










曾经,一份罕见病数据分析报告需要经历漫长的等待:人工对接全市40余家医疗机构-手动整理上百份异构数据报表-耗时长达3周。如今,同样的报告生成仅需60分钟!
当行业还在探讨DeepSeek技术落地场景时,某市卫健系统已经实现了从技术探索到规模应用的跨越式发展。这场效率革命的背后,是新质工具赋能“治数-用数”模式的全面重构。让我们一同解码这场为医疗健康系统赋能的技术革命!

医疗数据"掘金"之痛
如何让9000万条数据"活起来"?
某卫健委应急指挥中心的大屏上,罕见病数据正在“人工拼图”——一份报告需要从全市40+医院通过报表系统、BI分析应用、Excel表格等层层上报,然后经历“跨系统汇总、人工核验、分析建模”等冗长流程。这份本应实时更新的生命地图,却因数据孤岛、分析效率低下,被迫陷入长达数周的“人工考古期”。
全民健康平台每年上传省平台的数据超9000万条,关键时刻却像在沙漠里找水——卫健委的无奈,揭开了医疗数字化转型的残酷真相。虽已接入全市二级以上医院及1200余家基层机构,却因各医疗机构信息化水平参差不齐、数据标准不统一、系统集成度低等问题,面临"数据富矿难开采"的窘境。
这一困境绝非个案,而是折射出全国医疗数字化转型面临的共性挑战。若不能突破数据质量瓶颈,所谓的"疫情实时预警"、"资源智能调度"、"疾病精准追踪"等智慧场景,终将沦为纸上谈兵——数据富矿变不成临床决策的"指南针",更化不成公共卫生治理的"及时雨"。

