







 本文详细介绍了C4.5算法在数据集上的数值计算过程,该数据集包含天气、湿度和有雨三个属性,以及玩或不玩两个类别。通过对天气属性的分析,发现其信息增益高于平均值,因此选择天气作为根节点进行划分。接着,根据天气的不同情况,如晴天、多云和雨天,进一步探讨湿度和有雨?属性对信息熵的影响,最终构建决策树进行预测。
本文详细介绍了C4.5算法在数据集上的数值计算过程,该数据集包含天气、湿度和有雨三个属性,以及玩或不玩两个类别。通过对天气属性的分析,发现其信息增益高于平均值,因此选择天气作为根节点进行划分。接着,根据天气的不同情况,如晴天、多云和雨天,进一步探讨湿度和有雨?属性对信息熵的影响,最终构建决策树进行预测。
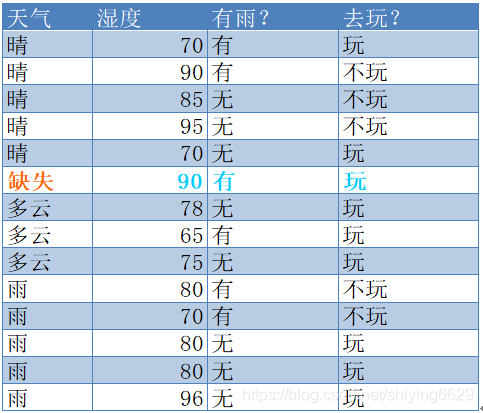
上述数据集有3个属性,属性集合A={ 天气,湿度,有雨? }, 类别标签有两个,类别集合L={玩,不玩}。
根节点包含样本集D中全部14个样例,各样例的权值均为1
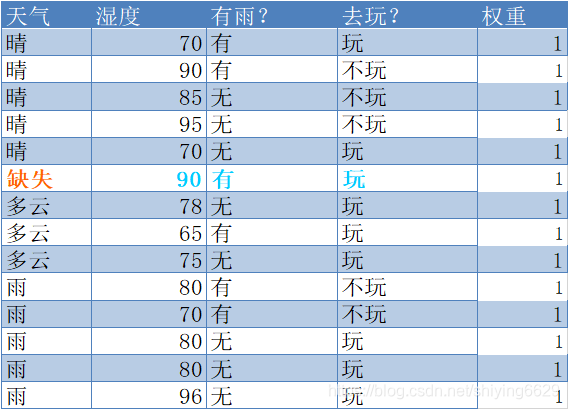
- 属性“天气”
该属性上无缺失值的样例子集D’包含13个样例即|D’|=13
|C1,D’|=5(“不玩”)
|C2,D’|=8(“玩”)
则D’的信息熵为
![]()
“晴”的有5个, 其中2个“玩”, 3个“不玩”
“多云”的有3个, 其中3个“玩”,0个“不玩”
“雨”的有5个, 其中3个“玩”, 2个“不玩”
“缺失”的有1个,其中1个“玩”,0个“不玩”
令D1’、D2’、D3’分别表示在属性“天气”上取值为“晴”、“多云”、“雨”的样本子集
按属性“天气”对D’划分后,则D’ 的信息熵为

样本集D上属性“天气”的信息增益为

2. 属性“湿度(直接以<=75和>75划分)
|D’|=14
|C1,D’|=5(“不玩”)
|C2,D’|=9(“玩”)
D’的信息熵
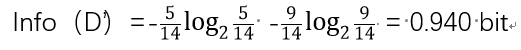
湿度“>75”的有9个, 其中5个“玩”, 4个“不玩”
湿度“<=75”的有5个, 其中4个“玩”,1个“不玩”
令D1’、D2’分别表示在属性“湿度”上取值为“>75”、“<=75”的样本子集
按属性“湿度”对D’划分后,则D’ 的信息熵
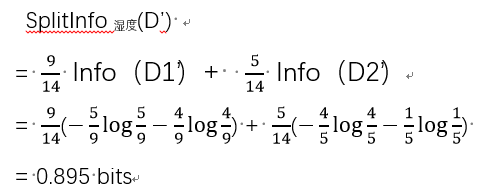
样本集D上属性“湿度”的信息增益为

3. 属性“有雨?”
|D’|=14
|C1,D’|=5(“不玩”)
|C2,D’|=9(“玩”)
D’的信息熵
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









