







目录
1.Java基本知识
1.数据类型
1.1 整形
- long类型后可加后缀 “L"或"l” 表示
- 二进制可加前缀 “0b"或"0B” 表示
- 八进制可加前缀 “0” 表示
- 十六进制可加前缀 "0x"或"0X"表示
- Java 7开始可为数字字面量加下划线使之更易读:1_000_000_000,编译器会去除
Java中没有任何无符号形式的整形
1.2 浮点类型
| 类型 | 存储需求 | 取值范围 |
|---|---|---|
| float | 4字节 | 大约3.402 823 47E+38F (有效位数为6~7位) |
| double | 8字节 | 大约1.797 693 134 862 315 70E+308 (有效位数为15位) |
- double表示双精度,一般都采用double类型,除非需要单精度的库或需要存储大量数据
- float类型后加后缀 “F"或"f” 表示;无后缀的默认为double类型
可用十六进制表示浮点数值,用p表示指数,而不是e
下面是表示溢出和出错情况的三个特殊的浮点数值 (实际开发中很少用到):
| Double.POSITIVE_INFINITY | Double.NEGATIVE_INFINITY | Double.NaN |
|---|---|---|
| 正无穷大 | 负无穷大 | NaN(不是一个数字) |
可以使用Double.isNaN方法检查是不是一个数字
1.3char 类型
- 表示单个字符;也可以用一个或两个char表示Unicode字符
特殊字符的转义序列:
| 转义序列 | 名称 | Unicode值 |
|---|---|---|
| \b | 退格 | \u0008 |
| \t | 制表 | \u0009 |
| \n | 换行 | \u000a |
| \r | 回车 | \u000d |
| \’’ | 双引号 | \u0022 |
| \’ | 单引号 | \u0027 |
| \\ | 反斜杠 | \u005c |
Unicode转义序列会在解析代码之前得到处理
1.4 boolean类型
- boolean类型有两个值:true、false
- 整形值和布尔值之间不能进行相互转换
2. 变量
- 变量名必须是一个以字母开头 并由字母或数字构成的序列,字母包括Unicode字符
- 可以使用Character类的isJavaIdentifierStart和isJavaIdentifierPart方法来检查是否为Unicode字符
2.1 常量
- 常量用关键字 final 表示,常量名全大写
- final 表示这个变量只能被赋值一次,而后不能更改
- 类常量:可以在一个类的多个方法中使用,定义在main方法外部,可以使用关键字static final表示
3. 运算符
- 整数被0除将会产生异常,浮点数被0除将会得到 无穷大 或 NaN 的结果
3.1 Math数学函数与常量
- sqrt(x):平方根
- pow(x, a):乘方
- Math.PI:
- Math.e:e常量的近似值
- floor: 返回不大于的最大整数
- round: 表示“四舍五入”,算法为Math.floor(x+0.5),即将原来的数字加上0.5后再向下取整。(正数小数点后大于5则进位;负数小数点后小于以及等于5都舍去,大于5的则进位)
- ceil: 不小于它的最小整数
floorMod 和 floorDiv 旨在解决整型余数问题。在java中,如果n为负数,n%2为-1,而floorMod(position + adjustment, 12)总是返回一个0到11之间的数字。(对于负的除数,还是会返回负值)。floorDiv则返回0到12之间的数字。
3.2 自增自减运算
- 前缀:先运算再使用数值
- 后缀:先使用数值再运算
3.3 位运算符
&:and 与
|:or 或
^:xor 异或
~:not 非
>> 或 <<:位模式左移或右移
>>>:用0填充高位
3.4 运算符级别
| 运算符 | 结合性 |
|---|---|
| [].()(方法调用) | 从左向右 |
| ! ~ ++ – + -(一元运算) ()(强制类型转换) new | 从右向左 |
| * / % | 从左向右 |
| + - | 从左向右 |
| <<>> >>> | 从左向右 |
| < <= > >= instanceof | 从左向右 |
| == != | 从左向右 |
| & | 从左向右 |
| ^ | 从左向右 |
| | | 从左向右 |
| && | 从左向右 |
| || | 从左向右 |
| ? : | 从右向左 |
| = += -= *= /= %= |= ^= <<= >>= >>>= | 从右向左 |
4. 字符串
4.1 字符串
Java没有内置的字符串类型,而是在标准Java类库中提供了预定义类:String,且String为final不可变,因此总是线程安全的,一般都用它作为参数传递
- substring(a, b):截取字符串
- + :连接字符串 (每次连接,都会构建一个新的String对象,效率低占空间,使用StringBuilder类,通过apped添加字符串可避免此问题)
- join("/", “a”, “b”, “c”):分隔字符串 “a/b/c”
- equal:检测两个字符串是否相等
"=="运算符只能检测两个字符串是否放在同一位置 - equalIgnoreCase:忽略大小写检测是否相等
- compareTo(String str):按照字典顺序检测一个字符串是否在str前后位置,之前为负,之后为正,相等为0
- replace(oldStr, newStr):用newStr代替原始字符串中 所有的oldStr,并返回一个新字符串
- toLowerCase() / toUpperCase():更改大小写,并返回一个新串
- trim():删除原始字符串头部和尾部的空格
String类没有提供用于修改字符串的方法,如果想修改,可先substring截取需要的字符,再拼接替换的字符串
不可变字符串的优点:编译器可以让字符串共享(复制原始字符串的效率远高于截取拼接,用StringBuilder可以高效拼接字符串)
StringBuilder类中常用方法:
StringBuilder append(String str):追加一个字符串并返回this
void setCharAt(int i, char c):将第i个位置设为c
StringBuilder insert(int offset, String str):在offset位置插入一个字符串并返回this
StringBuilder delete(int startIndex, int endIndex):删除偏移量从startIndex到-endIndex-1的字符并返回this
toString():返回一个与构建器或缓冲器内容相同的字符串
4.2 空串 和 null
- 空串"":是长度为0的字符串。可用str.length()==0 或 str.equals("")检测
- null:表示目前没有任何对象与该变量关联
检查一个字符串既不是null也不是空串:
if(str != null && str.length() != 0)
4.3 String / StringBuilder / StringBuffer 的区别
执行速度快慢为:StringBuilder > StringBuffer > String :
因为String为字符串常量,而StringBuilder和StringBuffer均为字符串变量,即String对象一旦创建之后该对象是不可更改的,但另外两者的对象是变量,是可以更改的。
在线程安全上,StringBuilder是线程不安全的,而StringBuffer是线程安全的,String为final不可变总是安全的:
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder。
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
4.4 输入输出
-
Java SE 6 引入了Console类实现读取密码:
Console cons = new Console(); String username = cons.realLine("username: "); char[] passwd = cons.readPassword("Password: "); //显示Password: 并读取输入
安全起见,返回的密码存放在一维字符数组中,而不是字符串中 (在对密码进行处理后,应该马上用一个填充值覆盖数组元素)
4.5 格式化输入
- Java SE 5.0 引用了C库中的printf方法:
用于printf的转换符
| 转换符 | 类型 | 举例 |
|---|---|---|
| d | 十进制整数 | 77 |
| x | 十六进制整数 | 9f |
| o | 八进制整数 | 237 |
| f | 定点浮点数 | 15.7 |
| e | 指数浮点数 | 1.57e+01 |
| g | 通用浮点数 | —— |
| a | 十六进制浮点数 | 0x1.fccdp3 |
| s | 字符串 | Hello |
| c | 字符 | H |
| b | 布尔 | True |
| h | 散列码 | 42628b2 |
| tx or Tx | 日期时间 | 已过时,现用java.time类 |
| % | 百分号 | % |
| n | 与平台有关的行分隔符 | —— |
**用于printf的标志
| 标志 | 目的 | 举例 |
|---|---|---|
| + | 打印正数负数的符号 | +333.33 |
| 空格 | 在正数之前添加空格 | | 333.33| |
| 0 | 数字前面补0 | 00333.33 |
| - | 左对齐 | |333.33 | |
| ( | 将负数括在括号内 | (333.33) |
| , | 添加分组分隔符 | 3,333,33 |
| #(对于f格式) | 包含小数点 | 3,333. |
| #(对于x或0格式) | 添加前缀0x或0 | 0xcafe |
| $ | 给定被格式化的参数索引:%1$x将以十六进制打印第一个参数 | 159 9F |
| < | 格式化前面说明的数值:%d%<x 以十进制和十六进制打印同一个数值 | 159 9F |
- 可以使用静态的String.format方法创建一个格式化的字符串,而不打印输出
4.6 文件输入与输出
- 读取文件:用File对象构造一个Scanner对象:
Scanner in = new Scanner(Paths.get("myfile.txt"), "UTF-8"); - 写入文件:构造一个PrintWriter对象(如果文件不存在,创建该文件):
PrintWriter out = new PrintWriter("myfile.txt", "UTF-8");
PrintWriter(String fileName):构造一个将数据写入文件的PrintWriter
static Path get(String pathName):根据给定的路径名构造一个Path
5. 控制流程
5.1 控制流程语句
- Switch中,case标签可以是:类型为char、byte、short、int的常量表达式,枚举常量,字符串字面量(Java SE 7)
- 带标签的break:标签必须放在要跳出的最外层循环之前,且紧跟一个冒号":".
5.2 大数值BigInteger / BigDecimal
- java.math包中的两个类,可以处理包含任意长度数字序列的数值
- 使用BigInteger.valueOf方法可以将普通的数值转换为大数值:BigInteger a = new BigInteger.valueOf(100);
- 不能使用+/*等处理大数值,而是使用 add / multiply 方法。
BigInteger add(BigInteger other
BigInteger subtract(BigInteger other
BigInteger multiply(BigInteger other)
BIgInteger divide(BigInteger other)
BigInteger mod(BigInteger other) 返回两个大整数的和、差、积、商、余数。
int compareTo(BigInteger other) 两个大整数相等,返回0;小于返回负数,大于返回正数
static BigInteger valueOf(long x) 返回值等于x的大整数
static BigDecimal valueOf(long x, int scale) 返回值为x或 x / 10 ^ scale的一个大实数
5.3 数组 foreach循环
- 遍历数组中的每个元素
- Arrays.toString(str):打印一维数组中的所有值(更简单的遍历打印方法)
- Arrays.deepToString(str):打印二维数组中的数据元素
匿名数组:new int[] {} 可以在不创建新变量的情况下重新初始化一个数组
在返回值为数组的方法中,如果结果为0,则可以创建一个长度0的数组:new arrName[0]。数组长度为0与null不同。
- Arrays.copyOf(str, str.length) :将一个数组的所有值拷贝到一个新的数组中去,第二个参数是数组长度,通常用来增加数组的大小
5.4 命令行参数
public static void main(String[] args){}
以java className -g cruel world 的形式运行程序:args数组将包含:
args[0]: “-g”
args[1]: “cruel”
args[2]:“world”
数组排序
随机不重复抽取一个范围内的数值:
将数组最后一个值赋给之前抽取的数的索引,并将总数减去 1 ,则抽取不会重复
- static int binarySearch(type[] a, int start, int end, type v):采用二分搜索发查找值
- static void fill(type[] a, type v):将数组的所有数据元素设置为v
- static boolean equals(type[] a, type[] b):如果两个数组大小相同,且下标相同的元素都对应相等,返回true
2.对象与类
三个主要特性:
- 对象的行为(behavior):可以对对象施加哪些操作或方法
- 对象的状态(state):施加方法时,对象如何响应
- 对象标识(identity):如何辨别具有相同行为与状态的不同对象
一个对象变量并没有实际包含一个对象,而仅仅引用一个对象
任何对象变量的值都是对存储在另外一个地方的一个对象的引用,new操作符的返回值也是一个引用
1. 类
类之间的关系:
- 依赖(“uses-a”):一个类的方法操作另一个类的对象
- 聚合(“has-a”):类A 的对象包含 类B 的对象
- 继承(“is-a”):类A 扩展 类B,继承 类B的方法
1.1 更改器方法 与 访问器方法
- 更改器方法:调用后可以改变对象的状态 ,setter
- 访问器方法:只访问对象而不修改对象 ,getter
1.2 构造器
- 构造器总是伴随着new操作符的执行被调用,而不能对一个已经存在的对象调用构造器来达到重新设置实力域的目的
- 构造器与类同名
- 每个类可以有一个以上的构造器
- 构造器可以有0个、1个或多个参数
- 构造器没有返回值
- 所有Java的对象都是在堆中构造的
- 不要在构造器中定义与实例域重名的局部变量
1.3 隐式参数和显式参数
public void raiseSalary(double byPercent){
double raise = salary * byPercent / 100; //可以这样调用 double raise = this.salary * byPercent / 100;
salary += raise; //this,salary += raise;
}
- raiseSalary方法有两个参数,第一个为隐式参数,是在方法名之前的类对象,第二个为显式参数,位于方法名后面括号中。
- 隐式参数:方法调用的目标或接收者,this关键字表示隐式参数
- 显式参数:明显地列在方法声明中
1.4 封装的优点
- 通过 getName()、getAge()形式的方法获取实力域值,称为访问器方法 或 域访问器。
- name是一个只读域,在构造器中设置完毕,就没有任何方法可以对它进行修改,这样确保name域不会受到外界的破坏
在需要获得或设置实力域的值时,应提供:
一个私有的数据域
一个公有的域访问器方法
一个公有的域更改器方法
- 优点**:可以改变内部实现,除了该类的方法之外,不会影响其他代码;更改器方法可以执行错误检查**
- 注意:不要编写返回引用可变对象的访问器方法,否则会破坏封装性。
- 如果需要返回一个可变数据域的拷贝,就应该使用clone。
1.5 私有方法
在实现一个类时,所有数据域都应该设置为私有的,大部分方法都设计为公有的。公有方法不能随意删除,其他代码可能依赖于它。
如果希望将一个计算代码划分成若干个独立的辅助方法,或者需要一个特别的协议以及一个特别的调用次序,可以将方法设为private的。(P111)
1.6 final实力域
- 可以将实力域定义为final,构建对象时必须初始化这样的域,且不可更改;
- final大都应用于基本类型域,或不可变类的域(类中每个方法都不会改变其对象,如String类)
1.7 静态域与静态方法
- 静态域:如果域定义为static,则一个类中只有一个这样的域;
- 静态方法:一种不能向对象实施操作的方法,或没有this的方法(在非静态方法中,this表示这个方法的隐式参数)
- 使用静态方法:一个方法不需要访问对象状态,其所需参数都是通过显式参数提供(如:Math.pow)
一个方法只需要访问类的静态域。
1.8 工厂方法
静态方法还有另一常见用途,使用静态工厂方法来构造对象。
如:NumberFormat类
NumberFormat currencyFormatter = NumberFormat.getCurrencyInstance();
NumberFormat percentFormat = NumberFormat.getPercentInstance();
double x = 0.1;
syso.print(currencyFormatter.format(x)) //prints $0.10
syso.print(percentFormatter.fotmat(x)); //prints 10%
不使用构造器完成以上操作的原因:无法命名构造器,构造器的名字必须与类名相同,这里希望将得到的货币实力和百分比实例采用不同的名字。
当使用构造器时,无法改变所构造的对象类型。而工厂方法将返回一个DecimalFormat类对象。
1.9 main方法
- main方法不对任何对象进行操作,在启动程序时还没有任何一个对象,静态的main方法将执行并创建程序所需要的对象。
1.10 方法参数
-
按值调用:表示方法接收的是调用者提供的值。(Java采用按值调用,方法得到的是所有参数值的一个拷贝)
-
按引用调用:表示方法接收的是调用者提供的变量地址。
-
方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象(对象引用是按值传递的)
Java中方法参数的使用情况:
1.一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)
private int s = 0;
public void changeParameter(int a) {a++;}
public static void main(String[] args) {
t.changeParameter(t.s);
System.out.println(t.s);
}
2.一个方法可以改变一个对象参数的状态
3.一个方法不能让对象参数引用一个新的对象
2.对象构造
2.1 重载
- 重载: 发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同,发生在编译时。
- 重写: 发生在父子类中,方法签名(方法名字和参数列表)必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
2.2 默认域初始化
- 在构造器中没有显式地给域赋予初值,就会被自动地赋为默认值(数值为0,boolean为false,对象引用为null),而方法中的局部变量必须明确地初始化。
2.3 参数名
一般在参数前面加个“a”, 或者 参数变量用相同的名字将实例域屏蔽,但可以采用 this隐式参数 来访问实例域
2.4 初始化块
- 初始化数据域的方法:在构造器中设置值, 或 在声明中赋值
- 或 初始化块:数据域在对象初始化块中被初始化,先运行初始化块,再运行构造器的主体.(通常直接将初始化块代码放入构造器)
{ id = nextId; nextId++;} - 使用静态初始化块对静态域进行初始化
...
