







 本文详细介绍如何在Linux虚拟机上安装并配置Kafka集群环境,包括环境准备、Kafka安装步骤及配置修改等内容。
本文详细介绍如何在Linux虚拟机上安装并配置Kafka集群环境,包括环境准备、Kafka安装步骤及配置修改等内容。
linux虚拟机搭建Kafka集群环境
一、环境准备
-
下载Kafka 官网下载地址
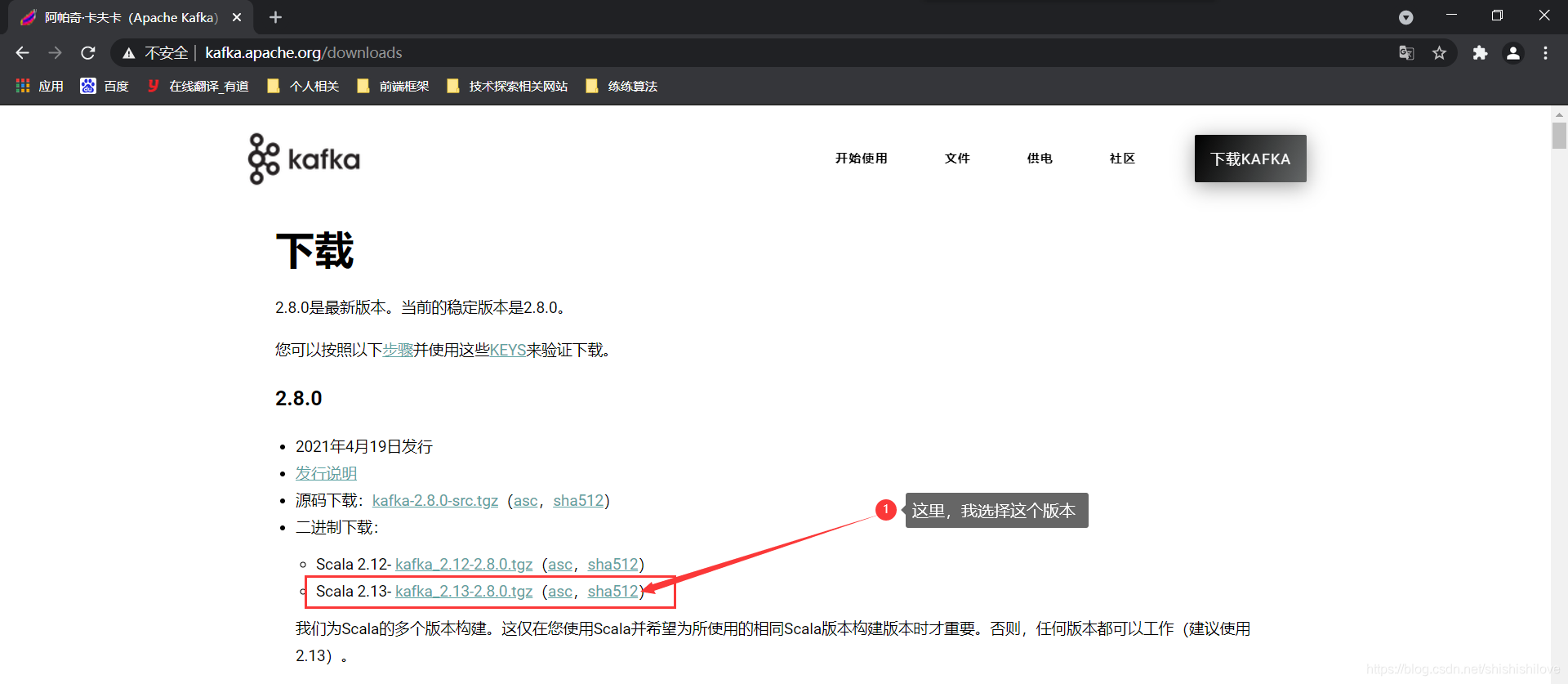
-
这里我选择安装过Zookeeper的三台服务器上,再分别安装kafka【192.168.109.100 ;192.168.109.101 ;192.168.109.102】,自己可以扩展另外一些机器来安装kafka。
一、Kafka安装
1、打开三台虚拟机
