







正则表达式
正则表达式学习
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
用来匹配一段特殊字符
常用正则符号:
^, $, . , * , | , (),(前面几个是基础的) +, ?, [],{}
命令加上 -r 之后表示拓展的正则,这样可以支持以上所有的正则符号,否则,只支持前几个基础的
^ 匹配开头
$ 匹配以某个字符结尾的字符
. 代表任意一个字符
星号(*) 代表前面一个字符出现了0次或者无限次{0,}
| 代表or 的意思(多次匹配)
{}代表字符出现的次数
()强制把多个字符匹配一个字符,括号内是一个字符
加号 + 前面一个字符出现了至少1次或者无限次
问号 ? 表示前面一个字符出现了 1次或者0次{0,1}
[]中括号表示范围匹配eg.a-z,1-9,A-Z 也是只能匹配第一个字符
[1-9a-zA-Z]
\w 匹配数字 大小写字母
以上两种方式一样
\d 匹配数字
\ 转义字符 反斜杠
匹配一些关键字的符号,使用转义字符
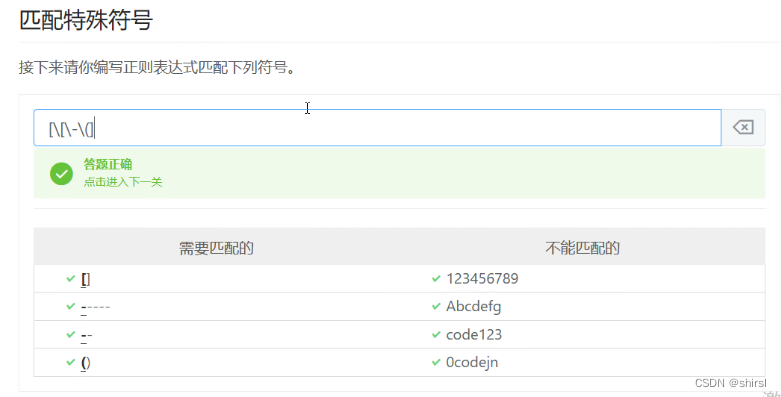
取反 ^
这个 ^ 必须在中括号里面。
可以通过在字符数组开头使用 ^ 字符实现取反操作,从而可以反转一个字符组(意味着会匹配任何指定字符之外的所有字符)。
比如:这里的 n[^e] 的意思就是n后面的字母不能为 e。但是这里的n必须是存在的。
建表(表名)的规范
长度不能超过30
不能有关键字
必须是大小写字母和0-9 -

记得是小写的w和d
大写的W D是取反。比如\W 匹配除了数字。字母以及_ 的其他都可以匹配。
\s快捷方式可以匹配空白字符,比如空格,tab、换行等。
grep 全局正则搜索
sed 流编辑器
awk 文本格式化工具
grep “想要查找的内容” 文件名
两个引号嵌套的时候 外单内双
grep -n (可以放到最后,也可以放到grep 后面) 可以输出内容的同时输出行号
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" zz.txt
oracle
oracle12c
oracle20c
oracle11g
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" zz.txt -n
1:oracle
6:oracle12c
7:oracle20c
8:oracle11g
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt
1:oracle
6:oracle12c
7:oracle20c
8:oracle11g
[root@iZ8vbgw05auetj737q3v9rZ yx]#
grep -i 忽略大小写
grep -n “oracle” zz.txt -i
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt
1:oracle
6:oracle12c
7:oracle20c
8:oracle11g
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt -i
1:oracle
6:oracle12c
7:oracle20c
8:oracle11g
10:ORACLE10g
grep -o 只匹配想要的字符 only
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt -o
1:oracle
6:oracle
7:oracle
8:oracle
grep -c 匹配行数 count
grep -c 匹配行数 count
不能用来判断个数
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt -c
4
以o开头,只匹配o
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "^o" zz.txt -o
1:o
6:o
7:o
8:o
9:o
grep -q 静默模式,使用echo $?
0代表有结果,1代表没有结果
-q 没有任何返回结果但是可以跟echo $?配合使用
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt -q
echo $?返回上一条命令是否有结果
[root@iZ8vbgw05auetj737q3v9rZ yx]# echo $?
