









JDK6和JDK7的LinkedList的算法有一些区别。JDK6是:带哨兵的环形双向链表,JDK7是不带哨兵、但是有first(头节点)和last(尾节点)的双向非循环链表。哨兵的好处是使得代码更简洁,但并不能降低对链表的操作的渐进时间界;坏处是如果有很多较短链表,使用哨兵会造成存储空间的浪费(哨兵是需要new一个Entry的)。
一,JDK6:带哨兵的环形双向链表
哨兵是个哑元,它表示NIL,包含和其他元素一样的各个域。可以简化边界条件。
private transient Entry<E>header =new Entry<E>(null,null,null);
哨兵header处于链表头和链表尾之间,哨兵的next指向链表头,哨兵的prev指向表尾,表头的prev指向哨兵,表尾的next指向哨兵。这样使得每个元素Entry对象都有一个前置Entry对象和一个后置Entry对象,从而简化了表头和表尾的边界条件,简化了链表插入和删除的代码
1,构造函数:
public LinkedList() {header.next =header.previous =header; }
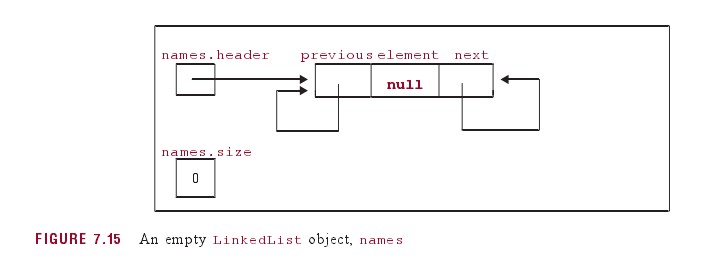
哨兵首尾相连,形成环形链表。
2,插入元素
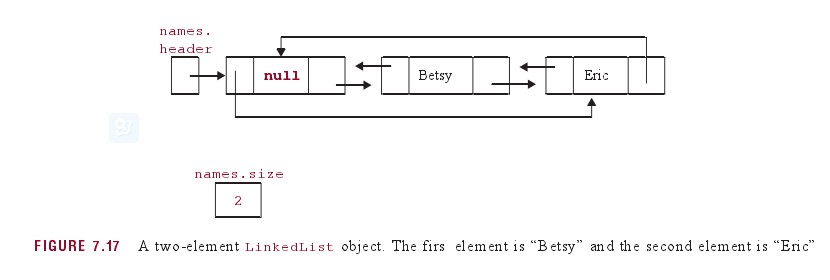
默认add方法在表尾添加元素。
下边这个方法更具有普遍性
在index位置插入元素element
public avoid add(int index,Object element){
addBefore(element,(index==size?header:entry(index)));
}如果index==size,则在表尾插入元素(由于环形双向链表的表尾的next是哨兵header,因此相当于在哨兵header之前插入一个元素,即addBefore(header)) 这个操作的时间复杂度可以认为是O(1)级别的
如果index不等于size,则需要entry(index)函数查找index位置的元素了。
由于这是一个环形双向链表,可以比较index和(size/2),来判断应该从header字段开始正向搜索还是逆向搜索
最坏情形是index在中间,要进行n/2次迭代(for循环次数),所以worstTime(n)为O(n)
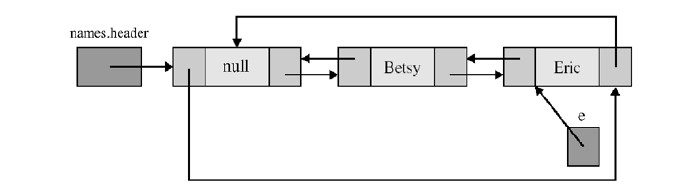
上边那张图里entry(1)的结果,找到了“Eric”元素
addBefore方法:
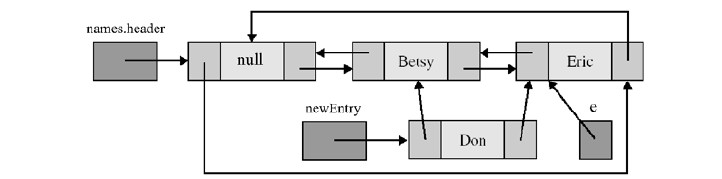
准备在阶段e前插入元素为Don的新节点,创建这个新节点newEntry,将其前驱指针域指向e的前驱,后继指针域指向e
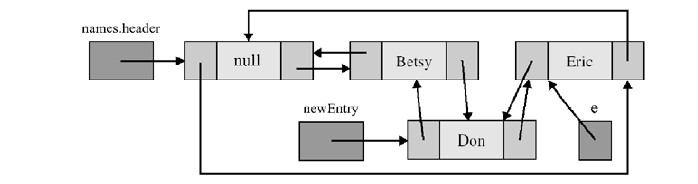
调整newEntry的前驱对象的后继指针域指向newEntry,调整newEntry的后继对象的前驱指针域指向newEntry

结果
3,删除元素
remove函数比较好写
首先要查找出节点,如果是remove(index),最坏情形迭代n/2次;如果是remove(Object),最坏情形迭代n次。总之还是O(n)
找到这个节点后,只需要改变被删除的元素的前驱对象的next和后继对象的prev就好了。这一步的操作的worstTime(n)是O(1).
总结:说LinkedList适合随机增删是有前提的,即链表不能太大。因为查找节点会耗费大量时间。















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









