










论文名称:An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning——一种将知识从服务器端预训练生成器转移到异构联邦学习中的客户端的高效上传方案
关键字与领域分类解读:异构联邦学习,原型学习

摘要(是关于HtFL的典型论文,其中提到了知识转移方法,用生成模型的方法)
异构联邦学习(HtFL)使得在具有不同模型架构的多个客户端上进行协作学习,同时保护隐私。尽管近期研究取得了一定进展,HtFL中的知识共享仍然由于数据和模型的异构性而面临挑战。为了解决这个问题,我们利用存储在公共预训练生成器中的知识,提出了一种新的上传高效的知识转移方案,称为FedKTL。FedKTL可以通过生成器在服务器上的推断生成与客户端任务相关的原型图像-向量对。利用这些对,每个客户端可以通过额外的监督本地任务,将生成器中的已有知识转移到其本地模型中。我们在两个类型的数据异构性下,对四个数据集进行了广泛的实验,使用了包括CNN和ViT在内的14种模型。FedKTL在准确率上超过了七种最先进的方法,最高提升达7.31%。此外,这个方案适用于仅有一个边缘客户端的场景。
Introduction(只介绍每段重点)
FL可以解决分布式机器学习中数据隐私安全的问题,但每个客户端数据分布不一致导致FedAvg效率不行,因此出现了pFL。但是这还不够,如过客户端采用不同的学习模型,导致无法直接聚合。现有的大多数的HtFL方法采用的是数据蒸馏KD,但这样会造成智能传输部分的知识,知识转移不够充分等问题。对于“全局辅助模型”,会引入大量的通讯开销的问题
为解决上述问题,提出了联邦知识转移LOOP(FedKTL),这个过程利用了原型的简明性和来自服务器端公共预训练生成器的先前知识。其中可以做到3点:①在服务器上使用生成器来针对某些客户端任务定制化生成全局原型图像-向量对,②使用这些图像向量对通过额外的监督本地任务将预先存在的公共知识从生成器转移到每个客户端模型 开发中所解决的问题包括:q1如何在保持上传效率的同时上传无偏原型?q2核心问题:对于既定生成模型,不进行微调即可适应客户端任务?q3如何迁移生成器上的知识到客户端,不论是何种语义的图像
