







文章目录
一、前言
本文创作于2017.2.15,当时使用的RocksDB版本为4.9。所测数据只能反映当时版本的性能,不适用于如今的新版本。
本文主要研究基于不同参数的调优,来展示对性能的影响,以供读者参考,提供优化的思路和方向。
二、RocksDB关键性能指标
本篇文章,主要利用了RocksDB的benchmark机制,进行各项测试。检测它的读写性能,以及各个参数调优后对性能的提升。
RocksDB中,可以调整的参数非常多,很多都是可以配置的,不同于LevelDB,需要修改代码,重新打包。
RocksDB的调优,主要就是为了优化下面的3种对性能有很大影响的场景:
1. 写放大
写放大即:写磁盘的速率 / 写数据的速率。
举个例子:如果写数据库速率为10Mb/s,磁盘写速率可以支持50Mb/s,则写放大为5。
也就是说,如果磁盘最大支持50Mb/s的写入,并且写放大为5,则意味着数据库所能支持的写入速率为10Mb/s。
在这种情况下,减小写放大倍数,可以显著增加数据库的写吞吐量。
2. 读放大
读放大即:做一次查询,需要进行读磁盘的次数。
如果做一次查询,需要读5次page,则读放大倍数为5。
其中,读数据分为逻辑读(logical read)和物理读(physical read)。逻辑读通常是对cache进行读取,RocksDB中,cache分为block cache 和table cache, 同时,os也有page cache。Block cache存储的是未压缩的block data,而page cache存储的是压缩过的block data。物理读就是直接读磁盘。
3. 空间放大
空间放大即:数据库文件大小 / 原始数据大小
例如:如果将10MB的数据存入数据库,而最终数据库占用了100MB的磁盘,则空间放大倍数为10。
三、测试机型
TS8机型:2个6核CPU,32GB内存,1.5T Intel SSD。
RocksDB: version 4.9
CPU: 24 * Intel® Xeon® CPU E5-2620 0 @ 2.00GHz
CPUCache: 15360 KB
Keys: 每个16 bytes
Values: 每个100 bytes(压缩后50 bytes)
四、性能分析
下面是在各个场景下,分别测试读性能和写性能。
1. 写性能 - 异步写入1千万个连续key
测试结果:
a) DB大小:1.2GB
b) 性能统计: 4.711 micros/op, 212251 ops/sec; 23.5 MB/s
2. 写性能 - 异步写入1千万个随机key
测试结果:
a) DB大小:920MB
b) 性能统计:8.724 micros/op, 114631 ops/sec; 12.7 MB/s
结论:
与场景1对比,随机写的性能下降很多。主要是大量随机的key写入,会增加compaction的量。
3. 写性能 - 开启sync,即每次写入都会刷盘
测试结果:
a) DB大小:920MB
b) 性能统计:112.391 micros/op, 8897 ops/sec; 1.0 MB/s (1000 ops)
结论:
开启sync会严重降低性能,需慎用。只有对可靠性要求苛刻场景使用。
4. 写性能 - 增大value
将value值从默认的100 bytes增大至100 KB,异步写入10万随机的key。
测试结果:
a) DB大小:109MB
b) 性能统计:359.595 micros/op, 2780 ops/sec; 265.3 MB/s
c) 磁盘IO:
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 27980.00 0.00 677.00 0.00 130.18 393.80 39.57 51.31 1.11 75.20
sda 0.00 27945.00 0.00 640.00 0.00 124.99 399.98 36.70 62.79 1.14 72.80