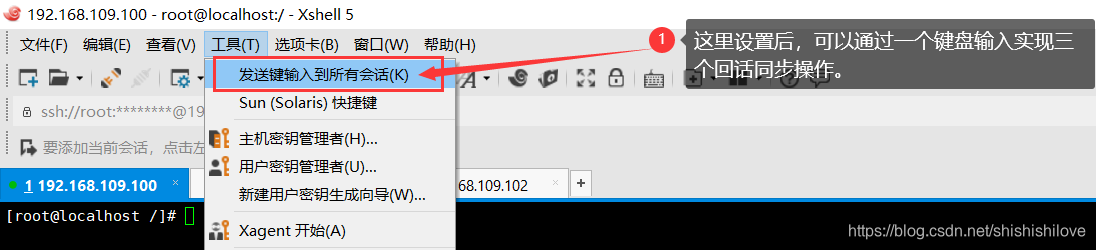
2、用Xshell连接,并选择【发送键输入到所有会话】
【发送键输入到所有会话】:意思是在一个会话中的操作,可以同步到其他会话窗口。这样只需要在一个连接机器的安装,就可实现所有连接机器的安装。
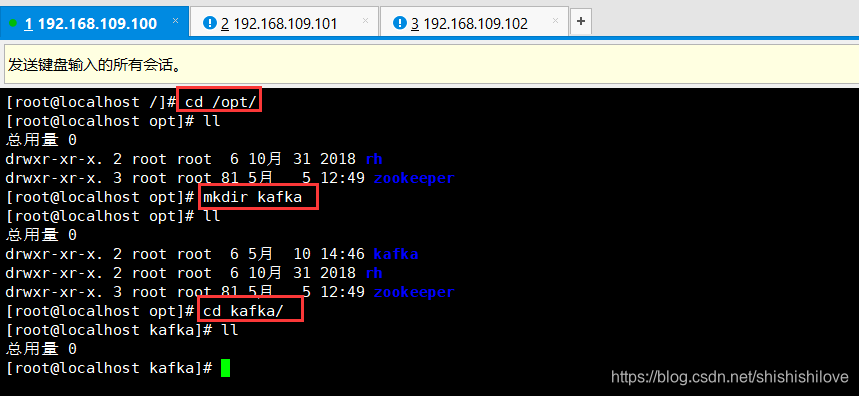
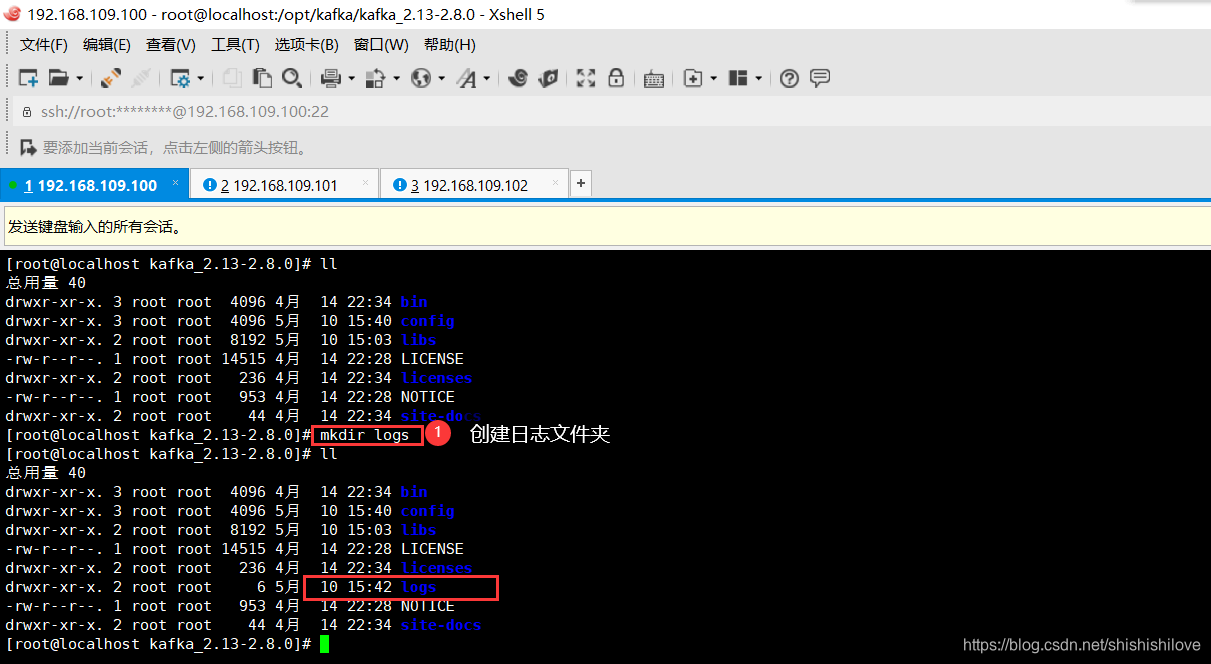
3、在【/opt】下创建kafka文件夹
******************命令如下******************
cd /opt/
mkdir kafka
cd kafka/
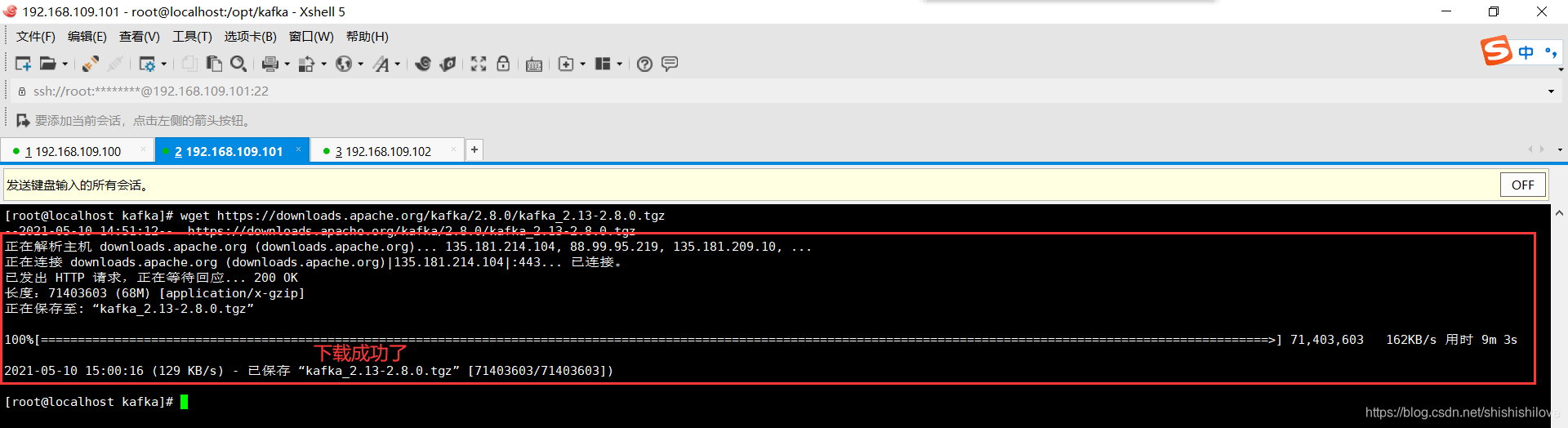
4、下载kafka 官网下载地址