对于上述问题Q1,参考了FedETF(equiangular tight frame)[1]方法,使用ETF分类器让生成器生成无偏原型。对于Q2,通过域对齐和轻量级特征转换器来解决这一问题,主要方法是在服务器上搞了一种轻量级的可训练特征转换器。举例Fig1:有效的向量生成的图像,随机向量生成的图像(因为没有意义所以图像也是杂乱的),原型向量生成的图像(没有什么意义),对齐后的原型生成的向量。对于Q3,首先聚合每个类的对齐向量以获得潜在质心并生成相应的图像以形成图像向量对。然后我们进行额外的监督本地任务,仅使用这些对来增强客户端模型的特征提取能力,从而减少生成的图像与本地数据之间的语义相关性要求。
Related Works
HtFL
Group Heterogeneity 将多个同质模型分配给客户端,考虑到它们多样的通信和计算能力,它们通常通过从服务器模型中采样子模型来形成组。
Partial-heterogeneity-based 基于部分异质的方法 LGFedAvg [36], FedGen [78], and FedGH [64]方法中允许客户端模型的主要部分呈现异质性,但假设剩余的小部分是同质的。但主要部分仍然存在数据不足的问题。
Full-heterogeneity-based 全异质方法 并不对客户端模型的架构施加限制。经典的基于蒸馏的HtFL方法在全局数据集上共享模型输出,但实际中很少存在这样的数据集。一种方法是共享类别原型,例如FedDistill [18]、FedProto [53]和FedPCL [54]。然而,在处理异构数据时,分类器偏差的现象在FL中被广泛观察到。
ETF Classifier
基本问题:平衡数据集下训练达到快完成时(尤其是LOSS快为0时)会造成神经坍塌对的问题。这种现象在原型学习中会造成原型和分类器向量收敛形成一个单一的ETF,其中向量是规范化的,且它们之间的成对型角度被最大化且相同或者平衡。
ETF的相关工作:单纯形ETF代表了一种理想的分类器,一些集中式方法(相对于分布式训练)提议生成一个随机的单纯形ETF矩阵来替代原始分类器,并在不平衡场景中使用固定的ETF分类器指导特征提取器的训练。
FL中的ETF应用:另外为解决 FL 中的数据异质性,FedETF建议用固定的 ETF 分类器替换每个客户端的原始分类器。然而,FedETF 假设存在同质模型,并遵循 FedAvg 传递全局知识。
Method
问题初步
这里其实是整个技术的pipeline的描述,就是这张图。有一个假设是正态分布的向量,输入mapping网络Gm后,得到对应的valid vec,通过synthesis网络Gs,由Gm和Gs之间的潜在向量形成的空间称为“W空间”。