0
[root@iZ8vbgw05auetj737q3v9rZ yx]#
grep -v 取反 只显示不满足匹配条件的行,包括空行
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "oracle" zz.txt -v
2:mysql
3:teradata
4:hive
5:cdh
9:oarcle12c
10:ORACLE10g
11:HIVE
12:MYSQL 5.8
13:
grep -E 使grep命令支持扩展正则 等于egrep
找出空行
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "^$" zz.txt
13:
[root@iZ8vbgw05auetj737q3v9rZ yx]#
去除空行
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -n "^$" zz.txt -v
1:oracle oracle oracle
2:mysql
3:teradata
4:hive
5:cdh
6:oracle12c
7:oracle20c
8:oracle11g
9:oarcle12c
10:ORACLE10g
11:HIVE
12:MYSQL 5.8
找出字符长度大于10的行(包括空行)
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep ".{10,}" zz.txt -E
oracle oracle oracle
找出oracle10以上的版本
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle[1-9][0-9].*" zz.txt -E -i
oracle12c
oracle20c
oracle11g
ORACLE10g
grep -B(B后加个数字)before
找出内容的前几行
grep -A(A后加个数字) after
同时返回匹配行的后几行
grep -C(C后加个数字) context
同时返回匹配行的前后几行
以上几个命令使用注意加上-n 给个行号比较容易看
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" zz.txt -B1
oracle oracle oracle
--
cdh
oracle12c
oracle20c
oracle11g
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" zz.txt -C1
oracle oracle oracle
mysql
--
cdh
oracle12c
oracle20c
oracle11g
oarcle12c
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" zz.txt -A2 -n
1:oracle oracle oracle
2-mysql
3-teradata
--
6:oracle12c
7:oracle20c
8:oracle11g
9-oarcle12c
10-ORACLE10g
fgrep 不支持正则 但是查找最快
fast grep
文件内容
[root@iZ8vbgw05auetj737q3v9rZ yx]# cat db.dat
ORACLE10g
USER:system PASSWORD:123456
ORACLE12c
USER:system PASSWORD:qwerty
HIVE
USER:root PASSWORD:hivedb
MYSQL
USER:123456 PASSWORD:mysqldb
找出所有oracle的用户和密码
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "oracle" -A1 db.dat -i | grep "^USER"
USER:system PASSWORD:123456
USER:system PASSWORD:qwerty
找出密码为123456的数据库