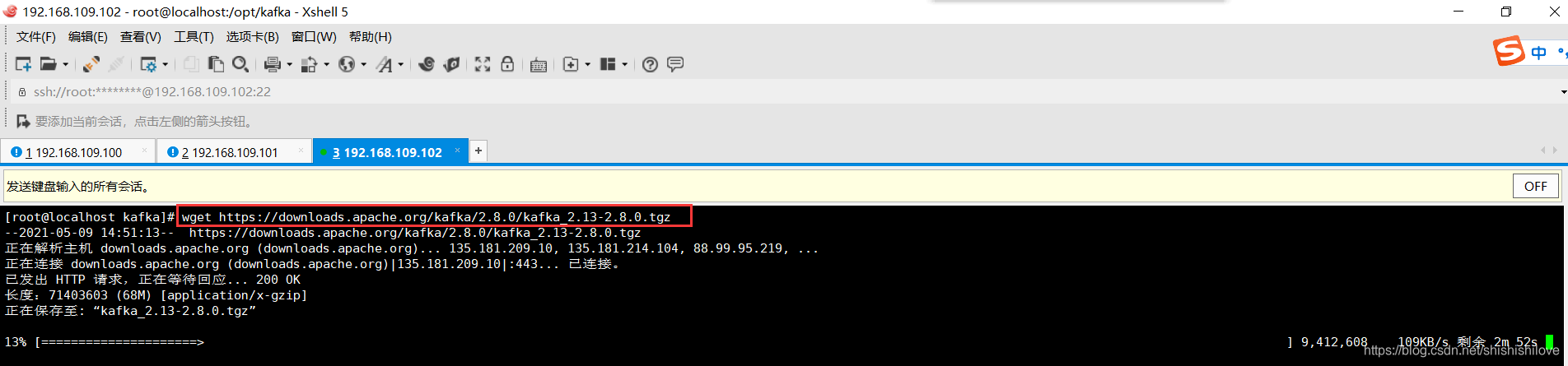
******************命令如下******************
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz
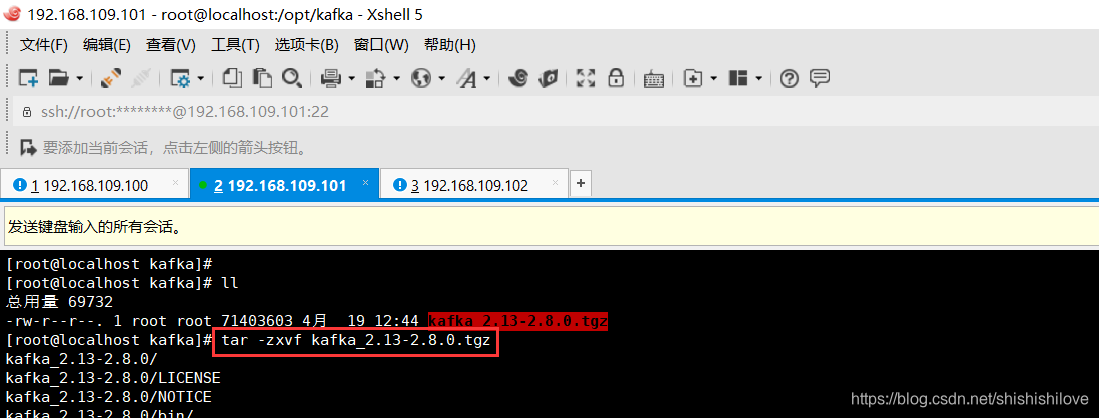
5、解压【kafka_2.13-2.8.0.tgz】
******************命令如下******************
tar -zxvf kafka_2.13-2.8.0.tgz
6、修改【server.properties】配置文件
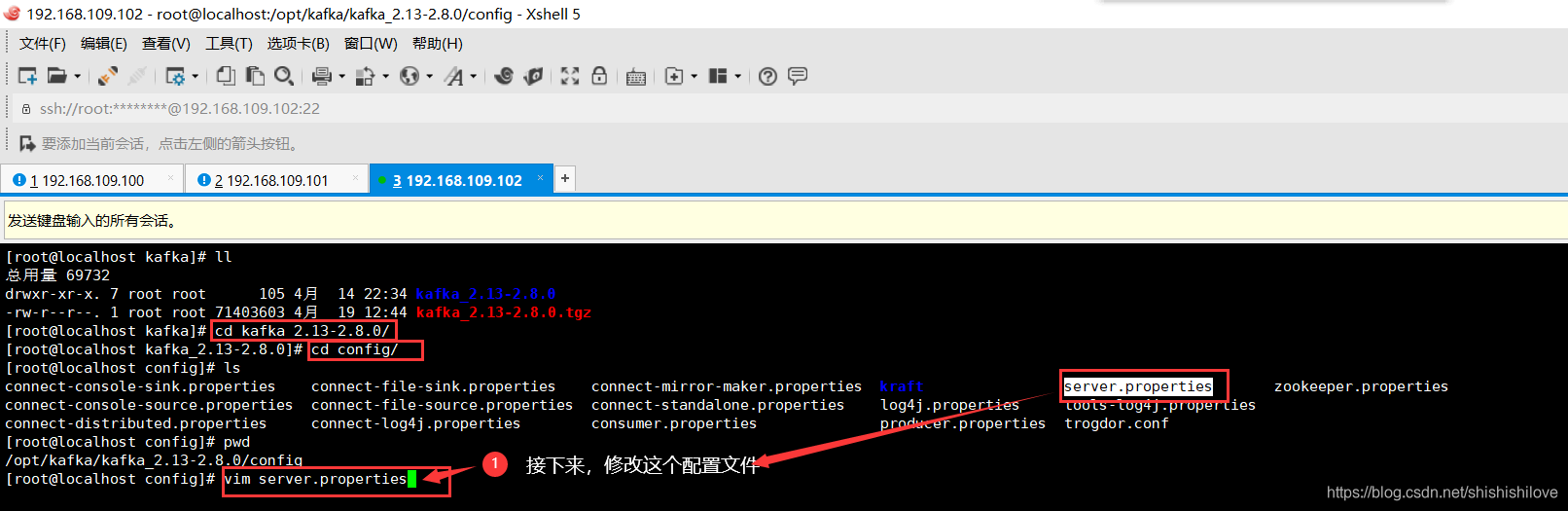
