






 本文档介绍了如何在ARM架构的设备上安装和配置netdata监控工具,包括通过下载最新版本的netdata.run文件进行安装,通过systemctl管理netdata服务,以及在浏览器中查看监控状态。此外,详细说明了如何调整图表保留时间和配置apps.plugin以监控系统资源使用,以及如何定制化监控MySQL实例。netdata允许用户根据需求调整内存使用和数据保留时间,以达到最佳监控效果。
本文档介绍了如何在ARM架构的设备上安装和配置netdata监控工具,包括通过下载最新版本的netdata.run文件进行安装,通过systemctl管理netdata服务,以及在浏览器中查看监控状态。此外,详细说明了如何调整图表保留时间和配置apps.plugin以监控系统资源使用,以及如何定制化监控MySQL实例。netdata允许用户根据需求调整内存使用和数据保留时间,以达到最佳监控效果。
ARM机器使用netdata监控
安装
下载地址
https://github.com/netdata/netdata/releases
找到对应平台的版本下载
此处使用了netdata-aarch64-latest.gz.run
下载下来直接sh netdata-aarch64-latest.gz.run 进行安装。
安装完成之后,可以通过在浏览器中访问http://your_server_ip:19999 查看Netdata的监控。如果不可以查看,请查看防火墙设置。
查看状态,停止,重启
systemctl status netdata
systemctl stop netdata
systemctl start netdata
systemctl restart netdata
使用
please note : 请注意,如果您修改了部分中的参数,您的数据历史记录将会丢失
文档:https://learn.netdata.cloud/docs/agent/daemon/config
- 配置图表保留时间
Netdata 使用内部时间序列数据库 (TSDB) 在特定数量的磁盘空间内存储尽可能多的指标。默存储空间为 256 MiB,对于 1-3 天的历史指标来说应该足够了。如果您导航回超出已存储历史指标的时间范围,将会看到无法查看。
配置文件位置: `/opt/netdata/etc/netdata/netdata.conf`
将在此处看到所有(或大多数)可配置选项都已注释掉(即以#开头)。这是因为Netdata的配置使用一组假定的默认值。任何禁用的设置都使用Netdata的默认值;
如果取消注释某个设置,则指定的值将覆盖默认值。这使配置文件包含您修改的内容。
可以在浏览器中访问<http://your_server_ip:19999/netdata.conf查看Netdata>的当前配置。
在这里,您需要确定要为Netdata提供多少RAM,或者在丢失之前将记录的图表数据保留多长时间:
# 2 hours at 1,000 metrics per second
4 bytes * 7200 seconds * 1,000 metrics = 28800000 bytes = 28.8 MB RAM
# 2 hours at 2,000 metrics per second
4 bytes * 7200 seconds * 2,000 metrics = 57600000 bytes = 57.6 MB RAM
# 4 hours at 2,000 metrics per second
4 bytes * 14440 seconds * 2,000 metrics = 115520000 bytes = 115.52 MB RAM
# 24 hours at 1,000 metrics per second
4 bytes * 86400 seconds * 1,000 metrics = 345600000 bytes = 345.6 MB RAM