sda 0.00 28073.00 0.00 666.00 0.00 119.77 368.31 34.18 57.71 1.03 68.40
结论:
value的增大,对写入QPS影响非常大。同时,也会增加磁盘写速率。
5. 写性能 - 异步方式,覆盖写入1千万个随机key
测试结果:
a) DB大小:915MB
b) 性能统计:8.655 micros/op, 115535 ops/sec; 12.8 MB/s
结论:
与场景2对比,写入性能几乎一致。因为RocksDB写入操作,主要就是append log,以及插入memtable。
所以,不论是随机写入,还是覆盖写入,基本都是一样的。
6. 读性能 - 随机读1千万次
测试结果:
性能统计:0.211 micros/op, 4729894 ops/sec
结论:
随机读性能非常高。并且还是在只开启1个读线程的条件下。
7. 读性能 - 读写同时进行1千万次
测试结果:
a) DB大小:1.4GB
b) 性能统计:18.564 micros/op, 53867 ops/sec; 2.7 MB/s (4573087 of 10000000 found)
结论:
开启了写数据后,读数据的QPS下降非常多。因为读写线程间会竞争锁。
8. 读性能 - Merge时进行读数据,1千万次
测试结果:
a) DB大小:1.7GB
b) 性能统计:25.218 micros/op, 39654 ops/sec; 2.2 MB/s (5071354 of 10000000 found)
c) 磁盘IO:
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 11693.00 0.00 828.00 0.00 48.91 120.98 2.40 2.89 0.39 32.40
sda 0.00 11245.00 0.00 813.00 0.00 47.10 118.65 2.47 3.04 0.37 30.40
sda 0.00 21944.00 0.00 759.00 0.00 88.68 239.29 22.42 29.54 0.70 52.80
结论:
通过观察,测试进程初始时,会启动4个线程,即1个主线程,1个read, 1个write, 1个flush。
然后,数据量增大时,还会增加一个compact线程。
9. 读性能 - 读线程的个数对性能的影响
| 读线程数量 | 测试结果 |
|---|---|
| 1 | 25.218 micros/op,39654 ops/sec |
| 2 | 11.548 micros/op,86594 ops/sec |
| 10 | 2.507 micros/op,398887 ops/sec |
| 20 | 1.571 micros/op,636593 ops/sec |
| 30 | 1.368 micros/op,731073 ops/sec |
| 80 | 1.246 micros/op,802698 ops/sec |
结论:
适当增加线程数量,对性能提升巨大。但达到一定数量后,不再是线性增长。
五、总结各个参数对读性能的影响
这里先列出在前面(场景9)已经测试过的一种case(即1个线程write/merge, 10个线程read), 做为用于性能对比的基准case。
基准case的性能如下:
2.507 micros/op, 398887 ops/sec; 19.3 MB/s (4390866 of 10000000 found)
下面的这个列表,展现了各个参数调整后,对读性能的影响。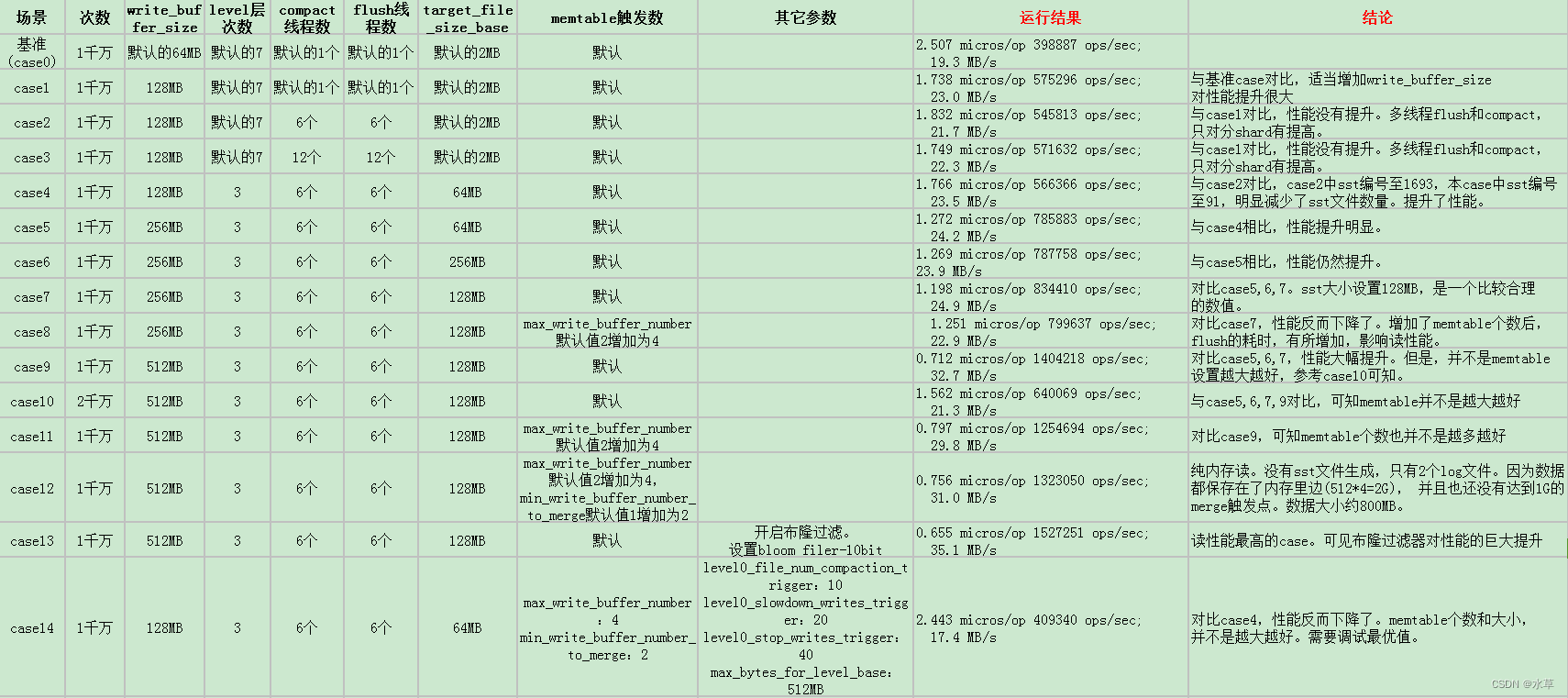















 532
532











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