进入【/opt/kafka/kafka_2.13-2.8.0/config/】路径下。
******************命令如下******************
cd /opt/kafka/kafka_2.13-2.8.0/config/
vim server.properties
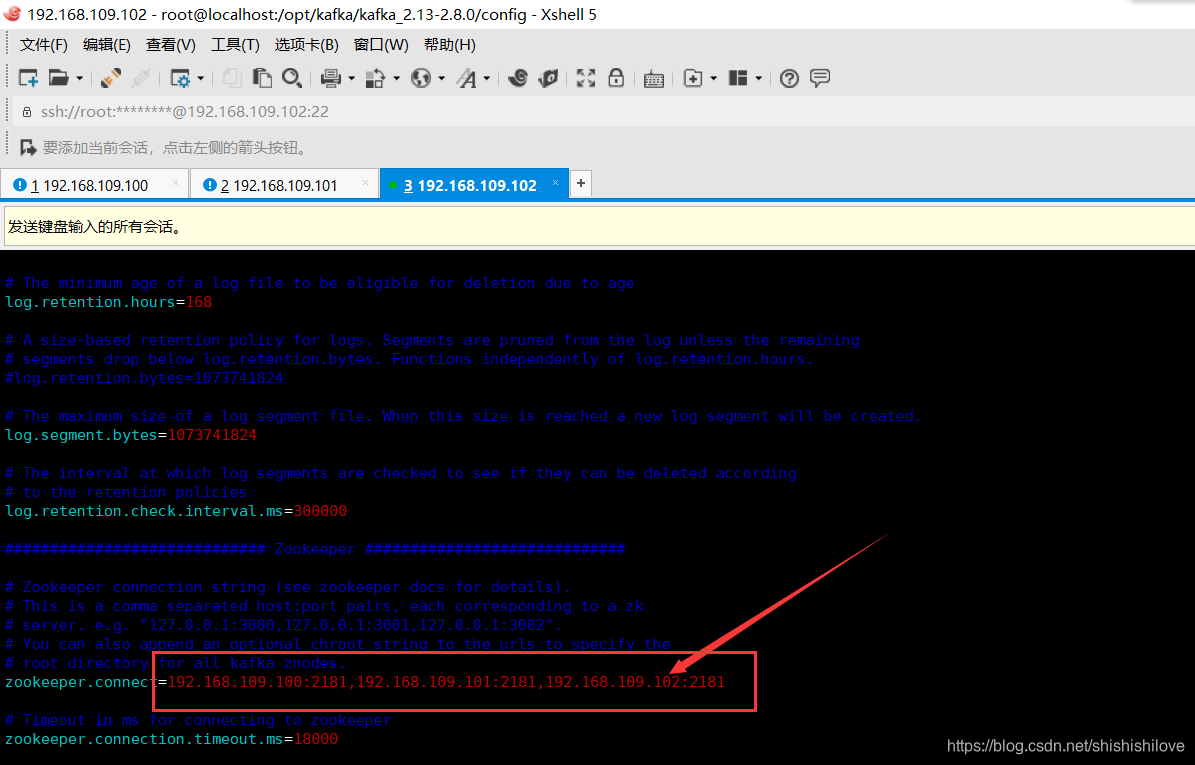
6.1、修改【zookeeper.connect】参数
【zookeeper.connect】:设置连接的zookeeper集群连接信息
******************命令如下******************
zookeeper.connect=192.168.109.100:2181,192.168.109.101:2181,192.168.109.102:2181