}
在类第一次加载时,将会初始化静态域
2.5 finalize方法
- 在垃圾回收器清除之前调用,回收资源,不要用来回收任何短缺资源,因为很难知道什么时候才能够调用。
- 确保finalizer方法在Java关闭前调用:使用Runtime.addShutdownHook添加“关闭钩”。
- 某个资源在使用完毕后要立刻关闭,可以使用close()方法
2.6 包
- 在两个包中有相同名称的类时,不能使用 * 来导入,可以在类名前面加上完整包名。
- 编译器在编译源文件时不检查目录结构
3. 注释
- @param:变量描述
- @return:描述
- @throws:类描述
- @author:姓名
- @version:版本
- @since:文本
- @deprecated:文本,添加一个不再使用的注释
- @see:引用,超链接
类的设计技巧
1.保证数据私有
2.对数据初始化
3.不要在类中使用过多的基本类型
4.不是所有的域都需要独立的域访问器和更改器
5.将职责过多的类进行分解
6.类名和方法名应体现它们的职责
7.优先使用不可变的类
3.继承
- 一个对象变量可以指示多种实际类型的现象被称为 多态
- 在运行时能够自动地选择调用哪个方法的现象称为 动态绑定(默认的处理方式)
- 不允许扩展的类称为final类,不可被继承
- 强制转换:应先用if(Obj instanceof Obj)判断是否能够成功转换
- 只能在继承层次内进行类型转换
动态绑定的重要特性:无需对现存代码进行修改,就可以对程序进行扩展。
理解方法调用:
1.编译器查看对象的声明类型和方法名。
2.编译器查看调用方法时提供的参数类型。如果在所有名为上述的方法中存在一个与提供的参数类型完全匹配,就选择这个方法。此过程称为重载解析。
3.如果是private、static、final方法或构造器,编译器将可以准确地知道应该调用哪个方法。这种调用方式为静态绑定。
4.当程序运行,并且采用动态绑定调用方法时,虚拟机一定调用与x所引对象的实际类型最合适的那个类的方法。
调用e.getSalary()方法的解析过程:
1.虚拟机提取e的实际类型的放发表。既可能时Employee、Manager方法表,也可能时Employee类的其他子类的方法表。
2.虚拟机搜索定义getSalary签名的类。此时虚拟机已经知道应该调用哪个方法。
3.虚拟机调用方法。
1.抽象类 abstract
1.包含一个或多个抽象方法的类必须为抽象的,但抽象类可以不包含抽象方法
2.抽象类可以包含具体的数据和方法,但不能被实例化
3.抽象类充当占位角色,具体实现 在子类中
4.扩展抽象类的两种方法:在抽象类中定义部分抽象方法或不定义抽象方法,则子类必须为抽象类;定义全部的抽象方法,则子类就不是抽象的
5.可以定义一个抽象类的对象变量,但只能引用非抽象子类的对象:Person p = new Student();
2. == 和 equals
== : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型比较的是值,引用数据类型比较的是内存地址)
equals() : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来两个对象的内容相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
举个例子:
java
public class test1 {
public static void main(String[] args) {
String a = new String("ab"); // a 为一个引用
String b = new String("ab"); // b为另一个引用,对象的内容一样
String aa = "ab"; // 放在常量池中
String bb = "ab"; // 从常量池中查找
if (aa == bb) // true
System.out.println("aa==bb");
if (a == b) // false,非同一对象
System.out.println("a==b");
if (a.equals(b)) // true
System.out.println("aEQb");
if (42 == 42.0) { // true
System.out.println("true"); }}}
说明:
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
3. hashCode
-
散列码是由对象导出的一个整型值,是没有规律的
-
hashCode方法定义在Object类中,因此每个对象都有一个默认的散列码,值为对象的存储地址。
-
StringBuilder类中没有定义hashCode方法,它的散列码是由Object类的默认hashCode方法导出的对象存储地址
String类计算hashCode:int hash = 0; for(int i=0; i<length(); i++){ hash = 31 * hash + charAt(i); } -
字符串内容相同,则 散列码相同
- int hashCode() :返回对象的散列码
- static int hash(Object…Objects) :返回一个散列码,由提供的所有对象的散列码组合得到
- static int hashCode((int|long|double|char|boolean…) value) : 返回给定值的散列码
- static int hashCode(type[] a) : 计算数组a的散列码
4. toString
-
只要对象与一个字符串通过操作符“+”连接,Java编译就会自动地调用toString方法,以便获得这个对象的字符串描述。
-
强烈建议为自定义的每个类添加toString方法,便于从日志记录中获取信息和调试。
-
如下定义
public String toString(){ return getClass().getName()+"[name=" + name + ",age=" + age + "]"; }
5. 泛型数组列表ArrayList<>()
- void ensureCapacity(int capacity):确定数组存储元素数量后,分配包含capacity个内部数组
- int size():返回数组列表中包含的实际元素数目
- void TrimToSize():将数组列表的存储容量削减到当前尺寸(垃圾回收器回收多余的存储空间)
使用get、set实现访问或改变数组元素的操作
set方法只能替换数组中已经存在的元素内容
灵活扩展数组并方便访问数组元素:
ArrayList<X> list = new ArrayList<>();
while(...){
x = ...;
list.add(x);
}
X[] a = new X[list.size()];
list.toArray(a); //在数组列表中间插入元素
int n = staff.size()/2;
staff.add(n, e);
6. 自动装箱与拆箱
装箱:将基本类型用它们对应的引用类型包装起来;
拆箱:将包装类型转换为基本数据类型;
-
自动装箱规范要求boolean、byte、char <= 127,介于-128~127之间的short和int被包装到固定的对象中。
-
由于包装器类引用可以为null,所有自动装箱有可能抛出NullPointerException异常。
-
装箱和拆箱是编译器认可的,而不是虚拟机
-
包含在包装器中的内容不会改变,可以用org.omg.CORBA包中的holder类型如IntHolder、BooleanHolder等来访问存储在其中的值:
public static void triple(IntHolder x){ x.value = 3 * x.value; } -
static int parseInt(String s[, int radix]): 返回字符串s表示的整形数值(默认十进制)。或者radix规定的进制。
-
Static Integer valueOf(String s[, int radix]):返回用s表示的整形数值进行初始化后的一个新Integer对象。或者radix规定的进制。
-
Number parse(String s):返回数字值,假设给定的String表示了一个数值。
7.可变参数的方法
-
max方法可以接收任意数量的参数,**Object…与Object[]**一样
public static double max(double...values){ double largest = Double.NEGATIVE_INFINITY; for(double v:values) if(v > largest) largest = v; return largest; }
main方法可以声明为下列形式:
public static void main(String…args)
继承的设计技巧
1.将公共操作和域放在超类;
2.不要使用受保护的域;
3.使用继承实现"is-a"关系;
4.除非所有继承的方法都有意义,否则不要使用继承;
5.再覆盖方法时,不要改变预期的行为;
6.使用多态,而非类型信息;
7.不要过多的使用反射。
4. 接口、lambda
接口
- 描述类具有什么功能
- 接口没有实例
- 实现接口的类必须实现接口中的所有方法
lambda
- 表示可以在将来某个时间点执行的代码块的简洁方法。可以用一种简洁的方式表示使用回调或变量行为的代码。
内部类
- 主要用于设计具有相互协作关系的类集合
代理
- 一种实现任意接口的对象。非常专业的构造工具,可以用来构建系统级的工具
1. 接口
- 接口中的所有方法自动地属于public;
- Java SE 8 之后,接口中可以提供简单的方法,且方法不能引用实例域;
- 提供实例域和方法实现的任务应该由实现接口的那个类来完成;
- 在实现接口时,必须把方法声明为public;
- 接口变量必须引用实现了接口的类对象;
- 可以使用instance检查一个对象是否实现了某个特定的接口;
- 接口中不能包含实例域或静态方法,却可以包含常量(Java SE 8可以有静态方法);
- 接口中的域会自动被设为public static final
- 每个类只能继承一个类,却可以实现多个接口;
- 接口也可以被继承扩展(extends)
1.为什么必须用接口规定类:因为Java是强类型语言,在调用方法时,编译器会检查这个方法是否存在,当一个方法中有调用某个方法,则编译器必须确认这个方法一定存在,用接口来规定就表示一定有这个方法。
2.为什么有了抽象类还需要接口: 每个类只能继承一个类,却可以实现多个接口。
1.1 接口静态方法
Java SE 8 中允许在接口中增加静态方法,但目前为止,都是将静态方法放在伴随类中。在标准库中有成对出现的接口和实用工具类,Collection/Collections或Path/Paths。(这个技术已经过时,现在可以直接在接口中实现方法。)
1.2 默认方法
可以为接口提供一个默认实现,必须用 default 修饰。
public interface Comparable<T>{
default int compareTo(T other) {return 0;}
}
为什么要默认方法:因为接口中的所有方法都要实现,若只需要其中一两个方法,则可以将方法都声明为default,需要时只需覆盖即可。
解决默认方法冲突:
如果在一个接口中将方法定义为默认方法,又在父类或另一个接口定义了同样的方法,则 父类优先
接口冲突:父接口提供了一个默认方法,另一接口提供了同样的方法(不论是否是默认参数),则必须覆盖这个方法来解决冲突。
当一个类同时实现两个同样的接口时,需要程序员解决二义性。
接口与回调(callback)
回调是一种常见的程序设计模式,可以指出某个特定事件发生时应该采取的动作。
public class TimerTest{
public static void main(String[] args){
ActionListener listener = new TimePrinter(); //构造TimePrinter类对象并转换为ActionListener
Timer t = new Timer(10000, listener); //将ActionListener对象传给Timer类
t.start();
JOptionPane.showMessageDialog(null, "Quit program?"); //null表示在屏幕中央输出语句
System.exit(0);
}
}
class TimerPrinter implements ActionListener{
public void actionPerformed(ActionEvent event){ //实现ActionListener接口中的方法
System.out.println("At the tone, the time is " + new Date());
Toolkit.getDefaultToolkit().beep(); //发出铃响
}
}
comparator接口(P224)
当需要按长度来比较时,可以使用一个数组和一个比较器作为参数,比较器是实现了Comparator接口的实例,
public interface Comparator<T>{
int compare(T first, T second);
}
按长度比较字符串,可以定义如下实现Comparator的类:
class LengthComparator implements Comparator<String>{
public int compare(String first, String second){
return first.length() - second.length();
}
}
具体完成比较时,需要建立一个实例:
Comparator<String> comp = new LengthComparator();
if(comp.compare(word[i], word[j]) > 0)...
对象克隆 (Cloneable接口)
-
Cloneable接口时Java提供的一组标记接口之一。通常用来确保一个类实现一个或一组特定的方法。标记接口不包含任何方法。它的唯一作用就是允许在类型查询中使用instanceof:(建议自己的程序中不要使用标记接口)
if(Obj instanceof Cloneable)... -
Cloneable接口提供了一个安全的clone方法 (它没有指定clone方法,只是从Object类继承的)
-
Clone方法是Object的一个protected方法,因此代码不能直接调用这个方法。它是个浅拷贝,当原对象与克隆对象的子对象是不可变时,它是安全的。但通常子对象都是可变的,则需要重新定义一个clone方法来建立深拷贝,同时克隆所有子对象。
对于每一个类,需要确定:
1,默认的clone方法是否满足要求;
2.是否可以在可变的子对象上调用clone来修补默认的clone方法;
3.是否不该使用clone。
实际上第3个是默认选项。如果选择1、2,类必须:
1.实现Cloneable接口;
2.重新定义clone方法,并指定public访问修饰符。
- 对于Object类的protected clone方法,虽然所有类都是Object的子类,但子类只能调用protected clone方法来克隆它自己的对象,必须重新定义clone为public才能允许所有方法克隆对象。
深拷贝
建立深拷贝,需要克隆对象中可变的实例域。
public Employee clone() throws CloneNotSupportedException{
Employee cloned = (Employee) super.clone();
cloned.hireDay = (Date) hireDay.clone(); //hireDay是一个Date,可变的
return cloned;
}
!!!
