崩
描述:大批量缓存设置了相同的失效时间,同一时间失效,造成服务瞬间性能急剧下降。(缓存雪崩是大量缓存键到期,缓存击穿少数或单一的缓存键到期)
解决方案:
- 设置缓存过期时间为随机时间(主要)。
- 设置热点数据永不过期。
- 缓存分布式部署,将热点数据均匀分布在不同搞得缓存数据库中。
# 通过随机失效时间登上王者姿势
wrapped_value = cache.get(key)
if wrapped_value is None:
# 查db之前加一把锁
while wrapped_value is None:
if try_lock(key):
value = db.get(key)
# 嗯,就是一个随机失效时间,最好是在某个区间
cache.put(key, wrapped_value(value), random_expire())
return wrapped_value.value
else:
# 等待10毫秒之后重试
sleep(0.01)
wrapped_value = cache.get(key)
return wrapped_value.value
else:
return wrapped_value.value
五、缓存设计时几个需要关注的点
1、不要把所有的数据都加载到缓存中。
所有的数据都加载到缓存中没有必要,因为频繁访问的数据就可能在20%左右。内存要比磁盘贵多了。
2、缓存需要有一个失效机制。
任何数据都有过期时间的,所以缓存需要有一个失效机制。失效时长需要有一个衡量,太长或者太短都不行,太长会导致数据不一致,并且太久没人访问的数据也会缓存起来,耗费内存资源,太短会导致缓存组件的效率降低。一般可以采取LRU机制,即把最不活跃长时间没有访问的数据清除出缓存。
3、缓存的代价是牺牲了数据的强一致性。
任何方案都会有代价的,使用缓存时需要关注业务的特点,有些需要数据强一致性的业务不适合用缓存。















 1467
1467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









