







在Spark生态当中,MLlib往往是被定义为一个机器学习的库,通过用MLlib封装好的算法,可以非常轻松便捷地构建机器学习应用。在大数据处理当中,有了MLlib的出现,可以说是非常有利的一个工具。今天的大数据学习分享,我们就来对Spark MLlib做一个简单的入门介绍。

Spark MLLib简介
MLlib作为Spark的机器学习库,提供了非常丰富的机器学习算法,比如分类、回归、聚类及推荐算法等。目前,MLlib分为两个代码包:spark.mllib与spark.ml。
spark.mllib
Spark MLlib是Spark的重要组成部分,是最初提供的一个机器学习库。这个库有一个明显的缺点,就是面对复杂的数据集,需要做多次处理,或者当需要对新数据结合多个已经训练好的单个模型进行综合计算时,使用Spark MLlib会使程序结构变得复杂,甚至难以实现。
spark.mllib是基于RDD的原始算法API,目前处于维护状态。该库下包含4类常见的机器学习算法:分类、回归、聚类、协同过滤。值得注意的是,基于RDD的API不会再添加新的功能。
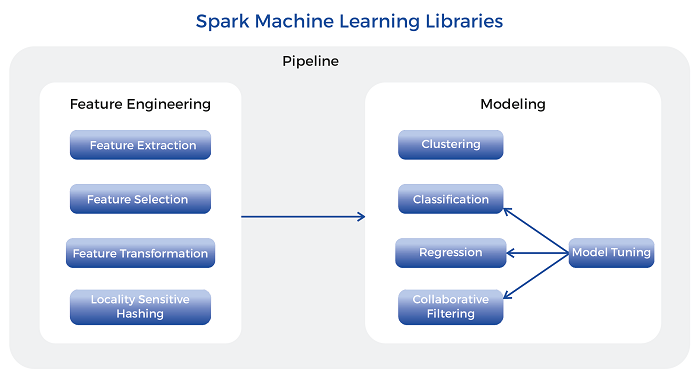
spark.ml
Spark1.2版本引入了ML Pipeline,经过多个版本的发展,Spark ML克服了MLlib处理机器学习问题的一些不足(复杂、流程不清晰),向用户提供了基于DataFrame API的机器学习库,提升数据处理效率。
与RDD相比,DataFrame提供了更加友好的API。DataFrame的优势,包括Spark数据源,SQL / DataFrame查询,Tungsten和Catalyst优化以及跨语言的统一API。
Spark ML API提供了很多数据特征处理函数,如特征选取、特征转换、类别数值化、正则化、降维等。另外基于DataFrame API的ml库支持构建机器学习的Pipeline,把机器学习过程一些任务有序地组织在一起,便于运行和迁移。
比如说,在数据变换上,Spark ML中提供了非常丰富的数据转换算法,对数据进行规范化、离散化、衍生指标等;在数据规约上,Spark ML提供的特征选择和降维的方法。
关于大数据学习,Spark MLlib入门,以上就为大家做了简单的介绍了。大数据学习是一个循序渐进的过程,Spark生态圈也是重要的学习内容,一个组件一个组件地深入,慢慢来。















 6258
6258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