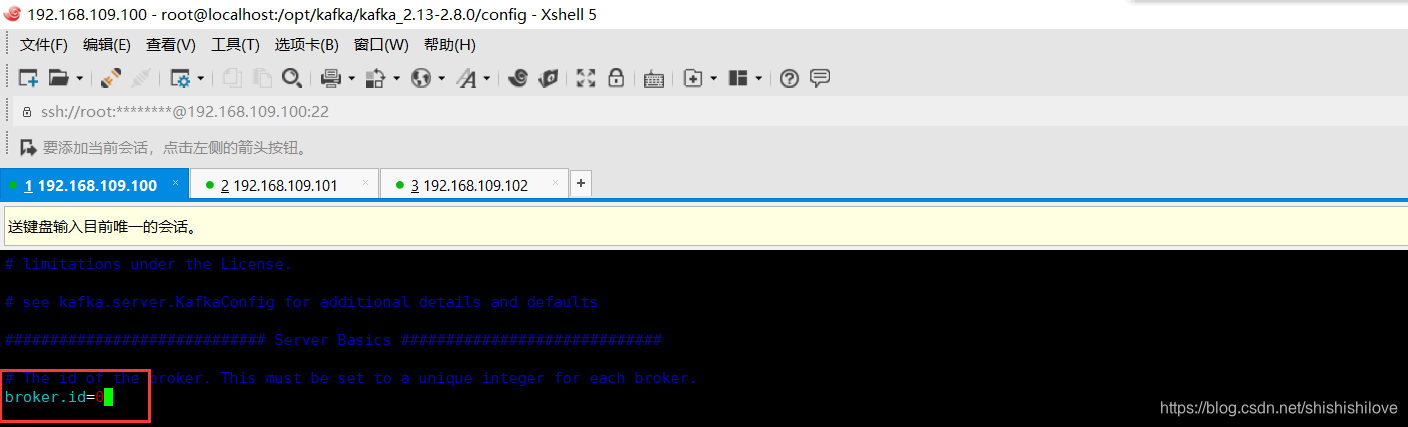
6.2、分别修改【broker.id】参数
【broker.id】: 当前机器在集群中的唯一标识,和zookeeper的myid性质一样。【不能重复】

我这里,机器[192.168.109.100],设置broker.id=0
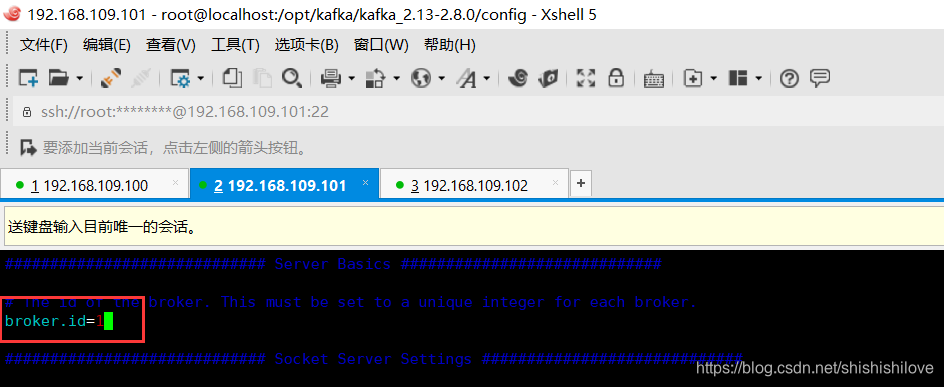
机器[192.168.109.101],设置broker.id=1
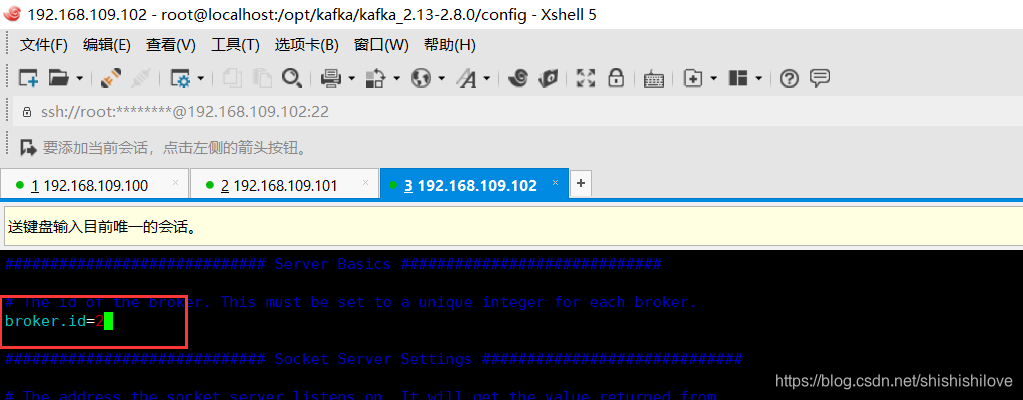
机器[192.168.109.102],设置broker.id=2
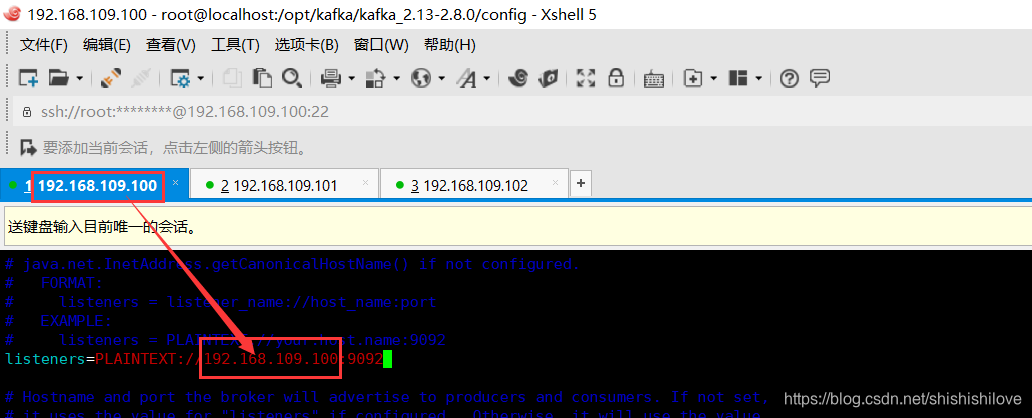