四大创新
破解医疗“数据富矿”的栓塞
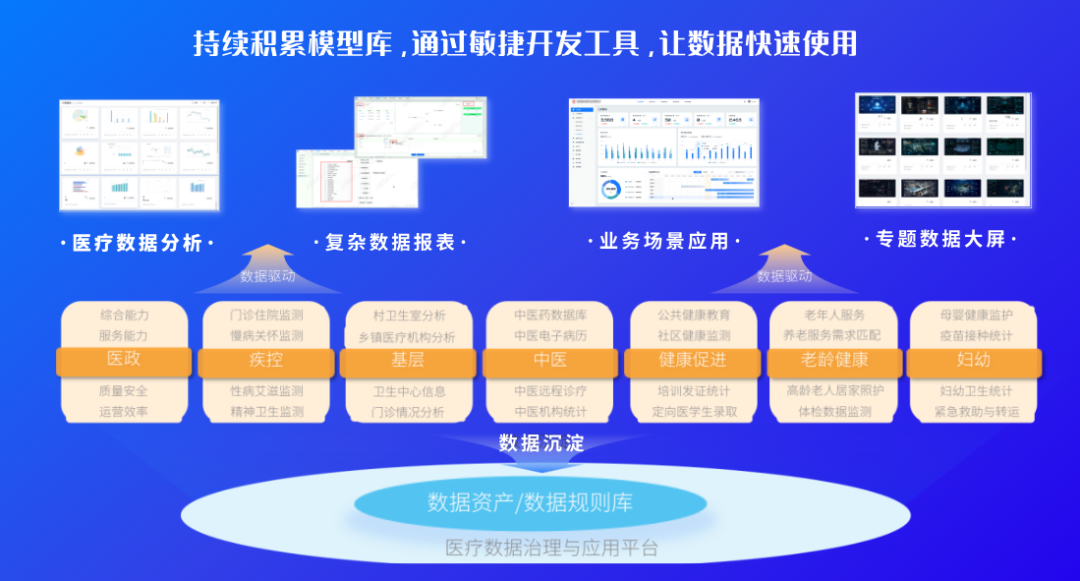
为激活数据潜能,卫健委以"数据新基建"理念重塑全民健康平台治理体系,通过构建智能化的数据中台,打通跨系统数据壁垒。同时,依托医疗领域专家知识库沉淀行业经验,融合业内最先进的AI大模型与无代码技术,全面升级“取数-治数-用数”路径。通过全流程智能匹配/推荐,降低数据使用门槛,释放数据应用潜能。
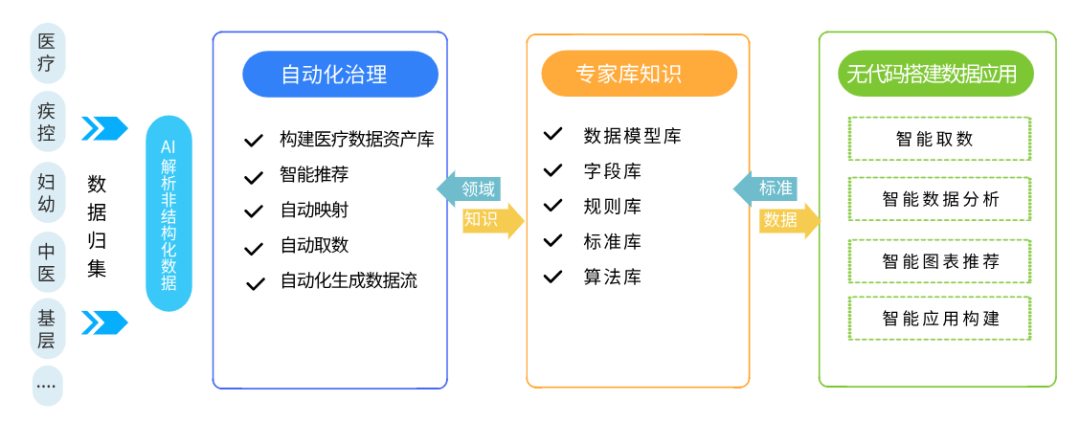
这四大创新,构建起医疗数据从“沉睡”到“觉醒”的智能通路,实现从"人工采矿"到"智能炼金"的范式跃迁。
专家库+AI双驱
智能识别目标数据
数据分析的前提是高质量业务数据的快速获取。然而,全市医疗机构有40多家,数据分散在不同系统,使得卫健委想要获取目标数据同大海捞针。
首先,每家医院根据省标或相关医疗数据的需求独立建设自己的信息系统,涉及30多家供应商、80多个接口,难以跨系统从大量的数据表中快速抽取目标业务数据。每当有新增数据需求时,需向各家医院提要求,通过下发报表等形式,医院IT部门手工提交,数据往往采集不全,数据获取流程长、准确率也无法保障。
其次,获取来的数据存在标准不统一、口径不一致、结构关系复杂等情况,使得业务人员对数据理解困难,难以进一步分析使用。一个空腹血糖值,在数据库里看起来如同加密的摩斯密码,A医院是"GLU-FBS(mg/dL)",B医院简写为"FBG"——若不是业务专家和技术人员逐条"破译",数据提取工作寸步难行。