-
所有数组类型都有一个public的clone方法,而不是protected。可以用这个方法建立一个新数组,包含原数组所有元素的副本。
渐析java的浅拷贝和深拷贝
浅拷贝:使用一个已知实例对新创建实例的成员变量逐个赋值,这个方式被称为浅拷贝。
深拷贝:当一个类的拷贝构造方法,不仅要复制对象的所有非引用成员变量值,还要为引用类型的成员变量创建新的实例,并且初始化为形式参数实例值。这个方式称为深拷贝
也就是说浅拷贝只复制一个对象,传递引用,不能复制实例。而深拷贝对对象内部的引用均复制,它是创建一个新的实例,并且复制实例。
对于浅拷贝当对象的成员变量是基本数据类型时,两个对象的成员变量已有存储空间,赋值运算传递值,所以浅拷贝能够复制实例。但是当对象的成员变量是引用数据类型时,就不能实现对象的复制了。
存在一个对象Person,代码如下:
public class Asian {
private String skin;
Person person;
public Asian(String skin,Person person){
this.skin = skin;
this.person = person; //引用赋值
}
public Asian(Asian asian){ //拷贝构造方法,复制对象
this(asian.skin,asian.person);
}
}
上面的对象Person有三个成员变量。name、sex、age。两个构造方法。第二个的参数为该对象,它称为拷贝构造方法,它将创建的新对象初始化为形式参数的实例值,通过它可以实现对象复制功能。
又有一个对象Asian,如下:
public class Asian {
private String skin;
Person person;
public Asian(String skin,Person person){
this.skin = skin;
this.person = person; //引用赋值
}
public Asian(Asian asian){ //拷贝构造方法,复制对象
this(asian.skin,asian.person);
}
}
上面对象也存在着两个成员变量,skin 和Person对象
对于person对象有如下:
Person p1 = new Person("李四","mam",23);
Person p2 = new Person(P1);
当调用上面的语句时。P2对象将会对P1进行复制。执行情况如下如下图:
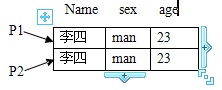
Asian a1 = new Asian("yellow",new Person("李四","mam",23));
Asian a2 = new Asian(a1);
对于Asian对象有:
New Asian(a1)执行Asian类的拷贝构造方法,由于对象赋值是引用赋值。使得a1和a2引用同一个对象
如下图:
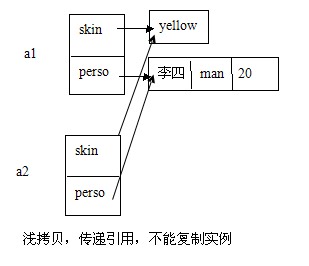
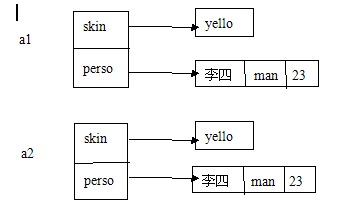
当a1执行某条可以改变该值的语句时,那么a1将会通过这个语句也可以改变a2对象的成员变量
如果执行以下语句:
2. lambda
-
lambda是一个可传递的代码块,可以在以后执行一个或多次。
-
带参数变量的表达式称为lambda表达式。
-
即使lambda表达式没有参数,仍然要提供空括号(),就像无参方法一样;
-
如果可以推导出一个lambda表达式的参数,则可以忽略其类型:
Comparator<String> comp = (first, second) -> first.length() - second.length(); //因为这个lambda将赋给一个字符串比较器 -
如果方法只有一个参数,而且这个参数的类型可以推导出,甚至可以省略小括号:
ActionListener listener = event -> System.out.println("..."); -
无需指定lambda的返回类型,会由上下文推导得出:
(String first, String second) -> first.length() - second.length() //可以在需要int类型结果的上下文中使用 -
如果一个lambda表达式只在某些分支返回一个值,而在另外一些分支不返回值,这是不合法的。
(int x) -> {if(x >= 0) return 1;}
修改ActionListener接口:
Timer t = new Timer(10000, event -> System.out.println("..."));
函数式接口
-
对于只有一个抽象方法的接口,需要这个接口的对象时,就可以提供一个lambda表达式。称为函数式接口。 如:Comparator接口
Arrays.sort(words, (first, second) -> first.length() - second.length()); //Arrays.sort的第二个参数需要一个Comparator实例
!!!!!!!
- 在Java中,对lambda表达式能做的也只是能转换成函数式接口
- 不能把lambda赋给类型为Object的变量,Object不是一个函数式接口
方法引用
Timer t = new Timer(10000, System.out::println);
-
System.out::println是一个方法引用,等价于lambda表达式 x -> System.out.println(x);
-
如果想不考虑大小写来对字符串排序:
Arrays.sort(strings, String::compareToIgnoreCase)
方法引用有3种情况:
- object :: instanceMethod
- Class :: staticMethod
- Class :: instanceMethod
1和2等价于lambda表达式,类似于Math::pow等价于 (x, y) -> Math.pow(x, y)
对于3,第一个参数会成为方法的目标。如:String::compareTOIgnoreCase等价于**(x, y) -> x.compareToIgnoreCase(y)**
类似于lambda表达式,方法引用不能独立存在,总是会转换为函数式接口的实例。
- 可以在方法引用里使用this。如:this::equals 等同于 x -> this.equals(x)
- 使用super也是合法的 super::instanceMethod
使用this作为目标,会调用给定方法的父类版本:
class Greeter{
public void greet(){
System.out.println("Hello");
}
}
class TimedGreeter extends Greeter{
public void greet(){
Timer t = new Timer(1000, super::greet); //执行super::greet方法时,会调用父类的greet方法
t.start();
}
}
构造器引用
- 与方法引用类似,不过方法名为new。如:Person::new是Person构造器的一个引用
- 可以用数组类型建立构造器引用。如:int[]::new,它有一个参数 数组长度。等价于lambda的 x -> new int[x]
Java有一个限制,无法构造泛型类型数组,数组构造器引用可以克制这个限制。如:
new T[n]会产生错误,因为会改为 new Object[n]
假设需要一个Person对象数组。Stream接口有一个toArray方法可以返回Object数组:Object[] people = stream.toArray();
不过需要的是Person引用数组,而不是Object引用数组,可以这样做:
Person[] people = stream.toArray(Person[]::new);
toArray方法调用这个构造器来得到一个正确类型的数组。
再谈lambda
lambda表达式有3个部分:
1.一个代码块
2.参数
3.自由变量的值,这是指非参数而且不在代码中定义的变量。
关于代码块及自由变量有一个术语:闭包(closure)。在Java中,lambda表达式就是闭包。
lambda表达式可以捕获外围作用域中变量的值,不过要确保捕获的值是明确定义的。
- lambda表达式中,只能引用值不会改变的变量。若在lambda中引用变量,而变量可能在外部改变,也是不合法的。即:lambda中捕获的变量必须是最终变量
- 在lambda中声明与一个局部变量同名的参数或局部变量是不合法的。
- 在lambda中使用this关键字,是指创建这个lambda表达式的方法的this参数。
使用lambda表达式的重点是 延迟执行,之所以要延迟执行,有:
1. 在一个单独的线程中运行代码。
2. 多次运行代码。
3. 在算法的适当位置运行代码。(如排序的比较操作)
4. 发生某种情况时执行代码。(如点击了一个按钮,数据到达等)
5. 只在必要时才运行代码。
常用函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 抽象方法名 | 描述 | 其他方法 |
|---|---|---|---|---|---|
| Runnable | 无 | void | run | 作为无参数或返回值的动作运行 | |
| Supplier | 无 | T | get | 提供一个T类型的值 | |
| Consumer | T | void | accept | 处理一个T类型的值 | andThen |
| BiConsumer<T,U> | T, U | void | accept | 处理T和U类型的值 | andThen |
| Function<T, R> | T | R | apply | 有一个T类型参数的函数 | compose,andThen,identity |
| BiFunction<T,U,R> | T,U | R | apply | 有T和U类型参数的函数 | andThen |
| UnaryOperator | T | T | apply | 类型T上的一元操作符 | compose,andThen,identity |
| BinaryOperator | T,T | T | apply | 类型T上的二元操作符 | andThen,maxBy,minBy |
| Predicate | T | boolean | test | 布尔值函数 | and,or,negate,isEqual |
| BiPredicate<T,U> | T,U | boolean | test | 有两个参数的布尔值函数 | and,or,negate |
基本类型的函数式接口
| 函数式接口 | 参数类型 | 返回类型 | 抽象方法名 |
|---|---|---|---|
| BooleanSupplier | none | boolean | getAsBoolean |
| PSupplier | none | p | getAsP |
| PConsumer | p | void | accept |
| OjbPConsumer<T | T,p | void | accept |
| PFunction<T | p | T | apply |
| PToQFunction | p | q | applyAsQ |
| ToPFunction<T | T | p | applyAsP |
| ToPBiFunction<T,U> | T,U | p | applyAsP |
| PUnaryOperator | p | p | applyAsP |
| PBinaryOperator | p,p | p | applyAsP |
| PPredicate | p | boolean | test |
注:p,q为int,long,double; P,Q为Int,Long,Double.
如果设计自己的接口,其中只有一个抽象方法,可以用@FunctionInterface注解来标记这个接口。
再谈 Comparator
…
3.内部类
- 内部类方法可以访问该类定义所在的作用域中的数据,包括私有的数据。也可以访问创建它的外围类对象的数据域及私有数据。
- 内部类可以对同一个包中的其他类隐藏。
- 内部类中声明的所有静态域都必须是final。因为一个静态域只有一个实例,而每个外部对象都分别有一个单独的内部类实例。如果不是final,就可能不是唯一的。
- 内部类不能有static方法,
- 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。
- 只有内部类可以是私有类,常规类只可以是protected或public。
可以使用 outerObject.new InnerClass(construction parameters) 语法格式更加明确地编写内部对象的构造器。this通常可以省去。
内部类对象的外围类引用被设置为创建内部类对象的方法中的this引用。
可以显式地命名将外围类引用设置为其他的对象。如:TimePrinter是个公有内部类,对于任意的语音时钟都可以构造一个TimePrinter:
TalkintClock jabberer = new TalkingClock(1000, true);
TalkingClock.TimePrinter listener = jabberer.new TimePrinter();
需要注意,在外围类的作用域之外,可以用OuterClass.InnerClass这样引用内部类。
内部类是一种编译器现象,与虚拟器无关。编译器会把内部类翻译成用$分隔外部类名与内部类名的常规类文件,而虚拟机对此一无所知。
3.1. 局部内部类:
-
局部内部类不能用public或private访问说明符进行声明,它的作用域被限定在声明这个局部类的块中。
-
局部类对外部世界完全地绝对隐藏起来
-
局部类不仅能够访问包含它们地外部类,还可以访问局部变量。但局部变量必须是final,即一旦赋值绝不会改变。
假设想更新在一个封闭作用域内地计时器,这时final限制则不太方便。可以使用一个长度为1地数组:counter++; //错误
counter[0]++; //长度为1的数组
3.2. 匿名内部类
-
如果只创建类的一个对象,则可以不用命名。
-
匿名类没有构造器,而会将构造器参数传递给父类构造器。在实现接口时,不能有任何参数。
public void start(int interval, boolean beep){
ActionListener listener = new ActionListener(){
public void actionPerformed(ActionEvent event){
System.out.println("" + new Date());
if(beep) Toolkit.getDefaultToolkit().beep();
}
}};
Timer t = new Timer(interval, listener);
t.start();
}
一般Java程序员用匿名内部类实现事件监听器和其他回调。
双括号初始化
如果只需要传递一个数组到一个方法,之后不再需要,则可以使用匿名内部类语法:
invite(new ArrayList<String>(){{add("Tom");add("Tony")}});
外层括号建立了ArrayList的一个匿名子类,内层括号则是一个对象构造块。
生成日志或调试消息时,通常希望包含当前类名。通过 getClass() 来实现,不过getClass调用的时this.getClass(),而静态方法没有this。所以应该使用以下表达式:
new Object(){}.getClass().getEnclosingClass()
**new Object(){}**会建立Object的一个匿名子类的一个匿名对象,getEnclosingClass则得到其外围类,也就是包含这个静态方法的类。
3.3. 静态内部类
- 解决类名冲突:将类定义为另一个类的 内部公有类,可以通过 OuterClass.InnerClass访问它。如果使用内部类只是为了把一个类隐藏在另外一个类的内部,不需要内部类引用外围类对象时,则可以将内部类声明为static,以便取消产生的引用。
- 只有内部类可以声明为static
- 静态内部类可以有静态域和方法。
4. 代理
- 代理可以在运行时创建全新的类,这样的代理能够实现指定的接口。且具有下列方法:
- 指定接口所需要的全部方法。
- Object类中的全部方法,如 toString、equals等。
- 然而不能再运行时定义这些方法的新代码,而是要提供一个调用处理器,调用处理器是实现了InvocationHandler接口的类对象。在这个接口中只有一个方法:Object invoke(Object proxy, Method method, Object[] args) ,无论何时调用代理对象的方法,调用处理器的invoke方法都会被调用,并向其传递Method对象和原始的调用参数。调用处理器必须给出处理调用的方式。
创建代理,需要使用Proxy类的newProxyInstance方法,此方法有三个参数 :
-
一个类加载器,null表示默认的加载器
-
一个Class对象数组,每个元素都是需要实现的接口。
-
一个调用处理器。
5. 泛型
- 类型参数的好处:使得程序具有更好的可读性和安全性。
- 设计泛型类型的目的:允许泛型代码和遗留代码之间能够互操作。
1.泛型类
定义泛型类Pair:
public class Pair<T>{
priavte T first,second;
public Pair() {first = null; second = null;}
public Pair(T first, T second) {this.first = first; this.second = second;}
public T getFirst() {return first;}
public T getSecond() {return second;}
public void setFirst(T newValue) {first = newValue;}
public void setSecond(T newValue) {second = newValue;}
}
- 一个泛型类(generic class)就是具有一个或多个类型变量的类。
- 类型变量一般使用大写形式,且比较短。
- 泛型类可看作普通类的工厂。用具体的类型替换类型变量就可以实例化泛型类型,如Pair,可以将结果想象成带有构造器的普通类和访问器及更改器方法。
2.泛型方法
定义泛型方法:
public static <T> T getMiddle(T...a){ //类型变量放在修饰符后,返回类型前。第二个T为返回类型
return a[a.length / 2];
}
- 泛型方法可以定义在普通类或泛型类中
如果想知道编译器对一个泛型方法调用最终推断出哪种类型:有目的地引入一个错误,并研究所产生的错误消息。
3. 类型变量的限定
<T extends Comparable> //表示为实现了Comparable接口地类
为什么使用extends而不是implements?
- 表示T应该是绑定类型的子类型。T和绑定类型可以是类,也可以是接口。
- 一个类型变量或通配符可以有多个限定:T extends Comparable & Serializable
- 限定类型用“&”分隔,逗号用来分隔类型变量。
- 可以根据需要拥有多个接口父类型,但限定中至多有一个类。如果用一个类作为限定,它必须是限定列表中的第一个。
4. 泛型代码和虚拟机
虚拟机没有泛型类型对象,在编译阶段会擦除类型变量,并用第一个限定的类型变量替换 (无限定的变量用Object)。Pair的原始类型如:
public class Pair{
priavte Object first, second;
public Pair(Object first, Object second){
this.first = first; this.second = second;
}
...
}
- 为了提高效率,标签接口(如:Serializable)应放在边界列表的末尾。
5. 翻译泛型表达式和泛型方法
程序调用泛型方法时,如果擦出返回类型,编译器会插入Employee的强制类型转换,会把这个方法调用翻译为两条虚拟机指令:
Pair<Employee> buddies = ...;
Employee buddy = buddies.getFirst();
- 对原始方法Pair.getFirst的调用。
- 将返回的Object类型强制转换为Employee类型。
泛型方法也进行类型擦除:
public static <T extends Comparable> T min(T[] a)
擦除后:
public static Comparable min(Comparable[] a)
桥方法
Class DateInterval extends Pair<LocalDate>{
public void setSecond(LocalDate second){
if(second.compareTo(getFirst()) >= 0)
super.setSecond(second);
}
}
类型擦除后:
class DateInterval extends Pair{
public void setSecond(LocalDate second) {...}
...
