







关于 MyBatis 二级缓存数据脏读问题
为方便理解,本章涉及示例代码已上传至 gitee
==>获取示例代码请点击这里。。。
拉取示例代码时,请拉取所有分支,master 分支只是做了示例的初始化
关于二级缓存的数据脏读,产生的原因是因为二级缓存的作用域是基于 Mapper 文件的。
即:现在假设一种情况:我们要同时查询出包含用户角色信息的用户信息,这是,我们会通过连接查询,对用户表和角色表进行连接查询,关联条件是:user.role_id = role.id;当用户数据查询出来以后,会将缓存信息绑定到 UserMapper 这个文件的二级缓存对象中,而当我们修改了用户角色表后,MyBatis 只会清空 RoleMapper 对应的二级缓存,UserMapper 对应的二级缓存并没有被清空,这时,再去查询用户角色信息,由于我们已经更改过数据库中的角色信息,但是 UserMapper 绑定的二级缓存并未清空,所以,这时的查询会直接去 UserMapper 对应的二级缓存中拿数据并返回,并不会查询数据库,所以,产生了数据脏读的问题。
下面我们来模拟一下这种情况:测试方法如下:
@Test
public void testReadUncommit() throws Exception{
// 查询 用户角色信息
SysUserMapper userMapper = sqlSession.getMapper(SysUserMapper.class);
List<Integer> list = new ArrayList<>();
list.add(1004);
list.add(1);
List<SysUser> userList = userMapper.userRoleByCollection(list);
Assert.assertNotNull(userList);
System.err.println("第一次查询的 RoleName : " + userList.get(0).getRoleList().get(0).getRoleName());
// 修改 sys_role 表中 超级管理员信息
SysRoleMapper roleMapper = sqlSession.getMapper(SysRoleMapper.class);
SysRole sysRole = new SysRole();
sysRole.setId(1);
sysRole.setRoleName("超级管理员" + Math.random());
Integer integer = roleMapper.updateRoleName(sysRole);
Assert.assertNotNull(integer);
sqlSession.commit();
System.err.println("修改后的 RoleName : " + sysRole.getRoleName());
// 再次查询 用户角色信息
SysUserMapper userMapper1 = sqlSession.getMapper(SysUserMapper.class);
List<SysUser> userList1 = userMapper1.userRoleByCollection(list);
Assert.assertNotNull(userList1);
sqlSession.close();
System.err.println("第二次查询的 RoleName : " + userList1.get(0).getRoleList().get(0).getRoleName());
}
其他配置都没有变,还是用的上一节中的二级缓存配置,即 RedisCache 。
然后我们运行,控制台打印如下:
// 第一次查询未命中缓存 即 0.0;查询数据库
DEBUG [main] - Cache Hit Ratio [com.mybatis.simple.mapper.SysUserMapper]: 0.0
DEBUG [main] - ==> Preparing: select user.id, user.user_name, user.user_email, role.id "role_id", role.role_name "role_role_name", role.enabled "role_enabled", role.create_by "role_createBy" from sys_user user inner join sys_user_role userRole on user.id = userRole.user_id inner join sys_role role on userRole.role_id = role.id where 1 = 1 and user.id in ( ? , ? )
DEBUG [main] - ==> Parameters: 1004(Integer), 1(Integer)
TRACE [main] - <== Columns: id, user_name, user_email, role_id, role_role_name, role_enabled, role_createBy
TRACE [main] - <== Row: 1, admin, admin@mybatis.com, 1, 超级管理员0.42340159076274864, 1, 1
TRACE [main] - <== Row: 1, admin, admin@mybatis.com, 2, 普通用户, 1, 1
TRACE [main] - <== Row: 1004, 孙悟空, SWK@xiyouji.com, 1, 超级管理员0.42340159076274864, 1, 1
TRACE [main] - <== Row: 1004, 孙悟空, SWK@xiyouji.com, 2, 普通用户, 1, 1
DEBUG [main] - <== Total: 4
// 第一次查询时查询出来的 RoleId = 1 的 roleName
第一次查询的 RoleName : 超级管理员0.42340159076274864
// 然后,我们修改 sys_role 中 roleId = 1 的 role_name,修改为 : role_name = "超级管理员0.11481772579472516"
DEBUG [main] - ==> Preparing: update sys_role set role_name = ? where id = ?