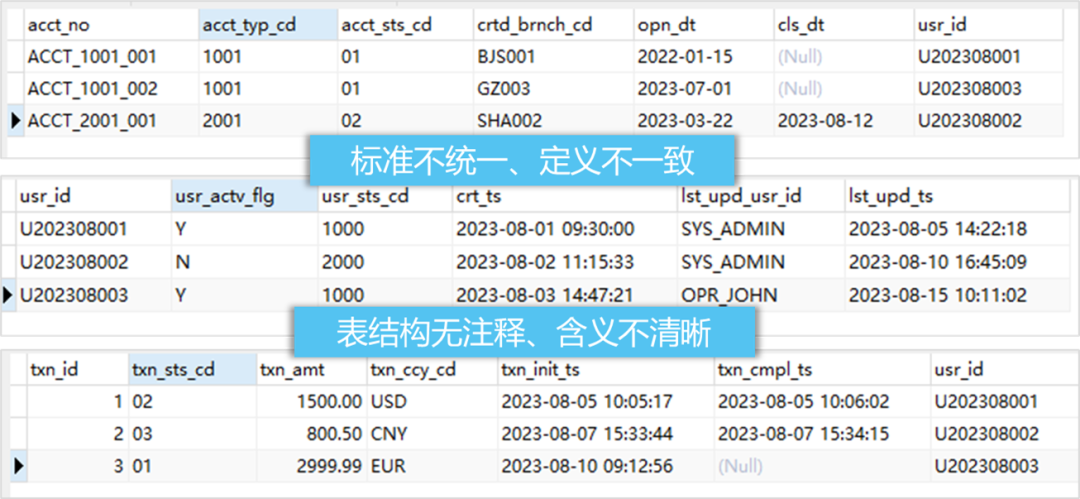
2024年8月,卫健委开始构建专家知识库,覆盖诊疗、药品、病种等60+项医疗领域数据模型,每个模型统一定义所有数据字段和标准。在对辖区范围多家医院系统数据抽取时,AI大模型基于专家库的知识沉淀进行推理,实现将不同系统数据按照统一准则(包括字段识别规则、元数据识别规则、质量规则、安全规则等),进行自动化映射和智能匹配推荐,从而抽取出目标数据。
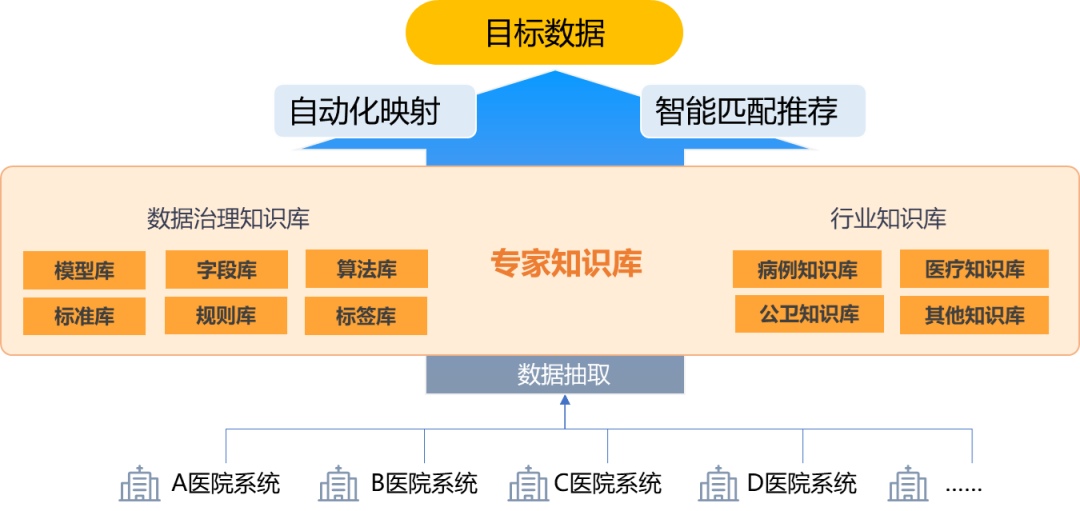
这一举措,将跨院数据获取从被动转为主动,将原本耗时三个月的人工比对工作,压缩至短短一周。这一智能化流程屏蔽了数据结构的细节,让参与项目的几位初级数据治理人员发挥出了远超经验水平的价值贡献——这不仅是效率的提升,更是给了卫健委与疾病赛跑的新武器。
主动数据治理
门槛直降 效率飙升
数据治理是一项长期性实施工作,在医疗卫生领域更是对数据有更高的质量要求,涉及患者安全、医疗决策、传染病预防等直接关乎生命健康和公共资金安全的敏感领域,数据质量指标要求异常严苛,因此对医疗数据的治理难度更大。
然而各家医院数据治理分散开展,实施依赖专业人员进行人工规则定义与脚本开发,数据质量高度依赖人员经验,数据治理门槛高、效率低。同时,数据上报卫健委后还需要再次进行巨量的人工质量稽核。
