









今天我们就来看看当输入./hadoop fs -get src des 时,代码中是如何执行的。
看过hadoop权威指南那本书,大家都知道当读取hdfs中的一个文件时,首先要向namenode咨询相关的数据块的信息,然后再和具体的datanode交互,将数据通过网络传过来,那么我们就从代码中看看这个过程的轨迹。
从/bin/hadoop脚本中可以很容易看到调用的是FsShell的main方法:
FsShell.main()--->ToolRunner.run()--->FsShell.run()--->copyToLocal(argv, i);

很容易可以看到读文件的时候DFSClient是通过DFSInputstream来做具体的工作的,那么我们就先来看下DFSInputstream的类图:
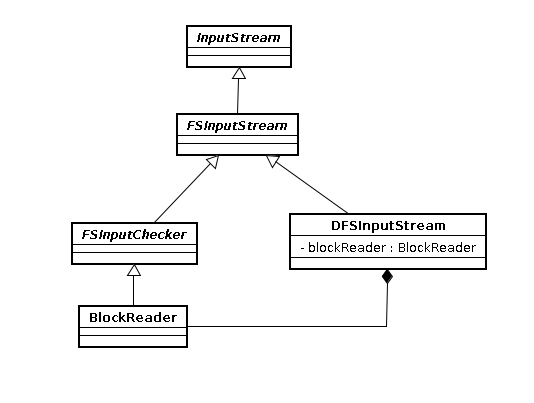
从第一副图(序列图)中可以看到读操作分为两个阶段,一个是调用DFSInputstream的openInfo方法和namenode联系;另一个阶段是通过read方法调用blockSeekTo方法来和datanode联系,从而实现读数据操作。
在这里简要地看下DFSInputstream的read方法。read方法每次都用一个buffer(默认大小为4k)来从输入流中读数据(把buffer读满),其中currentNode = blockSeekTo(pos);用来确定当前要读哪个datanode,然后真正的读取工作由readBuffer方法来完成,最后设置pos的位置,以便下一个buffer继续读取数据。















 2385
2385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