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "PASSWORD:123456" -bB1 db.dat -i | grep "PASSWORD" -v
0-ORACLE10g
找出所有的数据库名称
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "USER:" db.dat -v
ORACLE10g
ORACLE12c
HIVE
MYSQL
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep "USER:" db.dat -v |grep "^$" -v| uniq | wc -l
4
大写V是查看版本 搞清楚大小写
[root@iZ8vbgw05auetj737q3v9rZ yx]# grep -V
grep (GNU grep) 2.20
Copyright (C) 2014 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>.
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Written by Mike Haertel and others, see <http://git.sv.gnu.org/cgit/grep.git/tree/AUTHORS>.
**sed 命令 **
sed 流编辑器
增删改查
a: append 追加 往下面追加
i :insert新增 往上面插入
d: delete
s: swap 替换 s/想要替换的/替换成的/g
p: print
sed -n 关闭sed 命令的默认输出
sed -i 不做输出直接修改文件里的数据
在打印的模式下sed命令会对每个元素先进行输出(这里是默认输出),然后去对比条件是否匹配,如果匹配的话再次输出,如果不匹配的话就不输出了。所以可以看到满足条件的会输出两次,而不满足条件的会输出一次。

sed -n 关闭sed 命令的默认输出
sed -i 不做输出直接修改文件里的数据
sed -r 使用拓展正则表达式
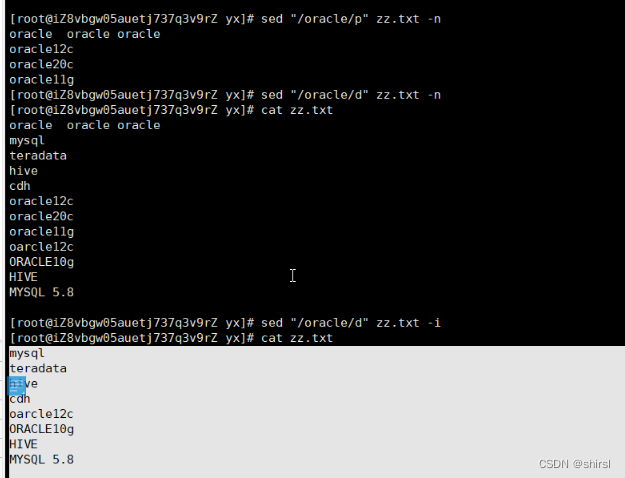
删除1行
删除1-3行
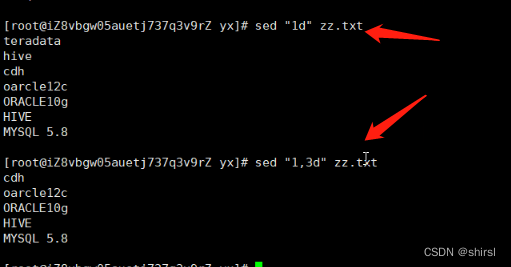
不给行的a和i模式(没有指明行号)那么则对每行都进行这样的处理。

全局替换以及局部替换
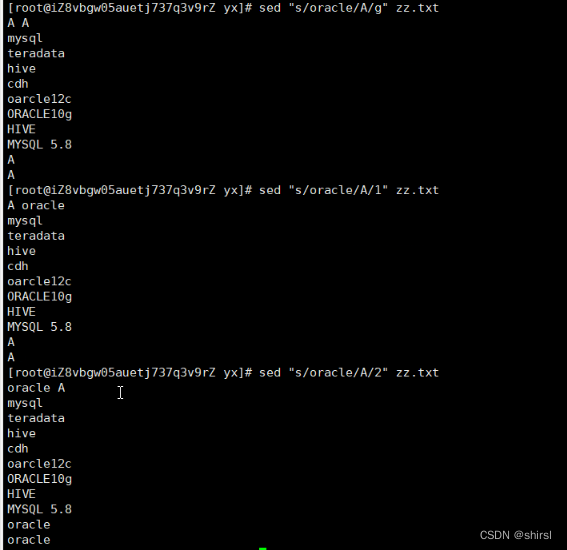
替换以o开头的几种情况
带有^符号的 sed处理的时候是一行一行对待的,把每当当做流
[root@iZ8vbgw05auetj737q3v9rZ yx]# sed "s/^[Oo]/A/g" zz.txt
Aracle oracle
mysql
teradata
hive
cdh
Aarcle12c
ARACLE10g
HIVE
MYSQL 5.8
Aracle
Aracle
[root@iZ8vbgw05auetj737q3v9rZ yx]# sed "s/^[Oo].+/A/g" zz.txt
oracle oracle
mysql
teradata
hive
cdh
oarcle12c
ORACLE10g
HIVE
MYSQL 5.8
oracle
oracle
[root@iZ8vbgw05auetj737q3v9rZ yx]# sed "s/^[Oo].*/A/g" zz.txt
A
mysql
teradata
hive
cdh
A
A
HIVE
MYSQL 5.8
A
A
[root@iZ8vbgw05auetj737q3v9rZ yx]# sed "s/^[Oo]/A/g" zz.txt
Aracle oracle
mysql
teradata
hive
cdh
Aarcle12c
ARACLE10g
HIVE
MYSQL 5.8
Aracle
Aracle
[root@iZ8vbgw05auetj737q3v9rZ yx]# sed "s/[Oo]/A/g" zz.txt
Aracle Aracle
mysql
teradata
hive
cdh
Aarcle12c
ARACLE10g
HIVE
MYSQL 5.8
Aracle
Aracle
找出IP地址