尤其是国家卫健委发布新版ICD-11疾病编码标准、平台已启用新编码体系时,全市40余家医院不得不展开新一轮数据治理,即将历史数据逐项对照新标准重新映射,又需人工核验新增字段的逻辑关系。
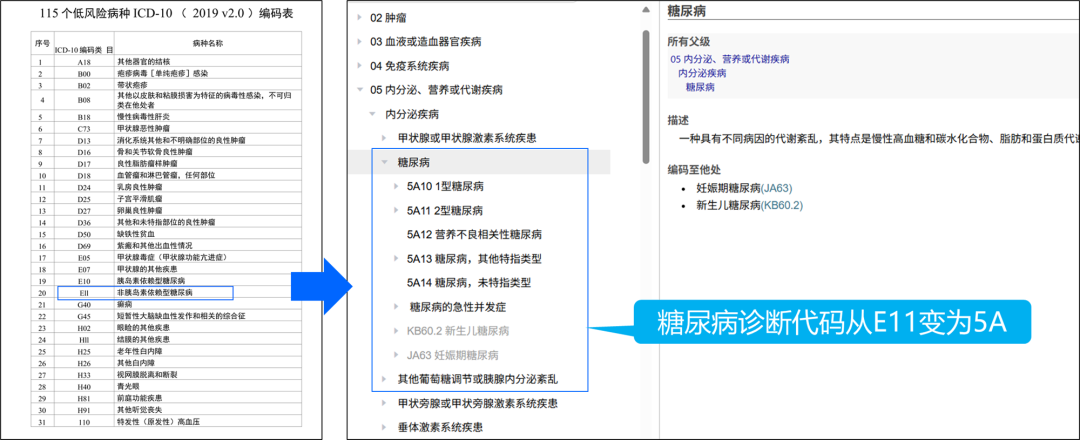
要提高数据治理效能,核心是降低治理门槛,减少人工规则配置。卫健委此次基于专家知识库和AI技术,将数据治理目标与具体业务场景(如门急诊、住院、检验单等)绑定,提高了自动化治理能力。
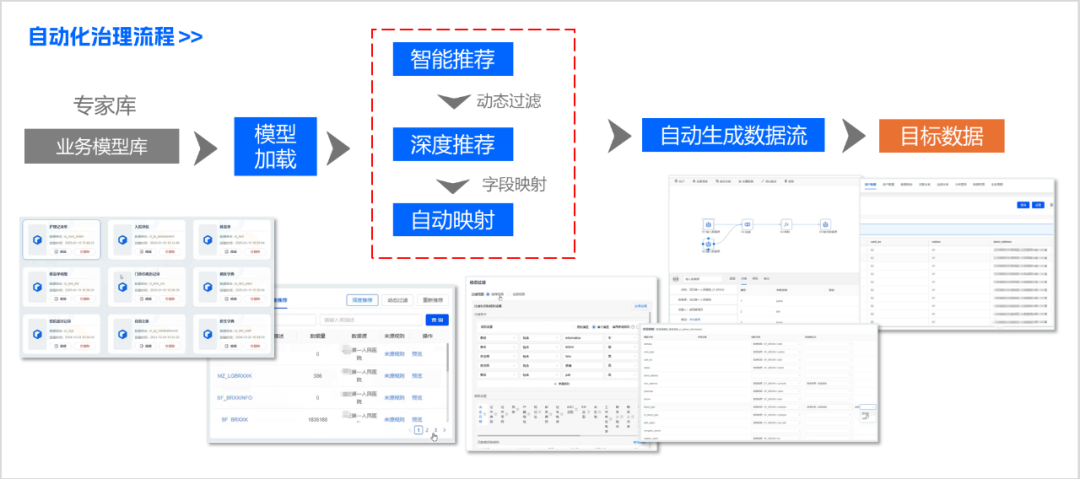
依托专家库中已经定义好的字段转换规则,结合数据语义引擎,对智能推荐的数据结果适配转换规则,实现从原始数据到标准数据的智能流水线处理,免去了以往编写SQL代码、手工构建中间表关联。这一创新模式突破性的将数据治理周期从以往的"按月迭代"提速至"天级响应",治理效率大幅提升,参与人员的技术门槛也大幅降低。同时,专家库能够动态同步省级编码标准,通过自动字段映射以及算法转换,无需人工处理。
智能自动建模与分析
打造卫健“分析超能力”
传统医疗数据分析如同一道高墙,将业务人员阻隔在数据价值之外。医疗健康数据维度复杂且时效性要求高,传统人工分析模式难以满足动态监测需求,业务人员面对海量数据常常束手无策。从数据整合到可视化呈现需要经历漫长的"接力赛",等分析结果出炉时,往往已经错过了最佳决策时机。