6.3、分别修改【listeners=PLAINTEXT://:9092】参数
【9092】:是kafka默认端口。这里每个机器都改成自己的ip,见如下操作:

******************修改如下******************
listeners=PLAINTEXT://192.168.109.100:9092
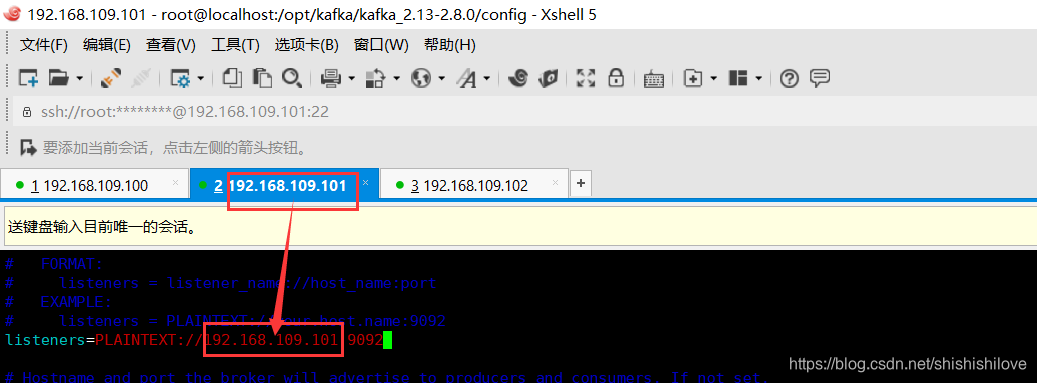
******************修改如下******************
listeners=PLAINTEXT://192.168.109.101:9092
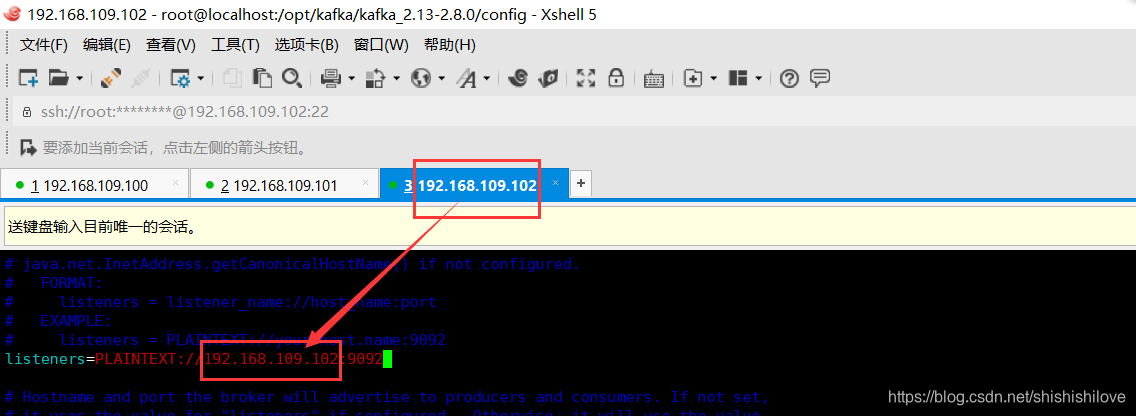