}
方法的擦除会使得存在另一个方法,即
public void setSecond(Object second)
此方法的类型参数为Object,而不似乎LocalDate。
DateInterval interval = new DateInterval(...);
Pair<LocalDate> pair = interval;
pair.setSecond(aDate);
这里希望对setSecond的调用具有多态性,并调用最合适的那个方法。由于pair引用DateInterval对象,所以应该调用DateInterval.setSecond。
但是类型擦除与多态发生了冲突,此时需要编译器在DateInterval类中生成一个桥方法(bridge method):
//setSecond((Date) second)为强制类型转换,使其调用的是DateInterval.setSecond(Date)方法
public void setSecond (Object second) { setSecond((Date) second); }
- 变量pair已经声明为类型Pair,并且这个类型只有一个简单的方法setSecond(Object),虚拟机用pair引用的对象调用这个方法。
- 这个对象时DateInterval类型的,因而将会调用DateInterval.setSecond(Object)方法,这个方法是合成的桥方法。它调用DateInterval.setSecond(Date)。
Java泛型转换:
- 虚拟机中没有泛型,只有普通的类和方法。
- 所有的类型参数都用它们的限定类型替换。
- 桥方法被合成用来保持多态。
- 为保持类型安全性,必要时插入强制类型转换。
约束与局限性(P321)
- 不能用基本类型实例化类型参数
- 运行时类型查询instanceof只适用于原始类型
- 不能创建参数化类型的数组,如 Pair[] table = new Pair[10]; //Error。但声明可以
- Varargs警告:向参数个数可变的方法传递一个泛型类型的实例。添加注解@SuppressWarnings(“unchecked”)或@SafeVarargs标注
- 不能实例化类型变量,如 public Pair() {first = new T();} //Error。类型擦出后T会改为Object
- 不能构造泛型数组
- 不能在静态域或方法中引用类型变量
- 不能抛出或捕获泛型类的实例,也不能扩展Throwable。但在异常规范中使用类型变量是允许的:public static void doWork(T t) throws T
- 可以消除对受查异常的检查。Java异常处理原则:必须为所有受查异常提供一个处理器。可以利用泛型消除这个限制
- 注意擦除后的冲突。泛型规范原则:要想支持擦出的转换,就需要强行限制一个类或类型变量不能同时成为两个接口类型的子类,而这两个接口是同一接口的不同参数化。
6.通配符类型
通配符类型中,允许类型参数变化。如:
public static void printBuddies(Pair<? extends Employee> p)
类型Pair是Pair<? extends Employee>的子类型。
Pair<manager> managerBuddies = new Pair(ceo, cfo);
Pair<? extends Employee> wildcardBuddies = managerBuddies; //OK
wildcardBuddies.setFirst(lowlyEmployee); //complile-time error
对setFirst的调用有一个类型错误。类型Pair<? extends Employee>方法应是这样:
? extends Employee getFirst()
void setFirst(? extends Employee)
这样不可能调用setFirst方法。编译器只知道需要某个Employee的子类型,但不知道具体是什么类型。因此它拒绝传递任何特定的类型。
但是getFirst就不存在此问题:将getFirst的返回值赋给一个Employee的引用完全合法。
这样可以区分 安全的访问器方法 和 不安全的更改器方法。
通配符的超类型限定:
? super Manager
限制为Manager的所有超类型。
带有超类型限定的通配符可以向泛型对象写入,带有子类型限定的通配符可以从泛型对象读取
无限定通配符
Pair<?>,有以下方法:
? getFirst()
void setFirst(?)
- getFirst的返回值只能赋给一个Object。setFirst方法不能被调用,甚至不能用Object调用。
- Pair<?>和Pair的本质不同在于:可以用任意Object对象调用原始Pair类的setObjecgt方法。
- 可以调用 setFirst(null)
7. 通配符捕获(P334)
- 通配符捕获只有在有许多限制的情况下才是合法的。
- 编译器必须能够确信通配符表达的是单个、确定的类型。
8. 反射和泛型
对象是泛型类的实例时,泛型类参数会被擦除,得不到太多信息。通过反射可以获得泛型类的信息。
使用Class参数进行类型匹配。
6. 集合
1. 集合框架图
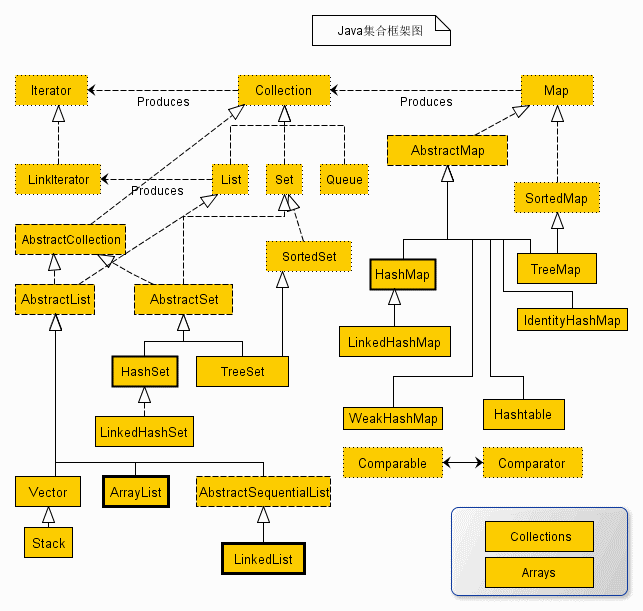
简化图:

说明:对于以上的框架图有如下几点说明:
1.所有集合类都位于java.util包下。Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些子接口或实现类。
2. 集合接口:6个接口(短虚线表示),表示不同集合类型,是集合框架的基础。
3. 抽象类:5个抽象类(长虚线表示),对集合接口的部分实现。可扩展为自定义集合类。
4. 实现类:8个实现类(实线表示),对接口的具体实现。
5. Collection 接口是一组允许重复的对象。
6. Set 接口继承 Collection,集合元素不重复。
7. List 接口继承 Collection,允许重复,维护元素插入顺序。
8. Map接口是键-值对象,与Collection接口没有什么关系。
9.Set、List和Map可以看做集合的三大类:
- List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
- Set集合是无序集合,集合中的元素不可重复,访问集合中的元素只能根据元素本身来访问(也是集合里元素不允许重复的原因)。
- Map集合中保存Key-value对形式的元素,访问时只能根据每项元素的key来访问其value。
2. 总体分析:
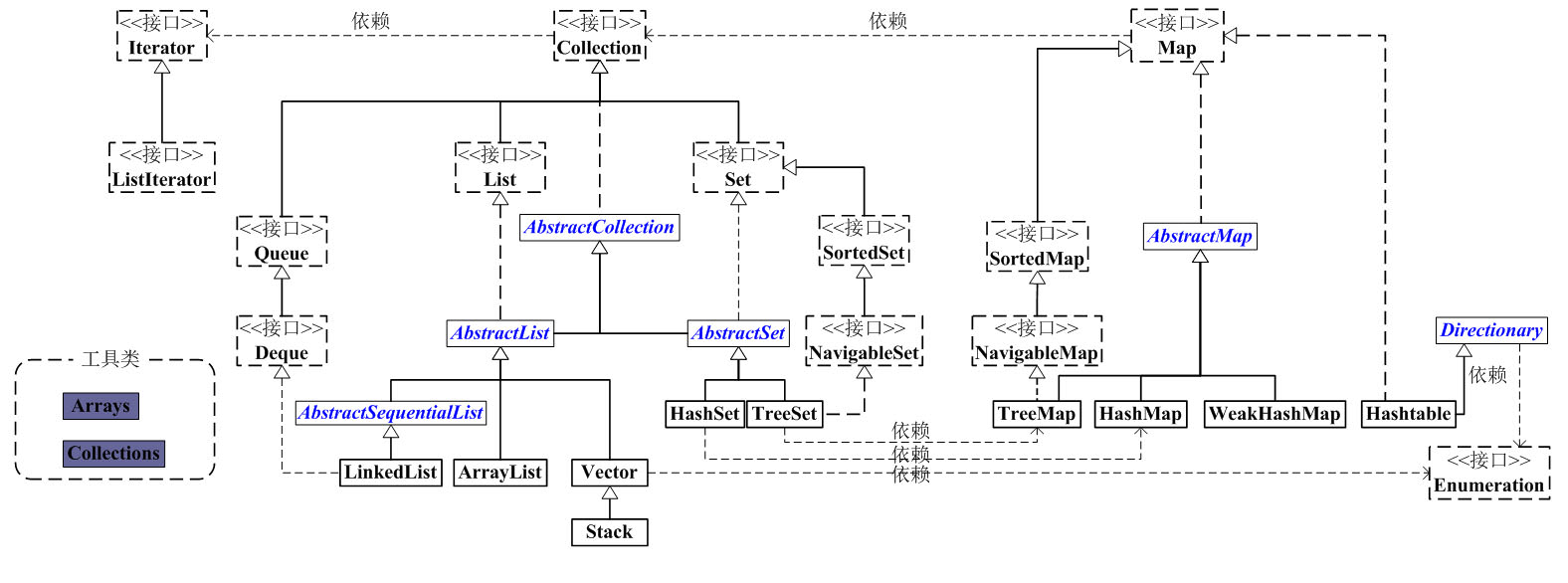
大致说明:
看上面的框架图,先抓住它的主干,即Collection和Map。
1、Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。Collection包含了List和Set两大分支。
-
(1)List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。List的实现类有LinkedList, ArrayList, Vector, Stack。
-
(2)Set是一个不允许有重复元素的集合。Set的实现类有HastSet和TreeSet。HashSet依赖于HashMap,它实际上是通过HashMap实现的;TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
2、Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。Hashtable虽然继承于Dictionary,但它实现了Map接口。
3、接下来,再看Iterator。它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是**因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。**ListIterator是专门为遍历List而存在的。
4、再看Enumeration,它是JDK 1.0引入的抽象类。作用和Iterator一样,也是遍历集合;但是Enumeration的功能要比Iterator少。在上面的框图中,Enumeration只能在Hashtable, Vector, Stack中使用。
5、最后,看Arrays和Collections。它们是操作数组、集合的两个工具类。
有了上面的整体框架之后,我们接下来对每个类分别进行分析。
3. Collection接口
Collection接口是处理对象集合的根接口,其中定义了很多对元素进行操作的方法。Collection接口有两个主要的子接口List和Set,注意Map不是Collection的子接口,这个要牢记。
Collection接口中的方法如下:

其中,有几个比较常用的方法,比如方法add()添加一个元素到集合中,addAll()将指定集合中的所有元素添加到集合中,contains()方法检测集合中是否包含指定的元素,toArray()方法返回一个表示集合的数组。
另外,Collection中有一个iterator()函数,它的作用是返回一个Iterator接口。通常,我们通过Iterator迭代器来遍历集合。ListIterator是List接口所特有的,在List接口中,通过ListIterator()返回一个ListIterator对象。
Collection接口有两个常用的子接口,下面详细介绍。
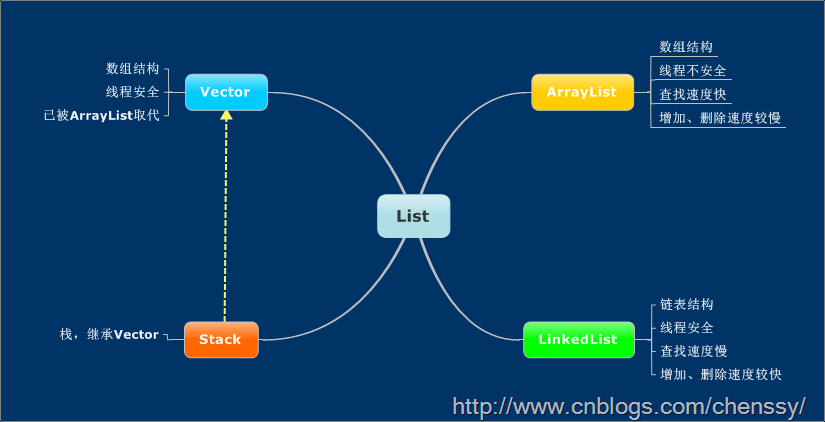
3.1 List接口
List集合代表一个有序集合,集合中每个元素都有其对应的顺序索引。List集合允许使用重复元素,可以通过索引来访问指定位置的集合元素。
List接口继承于Collection接口,它可以定义一个允许重复的有序集合。因为List中的元素是有序的,所以我们可以通过使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
List接口为Collection直接接口。List所代表的是有序的Collection,即它用某种特定的插入顺序来维护元素顺序。用户可以对列表中每个元素的插入位置进行精确地控制,同时可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
-
(1)ArrayList
ArrayList是一个动态数组,也是我们最常用的集合。它允许任何符合规则的元素插入甚至包括null。每一个ArrayList都有一个初始容量(10),该容量代表了数组的大小。随着容器中的元素不断增加,容器的大小也会随着增加。在每次向容器中增加元素的同时都会进行容量检查,当快溢出时,就会进行扩容操作。所以如果我们明确所插入元素的多少,最好指定一个初始容量值,避免过多的进行扩容操作而浪费时间、效率。size、isEmpty、get、set、iterator 和 listIterator 操作都以固定时间运行。add 操作以分摊的固定时间运行,也就是说,添加 n 个元素需要 O(n) 时间(由于要考虑到扩容,所以这不只是添加元素会带来分摊固定时间开销那样简单)。
ArrayList擅长于随机访问。同时ArrayList是非同步的。
-
(2)LinkedList
同样实现List接口的LinkedList与ArrayList不同,ArrayList是一个动态数组,而LinkedList是一个双向链表。所以它除了有ArrayList的基本操作方法外还额外提供了get,remove,insert方法在LinkedList的首部或尾部。由于实现的方式不同,LinkedList不能随机访问,它所有的操作都是要按照双重链表的需要执行。在列表中索引的操作将从开头或结尾遍历列表(从靠近指定索引的一端)。这样做的好处就是可以通过较低的代价在List中进行插入和删除操作。
与ArrayList一样,LinkedList也是非同步的。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList(…)); -
(3)Vector
与ArrayList相似,但是Vector是同步的。所以说Vector是线程安全的动态数组。它的操作与ArrayList几乎一样。 -
(4)Stack
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop 方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
3.2 Set接口
-
Set是一种不包括重复元素的Collection。它维持它自己的内部排序,所以随机访问没有任何意义。与List一样,它同样允许null的存在但是仅有一个。由于Set接口的特殊性, 所有传入Set集合中的元素都必须不同,同时要注意任何可变对象,如果在对集合中元素进行操作时,导致e1.equals(e2)==true,则必定会产生某些问题。Set接口有三个具体实现类,分别是散列集HashSet、链式散列集LinkedHashSet和树形集TreeSet。
-
Set是一种不包含重复的元素的Collection,无序,即任意的两个元素e1和e2都有e1.equals(e2)=false,Set最多有一个null元素。需要注意的是:虽然Set中元素没有顺序,但是元素在set中的位置是由该元素的HashCode决定的,其具体位置其实是固定的。
此外需要说明一点,在set接口中的不重复是有特殊要求的。
举一个例子:对象A和对象B,本来是不同的两个对象,正常情况下它们是能够放入到Set里面的,但是如果对象A和B的都重写了hashcode和equals方法,并且重写后的hashcode和equals方法是相同的话。那么A和B是不能同时放入到Set集合中去的,也就是Set集合中的去重和hashcode与equals方法直接相关。
为了更好地理解,请看下面的例子:
public class Test{
public static void main(String[] args) {
Set<String> set=new HashSet<String>();
set.add("Hello");
set.add("world");
set.add("Hello");
System.out.println("集合的尺寸为:"+set.size());
System.out.println("集合中的元素为:"+set.toString());
}
}
运行结果:
集合的尺寸为:2
集合中的元素为:[world, Hello]
分析:由于String类中重写了hashcode和equals方法,用来比较指向的字符串对象所存储的字符串是否相等。所以这里的第二个Hello是加不进去的。
再看一个例子:
public class TestSet {
public static void main(String[] args){
Set<String> books = new HashSet<String>();
//添加一个字符串对象
books.add(new String("Struts2权威指南"));
//再次添加一个字符串对象,
//因为两个字符串对象通过equals方法比较相等,所以添加失败,返回false
boolean result = books.add(new String("Struts2权威指南"));
System.out.println(result);
//下面输出看到集合只有一个元素
System.out.println(books);
}
}
运行结果:
false
[Struts2权威指南]
说明:程序中,book集合两次添加的字符串对象明显不是一个对象(程序通过new关键字来创建字符串对象),当使用==运算符判断返回false,使用equals方法比较返回true,所以不能添加到Set集合中,最后只能输出一个元素。
-
(1)HashSet
-
HashSet 是一个没有重复元素的集合。它是由HashMap实现的,不保证元素的顺序(这里所说的没有顺序是指:元素插入的顺序与输出的顺序不一致),而且HashSet允许使用null 元素。HashSet是非同步的,如果多个线程同时访问一个哈希set,而其中至少一个线程修改了该set,那么它必须保持外部同步。** HashSet按Hash算法来存储集合的元素,因此具有很好的存取和查找性能。**
-
HashSet的实现方式大致如下,通过一个HashMap存储元素,元素是存放在HashMap的Key中,而Value统一使用一个Object对象。
HashSet使用和理解中容易出现的误区:
-
a. HashSet中存放null值
HashSet中是允许存入null值的,但是在HashSet中仅仅能够存入一个null值。 -
b.HashSet中存储元素的位置是固定的
HashSet中存储的元素的是无序的,这个没什么好说的,但是由于HashSet底层是基于Hash算法实现的,使用了hashcode,所以HashSet中相应的元素的位置是固定的。 -
c.必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
-
-
(2)LinkedHashSet
LinkedHashSet继承自HashSet,其底层是基于LinkedHashMap来实现的,有序,非同步。LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。 -
(3)TreeSet
TreeSet是一个有序集合,其底层是基于TreeMap实现的,非线程安全。TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。当我们构造TreeSet时,若使用不带参数的构造函数,则TreeSet的使用自然比较器;若用户需要使用自定义的比较器,则需要使用带比较器的参数。
注意:TreeSet集合不是通过hashcode和equals函数来比较元素的.它是通过compare或者comparaeTo函数来判断元素是否相等.compare函数通过判断两个对象的id,相同的id判断为重复元素,不会被加入到集合中。
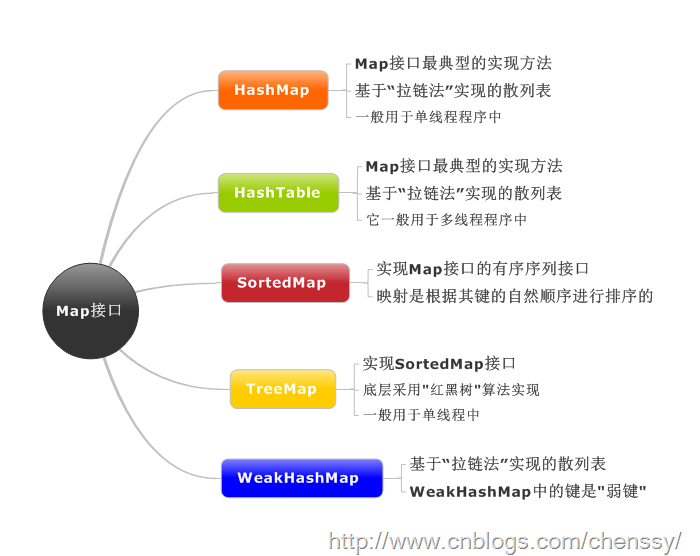
4. Map接口
- Map与List、Set接口不同,它是由一系列键值对组成的集合,提供了key到Value的映射。同时它也没有继承Collection。
- 在Map中它保证了key与value之间的一一对应关系。也就是说一个key对应一个value,所以它不能存在相同的key值,当然value值可以相同。
4.1 HashMap
- 以哈希表数据结构实现,查找对象时通过哈希函数计算其位置,它是为快速查询而设计的,其内部定义了一个hash表数组(Entry[] table),元素会通过哈希转换函数将元素的哈希地址转换成数组中存放的索引,如果有冲突,则使用散列链表的形式将所有相同哈希地址的元素串起来,可能通过查看HashMap.Entry的源码它是一个单链表结构。
4.2 LinkedHashMap
-
LinkedHashMap是HashMap的一个子类,它保留插入的顺序,如果需要输出的顺序和输入时的相同,那么就选用LinkedHashMap。
-
LinkedHashMap是Map接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现提供所有可选的映射操作,并允许使用null值和null键。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
-
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。
-
根据链表中元素的顺序可以分为:按插入顺序的链表,和按访问顺序(调用get方法)的链表。默认是按插入顺序排序,如果指定按访问顺序排序,那么调用get方法后,会将这次访问的元素移至链表尾部,不断访问可以形成按访问顺序排序的链表。
注意,此实现不是同步的。如果多个线程同时访问链接的哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。