DEBUG [main] - ==> Parameters: 超级管理员0.11481772579472516(String), 1(Integer)
DEBUG [main] - <== Updates: 1
修改后的 RoleName : 超级管理员0.11481772579472516
// 运行第二次查询,命中缓存,没有查询数据库,查询出来的 roleName 为 "超级管理员0.42340159076274864",但是我们数据库中的 role_name = "超级管理员0.11481772579472516";产生脏读
DEBUG [main] - Cache Hit Ratio [com.mybatis.simple.mapper.SysUserMapper]: 0.5
第二次查询的 RoleName : 超级管理员0.42340159076274864
从上面的控制台可以看出,虽然修改了 sys_role 表中的超级管理员名,但是当再次查询时,是从缓存中拿到的信息,所以,查询出来数据与数据库中数据不符,产生脏读。
要解决上述情况,**需要将 SysRoleMapper 的二级缓存的命名空间指向 SysUserMapper,即SysRoleMapper 与 SysUserMapper 共用一个二级缓存命名空间,**配置如下:
SysRoleMapper.xml
<cache-ref namespace="com.mybatis.simple.mapper.SysUserMapper"/>
之后,在运行测试方法,打印效果如下:
DEBUG [main] - Cache Hit Ratio [com.mybatis.simple.mapper.SysUserMapper]: 0.0
...
第一次查询的 RoleName : 超级管理员0.23810251575365593
...
修改后的 RoleName : 超级管理员0.5339710884073833
...
DEBUG [main] - Cache Hit Ratio [com.mybatis.simple.mapper.SysUserMapper]: 0.0
第二次查询的 RoleName : 超级管理员0.5339710884073833
控制台打印这里只放了关键的部分,可以看出,第二次查询时,二级缓存未命中,回去重新查询数据库。
下面来看一下 cache-ref 是如何运行的,对 cache-ref 标签的解析,在 MyBatis 初始化配置信息及阶段完成,流程图如下:
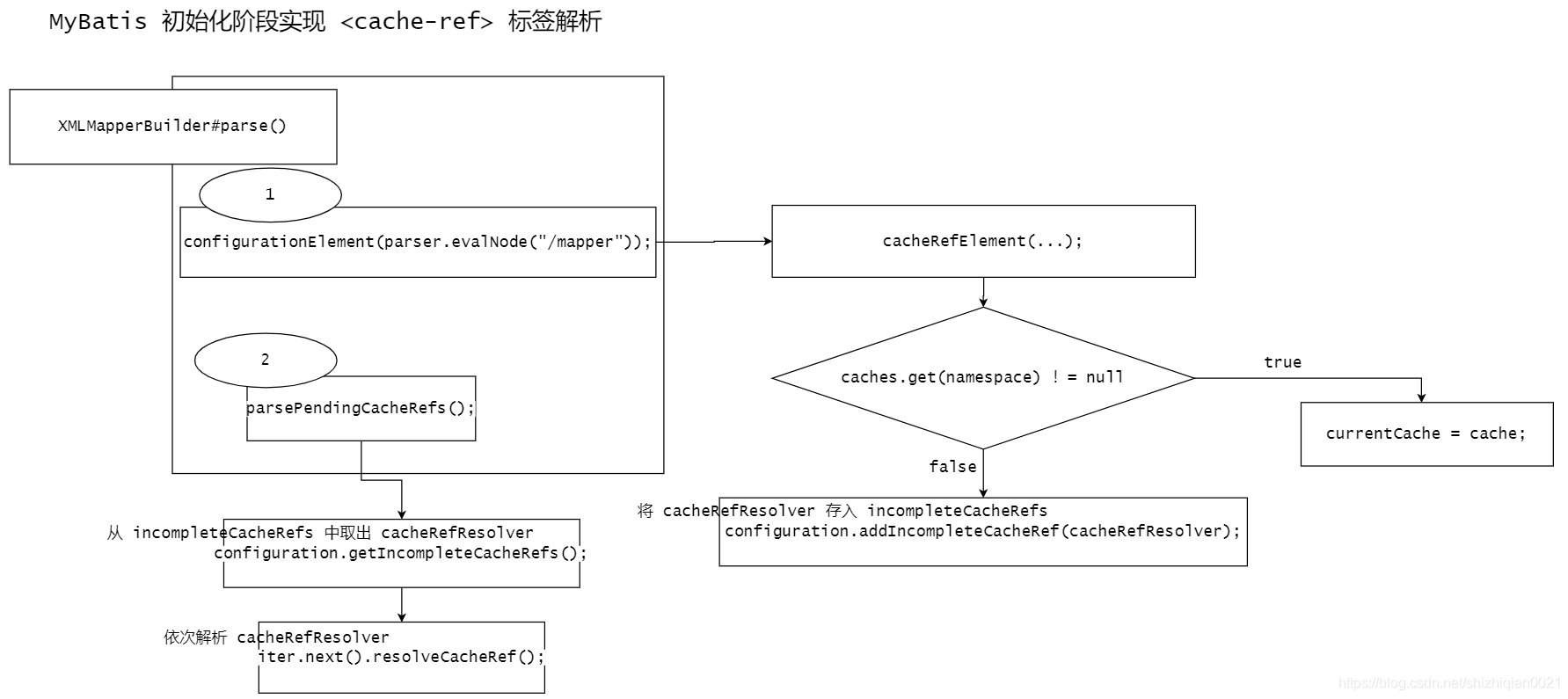
在上面的解析流程图中,关键的步骤可以分为以下几个,即:
// 负责解析 <cache-ref> 标签,根据命名空间,也就是我们在 <cache-ref> 中设置的 type 值,从 configuration 对象中获取对应的缓存对象,获取到,然后进行绑定;没有,则抛出一个 IncompleteElementException 的异常
cacheRefElement(context.evalNode("cache-ref"));
// 抛出的异常在 cacheRefElement(XNode context) 中被接收,如下:
private void cacheRefElement(XNode context) {
if (context != null) {
...
try {
cacheRefResolver.resolveCacheRef();
} catch (IncompleteElementException e)
// 在 configuration 中没有找到对应命名空间的缓存对象,则将该 cacheRefResolver 对象存入 incompleteCacheRefs 中。
configuration.addIncompleteCacheRef(cacheRefResolver);
}
}
}
// 每次解析完换一个 Mapper 文件后,会执行该方法,
parsePendingCacheRefs()private void parsePendingCacheRefs() {
// 获取 incompleteCacheRefs 集合
Collection<CacheRefResolver> incompleteCacheRefs = configuration.getIncompleteCacheRefs();
synchronized (incompleteCacheRefs) {
Iterator<CacheRefResolver> iter = incompleteCacheRefs.iterator();
while (iter.hasNext()) {
try {
// 再次调用 resolveCacheRef() 方法进行解析
iter.next().resolveCacheRef();
iter.remove();
} catch (IncompleteElementException e) {
// Cache ref is still missing a resource...
}
}
}
}
通过上面的流程图和部分步骤的关键方法,对于解析 cache-ref 标签的流程大概有了一个印象。
一般在使用时,会将数据库中有关联的表的 Mapper 文件共同使用一个二级缓存命名空间,这样,在关联的表更新数据后,便不会出现脏数据的情况。














 737
737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