******************修改如下******************
listeners=PLAINTEXT://192.168.109.102:9092
6.4、修改【log.dirs】参数
【log.dirs】:日志存放路径,根据自己情况而定。
******************修改如下******************
log.dirs=/opt/kafka/kafka_2.13-2.8.0/logs

6.5、退出编辑,并保存
按【ESC】键退出编辑,并输入【:qw!】保存【server.properties】配置信息。
******************命令如下******************
:qw!
三、运行Kafka集群
1、运行Zookeeper集群服务
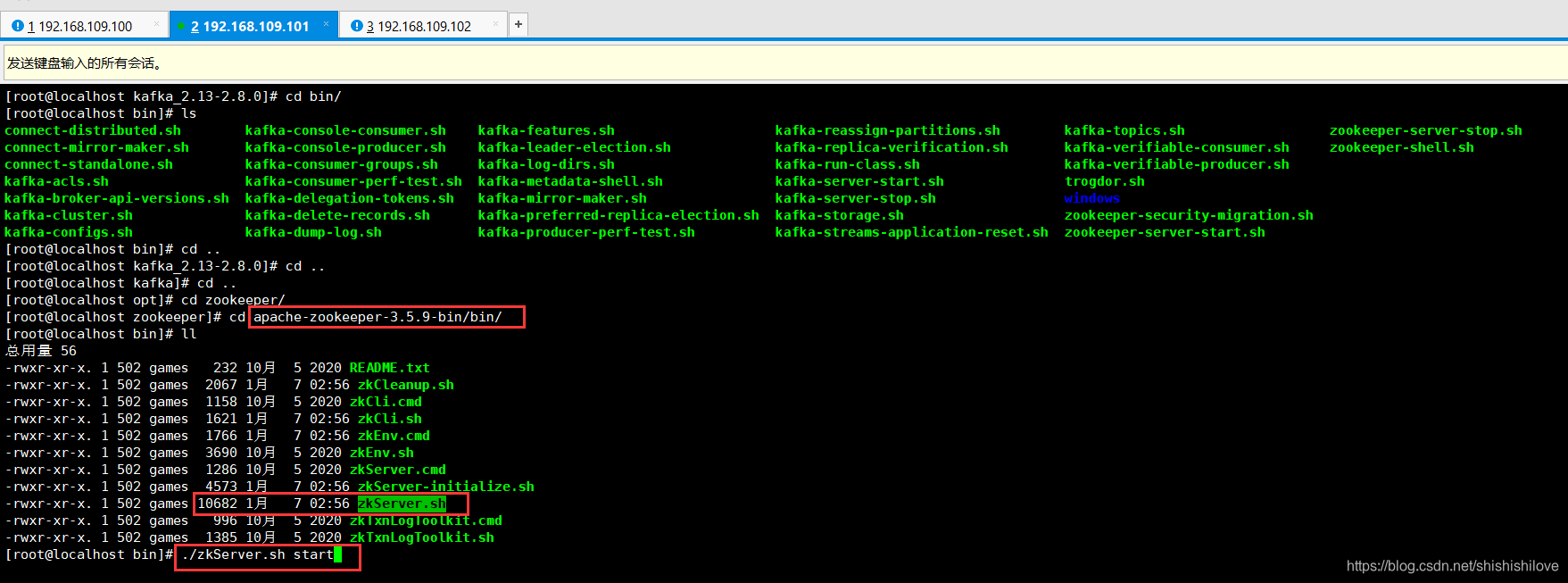