由于LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能,但在迭代访问Map里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
4.3 TreeMap
-
TreeMap 是一个有序的key-value集合,非同步,基于红黑树(Red-Black tree)实现,每一个key-value节点作为红黑树的一个节点。TreeMap存储时会进行排序的,会根据key来对key-value键值对进行排序,其中排序方式也是分为两种,一种是自然排序,一种是定制排序,具体取决于使用的构造方法。
-
自然排序:TreeMap中所有的key必须实现Comparable接口,并且所有的key都应该是同一个类的对象,否则会报ClassCastException异常。
-
定制排序:定义TreeMap时,创建一个comparator对象,该对象对所有的treeMap中所有的key值进行排序,采用定制排序的时候不需要TreeMap中所有的key必须实现Comparable接口。
-
TreeMap判断两个元素相等的标准:两个key通过compareTo()方法返回0,则认为这两个key相等。
如果使用自定义的类来作为TreeMap中的key值,且想让TreeMap能够良好的工作,则必须重写自定义类中的equals()方法,TreeMap中判断相等的标准是:两个key通过equals()方法返回为true,并且通过compareTo()方法比较应该返回为0。
5. Iterator 与 ListIterator详解
5.1 Iterator
Iterator的定义如下:
public interface Iterator<E> {}
Iterator是一个接口,它是集合的迭代器。集合可以通过Iterator去遍历集合中的元素。Iterator提供的API接口如下:
- boolean hasNext():判断集合里是否存在下一个元素。如果有,hasNext()方法返回 true。
- Object next():返回集合里下一个元素。
- void remove():删除集合里上一次next方法返回的元素。
使用示例:
public class IteratorExample {
public static void main(String[] args) {
ArrayList<String> a = new ArrayList<String>();
a.add("aaa");
a.add("bbb");
a.add("ccc");
System.out.println("Before iterate : " + a);
Iterator<String> it = a.iterator();
while (it.hasNext()) {
String t = it.next();
if ("bbb".equals(t)) {
it.remove();
}
}
System.out.println("After iterate : " + a);
}
}
输出结果如下:
Before iterate : [aaa, bbb, ccc]
After iterate : [aaa, ccc]
注意:
-
(1)Iterator只能单向移动。
-
(2)Iterator.remove()是唯一安全的方式来在迭代过程中修改集合;如果在迭代过程中以任何其它的方式修改了基本集合将会产生未知的行为。而且每调用一次next()方法,remove()方法只能被调用一次,如果违反这个规则将抛出一个异常。
5.2 ListIterator
- ListIterator是一个功能更加强大的迭代器, 它继承于Iterator接口,只能用于各种List类型的访问。可以通过调用listIterator()方法产生一个指向List开始处的ListIterator, 还可以调用listIterator(n)方法创建一个一开始就指向列表索引为n的元素处的ListIterator.
ListIterator接口定义如下:
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void remove();
void set(E e);
void add(E e);
}
由以上定义我们可以推出ListIterator可以:
-
(1)双向移动(向前/向后遍历).
-
(2)产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引.
-
(3)可以使用set()方法替换它访问过的最后一个元素.
-
(4)可以使用add()方法在next()方法返回的元素之前或previous()方法返回的元素之后插入一个元素.
使用示例:
public class ListIteratorExample {
public static void main(String[] args) {
ArrayList<String> a = new ArrayList<String>();
a.add("aaa");
a.add("bbb");
a.add("ccc");
System.out.println("Before iterate : " + a);
ListIterator<String> it = a.listIterator();
while (it.hasNext()) {
System.out.println(it.next() + ", " + it.previousIndex() + ", " + it.nextIndex());
}
while (it.hasPrevious()) {
System.out.print(it.previous() + " ");
}
System.out.println();
it = a.listIterator(1);
while (it.hasNext()) {
String t = it.next();
System.out.println(t);
if ("ccc".equals(t)) {
it.set("nnn");
} else {
it.add("kkk");
}
}
System.out.println("After iterate : " + a);
}
}
输出结果如下:
Before iterate : [aaa, bbb, ccc]
aaa, 0, 1
bbb, 1, 2
ccc, 2, 3
ccc bbb aaa
bbb
ccc
After iterate : [aaa, bbb, kkk, nnn]
6. 异同点
6.1ArrayList和LinkedList
- (1)ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- (2)对于随机访问get和set,ArrayList绝对优于LinkedList,因为LinkedList要移动指针。
- (3)对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。
但若是批量随机的插入删除数据,LinkedList的速度大大优于ArrayList。因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
6.2 HashTable与HashMap
相同点:
- (1)都实现了Map、Cloneable、java.io.Serializable接口。
- (2)都是存储"键值对(key-value)"的散列表,而且都是采用拉链法实现的。
不同点:
-
(1)历史原因:HashTable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现 。
-
(2)同步性:HashTable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的 。
-
(3)对null值的处理:HashMap的key、value都可为null,HashTable的key、value都不可为null 。
-
(4)基类不同:HashMap继承于AbstractMap,而Hashtable继承于Dictionary。
Dictionary是一个抽象类,它直接继承于Object类,没有实现任何接口。Dictionary类是JDK 1.0的引入的。
虽然Dictionary也支持“添加key-value键值对”、“获取value”、“获取大小”等基本操作,但它的API函数比Map少;而且Dictionary一般是通过Enumeration(枚举类)去遍历,Map则是通过Iterator(迭代M器)去遍历。
然而由于Hashtable也实现了Map接口,所以,它即支持Enumeration遍历,也支持Iterator遍历。
AbstractMap是一个抽象类,它实现了Map接口的绝大部分API函数;为Map的具体实现类提供了极大的便利。它是JDK 1.2新增的类。
-
(5)支持的遍历种类不同:HashMap只支持Iterator(迭代器)遍历。而Hashtable支持Iterator(迭代器)和Enumeration(枚举器)两种方式遍历。
6.3 HashMap、Hashtable、LinkedHashMap和TreeMap比较
-
Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。
-
Hashtable 与 HashMap类似,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢。
-
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。对于LinkedHashMap而言,它继承与HashMap、底层使用哈希表与双向链表来保存所有元素。其基本操作与父类HashMap相似,它通过重写父类相关的方法,来实现自己的链接列表特性。
-
TreeMap实现SortMap接口,内部实现是红黑树。能够把它保存的记录根据键排序,默认是按键值的****升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。TreeMap不允许key的值为null。非同步的。
-
一般情况下,我们用的最多的是HashMap,HashMap里面存入的键值对在取出的时候是随机的,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列,像连接池中可以应用。import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.util.TreeMap; public class MapTest { public static void main(String[] args) { //HashMap HashMap<String,String> hashMap = new HashMap(); hashMap.put("4", "d"); hashMap.put("3", "c"); hashMap.put("2", "b"); hashMap.put("1", "a"); Iterator<String> iteratorHashMap = hashMap.keySet().iterator(); System.out.println("HashMap-->"); while (iteratorHashMap.hasNext()){ Object key1 = iteratorHashMap.next(); System.out.println(key1 + "--" + hashMap.get(key1)); } //LinkedHashMap LinkedHashMap<String,String> linkedHashMap = new LinkedHashMap(); linkedHashMap.put("4", "d"); linkedHashMap.put("3", "c"); linkedHashMap.put("2", "b"); linkedHashMap.put("1", "a"); Iterator<String> iteratorLinkedHashMap = linkedHashMap.keySet().iterator(); System.out.println("LinkedHashMap-->"); while (iteratorLinkedHashMap.hasNext()){ Object key2 = iteratorLinkedHashMap.next(); System.out.println(key2 + "--" + linkedHashMap.get(key2)); } //TreeMap TreeMap<String,String> treeMap = new TreeMap(); treeMap.put("4", "d"); treeMap.put("3", "c"); treeMap.put("2", "b"); treeMap.put("1", "a"); Iterator<String> iteratorTreeMap = treeMap.keySet().iterator(); System.out.println("TreeMap-->"); while (iteratorTreeMap.hasNext()){ Object key3 = iteratorTreeMap.next(); System.out.println(key3 + "--" + treeMap.get(key3)); } } }
输出结果为:
HashMap-->
3--c
2--b
1--a
4--d
LinkedHashMap-->
4--d
3--c
2--b
1--a
TreeMap-->
1--a
2--b
3--c
4--d
6.4 HashSet、LinkedHashSet、TreeSet比较
-
Set接口
Set不允许包含相同的元素,如果试图把两个相同元素加入同一个集合中,add方法返回false。
Set判断两个对象相同不是使用==运算符,而是根据equals方法。也就是说,只要两个对象用equals方法比较返回true,Set就不会接受这两个对象。 -
HashSet
HashSet有以下特点:
-> 不能保证元素的排列顺序,顺序有可能发生变化。
-> 不是同步的。
-> 集合元素可以是null,但只能放入一个null。
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值也相等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。其规则是如果两个对象通过equals方法比较返回true时,其hashCode也应该相同。
另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。 -
LinkedHashSet
LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。 -
TreeSet类
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。
TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0。 -
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是负数,则表明obj1小于obj2。如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0。 -
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法。package com.test; import java.util.HashSet; import java.util.LinkedHashSet; import java.util.TreeSet; /** * @description 几个set的比较 * HashSet:哈希表是通过使用称为散列法的机制来存储信息的,元素并没有以某种特定顺序来存放; * LinkedHashSet:以元素插入的顺序来维护集合的链接表,允许以插入的顺序在集合中迭代; * TreeSet:提供一个使用树结构存储Set接口的实现,对象以升序顺序存储,访问和遍历的时间很快。 * @author Zhou-Jingxian * */ public class SetDemo { public static void main(String[] args) { HashSet<String> hs = new HashSet<String>(); hs.add("B"); hs.add("A"); hs.add("D"); hs.add("E"); hs.add("C"); hs.add("F"); System.out.println("HashSet 顺序:\n"+hs); LinkedHashSet<String> lhs = new LinkedHashSet<String>(); lhs.add("B"); lhs.add("A"); lhs.add("D"); lhs.add("E"); lhs.add("C"); lhs.add("F"); System.out.println("LinkedHashSet 顺序:\n"+lhs); TreeSet<String> ts = new TreeSet<String>(); ts.add("B"); ts.add("A"); ts.add("D"); ts.add("E"); ts.add("C"); ts.add("F"); System.out.println("TreeSet 顺序:\n"+ts); } }
输出结果:
HashSet 顺序:[D, E, F, A, B, C]
LinkedHashSet 顺序:[B, A, D, E, C, F]
TreeSet 顺序:[A, B, C, D, E, F]
6.5 Iterator和ListIterator区别
我们在使用List,Set的时候,为了实现对其数据的遍历,我们经常使用到了Iterator(迭代器)。使用迭代器,你不需要干涉其遍历的过程,只需要每次取出一个你想要的数据进行处理就可以了。但是在使用的时候也是有不同的。
List和Set都有iterator()来取得其迭代器。对List来说,你也可以通过listIterator()取得其迭代器,两种迭代器在有些时候是不能通用的,Iterator和ListIterator主要区别在以下方面:
- (1)ListIterator有add()方法,可以向List中添加对象,而Iterator不能
- (2)ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
- (3)ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
- (4)都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
因为ListIterator的这些功能,可以实现对LinkedList等List数据结构的操作。其实,数组对象也可以用迭代器来实现。
6.6 Collection 和 Collections区别
-
(1)java.util.Collection 是一个集合接口(集合类的一个顶级接口)。它提供了对集合对象进行基本操作的通用接口方法。Collection接口在Java 类库中有很多具体的实现。Collection接口的意义是为各种具体的集合提供了最大化的统一操作方式,其直接继承接口有List与Set。
Collection
├List
│├LinkedList
│├ArrayList
│└Vector
│ └Stack
└Set -
(2)java.util.Collections 是一个包装类(工具类/帮助类)。它包含有各种有关集合操作的静态多态方法。此类不能实例化,就像一个工具类,用于对集合中元素进行排序、搜索以及线程安全等各种操作,服务于Java的Collection框架。