-
apps.plugin
将系统资源的使用分解为进程、用户和用户组。遍历整个进程树,收集每个发现运行的进程的资源使用信息。apps.plugin使用预定义的进程组列表, 将所有正在运行的进程分配给该列表。此列表可通过 自定义apps_groups.conf。 plugin构建一个进程树(很像Linux中的ps fax),并将进程分组在一起(同时评估子进程和父进程),因此结果总是一个包含预定义成员集的列表(of course, only process groups found running are reported)
与传统的进程监控工具(如top)不同,它能够计算退出进程的资源利用率。它们的利用率与它们目前运行的父母有关。因此,它完全能够测量shell脚本和其他进程每秒数百次派生/生成其他短生命期进程所使用的资源。
与传统的进程监控工具(如top)不同,它能够计算退出进程的资源利用率。它们的利用率与它们目前运行的父子进程有关。因此,它完全能够测量shell脚本和其他进程每秒数百次派生/生成其他短生命期进程所使用的资源。
文件位置:/opt/netdata/usr/lib/netdata/conf.d/apps_groups.conf
编辑命令位置:/opt/netdata/etc/netdata/edit-config
编辑命令(我的安装arm的目录和网上的示例不同,请注意以实际的目录修改):
/opt/netdata/etc/netdata/edit-config apps_groups.conf
#------------------------------------------------------------------------------
# myowngroup
mygroup: *eversql*
other: *
重启,将在 Applications这个下面看到计算的值。且对这个信息有介绍。
Per application statistics are collected using apps.plugin. This plugin walks through all processes and aggregates statistics for application groups. The plugin also counts the resources of exited children. So for processes like shell scripts, the reported values include the resources used by the commands these scripts run within each timeframe
可以得到如下图的分组指标

- 监控mysql
./edit-config go.d/mysql.conf
这个文件中给出了一些例子,如果实际不匹配,可以全部注释掉,只保留自己的jobs。
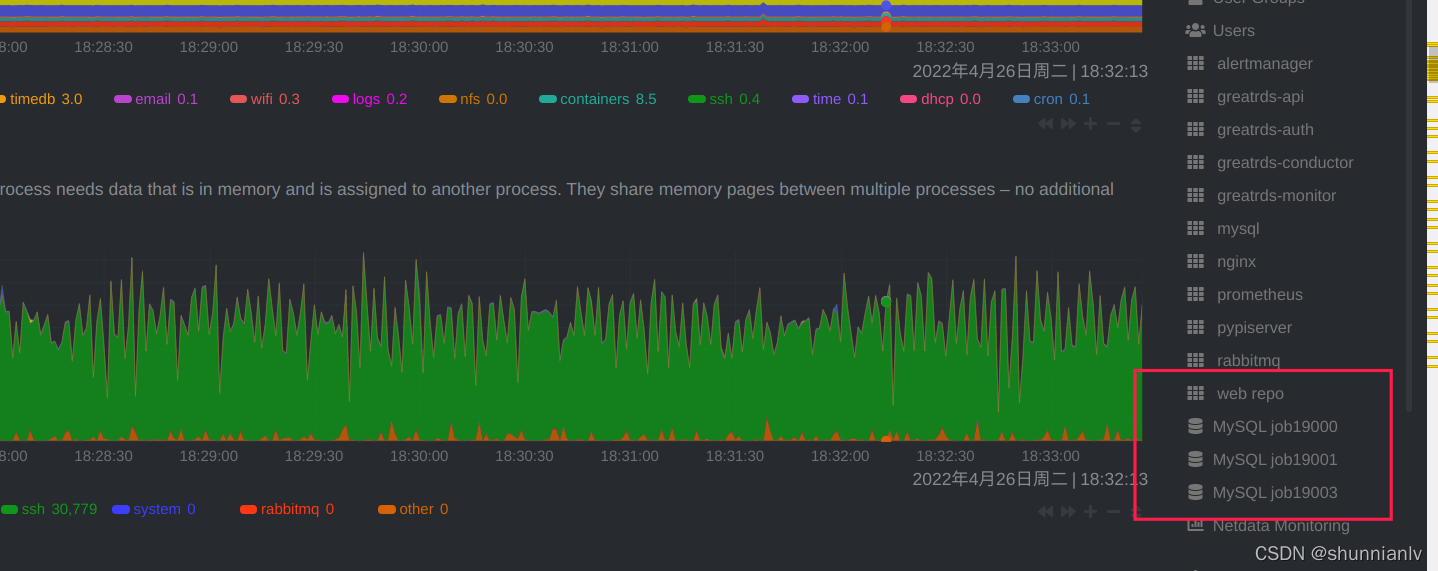
比如我们要监控19000,19001,19003这3个实例。
jobs:
- name: job19000
dsn: test1:123456@tcp(hostip:19000)/
- name: job19001
dsn: test1:123456@tcp(hostip:19001)/
- name: job19003
dsn: test2:123456@tcp(hostip:19003)/
然后可以这样调试编写好的文件,如果有问题会有提示。
调试编写的文件
./go.d.plugin -d -m mysql
调试通过,重启监控页面,将能看到对于这3个实例的单独监控条目。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









