









一,二叉搜索树的递归定义
t为空。或者
t的左子树的每个元素都小于t的根元素;
t的右子树的每个元素都大于t的根元素;
t的左子树和右子树都是二叉搜索树
二叉搜索树不允许树中的元素重复
二,BinarySearchTree类的实现
Java集合框架里没有二叉搜索树BinarySearchTree,因为Java集合框架里实现了红黑树——TreeSet
二叉搜索树不允许树中的元素重复。Set不允许包含重复元素,BinarySearchaTree可实现Set接口。
public class BinarySearchTree<E> extends AbstractSet<E>
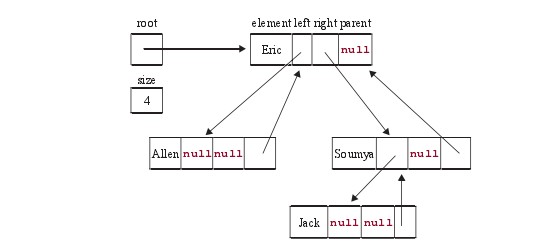
如图,BinarySearchaTree类除了迭代器外,还包括两个域——根结点和大小
Entry root;
int size;Entry结点类包括四个域——元素,以及左子结点、右子结点、父结点。
private static class Entry<E>{
E element;
Entry<E> left=null,right=null,parent;
Entry(){}
Entry(E pElement,Entry<E> pParent){
element=pElement;
parent=pParent;
}
}BinarySearchaTree包括这些方法——构造函数、拷贝构造函数、size、contains、add、remove方法。对于contains、add、remove方法而言,树的高度是估计最差时间和平均时间的关键。这三个方法都要进行查找,在查找的过程中遇到的结点构成一条从树根下降的路径。所以它们的运行时间是O(h),h是树的高度。
最坏情况是所有元素形成一个链表,查找最后那个叶结点,这时最坏时间worseTime是O(n)。而对于平均时间而言,树的平均高度是n的对数,所以平均时间averageTime是O(log n)
/**
* 初始化一个空的二叉搜索树对象。这棵二叉搜索树对象只能包含类型E的元素
* ,按照Comparable接口进行排序,不能含有重复的元素
*/
public BinarySearchTree(){
root=null;
size=0;
}BinarySearchTree只有root和size两个字段,复制构造函数在复制的时候除了复制根结点,还要复制根结点往下的各个结点。可以通过结点间的父子关系,通过递归的方式来实现copy。
/**
* 复制构造函数,浅拷贝。
* 最坏时间为O(n),n是被复制的otherTree的元素个数
* @param otherTree 要被浅复制的二叉搜索树对象
*/
public BinarySearchTree(BinarySearchTree<? extends E> otherTree){
root=copy(otherTree.root,null);
size=otherTree.size();
}
copy函数
/**复制一个结点。创建一个新结点,它复制了旧结点的元素、左子结点、右子结点,并给它指定了一个根结点
* 复制左子结点和右子结点时递归地使用这个copy函数
* Entry构造函数只需要包括元素和根结点两个参数,这样copy函数里可以用这个构造函数
* @param pEntry 被复制的结点
* @param pParent 指定的父结点
* @return 递归复制完毕后的结点
*/
private Entry<E> copy(Entry<? extends E> pEntry, Entry<E> pParent) {
// TODO 自动生成的方法存根
if(pEntry!=null){
Entry<E> newEntry=new Entry<E>(pEntry.element,pParent);
newEntry.left=copy(pEntry.left,newEntry);
newEntry.right=copy(pEntry.right,newEntry);
return newEntry;
}
return null;
}contains方法的实现
由于二叉搜索树t的左子树的每个元素都小于t的根元素,t的右子树的每个元素都大于t的根元素,可以利用这一点来决定每次比较被搜寻的元素和树中结点后,是往左子树走还是往右子树走。注意对异常的抛出。
/**
* 最坏时间为O(n),平均时间为O(log n)
* @return 如果二叉搜索树中包含该元素,返回true;否则返回false
* @throws NullPointerException 如果obj为空
* @throws ClassCastException 如果obj不空,但是不能和二叉搜索树对象中已经存在的元素比较
*/
public boolean contains(Object obj) {
Entry<E> temp = root;
int comp;
if (obj == null)
throw new NullPointerException();
while (temp != null) {
comp = ((Comparable<E>) obj).compareTo(temp.element);
if (comp == 0)
return true;
else if (comp < 0)