为了提高业务决策敏捷性,卫健委构建了一套智能数据应用引擎,如同配备了一位永不疲倦的AI分析师。只需像聊天般输入需求,或是轻松拖拽数据模块,那些曾经需要专业团队耗时数周完成的"慢性病监测报告"、"就诊趋势分析"、"疾病流行趋势预测"等复杂任务,如今在研讨会期间就能跃然屏上。
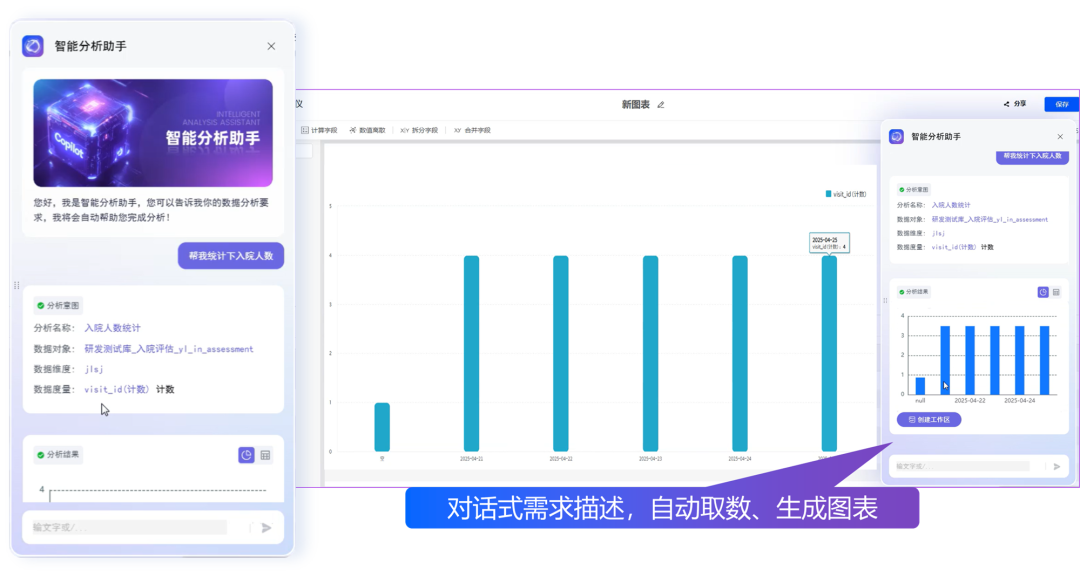
从宏观的“区域医疗全景”,到中观的“医院集群表现”,直至微观的“某家医院的接诊详情”,只需轻点鼠标就能自由穿梭,定位具体问题、历史趋势研判、智能未来预测——这些以往认为不可能的,或需要几个月才能完成的分析工作,现在只需一杯咖啡的时间就能呈现眼前。
解锁医疗文本宝藏
让70%沉睡病历数据重获新生力
对电子病历等非结构化数据的处理和使用,也是医疗领域面临的又一个棘手难题。当前这类非数据占比已超过70%,但真正能转化为标准化格式的不足三成。
医生在书写病历时,同一症状可能有十几种表述方式,比如"胸痛"可能被描述为"心前区压榨感",病情的关键信息往往分散在不同段落,这些特性往往需要专业人员耗时耗力去识别和理解内容,大量宝贵数据因此锁死在文本迷宫中,难以被采集和使用。
对此,卫健委借助领先AI技术来处理这类多模态非结构化数据,通过自然语义解析技术,不仅能精准识别"排除肺炎可能"这类需要反向标注的特殊表述,还能自动关联"冠心病"与"冠状动脉疾病"这类同义词,更能在毫秒间完成患者隐私信息的智能脱敏。
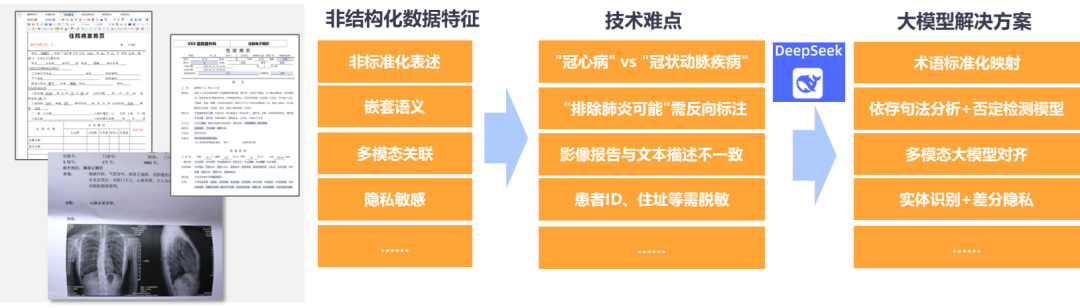