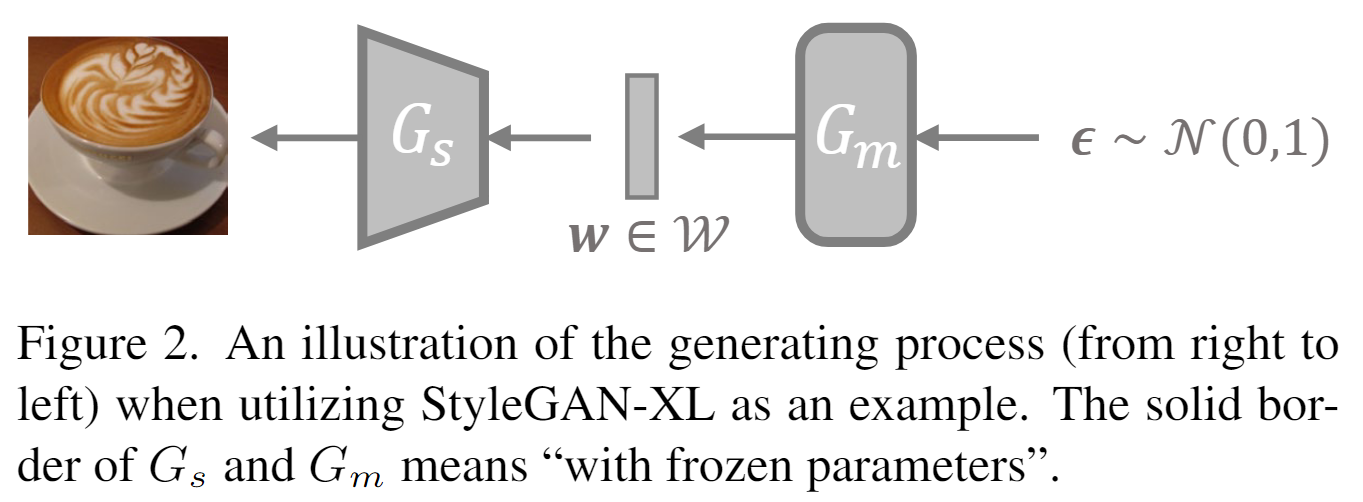
问题描述
这里跟普通联邦学习差不多,目标就是优化每个客户端所持有的Wi使得在其数据集上表现的loss和最小,也要注意这个有数据量的加权。
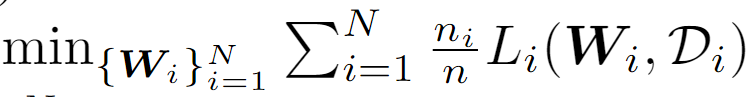
FedKTL算法
主要有6个step来实现:①在本地训练之后,每个客户端生成类别原型。②每个客户将原型上传到服务器。③服务器训练一个特征Transformer(用F表示,参数为WF),以将客户端原型变换并对齐到潜在向量。④在训练好的 F 的基础上,服务器首先获取类别的潜在中心 ̄Q,即每个类别内的平均潜在向量,然后通过将 ̄Q 输入到 Gs 中生成图像 DI。⑤每个客户端从服务器下载原型图像-向量对 {DI , ̄Q}。⑥每个客户端使用Di、DI和̄Q在本地训练gi和h′i,其中h′i是一个额外的线性的投影层(由Wh′i参数化),用于改变特征表示的维度。注意到|̄Q| = |DI| = C ≪ |Di|。
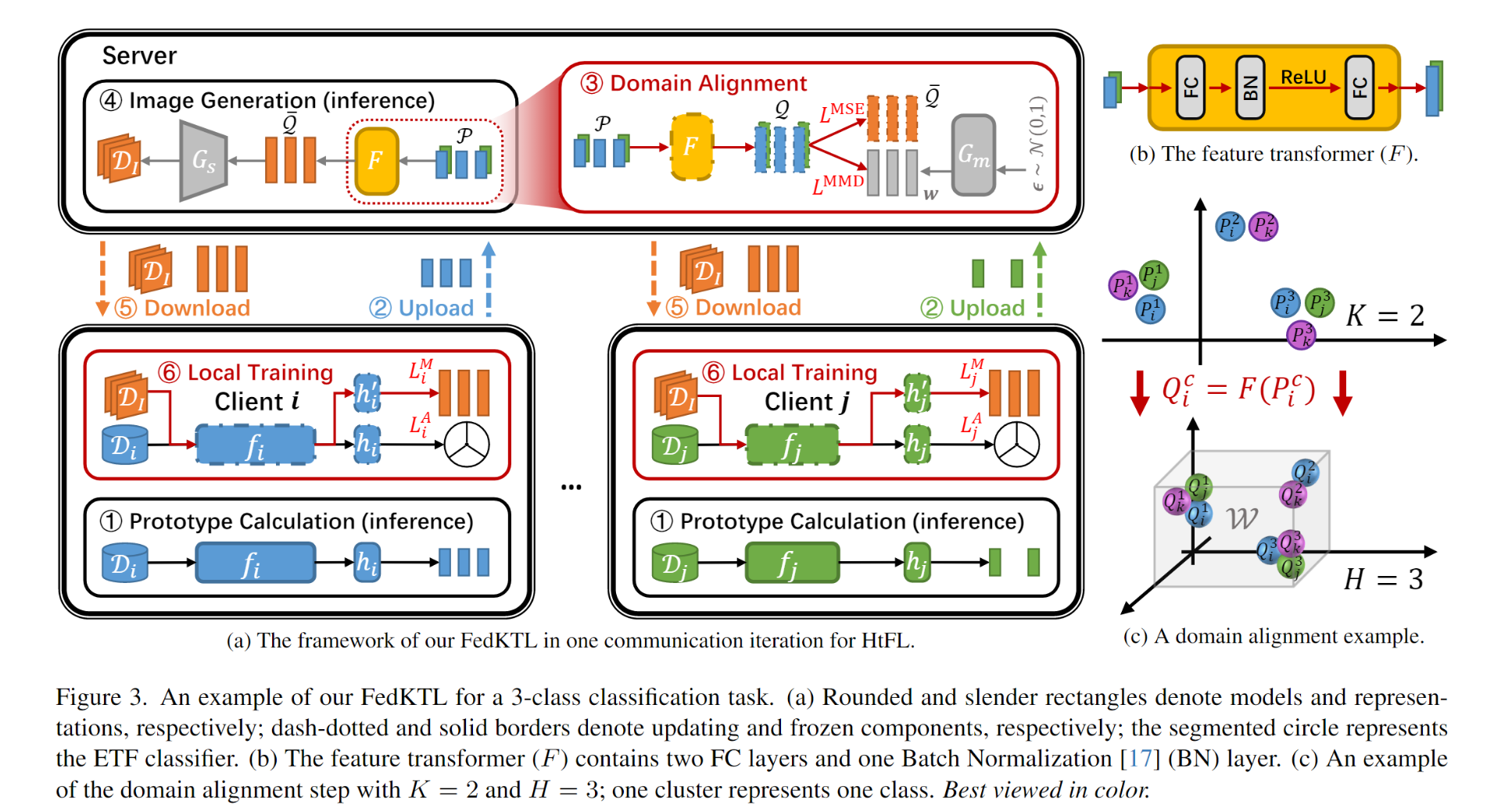
ETF分类器和原型生成器(对应Gm):其实主要就是根据任务形式设计Loss,作者设计的L这个地方是对应着在数据集
上的loss。在这个地方就是用ETF的思想,使用相同的ETF分类器去替换不同架构模型的原始分类器(我的理解是一般都是最后的fc层),并且在特征提取器上加一个全连接层作为线性投影层。这样就可以让每个本地模型生成与全局相同的ETF无偏的向量对齐的原型啦。
重磅难理解:先合成一个简单的ETF向量组V,然后这个向量组的构造公式:
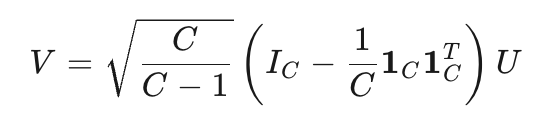
这就让向量矩阵中的每个向量V的长度都是1个单位长度,且向量中的夹角都满足如下: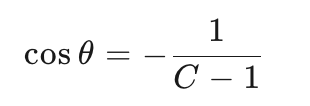
U 通常是通过随机初始化生成的,并且在训练过程中保持固定。这样可以确保 ETF 分类器的结构在所有客户端上是一致的,从而使得客户端能够生成无偏的类别原型。
之后采用了ArcFace loss来搞这个事情。大致理解就是让每个随机生成的向量夹角尽可能增大,然后让原型可以跟向量夹角匹配上!