temp = temp.left;
else
temp = temp.right;
}
return false;
}
add方法的实现
添加成功应当将size++
如果树是空树,即root==null时,应当新建一个Entry对象作为root。
如果树不空,则先要搜索到要添加的位置。比较被搜寻的元素和树中结点,如果是小于,就准备往左走。如果是大于,就准备往右走。但是往左走或往右走之前,要先判断下左边或者右边还有子结点吗,如果没有后路了,就把这个元素作为左子结点或者右子结点添加进去。
/**
* 如果成功插入元素,size++ 最坏时间为O(n),平均时间为O(log n)
* @return 如果调用该方法后,二叉搜索树成功插入该元素,二叉搜索树改变,返回true;否则返回false(元素已经存在,不能插入)
* @throws NullPointerException
* 如果该元素为空
* @throws ClassCastException
* 如果该元素不空,但是不能和二叉搜索树对象中已经存在的元素比较
*/
public boolean add(E element) {
if (element == null)
throw new NullPointerException();
if (root == null) {// 如果树为空,则新建一个Entry对象作为root
root = new Entry<E>(element, null);
size=1;
return true;
} else {// 如果树不空,遍历元素,找到位置插入进去
Entry<E> temp = root;
int comp;
while (true) {
comp = ((Comparable<E>) element).compareTo(temp.element);
if (comp == 0)// 元素已经存在,不能插入
return false;
else if (comp < 0)
if (temp.left != null)
temp = temp.left;
else {// 插入
temp.left = new Entry<E>(element, temp);
size++;
return true;
}
else if (temp.right != null)
temp = temp.right;
else {// 插入
temp.right = new Entry<E>(element, temp);
size++;
return true;
}
}
}
}remove方法的实现
首先要找到将被删除的结点、得到这个Entry对象的引用(getEntry),然后再删除它(deleteEntry)。
public boolean remove(Object obj) {
Entry e = getEntry(obj);
if (e == null)
return false;
deleteEntry(e);
return true;
}getEntry方法的实现类似于前边寻找结点的过程
/**搜索包含元素obj的结点并返回之
* @param obj 将被搜索的元素
* @return 如果找到了,返回true;如果没找到,返回null
* @throws NullPointerException
* 如果obj为空
* @throws ClassCastException
* 如果obj不空,但是不能和二叉搜索树对象中已经存在的元素比较
*/
private Entry getEntry(Object obj) {
// TODO 自动生成的方法存根
Entry<E> temp = root;
int comp;
if (obj == null)
throw new NullPointerException();
while (temp != null) {
comp = ((Comparable<E>) obj).compareTo(temp.element);
if (comp == 0)
return temp;
else if (comp < 0)
temp = temp.left;
else
temp = temp.right;
}
return null;
}deleteEntry方法比较麻烦
首先删除成功应当size - -
如果被删除的结点有两个子结点,如下图,要删除80,记作结点p
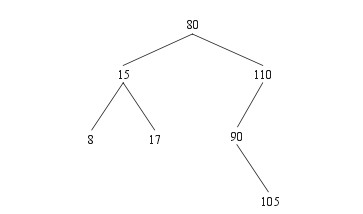
那就要找到p——80的后继结点successor (p),它是90,记作结点s
对于有两个子结点的结点p来讲,后继结点应当是p的右子树里最左边的结点(比它大的所有元素里最小的那个)。因此这个后继结点是没有左结点的。
将90这个元素复制给p
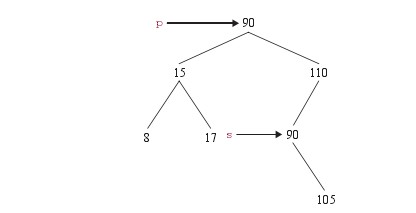
然后将s赋值给p,即将p指向s这个结点
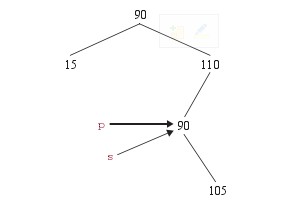
上述过程用代码表示为
if(p.left!=null&&p.right!=null){
Entry s=successor(p);
p.element=s.element;
p=s;
}后继方法successor(p)待会再开发。
然后删除s这个结点,将p指向删除后替代它位置的结点105.