代码示例:import java.util.ArrayList; import java.util.Collections; import java.util.List; public class TestCollections { public static void main(String args[]) { //注意List是实现Collection接口的 List list = new ArrayList(); double array[] = { 112, 111, 23, 456, 231 }; for (int i = 0; i < array.length; i++) { list.add(new Double(array[i])); } Collections.sort(list); for (int i = 0; i < array.length; i++) { System.out.println(list.get(i)); } // 结果:23.0 111.0 112.0 231.0 456.0 } }
7. 多线程
多线程
本文主要讲java中多线程的使用方法、线程同步、线程数据传递、线程状态及相应的线程函数用法、概述等。首先让我们来了解下在操作系统中进程和线程的区别:
进程:每个进程都有独立的代码和数据空间(进程上下文),进程间的切换会有较大的开销,一个进程包含1–n个线程。(进程是资源分配的最小单位)
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换开销小。(线程是cpu调度的最小单位)
线程和进程一样分为五个阶段:创建、就绪、运行、阻塞、终止。
多进程是指操作系统能同时运行多个任务(程序)。
多线程是指在同一程序中有多个顺序流在执行。
在java中要想实现多线程,有两种手段,一种是继续Thread类,另外一种是实现Runable接口.(其实准确来讲,应该有三种,还有一种是实现Callable接口,并与Future、线程池结合使用,此文这里不讲这个。
一、扩展java.lang.Thread类
这里继承Thread类的方法是比较常用的一种,如果说你只是想起一条线程。没有什么其它特殊的要求,那么可以使用Thread.(笔者推荐使用Runable,后头会说明为什么)。下面来看一个简单的实例
package com.multithread.learning;
/**
*@functon 多线程学习
*@author 林炳文
*@time 2015.3.9
*/
class Thread1 extends Thread{
private String name;
public Thread1(String name) {
this.name=name;
}
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(name + "运行 : " + i);
try {
sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
Thread1 mTh1=new Thread1("A");
Thread1 mTh2=new Thread1("B");
mTh1.start();
mTh2.start();
}
}
输出:
A运行 : 0
B运行 : 0
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
B运行 : 1
B运行 : 2
B运行 : 3
B运行 : 4
再运行一下:
A运行 : 0
B运行 : 0
B运行 : 1
B运行 : 2
B运行 : 3
B运行 : 4
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
说明:
程序启动运行main时候,java虚拟机启动一个进程,主线程main在main()调用时候被创建。随着调用MitiSay的两个对象的start方法,另外两个线程也启动了,这样,整个应用就在多线程下运行。
注意:start()方法的调用后并不是立即执行多线程代码,而是使得该线程变为可运行态(Runnable),什么时候运行是由操作系统决定的。
从程序运行的结果可以发现,多线程程序是乱序执行。因此,只有乱序执行的代码才有必要设计为多线程。
Thread.sleep()方法调用目的是不让当前线程独自霸占该进程所获取的CPU资源,以留出一定时间给其他线程执行的机会。
实际上所有的多线程代码执行顺序都是不确定的,每次执行的结果都是随机的。
但是start方法重复调用的话,会出现java.lang.IllegalThreadStateException异常。
Thread1 mTh1=new Thread1("A");
Thread1 mTh2=mTh1;
mTh1.start();
mTh2.start();
输出:
Exception in thread "main" java.lang.IllegalThreadStateException
at java.lang.Thread.start(Unknown Source)
at com.multithread.learning.Main.main(Main.java:31)
A运行 : 0
A运行 : 1
A运行 : 2
A运行 : 3
A运行 : 4
二、实现java.lang.Runnable接口
采用Runnable也是非常常见的一种,我们只需要重写run方法即可。下面也来看个实例。
/**
*@functon 多线程学习
*@author 林炳文
*@time 2015.3.9
*/
package com.multithread.runnable;
class Thread2 implements Runnable{
private String name;
public Thread2(String name) {
this.name=name;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
System.out.println(name + "运行 : " + i);
try {
Thread.sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Main {
public static void main(String[] args) {
new Thread(new Thread2("C")).start();
new Thread(new Thread2("D")).start();
}
}
输出:
C运行 : 0
D运行 : 0
D运行 : 1
C运行 : 1
D运行 : 2
C运行 : 2
D运行 : 3
C运行 : 3
D运行 : 4
C运行 : 4
说明:
Thread2类通过实现Runnable接口,使得该类有了多线程类的特征。run()方法是多线程程序的一个约定。所有的多线程代码都在run方法里面。Thread类实际上也是实现了Runnable接口的类。
在启动的多线程的时候,需要先通过Thread类的构造方法Thread(Runnable target) 构造出对象,然后调用Thread对象的start()方法来运行多线程代码。
实际上所有的多线程代码都是通过运行Thread的start()方法来运行的。因此,不管是扩展Thread类还是实现Runnable接口来实现多线程,最终还是通过Thread的对象的API来控制线程的,熟悉Thread类的API是进行多线程编程的基础。
三、Thread和Runnable的区别
如果一个类继承Thread,则不适合资源共享。但是如果实现了Runable接口的话,则很容易的实现资源共享。
总结:
实现Runnable接口比继承Thread类所具有的优势:
1):适合多个相同的程序代码的线程去处理同一个资源
2):可以避免java中的单继承的限制
3):增加程序的健壮性,代码可以被多个线程共享,代码和数据独立
4):线程池只能放入实现Runable或callable类线程,不能直接放入继承Thread的类
提醒一下大家:main方法其实也是一个线程。在java中所以的线程都是同时启动的,至于什么时候,哪个先执行,完全看谁先得到CPU的资源。
在java中,每次程序运行至少启动2个线程。一个是main线程,一个是垃圾收集线程。因为每当使用java命令执行一个类的时候,实际上都会启动一个JVM,每一个jVM实习在就是在操作系统中启动了一个进程。
四、线程状态转换
下面的这个图非常重要!你如果看懂了这个图,那么对于多线程的理解将会更加深刻!
1、新建状态(New):新创建了一个线程对象。
2、就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3、运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
4、阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。(wait会释放持有的锁)
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。(注意,sleep是不会释放持有的锁)
5、死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
五、线程调度
线程的调度
1、调整线程优先级:Java线程有优先级,优先级高的线程会获得较多的运行机会。
Java线程的优先级用整数表示,取值范围是1~10,Thread类有以下三个静态常量:
static int MAX_PRIORITY
线程可以具有的最高优先级,取值为10。
static int MIN_PRIORITY
线程可以具有的最低优先级,取值为1。
static int NORM_PRIORITY
分配给线程的默认优先级,取值为5。
Thread类的setPriority()和getPriority()方法分别用来设置和获取线程的优先级。
每个线程都有默认的优先级。主线程的默认优先级为Thread.NORM_PRIORITY。
线程的优先级有继承关系,比如A线程中创建了B线程,那么B将和A具有相同的优先级。
JVM提供了10个线程优先级,但与常见的操作系统都不能很好的映射。如果希望程序能移植到各个操作系统中,应该仅仅使用Thread类有以下三个静态常量作为优先级,这样能保证同样的优先级采用了同样的调度方式。
2、线程睡眠:Thread.sleep(long millis)方法,使线程转到阻塞状态。millis参数设定睡眠的时间,以毫秒为单位。当睡眠结束后,就转为就绪(Runnable)状态。sleep()平台移植性好。
3、线程等待:Object类中的wait()方法,导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 唤醒方法。这个两个唤醒方法也是Object类中的方法,行为等价于调用 wait(0) 一样。
4、线程让步:Thread.yield() 方法,暂停当前正在执行的线程对象,把执行机会让给相同或者更高优先级的线程。
5、线程加入:join()方法,等待其他线程终止。在当前线程中调用另一个线程的join()方法,则当前线程转入阻塞状态,直到另一个进程运行结束,当前线程再由阻塞转为就绪状态。
6、线程唤醒:Object类中的notify()方法,唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程。选择是任意性的,并在对实现做出决定时发生。线程通过调用其中一个 wait 方法,在对象的监视器上等待。 直到当前的线程放弃此对象上的锁定,才能继续执行被唤醒的线程。被唤醒的线程将以常规方式与在该对象上主动同步的其他所有线程进行竞争;例如,唤醒的线程在作为锁定此对象的下一个线程方面没有可靠的特权或劣势。类似的方法还有一个notifyAll(),唤醒在此对象监视器上等待的所有线程。
注意:Thread中suspend()和resume()两个方法在JDK1.5中已经废除,不再介绍。因为有死锁倾向。
六、常用函数说明
①sleep(long millis): 在指定的毫秒数内让当前正在执行的线程休眠(暂停执行)
②join():指等待t线程终止。
使用方式。
join是Thread类的一个方法,启动线程后直接调用,即join()的作用是:“等待该线程终止”,这里需要理解的就是该线程是指的主线程等待子线程的终止。也就是在子线程调用了join()方法后面的代码,只有等到子线程结束了才能执行。
Thread t = new AThread(); t.start(); t.join();
为什么要用join()方法
在很多情况下,主线程生成并起动了子线程,如果子线程里要进行大量的耗时的运算,主线程往往将于子线程之前结束,但是如果主线程处理完其他的事务后,需要用到子线程的处理结果,也就是主线程需要等待子线程执行完成之后再结束,这个时候就要用到join()方法了。
不加join。
/**
*@functon 多线程学习,join
*@author 林炳文
*@time 2015.3.9
*/
package com.multithread.join;
class Thread1 extends Thread{
private String name;
public Thread1(String name) {
super(name);
this.name=name;
}
public void run() {
System.out.println(Thread.currentThread().getName() + " 线程运行开始!");
for (int i = 0; i < 5; i++) {
System.out.println("子线程"+name + "运行 : " + i);
try {
sleep((int) Math.random() * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().getName() + " 线程运行结束!");
}
}
public class Main {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName()+"主线程运行开始!");
Thread1 mTh1=new Thread1("A");
Thread1 mTh2=new Thread1("B");
mTh1.start();
mTh2.start();
System.out.println(Thread.currentThread().getName()+ "主线程运行结束!");
}
}
输出结果:
main主线程运行开始!
main主线程运行结束!
B 线程运行开始!
子线程B运行 : 0
A 线程运行开始!
子线程A运行 : 0
子线程B运行 : 1
子线程A运行 : 1
子线程A运行 : 2
子线程A运行 : 3
子线程A运行 : 4
A 线程运行结束!
子线程B运行 : 2
子线程B运行 : 3
子线程B运行 : 4
B 线程运行结束!
发现主线程比子线程早结束
加join
public class Main {
public static void main(String[] args) {
System.out.println(Thread.currentThread().getName()+"主线程运行开始!");
Thread1 mTh1=new Thread1("A");
Thread1 mTh2=new Thread1("B");
mTh1.start();
mTh2.start();
try {
mTh1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
mTh2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+ "主线程运行结束!");
}
}
运行结果:
main主线程运行开始!
A 线程运行开始!
子线程A运行 : 0
B 线程运行开始!
子线程B运行 : 0
子线程A运行 : 1
子线程B运行 : 1
子线程A运行 : 2
子线程B运行 : 2
子线程A运行 : 3
子线程B运行 : 3
子线程A运行 : 4
子线程B运行 : 4
A 线程运行结束!
主线程一定会等子线程都结束了才结束
③yield():暂停当前正在执行的线程对象,并执行其他线程。
Thread.yield()方法作用是:暂停当前正在执行的线程对象,并执行其他线程。
yield()应该做的是让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
结论:yield()从未导致线程转到等待/睡眠/阻塞状态。在大多数情况下,yield()将导致线程从运行状态转到可运行状态,但有可能没有效果。可看上面的图。
/**
*@functon 多线程学习 yield
*@author 林炳文
*@time 2015.3.9
*/
package com.multithread.yield;
class ThreadYield extends Thread{
public ThreadYield(String name) {
super(name);
}
@Override
public void run() {
for (int i = 1; i <= 50; i++) {
System.out.println("" + this.getName() + "-----" + i);
// 当i为30时,该线程就会把CPU时间让掉,让其他或者自己的线程执行(也就是谁先抢到谁执行)
if (i ==30) {
this.yield();
}
}
}
}
public class Main {
public static void main(String[] args) {
ThreadYield yt1 = new ThreadYield("张三");
ThreadYield yt2 = new ThreadYield("李四");
yt1.start();
yt2.start();
}
}
运行结果:
第一种情况:李四(线程)当执行到30时会CPU时间让掉,这时张三(线程)抢到CPU时间并执行。
第二种情况:李四(线程)当执行到30时会CPU时间让掉,这时李四(线程)抢到CPU时间并执行。
sleep()和yield()的区别
sleep()和yield()的区别):sleep()使当前线程进入停滞状态,所以执行sleep()的线程在指定的时间内肯定不会被执行;yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
sleep 方法使当前运行中的线程睡眼一段时间,进入不可运行状态,这段时间的长短是由程序设定的,yield 方法使当前线程让出 CPU 占有权,但让出的时间是不可设定的。实际上,yield()方法对应了如下操作:先检测当前是否有相同优先级的线程处于同可运行状态,如有,则把 CPU 的占有权交给此线程,否则,继续运行原来的线程。所以yield()方法称为“退让”,它把运行机会让给了同等优先级的其他线程
另外,sleep 方法允许较低优先级的线程获得运行机会,但 yield() 方法执行时,当前线程仍处在可运行状态,所以,不可能让出较低优先级的线程些时获得 CPU 占有权。在一个运行系统中,如果较高优先级的线程没有调用 sleep 方法,又没有受到 I\O 阻塞,那么,较低优先级线程只能等待所有较高优先级的线程运行结束,才有机会运行。
④setPriority(): 更改线程的优先级。
MIN_PRIORITY = 1
NORM_PRIORITY = 5
MAX_PRIORITY = 10
用法:
Thread4 t1 = new Thread4("t1");
Thread4 t2 = new Thread4("t2");
t1.setPriority(Thread.MAX_PRIORITY);
t2.setPriority(Thread.MIN_PRIORITY);
⑤interrupt():不要以为它是中断某个线程!它只是线线程发送一个中断信号,让线程在无限等待时(如死锁时)能抛出抛出,从而结束线程,但是如果你吃掉了这个异常,那么这个线程还是不会中断的!