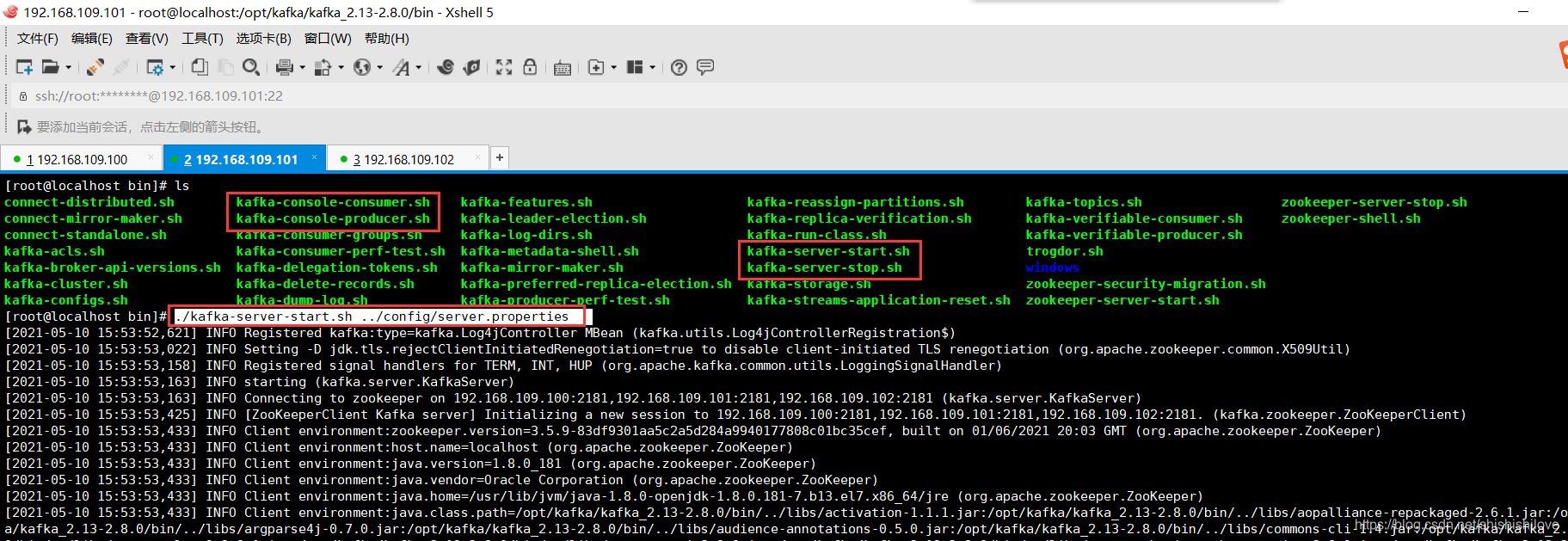
2、运行Kafka集群服务
./kafka-server-start.sh -daemon ../config/server.properties
####说明:【-daemon】守护进程方式启动,可加可不加。
【../config/server.properties】server.properties文件的相对路径
……
帮助他人,快乐自己,最后,感谢您的阅读!
所以如有纰漏或者建议,还请读者朋友们在评论区不吝指出!
个人网站…知识是一种宝贵的资源和财富,益发掘,更益分享…

















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