基于Deepseek等AI大模型,平台如同具备医学思维的超级助手,将杂乱无章的文本转化为脉络清晰的标准化数据,让沉睡在病历库中的临床经验、诊疗规律和疾病特征等信息重新焕发价值,为区域疾病预防管控提供全方位数据依据。

“自我进化 越用越聪明”的闭环增强回路
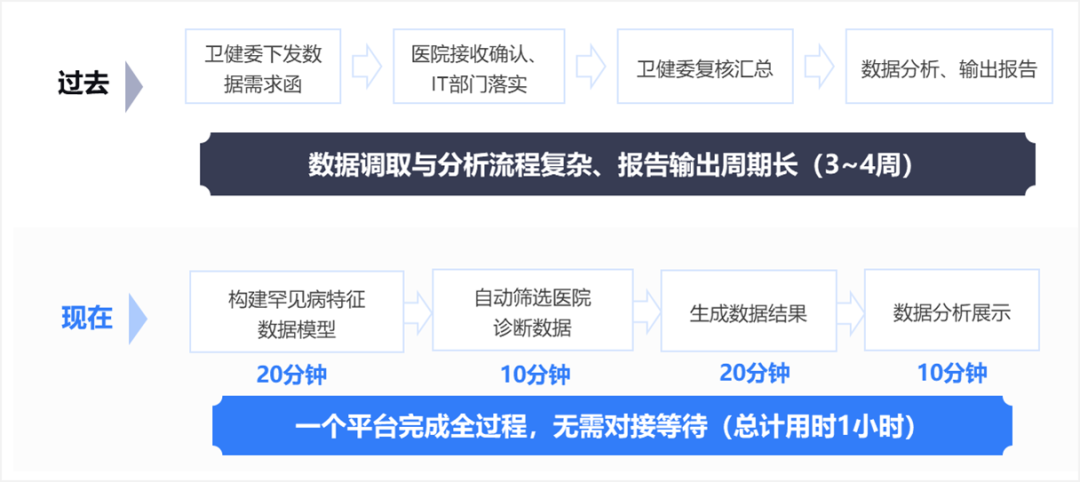
随着医疗领域专家知识库从无到有、从有到精的持续积累,全市40余家医院的接入效率实现质的飞跃:每家医院的数据接入时长从最初的3个月压缩至1周。
以最近的罕见病数据分析为例,从数据模型构建、跨院自动采集到报告生成,全流程耗时从3周锐减至1小时,真正实现了"数据即用即得"的决策支持。
这一突破性进展的秘诀在于:专家知识库不仅预置了可复用的行业数据模型与分析模型,更通过AI实现了知识的自动化沉淀。当遇到专家库未覆盖的映射规则、稽核规则时,系统能在项目执行过程中自动学习并沉淀新知识,无需人工干预。
这种"自动沉淀-自动复用"的闭环机制,使得每完成一次分析任务,系统的智能水平就提升一次——使用频次越高,知识库越完备;知识库越完备,人工干预越少,最终形成如同生命体般的自我进化能力,在医疗数据领域构建起"越用越聪明"的增强回路。
想了解卫健委效率革命背后的实践,后台私信“卫健委”获取案例详情~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