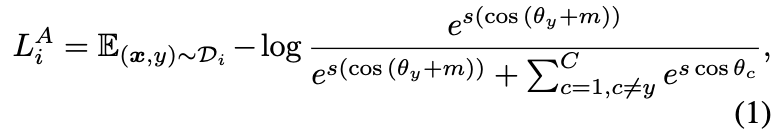
领域对齐与图像生成(对应fig1中的w):按常理知识我们知道上面出来的向量跟Gs对不上,这里就提出搞一个F让他们两的向量对齐,否则就是鸡同鸭讲了。
-
保持类别区分(Class-wise Discrimination):通过均方误差(MSE)损失 LMSE 保持转换后的向量 Q 的类别区分性。
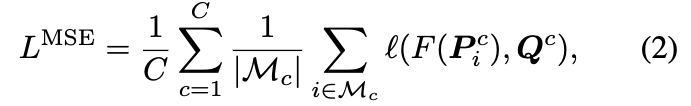
-
域对齐(Domain Alignment):通过最大均值差异(Maximum Mean Discrepancy, MMD)损失 LMMD 将 Q 对齐到生成器的有效输入域 W
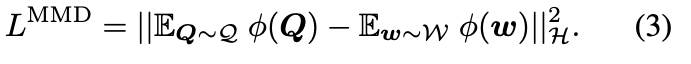
好吧最后就是服务器loss = Lmmd+λLmse了
转移预先存在的全局知识:这里需要计算通用生成器的生成图和本地特征提取器与判别器之间的预测损失了,然后把这个损失与相加,就是本地的损失啦。一句话:这里是将Gs的常识知识从Gs转移到fi
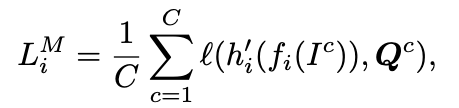
隐私性讨论
保护隐私的三方面:① 我们为所有客户引入了一个相同的ETF分类器,以生成无偏的原型,这些原型包含很少的私人信息 ②生成的图像属于生成器固有的输出领域,与客户的本地数据有很大不同 ③模型参数不共享
实验
这里还是得说一下,在实验中用了不同异质性场景,其实就是在同一个数据集上,多个客户端采用不同的模型(比如有cnn, resnet和vit),具体如下
| 代号 | 包含模型 |
| HtFE2 | 4-layer CNN and ResNet18 |
| HtFE3 | ResNet10, ResNet18, and ResNet34 |
| HtFE4 | 4-layer CNN, GoogleNet, MobileNet v2, and ResNet18 |
| HtFE9 | ResNet4, 6, 8, 10, 18, 34, 50, 101, 152 |
| HtFE8 HtM10 | HtFL4 + ResNet34, ResNet50, ResNet101, and ResNet152 HtFL8 + ViT-B/16 and ViT-B/32 |
其他的数据优越性就不用说了,分析来说就是客户端的模型的异质性越高这个东西就越有用,然后还有就是在HtFE8设置下,client越多(说明数据越分散),这个效果越牛逼。
自己的发现
这个只能用于图片的FL上,另外,如果是非常见(常识知识图像)那这里就可能失效!后面我会对这个地方进行思考改进。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