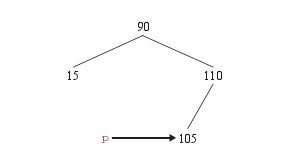
由于被删除的这个结点没有左子结点,因此删除它,相当于是在处理只有一个子结点或者没有子结点的删除操作。也就是说,删除有两个子结点的情况退化成了只有一个子结点或者没有子结点的情况。
如果没有子结点,就要区分是不是在删除根结点。
如果只有一个子结点
设结点replacement结点用来代替被删除的p结点
如果左子结点不空,那就就用左子结点代替;
否则,就用右子结点代替。
然后也要区分p是不是根结点。
//处理没有子结点的情形
if(p.left==null&&p.right==null){
if(p.parent==null)//删除根结点
root=null;
else//p不是根结点,但是p没有子结点
if(p==p.parent.left)
p.parent.left=null;
else
p.parent.right=null;
}
else{//处理只有一个子结点的情形
Entry replacement;
if(p.left!=null)//只有左子结点不空
replacement=p.left;
else//只有右子结点不空
replacement=p.right;
replacement.parent=p.parent;
if(p.parent==null)//p是根结点
root=replacement;
else
if(p==p.parent.left)
p.parent.left=replacement;
else
p.parent.right=replacement;
}这段代码是可以整合的。
没有子结点时,replacement=null,这时不需要设置replacement的父结点,其它处理方式都跟有一个子结点时一样
//处理最多只有一个子结点的情形
Entry replacement = (p.left != null ? p.left : p.right);//replacement=p.right的情形包括只有右子结点不空或者没有子结点(如果p.right是null,replacement也就是null了)
if(replacement!=null)//如果replacement不空,就设置它的父结点;如果空,就不用设置replacement父结点了
replacement.parent=p.parent;
if(p.parent==null)//p是根结点
root=replacement;
else//p不是根结点
if(p==p.parent.left)
p.parent.left=replacement;
else
p.parent.right=replacement;successor(p)方法如何实现?考虑到迭代器还需要开发next方法,在next方法里还会用到successor方法来求得后继结点,开发successor方法时就不仅仅处理有两个子结点的情形了。
在这里,我们是在考虑中序遍历左-根-右下的方法。
什么叫后继结点呢?后继就是大于本结点的元素的所有结点里元素最小的那个结点。我们知道左子树的结点元素值<根结点元素值<右子树结点元素值。
如果p结点有右子结点的话,后继结点应当是p的右子树里最左边的结点。所以该方法先向右子树移动,然后尽可能向左移动
如果p结点没有右子结点呢?如果p有后继结点y,那么y肯定是p的祖先了。而且y得比p的元素大,那么p是在y的左子树上,或者说y的左孩子也是p的祖先(p也是p本身的祖先,只不过不是真祖先)。y是比比p的元素大的结点里头元素最小的那个结点,所以y是其左子树包含p的结点中最低的结点,或者说y是其左孩子也是p祖先的p的祖先中的最低真祖先。(y>y.left≥p,所以y>p,是真祖先。)
代码如下:
private Entry<E> successor(Entry<E> p) {
// TODO 自动生成的方法存根
if (p == null)
return null;
else {
Entry<E> x=p;
if (x.right != null)
return treeMin(x.right);
else {
Entry<E> y = p.parent;
while (y != null && x == y.right) {
x = y;
y = y.parent;
}
return y;
}
}
}
//寻找最小元素结点
public Entry<E> treeMin(Entry<E> p){
while(p.left!=null)
p=p.left;
return p;
}
迭代器的实现
默认构造函数:对于中序遍历——左-根-右,应当从最小元素开始,也就是最左边的结点开始,lastReturned为null
public TreeIterator() {
next=root;
if(next!=null)
treeMin(next);
}
第一次调用next()方法是为了返回第一个结点的元素,其实就是从null开始算起的下一个元素。所以next()方法可用lastReturned保存当前next的值也就是被返回的结点,而next指向后继结点,返回的时候返回lastReturned的元素值即可。这样就实现了返回结点元素值的功能和next指针指向后继结点的功能。
public E next() {
// TODO 自动生成的方法存根
if(next==null)
throw new NoSuchElementException();//越界异常
lastReturned=next;
next=successor(next);
return lastReturned.element;
}remove方法:
一般情况直接调用deleteEntry(lastReturned)方法就行了。删除lastReturned结点。
但是当lastReturned有两个子结点的时候,deleteEntry(lastReturned)方法实际上是拿next这个后继结点的元素值复制给lastReturned,然后删除next这个结点。这样一来next结点就不在树上了。需要让next仍然指向那个后继结点,所以应当在方法一开始让next=lastReturned;
public void remove() {
// TODO 自动生成的方法存根
if(lastReturned.left!=null&&lastReturned.right!=null)//lastReturned有两个子结点的情况
next=lastReturned;
deleteEntry(lastReturned);
lastReturned=null;
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