⑥wait()
Obj.wait(),与Obj.notify()必须要与synchronized(Obj)一起使用,也就是wait,与notify是针对已经获取了Obj锁进行操作,从语法角度来说就是Obj.wait(),Obj.notify必须在synchronized(Obj){…}语句块内。从功能上来说wait就是说线程在获取对象锁后,主动释放对象锁,同时本线程休眠。直到有其它线程调用对象的notify()唤醒该线程,才能继续获取对象锁,并继续执行。相应的notify()就是对对象锁的唤醒操作。但有一点需要注意的是notify()调用后,并不是马上就释放对象锁的,而是在相应的synchronized(){}语句块执行结束,自动释放锁后,JVM会在wait()对象锁的线程中随机选取一线程,赋予其对象锁,唤醒线程,继续执行。这样就提供了在线程间同步、唤醒的操作。Thread.sleep()与Object.wait()二者都可以暂停当前线程,释放CPU控制权,主要的区别在于Object.wait()在释放CPU同时,释放了对象锁的控制。
单单在概念上理解清楚了还不够,需要在实际的例子中进行测试才能更好的理解。对Object.wait(),Object.notify()的应用最经典的例子,应该是三线程打印ABC的问题了吧,这是一道比较经典的面试题,题目要求如下:
建立三个线程,A线程打印10次A,B线程打印10次B,C线程打印10次C,要求线程同时运行,交替打印10次ABC。这个问题用Object的wait(),notify()就可以很方便的解决。代码如下:
/**
* wait用法
* @author DreamSea
* @time 2015.3.9
*/
package com.multithread.wait;
public class MyThreadPrinter2 implements Runnable {
private String name;
private Object prev;
private Object self;
private MyThreadPrinter2(String name, Object prev, Object self) {
this.name = name;
this.prev = prev;
this.self = self;
}
@Override
public void run() {
int count = 10;
while (count > 0) {
synchronized (prev) {
synchronized (self) {
System.out.print(name);
count--;
self.notify();
}
try {
prev.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) throws Exception {
Object a = new Object();
Object b = new Object();
Object c = new Object();
MyThreadPrinter2 pa = new MyThreadPrinter2("A", c, a);
MyThreadPrinter2 pb = new MyThreadPrinter2("B", a, b);
MyThreadPrinter2 pc = new MyThreadPrinter2("C", b, c);
new Thread(pa).start();
Thread.sleep(100); //确保按顺序A、B、C执行
new Thread(pb).start();
Thread.sleep(100);
new Thread(pc).start();
Thread.sleep(100);
}
}
输出结果:
ABCABCABCABCABCABCABCABCABCABC
先来解释一下其整体思路,从大的方向上来讲,该问题为三线程间的同步唤醒操作,主要的目的就是ThreadA->ThreadB->ThreadC->ThreadA循环执行三个线程。为了控制线程执行的顺序,那么就必须要确定唤醒、等待的顺序,所以每一个线程必须同时持有两个对象锁,才能继续执行。一个对象锁是prev,就是前一个线程所持有的对象锁。还有一个就是自身对象锁。主要的思想就是,为了控制执行的顺序,必须要先持有prev锁,也就前一个线程要释放自身对象锁,再去申请自身对象锁,两者兼备时打印,之后首先调用self.notify()释放自身对象锁,唤醒下一个等待线程,再调用prev.wait()释放prev对象锁,终止当前线程,等待循环结束后再次被唤醒。运行上述代码,可以发现三个线程循环打印ABC,共10次。程序运行的主要过程就是A线程最先运行,持有C,A对象锁,后释放A,C锁,唤醒B。线程B等待A锁,再申请B锁,后打印B,再释放B,A锁,唤醒C,线程C等待B锁,再申请C锁,后打印C,再释放C,B锁,唤醒A。看起来似乎没什么问题,但如果你仔细想一下,就会发现有问题,就是初始条件,三个线程按照A,B,C的顺序来启动,按照前面的思考,A唤醒B,B唤醒C,C再唤醒A。但是这种假设依赖于JVM中线程调度、执行的顺序。
wait和sleep区别
共同点:
- 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。
- wait()和sleep()都可以通过interrupt()方法 打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。
如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep /join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。
需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。
不同点: - Thread类的方法:sleep(),yield()等
Object的方法:wait()和notify()等 - 每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。
sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。 - wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
- sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
所以sleep()和wait()方法的最大区别是:
sleep()睡眠时,保持对象锁,仍然占有该锁;
而wait()睡眠时,释放对象锁。
但是wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态,从而使线程立刻抛出InterruptedException(但不建议使用该方法)。
sleep()方法
sleep()使当前线程进入停滞状态(阻塞当前线程),让出CUP的使用、目的是不让当前线程独自霸占该进程所获的CPU资源,以留一定时间给其他线程执行的机会;
sleep()是Thread类的Static(静态)的方法;因此他不能改变对象的机锁,所以当在一个Synchronized块中调用Sleep()方法是,线程虽然休眠了,但是对象的机锁并木有被释放,其他线程无法访问这个对象(即使睡着也持有对象锁)。
在sleep()休眠时间期满后,该线程不一定会立即执行,这是因为其它线程可能正在运行而且没有被调度为放弃执行,除非此线程具有更高的优先级。
wait()方法
wait()方法是Object类里的方法;当一个线程执行到wait()方法时,它就进入到一个和该对象相关的等待池中,同时失去(释放)了对象的机锁(暂时失去机锁,wait(long timeout)超时时间到后还需要返还对象锁);其他线程可以访问;
wait()使用notify或者notifyAlll或者指定睡眠时间来唤醒当前等待池中的线程。
wiat()必须放在synchronized block中,否则会在program runtime时扔出”java.lang.IllegalMonitorStateException“异常。
七、常见线程名词解释
主线程:JVM调用程序main()所产生的线程。
当前线程:这个是容易混淆的概念。一般指通过Thread.currentThread()来获取的进程。
后台线程:指为其他线程提供服务的线程,也称为守护线程。JVM的垃圾回收线程就是一个后台线程。用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束
前台线程:是指接受后台线程服务的线程,其实前台后台线程是联系在一起,就像傀儡和幕后操纵者一样的关系。傀儡是前台线程、幕后操纵者是后台线程。由前台线程创建的线程默认也是前台线程。可以通过isDaemon()和setDaemon()方法来判断和设置一个线程是否为后台线程。
线程类的一些常用方法:
sleep(): 强迫一个线程睡眠N毫秒。
isAlive(): 判断一个线程是否存活。
join(): 等待线程终止。
activeCount(): 程序中活跃的线程数。
enumerate(): 枚举程序中的线程。
currentThread(): 得到当前线程。
isDaemon(): 一个线程是否为守护线程。
setDaemon(): 设置一个线程为守护线程。(用户线程和守护线程的区别在于,是否等待主线程依赖于主线程结束而结束)
setName(): 为线程设置一个名称。
wait(): 强迫一个线程等待。
notify(): 通知一个线程继续运行。
setPriority(): 设置一个线程的优先级。
八、线程同步
1、synchronized关键字的作用域有二种:
1)是某个对象实例内,synchronized aMethod(){}可以防止多个线程同时访问这个对象的synchronized方法(如果一个对象有多个synchronized方法,只要一个线程访问了其中的一个synchronized方法,其它线程不能同时访问这个对象中任何一个synchronized方法)。这时,不同的对象实例的synchronized方法是不相干扰的。也就是说,其它线程照样可以同时访问相同类的另一个对象实例中的synchronized方法;
2)是某个类的范围,synchronized static aStaticMethod{}防止多个线程同时访问这个类中的synchronized static 方法。它可以对类的所有对象实例起作用。
2、除了方法前用synchronized关键字,synchronized关键字还可以用于方法中的某个区块中,表示只对这个区块的资源实行互斥访问。用法是: synchronized(this){/区块/},它的作用域是当前对象;
3、synchronized关键字是不能继承的,也就是说,基类的方法synchronized f(){} 在继承类中并不自动是synchronized f(){},而是变成了f(){}。继承类需要你显式的指定它的某个方法为synchronized方法;
Java对多线程的支持与同步机制深受大家的喜爱,似乎看起来使用了synchronized关键字就可以轻松地解决多线程共享数据同步问题。到底如何?――还得对synchronized关键字的作用进行深入了解才可定论。
总的说来,synchronized关键字可以作为函数的修饰符,也可作为函数内的语句,也就是平时说的同步方法和同步语句块。如果再细的分类,synchronized可作用于instance变量、object reference(对象引用)、static函数和class literals(类名称字面常量)身上。
在进一步阐述之前,我们需要明确几点:
A.无论synchronized关键字加在方法上还是对象上,它取得的锁都是对象,而不是把一段代码或函数当作锁――而且同步方法很可能还会被其他线程的对象访问。
B.每个对象只有一个锁(lock)与之相关联。
C.实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制。
接着来讨论synchronized用到不同地方对代码产生的影响:
假设P1、P2是同一个类的不同对象,这个类中定义了以下几种情况的同步块或同步方法,P1、P2就都可以调用它们。
1. 把synchronized当作函数修饰符时,示例代码如下:
Public synchronized void methodAAA()
{
//….
}
这也就是同步方法,那这时synchronized锁定的是哪个对象呢?它锁定的是调用这个同步方法对象。也就是说,当一个对象P1在不同的线程中执行这个同步方法时,它们之间会形成互斥,达到同步的效果。但是这个对象所属的Class所产生的另一对象P2却可以任意调用这个被加了synchronized关键字的方法。
上边的示例代码等同于如下代码:
public void methodAAA()
{
synchronized (this) // (1)
{
//…..
}
}
(1)处的this指的是什么呢?它指的就是调用这个方法的对象,如P1。可见同步方法实质是将synchronized作用于object reference。――那个拿到了P1对象锁的线程,才可以调用P1的同步方法,而对P2而言,P1这个锁与它毫不相干,程序也可能在这种情形下摆脱同步机制的控制,造成数据混乱:(
2.同步块,示例代码如下:
public void method3(SomeObject so){
synchronized(so){
//…..
}
}
这时,锁就是so这个对象,谁拿到这个锁谁就可以运行它所控制的那段代码。当有一个明确的对象作为锁时,就可以这样写程序,但当没有明确的对象作为锁,只是想让一段代码同步时,可以创建一个特殊的instance变量(它得是一个对象)来充当锁:
class Foo implements Runnable{
private byte[] lock = new byte[0]; // 特殊的instance变量
Public void methodA(){
synchronized(lock) {
//…
}
}
//…..
}
注:零长度的byte数组对象创建起来将比任何对象都经济――查看编译后的字节码:生成零长度的byte[]对象只需3条操作码,而Object lock = new Object()则需要7行操作码。
3.将synchronized作用于static 函数,示例代码如下:
Class Foo{
public synchronized static void methodAAA() // 同步的static 函数
{
//….