[root@iZ8vbgw05auetj737q3v9rZ yx]# ifconfig eth0 | sed "/inet/p" -n
inet 172.29.242.160 netmask 255.255.240.0 broadcast 172.29.255.255
inet6 fe80::216:3eff:fe1b:6486 prefixlen 64 scopeid 0x20<link>
如果取出的一行内容多于自己想要的,那么就把其他的内容替换为空
[root@iZ8vbgw05auetj737q3v9rZ yx]# ifconfig eth0 | sed -n "2p" |sed "s/inet//g" | sed "s/netmask.*//g" -r
172.29.242.160
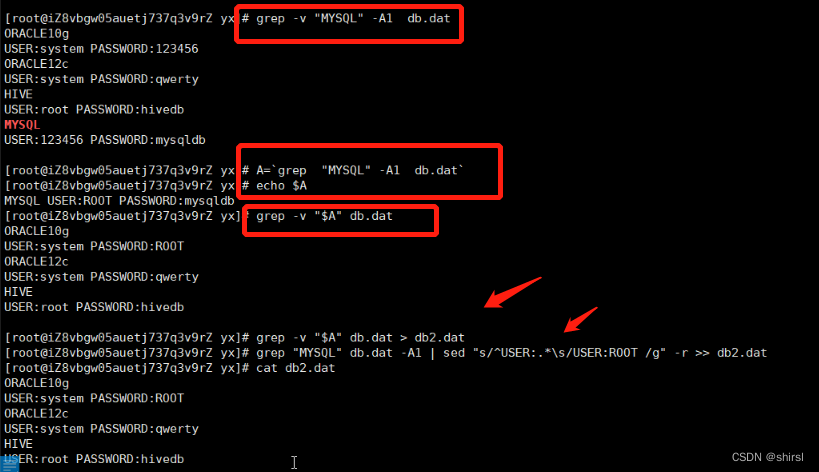
系统命令使用反引号 ` (tab键上面那个)
修改mysql 用户为root(原本的为123456) (修改mysql的用户名)
思路:
首先取出mysql下面一行也就是用户密码行,然后取反,得到除了MySQL之外的行,并把这些内容追加到db2.txt文件里面,然后将内容进行替换,也就是将123456替换为root,最后将替换的内容追加到db2.txt文件当中
管道符号不仅可以承接前面一条命令来的结果,也可以不承接,只表达一种顺序,比如下面的两条命令就没有承接关系。
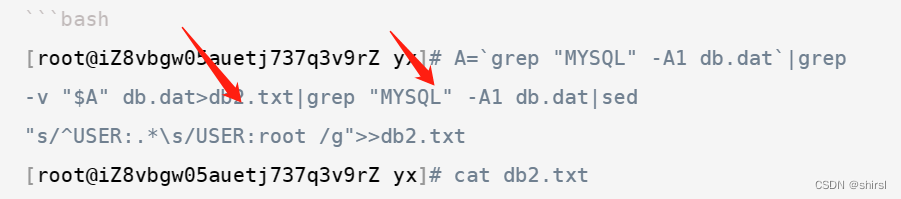
方法一:
[root@iZ8vbgw05auetj737q3v9rZ yx]# A=`grep "MYSQL" -A1 db.dat`|grep -v "$A" db.dat>db2.txt|grep "MYSQL" -A1 db.dat|sed "s/^USER:.*\s/USER:root /g">>db2.txt
[root@iZ8vbgw05auetj737q3v9rZ yx]# cat db2.txt
ORACLE10g
USER:system PASSWORD:ROOT
ORACLE12c
USER:system PASSWORD:qwerty
HIVE
USER:root PASSWORD:hivedb
方法二:
A=` grep "MYSQL" -A1 db.dat | sed "2p" -n `
B=` grep "MYSQL" -A1 db.dat | sed "2p" -n | sed "s/^USER:.*\s/USER:ROOT /g" `
sed -e "s/$A/$B/g" db.dat -i
一些总结:
LINUX三剑客:grep,sed,awk
正则表达式: ^,$,.,*,|,(),+,?,[],{}
^ 匹配以什么开始的字符
$ 匹配以什么结束的字符
. 一个任何字符
星号 * 前面一个字符出现了0次或无限次{0,}
加号 + 前面一个字符出现了至少1次或无限次{1,}
问号? 前面一个字符出现了0次或一次{0,1}
| 或者(多次匹配)
() 括号内是一个字符
[] 范围匹配 a-z,A-Z,0-9
grep 全局正则搜索
sed 流编辑器
awk 文本格式化工具
grep ‘“想要查找的内容”’ 文件名
grep -n 不仅输出匹配的行还输出所在的行号
grep -i 忽略大小写
grep -o 只匹配想要查找的字符
grep -c 返回匹配上的行数
grep -q 静默模式 , 要使用$? 接受执行结果 0 有 1 没有
grep -v 取反,只显示不满足匹配条件的行
grep -E 是grep命令支持扩展正则 等于 egrep
grep -An 同时返回匹配行的后n行
grep -Bn 同时返回匹配行的前n行
grep -Cn 同时返回匹配行的前后n行
sed 流编辑器
增删改查
a:append 追加
i:insert 新增
d:delete 删除
s:swap 替换 s/想要替换的/替换成的/g
p:print 输出
sed -n 关闭sed命令的默认输出
sed -i 不做输出直接修改文件里的数据
sed -r 使用拓展正则表达式















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