}
public void methodBBB(){
synchronized(Foo.class) // class literal(类名称字面常量)
}
}
代码中的methodBBB()方法是把class literal作为锁的情况,它和同步的static函数产生的效果是一样的,取得的锁很特别,是当前调用这个方法的对象所属的类(Class,而不再是由这个Class产生的某个具体对象了)。
记得在《Effective Java》一书中看到过将 Foo.class和 P1.getClass()用于作同步锁还不一样,不能用P1.getClass()来达到锁这个Class的目的。P1指的是由Foo类产生的对象。
可以推断:如果一个类中定义了一个synchronized的static函数A,也定义了一个synchronized 的instance函数B,那么这个类的同一对象Obj在多线程中分别访问A和B两个方法时,不会构成同步,因为它们的锁都不一样。A方法的锁是Obj这个对象,而B的锁是Obj所属的那个Class。
1、线程同步的目的是为了保护多个线程反问一个资源时对资源的破坏。
2、线程同步方法是通过锁来实现,每个对象都有切仅有一个锁,这个锁与一个特定的对象关联,线程一旦获取了对象锁,其他访问该对象的线程就无法再访问该对象的其他非同步方法。
3、对于静态同步方法,锁是针对这个类的,锁对象是该类的Class对象。静态和非静态方法的锁互不干预。一个线程获得锁,当在一个同步方法中访问另外对象上的同步方法时,会获取这两个对象锁。
4、对于同步,要时刻清醒在哪个对象上同步,这是关键。
5、编写线程安全的类,需要时刻注意对多个线程竞争访问资源的逻辑和安全做出正确的判断,对“原子”操作做出分析,并保证原子操作期间别的线程无法访问竞争资源。
6、当多个线程等待一个对象锁时,没有获取到锁的线程将发生阻塞。
7、死锁是线程间相互等待锁锁造成的,在实际中发生的概率非常的小。真让你写个死锁程序,不一定好使,呵呵。但是,一旦程序发生死锁,程序将死掉。
九、线程数据传递
在传统的同步开发模式下,当我们调用一个函数时,通过这个函数的参数将数据传入,并通过这个函数的返回值来返回最终的计算结果。但在多线程的异步开发模式下,数据的传递和返回和同步开发模式有很大的区别。由于线程的运行和结束是不可预料的,因此,在传递和返回数据时就无法象函数一样通过函数参数和return语句来返回数据。
9.1、通过构造方法传递数据
在创建线程时,必须要建立一个Thread类的或其子类的实例。因此,我们不难想到在调用start方法之前通过线程类的构造方法将数据传入线程。并将传入的数据使用类变量保存起来,以便线程使用(其实就是在run方法中使用)。下面的代码演示了如何通过构造方法来传递数据:
package mythread;
public class MyThread1 extends Thread
{
private String name;
public MyThread1(String name)
{
this.name = name;
}
public void run()
{
System.out.println("hello " + name);
}
public static void main(String[] args)
{
Thread thread = new MyThread1("world");
thread.start();
}
}
由于这种方法是在创建线程对象的同时传递数据的,因此,在线程运行之前这些数据就就已经到位了,这样就不会造成数据在线程运行后才传入的现象。如果要传递更复杂的数据,可以使用集合、类等数据结构。使用构造方法来传递数据虽然比较安全,但如果要传递的数据比较多时,就会造成很多不便。由于Java没有默认参数,要想实现类似默认参数的效果,就得使用重载,这样不但使构造方法本身过于复杂,又会使构造方法在数量上大增。因此,要想避免这种情况,就得通过类方法或类变量来传递数据。
9.2、通过变量和方法传递数据
向对象中传入数据一般有两次机会,第一次机会是在建立对象时通过构造方法将数据传入,另外一次机会就是在类中定义一系列的public的方法或变量(也可称之为字段)。然后在建立完对象后,通过对象实例逐个赋值。下面的代码是对MyThread1类的改版,使用了一个setName方法来设置 name变量:
package mythread;
public class MyThread2 implements Runnable
{
private String name;
public void setName(String name)
{
this.name = name;
}
public void run()
{
System.out.println("hello " + name);
}
public static void main(String[] args)
{
MyThread2 myThread = new MyThread2();
myThread.setName("world");
Thread thread = new Thread(myThread);
thread.start();
}
}
9.3、通过回调函数传递数据
上面讨论的两种向线程中传递数据的方法是最常用的。但这两种方法都是main方法中主动将数据传入线程类的。这对于线程来说,是被动接收这些数据的。然而,在有些应用中需要在线程运行的过程中动态地获取数据,如在下面代码的run方法中产生了3个随机数,然后通过Work类的process方法求这三个随机数的和,并通过Data类的value将结果返回。从这个例子可以看出,在返回value之前,必须要得到三个随机数。也就是说,这个 value是无法事先就传入线程类的。
package mythread;
class Data
{
public int value = 0;
}
class Work
{
public void process(Data data, Integer numbers)
{
for (int n : numbers)
{
data.value += n;
}
}
}
public class MyThread3 extends Thread
{
private Work work;
public MyThread3(Work work)
{
this.work = work;
}
public void run()
{
java.util.Random random = new java.util.Random();
Data data = new Data();
int n1 = random.nextInt(1000);
int n2 = random.nextInt(2000);
int n3 = random.nextInt(3000);
work.process(data, n1, n2, n3); // 使用回调函数
System.out.println(String.valueOf(n1) + "+" + String.valueOf(n2) + "+"
+ String.valueOf(n3) + "=" + data.value);
}
public static void main(String[] args)
{
Thread thread = new MyThread3(new Work());
thread.start();
}
}
多线程 看这篇就够了
引
如果对什么是线程、什么是进程仍存有疑惑,请先Google之,因为这两个概念不在本文的范围之内。
用多线程只有一个目的,那就是更好的利用cpu的资源,因为所有的多线程代码都可以用单线程来实现。说这个话其实只有一半对,因为反应“多角色”的程序代码,最起码每个角色要给他一个线程吧,否则连实际场景都无法模拟,当然也没法说能用单线程来实现:比如最常见的“生产者,消费者模型”。
很多人都对其中的一些概念不够明确,如同步、并发等等,让我们先建立一个数据字典,以免产生误会。
多线程:指的是这个程序(一个进程)运行时产生了不止一个线程
并行与并发:
并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
并发与并行
线程安全:经常用来描绘一段代码。指在并发的情况之下,该代码经过多线程使用,线程的调度顺序不影响任何结果。这个时候使用多线程,我们只需要关注系统的内存,cpu是不是够用即可。反过来,线程不安全就意味着线程的调度顺序会影响最终结果,如不加事务的转账代码:
void transferMoney(User from, User to, float amount){
to.setMoney(to.getBalance() + amount);
from.setMoney(from.getBalance() - amount);
}
同步:Java中的同步指的是通过人为的控制和调度,保证共享资源的多线程访问成为线程安全,来保证结果的准确。如上面的代码简单加入@synchronized关键字。在保证结果准确的同时,提高性能,才是优秀的程序。线程安全的优先级高于性能。
好了,让我们开始吧。我准备分成几部分来总结涉及到多线程的内容:
扎好马步:线程的状态
内功心法:每个对象都有的方法(机制)
太祖长拳:基本线程类
九阴真经:高级多线程控制类
扎好马步:线程的状态
先来两张图:
线程状态
线程状态转换
各种状态一目了然,值得一提的是"blocked"这个状态:
线程在Running的过程中可能会遇到阻塞(Blocked)情况
调用join()和sleep()方法,sleep()时间结束或被打断,join()中断,IO完成都会回到Runnable状态,等待JVM的调度。
调用wait(),使该线程处于等待池(wait blocked pool),直到notify()/notifyAll(),线程被唤醒被放到锁定池(lock blocked pool ),释放同步锁使线程回到可运行状态(Runnable)
对Running状态的线程加同步锁(Synchronized)使其进入(lock blocked pool ),同步锁被释放进入可运行状态(Runnable)。
此外,在runnable状态的线程是处于被调度的线程,此时的调度顺序是不一定的。Thread类中的yield方法可以让一个running状态的线程转入runnable。
内功心法:每个对象都有的方法(机制)
synchronized, wait, notify 是任何对象都具有的同步工具。让我们先来了解他们
monitor
他们是应用于同步问题的人工线程调度工具。讲其本质,首先就要明确monitor的概念,Java中的每个对象都有一个监视器,来监测并发代码的重入。在非多线程编码时该监视器不发挥作用,反之如果在synchronized 范围内,监视器发挥作用。
wait/notify必须存在于synchronized块中。并且,这三个关键字针对的是同一个监视器(某对象的监视器)。这意味着wait之后,其他线程可以进入同步块执行。
当某代码并不持有监视器的使用权时(如图中5的状态,即脱离同步块)去wait或notify,会抛出java.lang.IllegalMonitorStateException。也包括在synchronized块中去调用另一个对象的wait/notify,因为不同对象的监视器不同,同样会抛出此异常。
再讲用法:
synchronized单独使用:
代码块:如下,在多线程环境下,synchronized块中的方法获取了lock实例的monitor,如果实例相同,那么只有一个线程能执行该块内容
public class Thread1 implements Runnable {
Object lock;
public void run() {
synchronized(lock){
..do something
}
}
}
直接用于方法: 相当于上面代码中用lock来锁定的效果,实际获取的是Thread1类的monitor。更进一步,如果修饰的是static方法,则锁定该类所有实例。
public class Thread1 implements Runnable {
public synchronized void run() {
..do something
}
}
synchronized, wait, notify结合:典型场景生产者消费者问题
/**
* 生产者生产出来的产品交给店员
*/
public synchronized void produce()
{
if(this.product >= MAX_PRODUCT)
{
try
{
wait();
System.out.println("产品已满,请稍候再生产");
}
catch(InterruptedException e)
{
e.printStackTrace();
}
return;
}
this.product++;
System.out.println("生产者生产第" + this.product + "个产品.");
notifyAll(); //通知等待区的消费者可以取出产品了
}
/**
* 消费者从店员取产品
*/
public synchronized void consume()
{
if(this.product <= MIN_PRODUCT)
{
try
{
wait();
System.out.println("缺货,稍候再取");
}
catch (InterruptedException e)
{
e.printStackTrace();
}
return;
}
System.out.println("消费者取走了第" + this.product + "个产品.");
this.product--;
notifyAll(); //通知等待去的生产者可以生产产品了
}
volatile
多线程的内存模型:main memory(主存)、working memory(线程栈),在处理数据时,线程会把值从主存load到本地栈,完成操作后再save回去(volatile关键词的作用:每次针对该变量的操作都激发一次load and save)。
volatile
针对多线程使用的变量如果不是volatile或者final修饰的,很有可能产生不可预知的结果(另一个线程修改了这个值,但是之后在某线程看到的是修改之前的值)。其实道理上讲同一实例的同一属性本身只有一个副本。但是多线程是会缓存值的,本质上,volatile就是不去缓存,直接取值。在线程安全的情况下加volatile会牺牲性能。
太祖长拳:基本线程类
基本线程类指的是Thread类,Runnable接口,Callable接口
Thread 类实现了Runnable接口,启动一个线程的方法:
MyThread my = new MyThread();
my.start();
Thread类相关方法:
//当前线程可转让cpu控制权,让别的就绪状态线程运行(切换)
public static Thread.yield()
//暂停一段时间
public static Thread.sleep()
//在一个线程中调用other.join(),将等待other执行完后才继续本线程。
public join()
//后两个函数皆可以被打断
public interrupte()
关于中断:它并不像stop方法那样会中断一个正在运行的线程。线程会不时地检测中断标识位,以判断线程是否应该被中断(中断标识值是否为true)。终端只会影响到wait状态、sleep状态和join状态。被打断的线程会抛出InterruptedException。
Thread.interrupted()检查当前线程是否发生中断,返回boolean
synchronized在获锁的过程中是不能被中断的。
中断是一个状态!interrupt()方法只是将这个状态置为true而已。所以说正常运行的程序不去检测状态,就不会终止,而wait等阻塞方法会去检查并抛出异常。如果在正常运行的程序中添加while(!Thread.interrupted()) ,则同样可以在中断后离开代码体
Thread类最佳实践:
写的时候最好要设置线程名称 Thread.name,并设置线程组 ThreadGroup,目的是方便管理。在出现问题的时候,打印线程栈 (jstack -pid) 一眼就可以看出是哪个线程出的问题,这个线程是干什么的。
如何获取线程中的异常
不能用try,catch来获取线程中的异常
Runnable 与Thread类似
Callable
future模式:并发模式的一种,可以有两种形式,即无阻塞和阻塞,分别是isDone和get。其中Future对象用来存放该线程的返回值以及状态
ExecutorService e = Executors.newFixedThreadPool(3);
//submit方法有多重参数版本,及支持callable也能够支持runnable接口类型.
Future future = e.submit(new myCallable());
future.isDone() //return true,false 无阻塞
future.get() // return 返回值,阻塞直到该线程运行结束
九阴真经:高级多线程控制类
以上都属于内功心法,接下来是实际项目中常用到的工具了,Java1.5提供了一个非常高效实用的多线程包:java.util.concurrent, 提供了大量高级工具,可以帮助开发者编写高效、易维护、结构清晰的Java多线程程序。
1.ThreadLocal类
用处:保存线程的独立变量。对一个线程类(继承自Thread)
当使用ThreadLocal维护变量时,ThreadLocal为每个使用该变量的线程提供独立的变量副本,所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。常用于用户登录控制,如记录session信息。
实现:每个Thread都持有一个TreadLocalMap类型的变量(该类是一个轻量级的Map,功能与map一样,区别是桶里放的是entry而不是entry的链表。功能还是一个map。)以本身为key,以目标为value。
主要方法是get()和set(T a),set之后在map里维护一个threadLocal -> a,get时将a返回。ThreadLocal是一个特殊的容器。
2.原子类(AtomicInteger、AtomicBoolean……)
如果使用atomic wrapper class如atomicInteger,或者使用自己保证原子的操作,则等同于synchronized
//返回值为boolean
AtomicInteger.compareAndSet(int expect,int update)
该方法可用于实现乐观锁,考虑文中最初提到的如下场景:a给b付款10元,a扣了10元,b要加10元。此时c给b2元,但是b的加十元代码约为:
if(b.value.compareAndSet(old, value)){
return ;
}else{
//try again
// if that fails, rollback and log
}
AtomicReference
对于AtomicReference 来讲,也许对象会出现,属性丢失的情况,即oldObject == current,但是oldObject.getPropertyA != current.getPropertyA。
这时候,AtomicStampedReference就派上用场了。这也是一个很常用的思路,即加上版本号
3.Lock类
lock: 在java.util.concurrent包内。共有三个实现:
ReentrantLock
ReentrantReadWriteLock.ReadLock
ReentrantReadWriteLock.WriteLock
主要目的是和synchronized一样, 两者都是为了解决同步问题,处理资源争端而产生的技术。功能类似但有一些区别。
区别如下:
lock更灵活,可以自由定义多把锁的枷锁解锁顺序(synchronized要按照先加的后解顺序)
提供多种加锁方案,lock 阻塞式, trylock 无阻塞式, lockInterruptily 可打断式, 还有trylock的带超时时间版本。
本质上和监视器锁(即synchronized是一样的)
能力越大,责任越大,必须控制好加锁和解锁,否则会导致灾难。
和Condition类的结合。
性能更高,对比如下图:
synchronized和Lock性能对比
ReentrantLock
可重入的意义在于持有锁的线程可以继续持有,并且要释放对等的次数后才真正释放该锁。
使用方法是:
1.先new一个实例
static ReentrantLock r=new ReentrantLock();
2.加锁
r.lock()或r.lockInterruptibly();
此处也是个不同,后者可被打断。当a线程lock后,b线程阻塞,此时如果是lockInterruptibly,那么在调用b.interrupt()之后,b线程退出阻塞,并放弃对资源的争抢,进入catch块。(如果使用后者,必须throw interruptable exception 或catch)
3.释放锁
r.unlock()
必须做!何为必须做呢,要放在finally里面。以防止异常跳出了正常流程,导致灾难。这里补充一个小知识点,finally是可以信任的:经过测试,哪怕是发生了OutofMemoryError,finally块中的语句执行也能够得到保证。
ReentrantReadWriteLock
可重入读写锁(读写锁的一个实现)
ReentrantReadWriteLock lock = new ReentrantReadWriteLock()
ReadLock r = lock.readLock();
WriteLock w = lock.writeLock();
两者都有lock,unlock方法。写写,写读互斥;读读不互斥。可以实现并发读的高效线程安全代码
4.容器类
这里就讨论比较常用的两个:
BlockingQueue
ConcurrentHashMap
BlockingQueue
阻塞队列。该类是java.util.concurrent包下的重要类,通过对Queue的学习可以得知,这个queue是单向队列,可以在队列头添加元素和在队尾删除或取出元素。类似于一个管 道,特别适用于先进先出策略的一些应用场景。普通的queue接口主要实现有PriorityQueue(优先队列),有兴趣可以研究
BlockingQueue在队列的基础上添加了多线程协作的功能:
BlockingQueue
除了传统的queue功能(表格左边的两列)之外,还提供了阻塞接口put和take,带超时功能的阻塞接口offer和poll。put会在队列满的时候阻塞,直到有空间时被唤醒;take在队 列空的时候阻塞,直到有东西拿的时候才被唤醒。用于生产者-消费者模型尤其好用,堪称神器。
常见的阻塞队列有:
ArrayListBlockingQueue
LinkedListBlockingQueue
DelayQueue
SynchronousQueue
ConcurrentHashMap
高效的线程安全哈希map。请对比hashTable , concurrentHashMap, HashMap
5.管理类
管理类的概念比较泛,用于管理线程,本身不是多线程的,但提供了一些机制来利用上述的工具做一些封装。
了解到的值得一提的管理类:ThreadPoolExecutor和 JMX框架下的系统级管理类 ThreadMXBean
ThreadPoolExecutor
如果不了解这个类,应该了解前面提到的ExecutorService,开一个自己的线程池非常方便:
ExecutorService e = Executors.newCachedThreadPool();
ExecutorService e = Executors.newSingleThreadExecutor();
ExecutorService e = Executors.newFixedThreadPool(3);
// 第一种是可变大小线程池,按照任务数来分配线程,
// 第二种是单线程池,相当于FixedThreadPool(1)
// 第三种是固定大小线程池。
// 然后运行
e.execute(new MyRunnableImpl());
该类内部是通过ThreadPoolExecutor实现的,掌握该类有助于理解线程池的管理,本质上,他们都是ThreadPoolExecutor类的各种实现版本。请参见javadoc:
ThreadPoolExecutor参数解释
翻译一下:
corePoolSize:池内线程初始值与最小值,就算是空闲状态,也会保持该数量线程。
maximumPoolSize:线程最大值,线程的增长始终不会超过该值。
keepAliveTime:当池内线程数高于corePoolSize时,经过多少时间多余的空闲线程才会被回收。回收前处于wait状态
unit:
时间单位,可以使用TimeUnit的实例,如TimeUnit.MILLISECONDS
workQueue:待入任务(Runnable)的等待场所,该参数主要影响调度策略,如公平与否,是否产生饿死(starving)
threadFactory:线程工厂类,有默认实现,如果有自定义的需要则需要自己实现ThreadFactory接口并作为参数传入。















 685
685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









